About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Mary had a ...
Had a go out sound in - and couldn't get it to work at first, so I went for a nice ride. Just a casual 58km with a long beer and pizza stop at a mate's on the way. I was a little sore and tired by the time I got home (mostly from the saddle; haven't ridden that bike much for ages), but after a decent sleep, not a hint of soreness.
After I got home and became bored with TV I decided to have a search on the net about sound again - and the vital clue - aux-in is line-level and not mic-level (well I should've known that but it all goes through the same amps). So the code was working after-all, I plugged a laptop out into line-in and got some results.
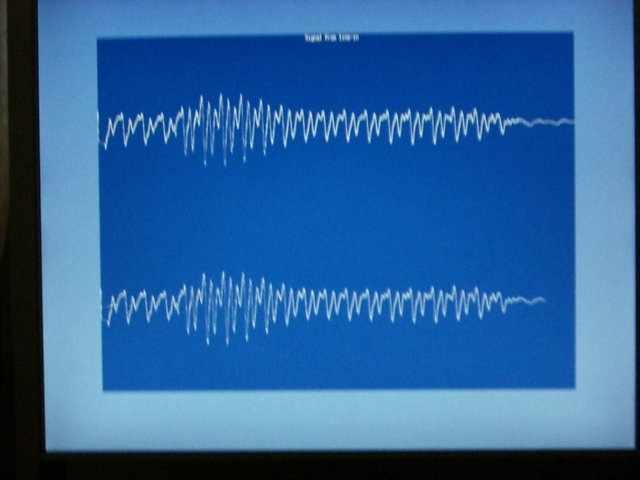
Actually I worked out that if I use a speaker (or headphones) as the line-in, I can get enough signal as well, but I left the gain at 0dB for a line-level signal.
Then I wrote a very simple synthesiser loop which plays 'mary had a little lamb' (badly) with a triangle-wave and simple ADSR envelope (in true SID-chip style!), and then jumps to a rather annoying 440Hz sound which phases from side to side, whilst showing the line-in waveform on the screen (as in the screenshot).
Source in audo-beep.c, which includes all of the initialisation code as well.There's a commented line in the init:
aregw(AV_ATX2ARXPGA, (7 << 3) | 7);
which can send the digital signal from line-in directly to the output. But the signal is really rather awful, and doesn't seem to match the data received, with lots of clipping and nastiness. Probably some bad interaction with the synethsiser data, and not biasing things properly.
This code doesn't use DMA, so is about as simple as you can get whilst still making noises.
Hmm, I wonder what to do next. Having USB for keyboard and mouse is a real pain, it's pretty hard to do much interesting `computer' stuff when you only have a serial port for communications.
Now to get 'mary had a little lamb' out of my head ...
Beagle beeps
Well, some semblance of a beep, it sounds more like an alarm going off. Another frustrating tasks of mis-understanding and reboots.
To start with I had it 'click' when it turned the audio codec on or off, so at least I knew I was writing to the right registers. And changing the volume even changed the magnitude of the click.
Then after setting all the registers to something that seemed to make sense, I simply forgot to turn on the audio interface, so I spent a lot of time wondering why the McBSP end of things wasn't sending any data out (I was copying the `MP3 Out' use-case too closely which neglected to mention it ... although I read about the enable bit numerous times and knew I needed it, I simply forgot to check I was setting it). Then once I got that working I still had no sound - I couldn't get the routing to work. I knew the serial port frame signaling was at least working (no idea on the data) as changing the sample rate had an effect on how often XDRDY was asserted.
But nothing I tried worked. The audio device has quite a few registers spread all over the place, and the manual is formatted in a way which makes them hard to look up or follow. It only has a TOC entry for the whole lot, and with Evince, that makes it pretty tricky to navigate. Not to mention that Evince wants to select links half the time when you click on them just to make things more painful. I think I missed something in the manual about which serial sources receive data from the port, and data only comes in via serial 2 for non-TDM signaling. And I was trying to use serial input 1 as the source, then switching that to audio 1 internally - so I guess there was no sound from the start.
In the end I cheated a bit - I got a dump of the registers on a running GNU/Linux system which was playing sound at the time. Then I compared them one by one with those I had - on the way found some bugs anyway - and eventually just set the routing up the same way.
After all the hassles and straining to hear anything from a set of headphones I was surprised when it worked - fortunately I had the headphones off otherwise I might've got a rude shock at 3 in the morning. I'm still not using DMA to write to it, but that shouldn't be too difficult. I want to try to receive sound first before I try DMA or drop the code, but hopefully that should be simpler, since I don't have much choice in what goes where now.
Oh there was one other sting in the tail. I was playing with one of the gain controls to see if I could turn the volume down a bit: AV_ARXL2PGA. It's supposed to have a range from 0x00 to 0x3f (i.e. from mute to 0dB in 1dB steps; the master volume control), but if I set any value below about 0x30 it simply mutes the output. Which was another value I 'got wrong' when testing, so who knows, I might've had the routing correct at one point and not heard anything because of this. I'll have to have another poke at that too.
So mistakes in summary:
- Forget to turn on the AUDIO_IF bit to receive data.
- Didn't make sure the master volume (ARXL2PGA, ARXR2PGA) is over 0x30 (why this is an issue I don't know).
- For I2S mode, it seems audio only comes in through SDRL2 and SDRR2.
For the McBSP2 there was some issues too, to do with signaling polarities mostly - although I don't know if I have them right yet. Requires looking at the raw signal diagrams more closely.
Hmm, looks like a nice day for a ride.
Searching for myself
No i'm not about to go all deep and meaningful on you, although I was probably drunk enough earlier to consider it. Neither have I lost track of my person. Nor was I vanity-surfing.
First I was looking at how easy this blog was to find when looking for beagle board coding info, and then I was looking to see how easy info about me was to find for those that might be looking.
For the first I found a `BeagleBoard' user on facebook who has been noting my posts - but for that I had to dig, as I did for this site. And for the second I found a real gem of a memory on the first page of Google search results:
PC Backups/bugs etc.
Michael Zucchi (cismpz@cis.unisa.edu.au)
Tue, 10 Sep 1996 13:00:20 +0930 (CST)
* Messages sorted by: [ date ][ thread ][ subject ][ author ]
* Next message: Ken Laprade: "BUG: "cannot create" error file"
* Previous message: Martin Espinoza: "I need someone's, ANYONE's ...
* Next in thread: Gregory T. Notch: "Re: PC Backups/bugs etc."
Howdy,
I'm an assistant sysadmin in a small computer department at the Uni
of South Australia. We have automated backup systems for unix
(using amanda), and mac systems (using retrospect), however its
currently upto the users of pc systems to backup the files they
use regularly, with whatever means they have at thier disposal.
Now, the recent versions of 'samba' include an smbclient which can
create tar files from pc shares. Obviously the idea here is to
use the recent tar support of Amanda to automagially do our PC
backups too, based on WFWG shares on each of the systems to be
backed up. Essentially, i'm trying to 'bolt on' remote pc share
'tar' support into the gnu-tar files. e.g. if the disklist
contains:
hostname //pchost/password nocomp-user-tar
then the 'hostname' host has samba installed (in my case i use
the master backup host - load to this host could be a problem
when a large number of remote pc disks are being backed up through it),
and when a backup takes place it connects to \\pchost\backup with
the password 'password', and tars to stdout. The gnutar code
recognises a remote pc host by the disk name syntax. I also modified
the smbclient software slightly to produce a 'totals' line from
stderr. I'm not sure if i'll ever get it finished, but i've managed
to get it to tar a remote NT workstation share and record it in
/etc/amandates, and incremental backups should work (properly - using
the dos archive bit) too.
However i seem to have found a bug in Amanda in the process.
client-src/sendsize.c calls start_amandates(0) in line 89.
start_amandates runs ok, but calls enter_record (from
common-src/amandates.c) which, on error (when the recorded
dump date doesn't match the /etc/amandates dumpdate) it
tries to use the 'log' function. This in turn tries to access
the config files - which aren't stored on the client side of
an amanda setup. Consequently sendsize bombs out with:
"sendsize: could not open log file (null): Bad address"
As this seems the only place to report bugs, i'm leaving it
here.
Regards,
Michael Zucchi
--
/// `... thinking is an exercise to which all too few brains
/// are accustomed.' - First Lensman, E.E. `Doc' Smith
\\\/// Michael Zucchi B.E. M.Zucchi@UniSA.edu.au
\\\/ CIS, Assistant Systems Administrator, UniSA +61 8 302 3033
* Next message: Ken Laprade: "BUG: "cannot create" error file"
* Previous message: Martin Espinoza: "I need someone's, ANYONE's ...
* Next in thread: Gregory T. Notch: "Re: PC Backups/bugs etc."
Wow. From my first job. I had written and released free-ware before for AmigaOS in isolation (an accelerated GIF decoding system component for example), but IIRC this was pretty much my first post to a free software mailing list, and it was followed not long after by my first patch.
I was so polite back then, I wonder what happened. And wrote overly verbose email messages as I continue to do to this day. Although I had a somewhat pretentious signature (which I kept for many years), I still think it speaks volumes.
But after 15 years of crapping around the internet, you might have expected something like that would've dropped from the first page by now ...
What I find interesting is that if you search in 'bing', that is about the only sort of thing you CAN easily find with my name on it. It's like the whole internet after 1998 simply doesn't exist as far as I'm concerned (oddly enough, that's about when I started on GNOME).
Hmm, maybe that wouldn't be such a bad thing either.
A couple of bits and pieces
Wow this really turned into a monster post, I guess I had a lot of crap on my mind. So much for going for a ride today as i'd hoped - the wind really picked up anyway so it wouldn't have been much fun.
On Software Engineering ...
First, a couple of interesting posts on a blog run by a guy from Insomniac (Ratchet & Clank, Resistance, etc). I've read bits of his before because he has some posts about CELL coding, but I came across his revamped site recently whilst looking up issues about C99's un-ANSI-C-ed-ness.Three Big Lies of Software Development. I think they are pretty fundamental things that every programmer needs to keep in mind. The first is the scourge of pretty much all modern software - and why software seems to stay about the same speed even though hardware has jumped in leaps and bounds. The second I suggest could be squarely aimed at every introductory course to `object oriented design' and is exacerbated by the first lie. And the third is probably the most important; it's the data, stupid.Sketches on on concurrency, data design, and performance is also a must read in this day and age of multi-processors. The post-it notes are a particularly nice touch although the PDF versions are much nicer to read than the web gallery. I particularly like his rant against typical C++, and how he explains that ideas such as a 'lock free doubly-linked list' are nonsensical in a concurrent environment. e.g. with no 'after' or 'before', how can you insert 'after' or 'before', and without an insert 'after' or 'before', it is no longer the same ADT.And finally the aforementioned reference to C99's weirdness in understanding strict aliasing. I see why they added this feature - to enable optimisations that a compiler couldn't otherwise do (but looked obvious to an author), but to me it just isn't `C' any more, it's a slightly different language (and worse, it conflicts explicitly with the sort of stuff you need to do to make normal C faster or do operating-system type tasks). Anyway, I think this particular comment really tells the story, with my own emphasis:
The above source when compiled with GCC 3.4.1 or GCC 4.0 with the -Wstrict-aliasing=2 flag enabled will NOT generate a warning. This should serve as an example to
always check the generated code
. Warnings are often helpful hints, but they are by no means exaustive and do not always detect when a programmer makes an error. Like any peice of software, a compiler has limits. Knowing them can only be helpful.
I'm not sure that even I would be terrible comfortable with a language where that was a requirement - and I suspect i'd be far more comfortable with it than the majority. I was looking this stuff up because Jeff was chatting to me about some of my code in Evolution that a recent gcc was just silently dropping because it aliased some pointers. Funny, I thought that's what casts were for - and it's not like you can't still do it, you can just use a union to do exactly same thing; it's just a lot messier for humans to read. Anyway, that post is a really good explanation of the issue and how to change your code to fit the newer C variant so the compiler can make it run (potentially quite a bit) faster.
Anyway, a very interesting few posts on Mr Acton's site - it's a pity he doesn't update it a little more often (there's more on Insomniacs R&D site too, much more I still need to read myself).
On Menus ...
Odd information I feel the need to share: IceCat (Firefox) gets a little unwieldy with 180 tabs open, I think this is the fourth copy of A Hacker's Craic open because I can't be bothered to find the other ones. It still runs though.
Which leads me on to partly why ... scrolling @#@#ing menus. What idiot decided they belonged in any modern toolkit (let me guess, they're in Cocoa)? I remember seeing some GUI toolkit implement them in the early 90's and thought `that looked pretty cool' - but they aren't. They suck. They don't scale, and they're difficult to use. Even a small list on a button at the top or bottom of the screen will put on tiny hard-to-hit and hard-to-use up/down arrows if you've previously selected an item at the wrong part of the list. Try using one with a G-spot under your finger.

This my friend, is a G-spot.
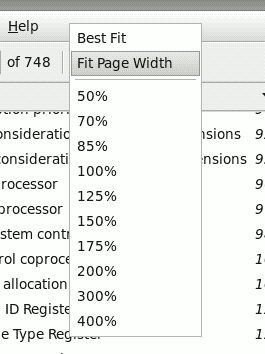
So here's a perfect example in Evince, which I have been using heavily recently (more on that later). It looks pretty and all, nice and simple and obvious and `easy to use'.
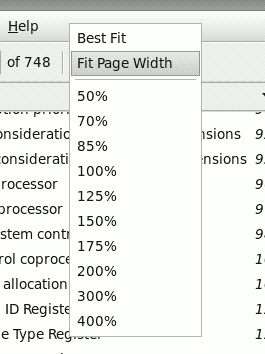
Now look what happens when you access it from Evince running in full-screen mode. And this is only one of the possibilities, you get various, quite-different results depending on exactly where within the button you click and if the mouse moves whilst you press on it with your finger e.g. if you click near the top it actually selects `Best Fit' for you and removes the scrolling buttons since the mouse is suddenly over the 'up scroll region' and not over the current item.
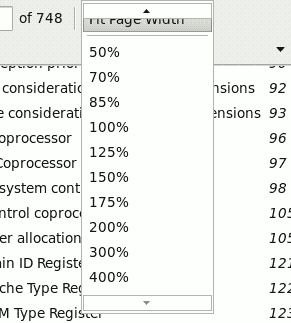
Hmm, nice one. It looks like arse, is completely unnecessary, and those silly little `scroll region/buttons' are too hard to use; apart from being too small, they're actually a whole new type of button which aren't used anywhere else in any GUI - a `click-less button', or `hover button' if you will. I'm using a fairly old Evince, so these might be bugs specific to the version, but the whole idea stinks and it's going to always have these sorts of serious usability issues - a menu that can look different every time you use it isn't going to aid muscle memory for starters. Not to mention the stupid `hover buttons' that you need to put your mouse over and wait ... wait ... wait for it to show the desired item.
The problem is it's mixing two access modes, a 'click' and a 'hover mode' - once you click on the button you're in 'hover mode' - whatever the mouse is over is selected or activated. So it has to attempt to ensure the mouse is over the right location when you click, and since it wont warp the mouse pointer, it warps the menu instead. Even mouse pointer warping would be (much) better than this, but there are alternatives like staying in a 'click' mode and just requiring another click to actually select an option. It sort of does this if you don't move when you 'click', but I don't know many mice that don't move most of the time when you physically push part of them, so it's even worse - you could get either behaviour depending on how steady your hand is. In the Firefox case with 180 items it would just never work anyway, it's just the wrong UI element to use.
As for Evince, I think i'm stuck using the wrong tool for the job. It's not really much of a document reader once you get a document with over few dozen pages. The search is very slow too, on my workstation it takes about 70 seconds (depending greatly on the search string) to scan the OMAP3 TRM (~3500 pages); although I realise this has a lot to do with the PDF format. fgrep scans the whole 22MB raw file in 0.035s. Add no find all, and the fact it forgets the last search as soon as you click somewhere, and it's pretty painful. Not to mention the lack of navigation stack and other basics which get in the way. Ok perhaps it is intended to be a simple viewer for 'users' - but
developers are friggan `users' too
.
Now, there was something else I wanted to mention ... what was it. Damn, completely gone. Oh oh, no, here it comes. It's about `distributions'.
On Distributions ...
On the Haiku lists there's been some discussions about package management. And that naturally leads to the idea of a `distribution' - which the Haiku guys are fundamentally against, and I think with good reason.
What exactly is a `distribution'? It's a collection of software which has been thrown together and presumably validated to some extent in such a way as to work together. In a way it is a kind of `neat' thing, and one that can only exist because all the software is free software; every single piece of third software can (potentially) be compiled and validated specifically for the target platform. This is a pretty fundamental change to the way software is distributed, and can lead to fundamentally different outcomes, for example with security, or platform support. Even a lowly IRC client is under complete vendor control, so can be prevented from becoming a penetration attack vector because of some sloppy code or accidents. Or a vendor can rebuild everything for a different hardware platform without having to wait for every ISV to support it. And upgrading can be a bit fun if your computer is a playground - discovering all the new features of every application (until you're a jaded old prick like me, where half the changes are frustratingly stupid).
So, there are many benefits from `distribution' based deployment.
However there are problems as well. We all used to scowl at how M$ forces everyone onto the upgrade treadmill, but although different in nature, is quite a problem with `distribution' based software too. In some ways it is worse - you actually have to upgrade all of your software at once; and this is not always a good thing. New versions means new bugs, and with the propensity for the most active developers being rewarded with having their projects anointed for inclusion, often stable mature applications are replaced with unstable shinier newer ones. Some previously existing software may not make the cut at all, so you can't even keep using it if you wanted to. And although it's more of a serious problem for proprietary software (and thus not particularly important), the upgrade mill affects free software too - it can be extremely tough going compiling older software to a usable state - and probably drag in a whole pile of tools and libraries not used elsewhere. In effect old software bit-rots faster than it needs to, and is effectively locked out and thrown away. This is particularly acute with the modern scourge of using massive and complex frameworks which change in incompatible ways from version to version in time-frames of 5 years or less.
The strength of a Unix-like `open platform' is also it's major weakness. For example, by having the option to use different toolkits in X, every dog and his man will choose a different toolkit for their apps. And this just multiplies all of the potential issues that large-scale code faces; project goals, consistent design philosophy, bugs and maintenance. Not only do you have these problems within a given software `platform', it is multiplied across all of them.
Just look at the completely fucked-up-mess that sound is. Just imagine the state we'd be in if the kernel didn't implement TCP/IP but we had 4 or 5 different, incompatible, and competing implementations running in user-land. Sound is just as fundamentally a hardware issue as networking is, so why isn't it all just in the kernel the same way? And i'm talking about the full audio stack here, not just a buffer to a DAC which is all Linux will allow, throwing the guts of modern sound off to user-land. After all, we don't have user-land switching of the ethernet packets do we?
So I think what the Haiku devs are really trying to avoid is such a mess infiltrating their system. Without this crap to deal with there just isn't any need for a `distribution' in the first place. And even the fact of having a single GUI toolkit with tighter focus will take a lot less effort to maintain than a dozen (regardless of the matter of spreading the load), and more importantly provide the user with a more consistent and pleasant experience. And developers too for that matter; having a choice just means the wrong one can be taken.
Hmm, I like the sound of that, and can't find any reference in a web search, so with a bit of outright ego-tism, I shall claim it to be my own.
Zucchi's Law
“Having a choice always leads to
the wrong option being taken
at least some of the time.”
Somewhat analagous to Murphy's Law I guess, but the key difference is this is about the limitations of informed choice and the fallibility of humans, not of their environment.
There's nothing technical stopping GNU/Linux doing the same thing, but there's too much `wet ware' in the way, so the politics make it completely impossible. It will take another operating system to do it. That's all Android or ChromeOS are; a single toolkit and application environment with less choice for the developer, but still built on the same base operating system.
Eye-Too-See
Slightly wet day today ... what better excuse is needed for some hacking. Like I needed one.I started looking at the I
2
C controller today. Originally the idea was to try and get some sort of sound out of the board (it's one of the parts needed), but then I thought that was a bit too ambitious. So I settled for trying to blink the LED connected to the power controller/audio chip.After a bit of a false start it just worked. Damn, there's a surprise, not used to things `just working'. The manual describes programming the I
2
C controller a few times, and only the one with the detailed flow-chart of a sort of state-machine is the one that works. Took a little while to work out how to read back data from a master, but it was reasonably straight forward given the description of the protocol in the TPS65950 manual.Since the LED is connected through a PWM the code does more than just turn the LED on and off, I made it `pulse' by smoothly changing the duty cycle using an approximate sine curve. Code is in i2c-leds.
Vectors and Bits again
Well I fixed the `c long' version of the rect-fill from the update mentioned a couple of posts ago ... and a bit more besides.
After sleeping in a bit I worked on some MMU code so I can start using the CPU cache. Most of that was just gaining a deeper understanding of the permission and memory type bits, which are a little confusing in places. It looks like it's been extended a couple of times whilst keeping compatability so there's multiple combinations that appear to do the same thing but with different nomenclature. Hmm, I have it more or less worked out ... I think. So once I got the MMU code working, it allowed me to enable caches and play a bit with various options. I used only section and super-section pages - 1MB or 16MB, so i'm probably only using a couple of TLB entries to run everything (= no page table walks).
I was assuming the caches were on when i enabled the MMU ... oh but they weren't, of course ... stupid me. Wow does that make a difference ... Wow.
Ok, pause to run a few more timings. ... Here goes.
Code Total Slowest Fastest
C short 36097442 0.89 5.22
C long 40526536 1.00 5.86
ARM asm 15801430 0.38 2.28
NEON 9654736 0.23 1.39
NEON2 9982542 0.24 1.44
NEON3 9421366 0.23 1.36
NEON4 9467262 0.23 1.37
sDMA 6904794 0.17 1.00
(see 2 posts ago, or render-rect.c for what they mean)
This is the original scenario from a previous post, but with a 'fixed' C long version. Strangely, it runs slower than the short version. A cursory look at the assembly looks like it's doing the right thing - but it's not worth looking deeper. My guess is the extra logic required for the un-aligned edges is throwing it out or the pointer aliasing is making the compiler angry. Oddly, the performance monitor is registering the same number of data writes too.
Anyway, who cares. Lets turn the MMU on and set the memory regions up properly and and see what happens. Even with the caches off things happen, although not much.
With MMU on, graphics = wt With MMU on, graphics = wb
Code Total Slowest Fastest Code Total Slowest Fastest
C short 36058684 0.89 7.33 C short 36233408 0.89 5.23
C long 40496404 1.00 8.23 C long 40584664 1.00 5.86
ARM asm 9367578 0.23 1.90 ARM asm 15811204 0.38 2.28
NEON 5332580 0.13 1.08 NEON 9653676 0.23 1.39
NEON2 4917308 0.12 1.00 NEON2 10057086 0.24 1.45
NEON3 5598968 0.13 1.13 NEON3 9555816 0.23 1.38
NEON4 5685246 0.14 1.15 NEON4 9431842 0.23 1.36
sDMA 6908602 0.17 1.40 sDMA 6917612 0.17 1.00
We're starting to beat the system DMA - I presume that even with the cache off this enables some sort of write-combining/write-buffering. It's interesting that the NEON2 code speeds up the most (nearly 2x) - probably given it has the smallest loop the CPU isn't in contention for memory bandwidth as much. You'd never use a write-back cache for video memory, but I timed it anyway. I really have no idea how or why using it is making any difference whatsoever though, since the global cache bits are all off!
Ok, so ... der, lets turn on the caches properly.
The way I set the MMU up is to have the first bank of memory - where all code and data resides - as write-back write-allocate (writes also read a cache-line), and the second - where the frame-buffer resides - as write-through no-write-allocate. For the `graphics = wb' case, I also set write-back write-allocate on the second bank of memory (in a separate run). All the IO devices are using shared-device mode.
First, with unrolled loops.
MMU on, graphics = wt, -O3 -funroll-loops MMU on, graphics = wb, -O3 -funroll-loops
-- lots of artifacts
Code Total Slowest Fastest Code Total Slowest Fastest
C short 957743 0.14 1.02 C short 1816546 0.28 1.00
C long 956818 0.14 1.02 C long 1992627 0.30 1.09
ARM asm 933198 0.14 1.00 ARM asm 1871829 0.28 1.03
NEON 930448 0.14 1.00 NEON 1857085 0.28 1.02
NEON2 945969 0.14 1.01 NEON2 1862711 0.28 1.02
NEON3 946522 0.14 1.01 NEON3 1848473 0.28 1.01
NEON4 945739 0.14 1.01 NEON4 1861538 0.28 1.02
sDMA 6456313 1.00 6.93 sDMA 6455228 1.00 3.55
Ahh, now this is more like it. Getting over 800MB/S (if my timing calculations are right).
Even the basic crappy C code is within a whisker of everything else - even though it executes about 3.5x as many instructions to get the same work done. The system DMA has fallen right off; but run asynchronously it would probably still be worth using since it is basically `free', and the CPU can do a lot more than just write memory. This code also polls the DMA status in a tight loop, I don't know if that is having any bandwidth effects
The write-back timing is all out of whack - the C short version is the first to run, so it gets a benefit of having an empty cache and nothing to write-back. You also get to see the CPU write stuff back to the screen when it feels the need - lots of weird visual artifacts. And the explicit cache flushing required would only make it slower on top of that. In short - useless for a framebuffer. Any performance issues you might expect a write-back cache to address are handled much better by using proper algorithms. I saw it mentioned on the beagleboard list, so it seemed worthy of comment ...
And lastly, just with -O3, a typical compile flag (-funroll-loops generates much bigger code so might not always be desirable). I also added in a `hyper-optimised' memset implementation for good measure.
MMU on, graphics = wt, -O3
Code Total Slowest Fastest
C short 1372096 0.21 1.47
C long 1038868 0.16 1.11
ARM asm 948600 0.14 1.02
NEON 929968 0.14 1.00
NEON2 939165 0.14 1.00
NEON3 946102 0.14 1.01
NEON4 945702 0.14 1.01
msNEON 1309313 0.20 1.40 (see memset_armneon())
sDMA 6462071 1.00 6.94
The C is still ok, if a bit slower, but barely worth `optimising' in this trivial case.
The msNEON code is from the link indicated ... interesting that a more complex C loop beats it somewhat; the msNEON code is only writing the same amount of memory linearly not as a rectangle, and with severe alignment restrictions.
The NEON2 code has such a simple inner loop, yet is the most consistently top performer. Good to see that KISS sometimes still works.
// write out 32-byte chunks
2: subs r6,#1
vst1.64 { d0, d1, d2, d3 }, [r5, :64]! // ARM syntax is `r5 @ 64'
bgt 2b
The ARM code is quite a mess by comparison:
// write out 32-byte chunks
2: strd r2,[r5]
strd r2,[r5, #8]
strd r2,[r5, #16]
subs r6,#1
strd r2,[r5, #24]
add r5,r5,#32
bgt 2b
(FWIW I tried a similar trivial loop in ARM, a direct translation of the `C long' code, and that wasn't terribly fast).
Anyway, I think i've done memory fill/rect fill to bloody death (and beyond!) now. It's just not a terribly interesting problem - particularly for a SIMD unit. Apart from evaluating raw memory performance. Actually it is kind of handy for that since it will easily show if things aren't configured properly.
PS Code changes not committed yet.
Time is an illusion ...
Damn, it's 4am again. Knew I should've gone out for a ride yesterday, just haven't felt really sleepy - but it's starting to bite now.
I was watching TV (well, I had it on, it was a pretty boring - and extremely long - silent movie from Taiwan) and catching up on the news ... and then I got bored with that ... and poked around the 'my.ti.com' for a little while and came across some beagleboard TV out stuff. And being a glutton for punishment, something to look at at midnight ...
When playing with the Haiku boot process I had installed an older u-boot which initialises the video, so I guessed that should at least be a good signal. So I dragged it all around to the TV again and plugged it in and booted it up. Blah, still crap. What's going on. So as a last resort I tried another cable - i'd been using one of those expensive ones and just didn't expect any problems. Found a brand new cheapie from a video card or something ... damn, worked!
Well after much mucking about and a few mistakes I added some API to add TV out, and handle viewports on larger data (to clone the lcd display), and well, enough crapping on:

Don't mind the grey screen on the venerable old 1084 ... I don't have the right cable to hook up separated-lca to s-video, so there's no colour signal.
Hmm, now the cat's whining, wonder what he wants.
vectors and bits
Updated, see the end of the post
Yesterday I started poking around with the SIMD unit. Wow, is that a way to eat up time or what.
Wasn't quite sure what to do with it, so played at first with writing an RGB888 to RGB565 converter. Didn't get to testing it, but it brought back memories of the SPU hacking I did before - the instruction set has a lot of similarities, although NEON is filled out more. And like with the SPU, there's so many ways to do the same thing it can be a bit overwhelming trying to find a good way of solving a problem. Particularly if you don't really know which instructions are there, or what they do. There seems to be some interesting ones though, like vrsi which lets you insert the upper-bits of each element into the lower-bits of each element in another register (without clobbering it's contents). I still seem to be wedded to the vtbl instruction as I was with the shuffleb instruction on SPU, although I think it's not always the best route. I really missed the spu_timing tool though - although the issue rules and latencies are simpler.
That idea didn't seem to be going anywhere in particular, so I thought i'd look at some specific stuff I need, and for which I have very slow implementations - font rendering and rect fill, although I only got around to looking at rect fill, and that still doesn't work 100%. I just did it using ARM code though. For such an old architecture i'm was a little surprised at the lack of info available for such tasks - at least as it applies to searching using google. Maybe it's too old, and the new stuff is hidden away in proprietary and embedded systems, and nobody does software rendering anymore.
And then I totally lost track of the time reading about the DSP ... at 4am I thought it was time to `call it a night' - that's what I get for having coffee and chips for dinner (and in short; there's no free tools to use it, and the Linux driver uses binary blobs - of course).
Today I filled out the rect fill code a bit and tried various implementations, including some NEON variants. Oh, I also `discovered' the performance counting unit - wow, you can track a lot of stuff, from branches taken to cache and memory stats to stalls. Very nice.
Oh NEON. Fucking hell. Spent about 4 hours tracking down why the NEON instructions just threw an undefined instruction exception. After a couple of hours of digging I came across a reference to the Coprocessor Access Control Register, but that didn't really help (oh and a thread on the beagleboard group where people just say to turn CONFIG_NEON to y ... sigh). So here I was trying to turn on clocks and power and other PRCM registers ... and then I remembered something about a bit in a status register to enable/disable the whole shebang. A bit more tracking down (i've got about nearly 10K pages of documentation to search now) and I discovered the FPEXC register and VMSR/VMRS instructions (my memory was wrong, but it was a lucky guess). Although the binutils i'm using doesn't support them ... sigh. Finally found a workaround using MRC/MCR from Linux - about the only thing i've managed to find in there when tracking things down (a lot of stuff is so abstracted it it's very hard to follow). Gee that was frustrating.
Anyway, so I came up with some total cycle counts for various implementations of a 'rectangular block colour fill for RGB565'.
These are all with *NO CACHE* or write buffers, so they don't really mean anything other than relative to each other. You have to turn the MMU on to turn on data caches and write buffers, perhaps that is the next thing to try.
Code Total Slowest Fastest
C short 36308222 1.00 5.25
C long 18307488 0.50 2.64
ARM asm 15877960 0.43 2.29 - uses 4x strd (writes 8 bytes/instruction)
NEON 9735680 0.26 1.40 - uses 2x writes of 2xD regs, 64 bit aligned
NEON2 9134690 0.25 1.32 - uses 1x write of 4xD regs, 64 bit aligned
NEON3 9311284 0.25 1.34 - uses 2x writes of 4xD regs, 128 bit aligned
NEON4 9191652 0.25 1.33 - uses vstm of 8xD regs
sDMA 6910682 0.19 1.00
The NEON implementations use ARM code for the non-aligned 'edges', and none of them are particularly fantastic code.
Hrm, I thought the ARM asm one was ok when I was running it by itself, i guess twice as fast as something is quite noticeable, but obviously it's kind of slow.
Looking in more detail at a couple of them:
drawRect() C long
total cycles=18307488
dwrite intns=169668
ext writes =169671
iexec =701230
istall =1201453
drawRect() ARM asm
total cycles=15877960
dwrite intns=168963
ext writes =168965
iexec =310508
istall =182922
The C version executes 2x as many instructions but the execution time isn't much different - everything is waiting on memory (although I wonder if it uses less power). At first I thought the total cycle count was a mistake, but of course, it's taking about 100x longer than the number of instructions executing, so memory accesses must be around 100 cycles -- which sounds about right. Be interesting to see if any cache/write buffers make a noticeable difference here, although it is just a flood of writes.
Update: Should've tested more, the long version was still just a 'short' version, it just wrote half the width ... so all bogus. Will revisit in a newer post.
The code in question is all in puppy bits:
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!