About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

It's funny 'cause it's true ...
From a little while ago, but I just flipped threw a few weeks worth of xkcd the other day and came across it.
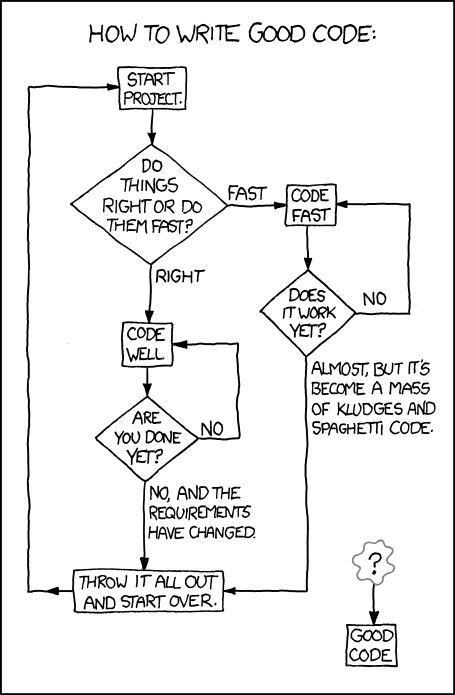
When I was doing engineering at uni we talked about the reams of documentation and being able to pre-define the problem to such a degree that the coding itself would be an afterthought. A mere bullet-point to be performed by lowly trained knuckle dragging code monkeys somewhere between finalising the design and testing. Of course, this was proven to be immediately impractical during our final year project - and that was about the last time I ever saw an SDD. In one job I had we started with lofty goals of fully documenting it using references SRS and SDD's and the like but in the end we just ended up with piles of junk. They were complete, and even sometimes up to date but ultimately useless - they didn't add any value.
In reality of course there are many impediments to such an approach:
- The customer doesn't know what they ultimately want. Ever.
- New ideas come along which change or add requirements.
- You don't know the best way to solve a problem without trying it.
- You don't know where to even start solving problems without plenty of experience.
- The market or other outside circumstances force a change.
- That just isn't how the brain works - you continue to learn every second of every day and that changes how you would solve problems or present them.
- It's slow and too expensive for anyone who has to earn money and not just ask for it (i.e. outside of defence, govt).
Although contracts are still written this way, and documentation is still a phone-book sized deliverable in military software. And computer engineering academia are still trying to turn what is essentially an art, into a science. I don't think their efforts are completely worthless (at least not all of them), but I think software is too complex for this at this stage and only getting more complex.
It's not that development documentation isn't useful - I wouldn't mind a good SRS myself - but there needs to be a happy medium.
Back to the flow-chart - which to me has a deeper meta-meaning even by being a flow-chart. The software engineering lecturers scoffed at flow-charts as being obsolete and out of date - yet they seem to be more useful than anything they claimed replaced it.
Personally I try to do it right but sometimes do it fast - because ultimately you always end up having to refresh a significant chunk of the code-base when the customer reveals what they really wanted from the start. Fortunately when i'm in the groove (say 30% of the time?) I can hack so fast and well (not to put tickets on myself, but i can) the line is a bit blurred - writing and (re)-re-factoring gobs of code on the fly as the design almost anneals itself into a workable solution. Pity I can't do that all the time.
Extra effort is usually is worth it, but not always. And sometimes the knack is just knowing when you get get away with taking short-cuts. For isolated code at the tail-end of the call-graph it usually makes little difference so long as it works.
If you throw the front-end away and start from scratch and you have some well designed code underneath, you can usually re-use most of it. Crappy code is much harder to re-use. But in the earlier stages of a project doing it right can be more of a hindrance. Particularly with OO languages - which force you to create good data models to fit the problem - which means even a small change to the problem can be a big change to the data model. Of course, many coders never achieve good data models, so perhaps for them the cost isn't so high - at the cost of perpetually low quality code. Yes I say data, not code - the data is always more important.
Annealing is probably a good way to describe software design and maturity process - early stages punctuated by large fluid changes due to high-energy experimentation then and over time the changes becoming smaller as it matures and solidifies. If the requirements change you have to put it back into the fire to liquefy the structure and reconsider how it fits in the new solution.
Simply bolting on new bits will only create an ugly and brittle solution.
Why not -1 button?
So apparently google have added a +1 button to the search results. Why not a -1? I'm not sure exactly what this is supposed to achieve - yet more ways for spammers to skew the results? I'm already a bit wary of google giving me my own private view of the internet, I hardly want that increased. And often what you're trying to find is the stuff that doesn't come up on the front page now - it seems this would only make that worse.
Just more clutter I don't need or want which simply slows down the page loading.
They also seem to have fucked up the mail client by making a section of the screen not scroll. Which makes it unusably slow and even uglier than it's already ugly forebear. So I guess I will have to go to basic HTML mode now. Which is a pity because I use the chat thing to find out when drinks are on.
Stuff
Been pretty lazy this week - I seemed to spend too much time reading a few sites I frequent from time to time, mostly about the GFC and some of the local political-media clown-show (they are no longer separate entities). But the picture they paint of the world is pretty bleak so it's really all just a bit of a downer; although i'm not sure if it's just the reading that gets me down or feeling a bit flat in the first place that tends to drive me toward reading it.
So no spare-time hacking this week. I did however prune back the golden rain tree in the back yard yesterday - and given we had a couple of days of sunlight I even got a little red in the face. Always nice to get some sunshine in the middle of winter even when such days are few and far between. I also made that lime cordial last week.
For work i'm hitting some big performance problems on the target platform - partly because I think the customer has some unrealistic expectations, and partly because I didn't do enough research at the time on card performance, or they just weren't up to scratch. Oh well. I presume it's something to do with the EOFY purchase dash as well but buying new hardware has come up as a possible solution. Fortunately things have moved a bit since then so at least buying new hardware should be a big help although it wont solve everything.
I'm also pushing for AMD hardware this time - although the Nvidia hardware has been ok as far as that goes, they've obviously given up on OpenCL (no released 1.1 driver, and their opencl 'zone' hasn't changed in a year) and it doesn't seem like a company that wants my money or deserves any support (even the forums are pretty quiet so it seems i'm not alone - we all get the hint). Expanding ones experience and educating yourself about the alternatives is always a good thing too.
By coincidence AMD just had some marketing event about their heterogeneous computing plans, and Anandtech has a really interesting article on where AMD are going with their GPU/CPU architecture. Looks quite promising, although i'd really like to see a bump in local-store size. Although there is certainly enough there to be useful it is still a bottleneck, and with even more parallelism possible due to the design, the limited global bandwidth will only become more of a bottleneck.
Pity it's still a way off, because a change in architecture of that magnitude will require a different approach for performance, although in general it looks like it will be easier and it will also map well to OpenCL.
Lazerimagez
So I needed a bit of a break from work and other stuff I was working on so I've revisited ImageZ in my spare time over the last week or so. I'm contemplating cleaning it up a little and putting it somewhere other than my own hard drive - it's well and truly alpha-quality but maybe it can go beyond that.
I decided trying to have a global tool context was just never going to work, so I've moved them to being per-image. And now I'm in the midst of redoing the drawing tool - recognising that the only thing that changes with the pen types is what it draws at each paint position. So i've made an interface that creates pens on the fly using shape, dimensions, colour, and fill type. Still not sure where i'll end up with this but it seems a more promising direction.
And as also can be seen, I thought it needed a bit more colour ...
I'd forgotten how much I actually had working quite well - layers of different data types (8 bit, 16 bit, float, grey-scale or RGB), infinite undo, compound selections, and a nice save dialogue. Although there are also some pretty broken parts - all blend modes apart from Normal (I changed the alpha model and haven't updated them), image operations, and being able to load and save multi-layered images (that's a bit of a show-stopper). I know one reason I didn't get far on the latter was that there is no native support for loading/saving float format images.
Unfortunately the rest of the household is all croaking from some illness and I feel like i'm headed toward a bit of man-flu, so this weekend will be a slow one I think.
The Player
Not really worth a screen-shot but I kept poking away at the player code and added some seek support. I've got it working pretty well on 'well-behaved' files, although it isn't nearly robust enough for 'general use'.
I then got totally side-tracked and started working on a Linux DVB interface. I just cut & pasted some of the jjmpeg binding code, and created a new shared library and namespace within the jjmpeg project. The task of binding the ioctl interface doesn't really match that of binding libavcodec but using the same mechanism should suffice. Not sure jjdvb is a great namespace either, but then again it will do. Now I just have to drag some coax across the room to the PC to test it, or try it on another machine ...
As an aside, with all this hacking of late I haven't been doing much else, although at least I got out and mowed the lawn today for the first time in 3 weeks. And fortunately caught some of the very brief sunlight. Also swept the leaves up and turned the compost heap over. But I didn't get to making the lime cordial I had planned to, although I prepared the bottles to keep it in.
(Today was a public holiday, and with Friday off too that was one long weekend of hacking - I think I need a day off!).
The Wall
Just for fun I tried throwing a bunch of videos into one window simultaneously.

And yes, the sound plays ... although it is quite disconcerting and disorienting having all 9 play at once ...
The sources are PAL-format digital recordings transcoded to x264, i'm scaling them using libswscale and then simply using swing labels to display them. It's clocking up between 100% and 150% CPU usage on the java process (100% == 1 core on Linux). So even though i'm hardly trying to make it quick it's hardly taxing the box (albeit a very fast box).
For some reason the timing code gets messed up if I try to sync to the audio timestamp, but that might just be these videos.
Video Player
So this weekend I wrote a video player using jjmpeg. Yesterday I had the basic video working, and today I got sound working - using OpenAL (JOAL) for output. For the most part even using a fairly simple synchronisation mechanism it works fairly well. I'm letting the hardware run the sound at it's native rate, and synchronising the video to the timestamps in the file (using Thread.sleep() no less!) - not perfect but it's a start.I also uploaded a new jjmpegdemo's directory to the jjmpeg project which includes a simple audio player that I used to work out OpenAL.
But the Video player is a bit more complex, I've currently got 1 thread demuxing the input, 1 thread each for video or audio stream decoding, and another thread to synchronise the audio and video. I use some of the nice classes from java.util.concurrent to handle the packet and frame queues which means each bit of code is pretty simple. I'm recycling the AVPacket's, the frames and audio sample buffers so once started it has a pretty low GC load.
I'm having some strange problems though - certain files seem to throw the demuxer right out - I get massive corruption in video and audio and it's getting completely broken data frames. These files play just fine in the AudioPlayer above, so I presume i'm doing something incorrect with my threading which is corrupting something along the way. Other files work just fine though so it doesn't seem to be just a simple problem with invalid code - it also affects different containers and codecs inconsistently. Just the sort of bugs I like ...
Update It seems I had too many threads. I've moved calling the codecs from their own thread to the demux thread. Then I have 2 threads for rendering the audio and video separately instead.
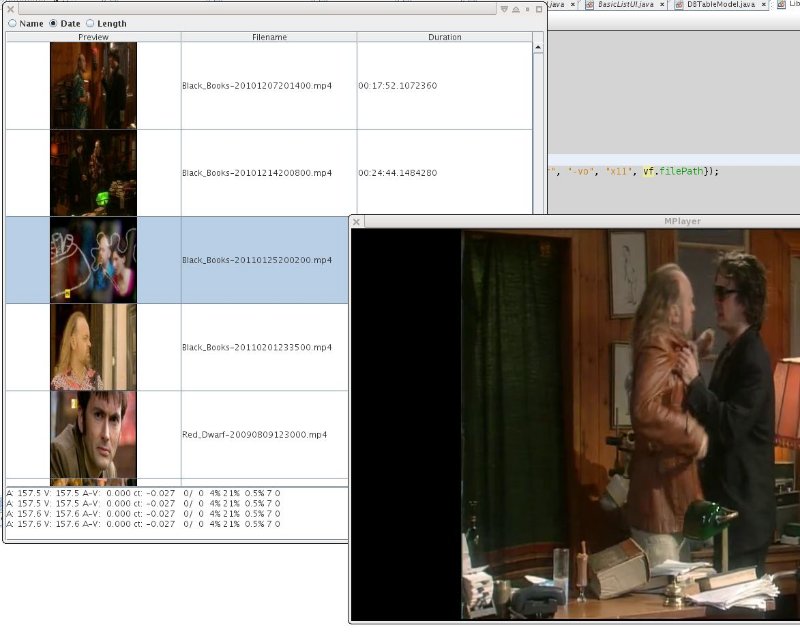
Video List
So one thing i've been mucking about with using jjmpeg for is creating a GUI for listing videos ... which seems a pretty basic starting point for doing anything further.
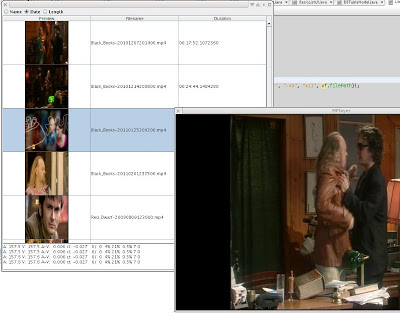
Yeah it's not much to look at so far but one has to start somewhere. I might look at using Piccolo2d as the rendering surface, although I have to determine how to handle virtual items as I do here with the JList. Apart from general fugliness it flashes white whenever you change the view sort, which is quite unpleasant. As can be seen, I hooked it up to mplayer after you double-click a row, just for a laff ...
Under the bonnet it uses jjmpeg of course to scan the files - it's currently generating 128x128 preview images at 1 minute intervals - of which only the first is shown. I have a separate tool to `import' the videos for the moment but I have code lying about to allow dropping of files, so it wont be hard to add. I'm using Berkeley DB - java edition to hold the meta-data and preview images, and i've hooked it up so the DB is scanned in another thread. I use different secondary indices for each sorted view so they are all just as fast (slow?) as each other - this will also let me query by keyword with a little more code. I'm also using SoftReferences to implement a cache of database items. Unfortunately Berkeley DB JE doesn't let you query by record number like the C version, nor read the secondary database keys without also dereferencing to the primary database (i.e. slower than might otherwise be), but judicious use of threads can help alleviate such issues.
In short: it should scale quite well.
Probably ...
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!