About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Masked Loops & LU Decomposition
Update 26/11/11: So it turns out the timing is completely bogus because the code not only had a typo in it - which probably allowed the loop to be optimised away - the algorithm was incorrect as well. So I have a feeling this is all just wrong now ... That's what I get for timing without validating first.
I have since re-coded this algorithm, and I think I have something that works. I resorted to building a code generator and manually unrolling all the loops using branchless code. For 4096 6x6 matrices it takes 28uS to perform the LU decomposition (they're the same matrix again).
Also see a follow-up on the LU decomposition problem.
I've been having trouble getting some code going for work so I thought i'd have a 'break' and visit porting some of the bits and pieces to OpenCL.
The LU decomposition seemed obvious.
Not because I really intended to use it, I thought i'd just try an almost direct translation to OpenCL to start with. All I did was have each thread work on a full solution independently. I used local memory for the column cache, but that was about it.
Fairly impressed - even disregarding all possible optimisations and memory issues, it only took 220uS (4096, 6x6 matrices). It can no doubt be made to run faster, but I was so surprised I almost considered just leaving it at that - relative to the other operations it is 'fast enough' ... but of course I didn't. (I was also solving the same matrix copied 4096 times, so it was 'best case' wrt thread divergence). I guess it isn't really so surprising though - apart from the poor memory access pattern the code path is consistent across threads.
I did a bit more work the serial version before tackling the parallel: e.g. by copying the whole matrix to LS first, and telling the compiler to unroll the loops I got it down to 118uS.
Anyway, along the way to parallising this I came across an interesting and not entirely obvious optimisation. It was to use the sort of result-masking you need when vectorising algorithms, but just for a simple loop.
Part of one inner loop the algorithm has this construct:
#define m 6
#define n 6
int kmax = min(i, j);
float s = 0.0f;
for (int k = 0; k < kmax ; k++) {
s += LU[i*n+k] * LU[k*n+j];
}
LU[i*n+j] = LU[i*n+j] -=s;
In this case, 6 threads working together on this problem and each are working on 1 row each. The i index is thus the matrix-local work-item, and j is the current column.
The problem with this code is the loop indexing is unknown at compile time, so the address calculations need to be done on the fly and the loop can't be unrolled very efficiently. And although the compiler could do what I do below, it seems a bridge too far at present.
So I changed the loop to this:
int kmax = min(i, j);
float s = 0.0f;
for (int k = 0; k < n ; k++) {
float v = LU[i*n+k] * LU[k*n+j];
s += k < kmax ? v : 0;
}
LU[i*n+j] = LU[i*n+j] -=s;
And even though it appears to be doing more work - things just don't work like that on a GPU. Each 'thread' is still executing all parts of all loops anyway (or at best, sitting idle waiting for the longest running one to finish).
This simple change lead to a 25% improvement in the overall execution time in my test case.
My 'final' code executes in 38uS (I haven't verified it works! So this number might be nonsense!). And I still have further to go - the way I access memory isn't coalesced, I also have a lot of local-store bank conflicts to nut out.
So, assuming the code works, maybe that original 220uS wasn't so hot afterall.
Fixing what isn't really broken.
Blah, so Google have decided they're going to mess up another of their products for me.
I've already stopped using the web interface to gmail - I just use pop and thunderbird - and now they're playing with blogger.
Blogger's existing interface is pretty crap - but it's simple and it's fast and easy to use. But the 'improvements' hardly seem improvements to me.
Harder
First, the composer. About the only 'good' thing is that the editing area is bigger - not much difference to me - and that it is a fixed size - that's the nicest bit.
But it's now more difficult to attach labels to posts as you need to click on the labels tab first - it seems like a simple thing, but the old interface is very simple if you use a few common labels most of the time. The post options 'pane' in general is pretty pants, it somehow manages to take up about 4x as much space as the previous one while only showing 1/4 as much information at a time.
They've broken the 'preview' feature - ok, it was always fairly broken - but now it's a full stylised preview which takes quite a while to load on a separate page/tab. The old in-line quick preview was much more useful to me than the full preview just to review the content of the text when proof-reading and editing and trying to get the paragraph white-space right. What used to take no time now takes a second and a tab switch.
Bigger
The stats pages now no longer fit in my browser, and they seem to take longer to load. Too many annoying tooltips and popups as well.
The settings/dashboard is weird in general - everything is double-spaced, and a huge chunk of the top of the window is dedicated to a fixed area that doesn't really add anything useful by being fixed. For some reason people seem to love this kind of crap but it just gives me the shits.
For me blogger is just another tab of dozens - not a stand-alone full-screen application. Everyone seems to want to move away from being able to put stuff in a window which doesn't take up the whole screen - you know, to multi-task?
Apple had a reason to force full-screen applications - first in macos which had a shit multi-tasking system, and then on iphone/itab since the machines aren't that powerful. Microsoft did the same with windows - the OS was really just a glorified application switcher. But I thought those days were long gone ...
Slower & Hotter
One reason I dropped gmail is that it was starting to make my laptop hot - firefox was busy all the time doing pointless shit you couldn't see or would rather not. It will be interesting to see if this new interface on blogger is also heavier than the old one. Whilst typing this post i've already noticed a bunch of pauses and freezes which I can't recall having occured in the previous incarnation.
This could be a real deal-breaker for me, although the stats are fun to watch, by far the most time I ever use in blogger is simply writing blog posts. If that becomes too painful (and I have to say, 1/2 a second cursor pause every 20 seconds gets tiring VERY VERY fast) then I wont be too pleased. The pause seems to get longer the more you write too ...
For now i'll go back to the old blogger, and I provided some feedback, for what little that will be worth. But I know eventually i'll be forced onto something I don't really want.
(this sort of forced-upgrade stuff is the sort of thing that scares me about firefox's 'no version' plans. I'm still using an 'old' firefox because the new ones are not to my liking, and in any event aren't packaged for my distro - but at least I can use an old version if I so want).
Update And in a further twist, the 'no i'd rather go back to the old interface' feedback form failed to work.
Java 2D arrays
I had to find a bit of code to solve a set of simultaneous equations for some prototype code i'm working on.
Having to do this gives me the willies really because linear algebra was never much fun for me ...
I only have to solve a pretty simple system - 6x6 - and I settled on using Jama, mostly because it's a small and simple library. The code is also fairly clean and I need to eventually port this to OpenCL too.
The code uses 2-D arrays to store it's matrices, but I know 2-D matrices in Java aren't particularly efficient - they are implemented much the way you would do it in C. That is an array of pointers which point to the rows of the array. Thus every 2D access requires 2 array dereferences. Anyway as I need to port it to OpenCL eventually anyway I tried converting the Matrix and LUDecomposition classes to use linear arrays. Then I just use simple arithmetic to map 2-D indices onto this linear array (i.e. i*n + j).
I got pretty much exactly a 2x performance boost from this simple change. Which is in-line with what I expected but I didn't quite expect it to be so close to 2x. The memory accesses far out-weigh any arithmetic on a modern CPU, and since 2-D arrays require 2x as many memory accesses (and 2x the range checks i presume), halving the memory accesses required lead to a 2x speed up. Even though the twin-array access was replaced by the more complex multiply and an addition as the index calculation.
Jama is wildly out of date, and I didn't look at the alternatives which might focus more on performance, but it shows that at least in this case 2-D arrays come at quite a cost.
Not really looking forward to getting it working in OpenCL either, trying to parallelise it is going to be a bit of a hassle. Then again maybe the challenge will be refreshing - I need something to spark me up at the moment.
This whole chunk of work is getting me down a bit - I have a big pile of hard to decipher ('matlabotomised') code to convert before I even get something to test, and then I have to try to remove some of the matlabisms that don't make sense in a real language, or require unnecessary excess memory. Then I have to get it working. And once that's done I have to re-do it all again from Java to OpenCL and get that working ... but i'm just not into it these last few weeks. Lack of sleep mostly (I keep waking at sun-up, I really must exercise), but also some other distractions - a few days of nice weather, family visiting, and so on.
This is also why I haven't had time to work on any of the other projects - I just don't have the energy. Lawn is looking good though.
The problem with teaching abstractions
For want of distraction, I've been hanging around some of the OpenCL forums of late. Boy do they get some ninny questions.
From people trying to drop plain C (with full stdio and all) into the compiler and expecting it to work, to someone asking if you can 'write functions' in the host language ... (err, I mean seriously. Maybe the guy is a matlab guru but certainly it isn't that hard to find out about C or whatever host language he's using).
But those are just the most extreme in the last couple of days. What is more worrying is just how many people don't seem to understand computer architecture at all - much less a system containing a 'remote' processing device like a GPU.
Really basic things like cache, registers, stack, memory latency, memory banks & contention, I/O bus latency, call invocation overheads, and so on. Not to mention the less-obvious but not really more complex ideas that GPU's bring to the table such as memory coalescing, thread divergence/masking (i.e. SIMT branches), local memory, and so on.
Also, a rough idea of just how fucking fast modern hardware is.
I presume most of the queries are from students but they just seem to have absolutely NFI what is going on 'under the bonnet' on their shiny new bit of hardware. e.g. the reason your code is slower on a GPU should be bleedingly obvious before you went anywhere near a compiler.
Before trying to work with such a complex system, you really need to know some basics of computer system architecture - otherwise none of the api will make any sense, nor will any of the results.
The manuals are good: just read them.
Experiment on your own; it's easy, it's fast, it's cheap (it only takes your time, and a student's time isn't worth anything). You don't learn any-where near as much if you just copy someone else, or forever ask inane questions.
Visual Selections
After hitting the bottle with a couple of mates last night I ended up sleeping on the couch (too lazy to make my bed after washing the sheets), woke up about 6:30 feeling a bit ordinary but I thought i'd get some hacking out of the way because I was awake and couldn't really face too much else.
I continued to work on removing the Piccolo2D stuff - which I completed. Now i'm just using plain Java2D for the rendering. Of course, one of the big reasons I did it was so I could zoom without making the handles scale as well ... and of course I forgot to implement that so it all zooms anyway. No biggy ... at least it seems to work. And it should be relatively simple to implement it.
I still need quite a bit of code to implement interesting interface behaviour ... but at least it is no worse than the Piccolo2D stuff was before it.
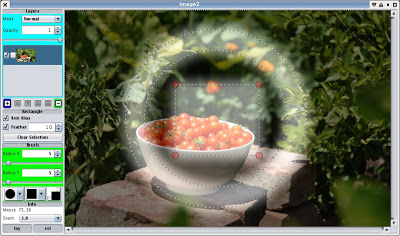
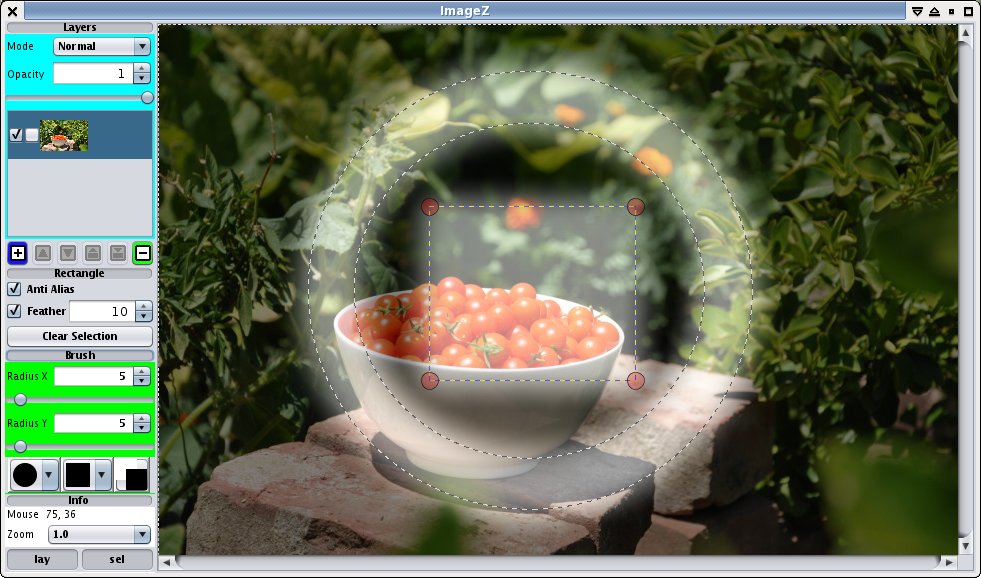
As part of that I visited the selection code. Some time ago I had the idea of being able to show the current selection using a shadow mask - including the current 'feathering' and so on. So I added that - all 4 lines of code required for that. Well I think it looks pretty cool, and if you have a fast machine it updates in real-time as you edit the selection even though it uses a Gaussian blur for the feathering.
Update: Since I think there's now enough functionality to move it beyond the simply embarrassing stage, I've packaged the first public alpha release too. See the downloads page on the project, but don't expect too much.
Crop Tool
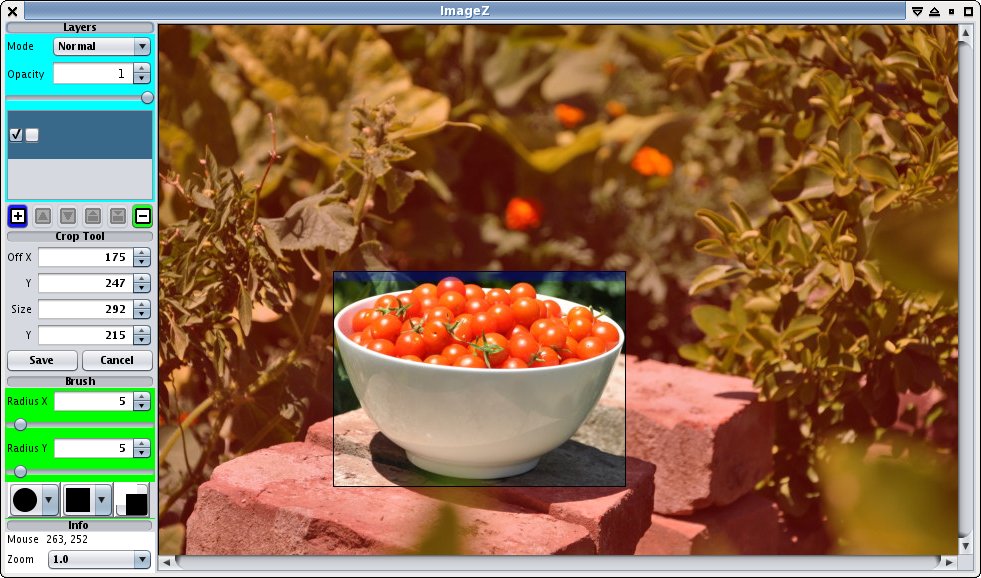
I had a few hours to play with this morning and I had another look at the crop tool for ImageZ.
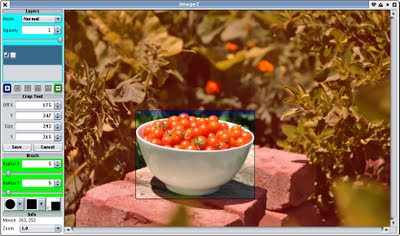
It lets you change the top/left/bottom/right edge with the pre-lit 'handles', or drag the whole rectangle around clicking inside the box. Clicks outside of the box let you drag to select a new bound. So pretty simple/obvious interface, although I couldn't be bothered implementing the corner handles.
So I had previously decided that Piccolo2D just doesn't quite fit this application - the need to have user-interface elements which don't scale with the zoom setting was the deal-breaker. Current code that uses it has some very messy mechanisms to make it work - sometimes.
The new stuff just uses some custom objects and Java2D to do the rendering and a very flat/simple 'scene graph'. So far I haven't even added any sort of optimised rendering although I probably will need to. Although right now it is fast most of the time (not so much when zoomed - but that was the same for the piccolo2d stuff too).
I also played with a slightly different event model - currently the current tool gets mouse events, but I decided rather than have the tool manage events of control-handles they can do it themselves. It wasn't much extra code to implement the event routing in the imageview class.
I think there's still a bit more work for the tool design before i think i'll be finished with it, but at least it feels i'm moving forwards with it. I will keep an eye on this as I discover what works and what doesn't and eventually clean it all up to a consistent and hopefully simple interface.
Probably the next thing to look at will be improving the brush mechanics though, or maybe fixing the super-affine tool - perhaps with that I will have enough to drop a jar.
Another one bites the dust ...
Mum just called to let me know another one of my brothers has died. It wasn't a surprise - he was literally on his death-bead a few times last year and despite numerous health problems continued to smoke and drink. Add to that a misspent youth of drug abuse and kleptomania and who knows what else, and it was pretty much a foregone conclusion. It's surprising perhaps that he even made it to his early 50's in the first place.
Barely knew him myself - he disappeared for about 10 years in the mid 80s, finally turning up in Perth as a lawyer (which was surprising given his past). I think he always blamed mum for pushing him to get a trade rather than follow educational prospects, but I think he must've fried his brain so much he forgot what a dope-head he was at the time. Then again, I was a bit too young at the time to really grok what was going on. Then he more or less circumnavigated the whole country in the years following, having a son with his girlfriend along the way.
Seems the census collector found him when she returned to pick up the census form (his gf left him a couple of years ago, apparently to futilely chase some young bloke). Given that the collector (probably) dropped it off a week earlier and it wasn't touched, he may have died some time before that. Bit sad I suppose. And it's not like this was in the city either, it was a country town. Nothing like a bit of community cohesion! On ya Australia!
2 down, 7 to go ...
Still, even if it wasn't unexpected and I barely knew him, death of a sibling is still a strange thing to experience, even the second time around.
GEGL/OpenCL
So apparently a lad's been working on getting some OpenCL code into GEGL. What surprises me is just how slow the result is - and how slow GEGL is at doing the super-simple operation of brightness/contrast even with a CPU.
Of course, I'm not sure exactly what is being timed here, so perhaps it's timing a lot more than just the mathematics. Well obviously it has to be, my ageing Pentium-M laptop can do a 1024x1024xRGBA/FLOAT brightness/contrast in about 70ms with simple single-threaded Java code. So 500ms for the same operation using 'optimised sse2' is including a hell of a lot of extra stuff beyond the maths. Curiously, the screenshot of the profiler shows 840 'tiles' have been processed, if they are 128x64 as suggested then that is 6MP, not 1MP as stated in the post - in that case 500ms isn't so bad (it isn't great either, but at least it's in the same order).
I tried posting this to the forum linked to this phoronix post but for whatever reason it refused to take the post, so i'll post it here instead.
This result is really slow. Like about 100x off if I have the relative performance of that gpu correct. Even the CPU timings look suspect - is GEGL really that slow?
A list of potential bottlenecks:
- the locking stuff sounds overly complex, but maybe that's a gegl requirement
- are you timing 1-off allocations which skew the results?
- moving single tiles back/and forth/processing them separately (this is a big one)
- processing only a single tile per kernel call (this is a really big no-no)
- might want to specify the local work-size to ensure the best memory access pattern on the opencl side. 16x16 usually works well for image processes per pixel on a gpu.
- PCI latency, related to working with small blobs of data at a time. This can be completely hidden fairly easily by queueing up more jobs before a synchronisation point (either a clFinish or EnqueueReadBuffer(, true). Also you need to do a clFlush if you want the work to start while the cpu is still doing something (e.g. queuing up more work).
- GEGL design. I know nothing about it, but if you need to go to the CPU to do synchronisation between each composed operation you may never achieve very good performance. Ideally you upload data once to the gpu, then do all processing without any cpu synchronisation until the final result is ready. By default an opencl command-queue is in-order (and no implementation support out of order anyway), so you leverage that as well. If GEGL can't already handle threads to do a similar parallelisation it might not be ready for opencl either.
- GEGL itself. Since the GEGL CPU timings are so slow (i mean, really really slow) GEGL must be doing a lot more behind the scenes/adding so much overhead that the actual calculations are completely swamped. If this is 'fixed', then no matter what you do, such processing will always be relatively slow, although as the complexity of the algorithm increases this fixed overhead will matter less.
A list of things which can't be bottlenecks:
- PCI bandwidth. It's just not enough data to matter.
- OpenCL kernel - maybe it can be improved with a better work-group-size, but it's so simple it can't really be wrong.
Suggestions
- My gut feeling is that you ignore tiles completely on the opencl backend. Even doing manual cpu-side composition of tiles into aggregate will be fairly cheap compared to synchronous transfers/operations. Composing operations complicate matters though ...
- Don't try to hide too much detail with abstractions. It usually just makes it harder to know what's really going on (particularly for another coder).
- Don't worry too much about comparing such a simple operation with the CPU. The CPU should already be able to do it at about memory speed, and you're adding PCI copies in-between. It's the more interesting stuff like convolution or FFT-based algorithms where the GPU will blow it completely out of the water.
- Think of the GPU processor as a 'stream' processor. You want to load it up with a pipeline of operations and keep the pipe stuffed with work. Waiting for the pipeline to empty before adding more work will kill performance faster than anything else. This applies at every level - the individual threads, SM's, as well as data blocks.
- Might need to do some profiling of the CPU GEGL brightness/contrast implementation. Something other than the actual calculations is taking most of the time.
In the nvidia profiler, look at the 'gpu time width plot' to see when the gpu is actually doing work. You'll probably see the individual jobs (and memory transfers) take almost no time and it's mostly sitting idle waiting for work from the cpu. It's that idle time which is going to be 99% of the elapsed time which is where you find all the gains at this point.
Don't even bother looking at the graph you posted - memory transfer time will have to be greater than the processing time since the processing is so simple and the gpu memory bandwidth is so much higher than pci speed. All you're doing is confirming that fact. The memory transfer time can mostly be hidden using asynchronous programming techniques anyway, so it is basically irrelevant.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!