About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Special-Case Code and Multi-Pass Algorithms
Ok, so without going into too much detail I have a function which needs to resample 3 float2 planes of data to another resolution, and then perform very simple arithmetic on it (a few mult, add). The scale factors are powers of two up and down. One complication is that the numbers have to be pre-sampled first at pixel corners before being interpolated.
I implemented it initially using bilinear interpolation for simplicity, and yesterday looked at implementing bicubic filtering.
It wasn't really that bad - the given routine was about 1.5x the original speed which is ok, and overall this was only a 3% impact.
But I thought I would try a few ideas to speed it up ...
A) I separated the routine into separate implementations, one for each scale. I still used the same sampling routine, but just passed it a fixed-value for the scale. In previous micro-benchmarks on the bilinear code I noticed this lead to a pretty decent improvement.
But in this case it didn't. It slowed down some scales by a factor of 1-2, and moreover, made other routines in the same source file execute slower(!). I can only assume the growth in code-size was a significant factor here. I also noticed the register usage hit 63 again - which probably means all i've done is hit a bug in the compiler again (I should really upgrade the driver: we're moving to AMD hardware RSN anyway).
B) Using two passes. A separate scale pass followed by a calculation pass. Intuitively this should be somewhat slower: the calculation after the scaling is simple and can be done in registers.
But of course it turned out faster. Not a huge amount, about 20% for the routine in question.
I did have to do some work to make it happen though: using local memory and 2d workgroup sizes, and separate code for the scaling down functions (e.g. it just sums 2x2 block to go down by 2). In this case using separate functions for each size worked quite well (more evidence of compiler bugs). I was also able to batch the 3 planes separately to get added parallelism - the problem size is quite small so this should hep.
... and after writing (C) below I re-arranged the upscaler to use hard-coded sizes as well, and re-did the bicubic interpolator to accept integer and offset values separately: the compiler can remove some of the calculations here since i'm always using the same pixel offsets.
... and i also experimented with changing the output type to float8 rather than float2 and writing 4 pixels at once for the 4x upscale. This was 2x faster again for this routine (and uses fewer registers?), although I can't trust this number as the results are now broken (and i really have had about enough of it and don't want to debug it).
C) Doing more at once. e.g. doing 1/2, 1, and 2x at the same time. Actually because the 2x scale uses hard-coded interpolation numbers the bicubic interpolation can be simplified greatly (that just gave me an idea to improve B) above).
I didn't get this incorporated because it required a bit of re-arrangement of the host code, but this could shave off a bit more. I usually need a few scales of the same data in each pass so this would be useful.
Conclusions
Although all these could also be applied to the bilinear code, I now (with the changes in B above) have bicubic interpolation for this routine running much the same speed as the original bilinear did.
But it shows that you sometimes don't want to do too much in a given routine - compiler bugs, register spillage, or just more registers end up being used, which adversely affect parallelism and performance. Although a trip to memory is quite costly, these other factors can greatly outweigh it.
After all this, and a few more changes in this particular routine i'm working on, I only managed about a 9% improvement. TBH i'm not sure it's really worth it ... and I probably only went so far as I had a bit of time between getting this to a working state and heading back to reading papers.
Awesome-ease Chicken
Been a while since i shared a recipe, and i've been making some variation of this fairly regularly of late ... This is a sort of kitchen-friendly variation on Portuguese Chicken done in an oven. And it's super-shit-easy to make. I used to make it on a BBQ but this is probably nicer to eat and easier to cook properly.
PS I admit i've had a couple of very lovely glasses of Church Block '07 and came up with the utterly-naff name which i've never used before. It's just a super-tasty roast chicken.
1. Cut chicken
Start by cutting a chicken up the breast-bone.

2. Prepare pan
Place a handful of (freshly picked of course) thyme in the middle of a suitably sized dish/oven-proof frying pan.

3. Mount the fowl
Push down on the back of the chicken to flatten it out - you should hear bones/joints breaking - if you're picky you can also break out the rib-bones at this point to make it easier to eat - and then place it over the thyme. I also poked it over with a fork to help the seasoning in and the fat out.

4. Seasoning, Lemon & Salt
Cover with the juice of one (small) lemon, and if you have it, about a 2 teaspoons of Asian 'chicken seasoning' - this is about 1/2 salt, with some flour, MSG, onion and stock powder mixed in. A good teaspoon of vegetta powdered stock, or simply salt and some pepper would suffice.

5. Seasoning, Herbs
Cover with broken fresh herbs (e.g. sage) and sliced ripe chillies. I also sometimes add a few thin slices of ripe tomato at this point, but my tomato plants are still growing this early in the season ...

6. Cook It
Being flat, it cooks a bit faster even at the normal 180C. I usually baste it a couple of times as well to bring out some colour, and when it looks cooked it usually is. This small fowl was an hour in a pre-heated oven - about 45-50 minutes/kilo rather than 60. I also upped the temperature for the last 15 minutes, but one has to be careful not to burn the herbs too much.

7. Eat It
Because the chicken is laid down flat it traps the steam inside and cooks from both the inside and outside at the same time (i'm sure the black pan helps). This cooks it faster and keeps it very moist. And with the skin upwards it crisps up nicely and builds up a strong flavour.
It scales in the obvious way to larger fowl - I've cooked up to size 20 chickens this way.
Wavelet Denoise & Sharpen
So I had some luck with a bit of fiddling with the scaling function for wavelet sharpening. And managed to get both sharpening and smoothing working at the same time. I'm fairly happy with the results.Update: see also a further post on using the DCT in a similar way.Update: I've now implemented a version of this in ImageZ, see the follow-on post
Ok, first the raw Lenna input image I used - converted to greyscale by Java2D. Just to make comparison easier and to add another pretty face to the page.

Now, with the sharpening ramped right up. As you can see it's pretty much the same as using unsharp-mask with a well-selected radius and a medium weight. And like unsharp mask it tends to emphasise any noise.

Unsharp mask/Wiener Deconvolution can still work better if the image is simply de-focussed as they have a PSF function to estimate the amount of defocusing.
Now, with the same settings, and also de-noised very heavily. Despite the obvious and unnatural looking heavy processing the edge sharpness and most of the detail is still retained rather well. Most added artefacts are relatively smooth and natural looking too. If you've ever tried using a median filter or a selective Gaussian blur, you'd know they pretty much suck at retaining any texture detail or clean edges.

And finally, a more natural level of sharpening and de-noising.

Pretty happy with it given how simple the maths is. I've over-emphasised some of the results by using high values, but a smooth variation in results between the original and any of the extreme values is possible.
Two steps are applied to each complex coefficient in turn in a way that can be done whilst the coefficients are in registers. So if you have other processing going on it's essentially free.
- Threshold De-noise
- C = C * { abs(C) > T ? ( abs(C) - T ) / abs(C) : 0 }
Where:
C the complex transform coefficient;abs(x) returns the magnitude of the complex number x;T input threshold from about 0.01 to 0.001.(see the previous post for a dead link to the source of this)
This zeros out small coefficients - which are apparently likely to be noise - and scales the rest to their original range.
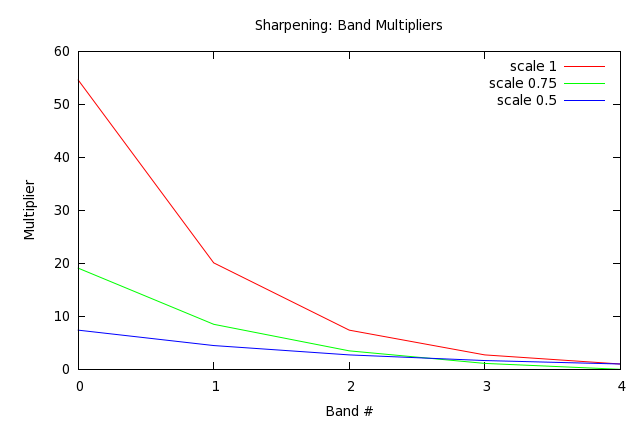
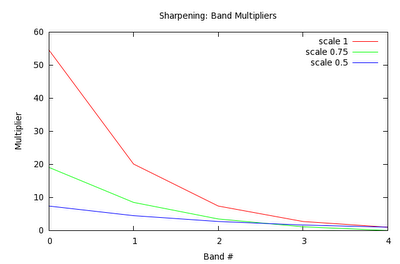
- Scale Bands
- C = C * { ( exp( (bandcount - nband) * scale) - 1 ) * weight + 1 }
Where:
bandcount is depth of wavelet transform;nband is number of the band (0 is the highest frequency);scale input sharpness 'gradient' from 0-1; andweight input sharpness weight from 0-1.scale is a general 'sharpening factor' setting, and weight specifies how heavily it is applied.
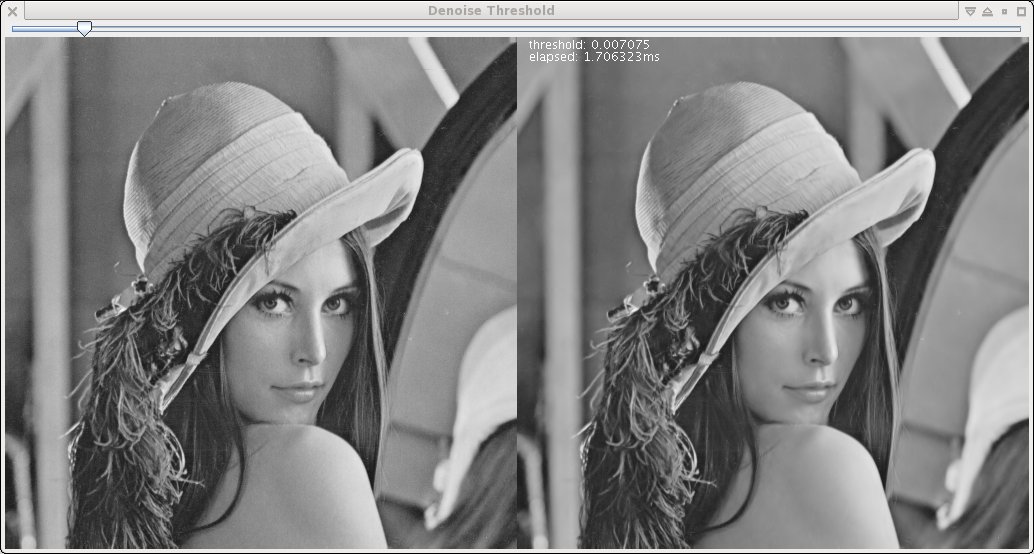
Wavelet Denoise
As a test routine for some low-level code I threw together a little test harness of a complex wavelet de-noise algorithm.It was based on some papers and demo code from this link (which appears to be dead now ... and has been for some time at that). It's just using a very simple threshold-and-scale of the wavelet coefficients, so apart from the relatively expensive Dual-Tree Complex Wavelet Transform it is simple and cheap to implement. The 1.7ms reported is the time to forward transform, apply the thresholding, the inverse, and download the (float) image to Java and convert it to a greyscale byte image. (I know, the screenshot should have been a png, so it's not entirely clear here ...)

This has nothing to do with what i'm working on but I thought it looked quite interesting. It preserves edge detail much better than techniques like a median filter or a Gaussian blur, and introduces fewer artefacts compared to the adaptive blurs i've seen. According to that now-broken-link, using the complex waveform produces subjectively better results compared to the DWT.
Perhaps i could use it as a processing step: if you already have the DTCWT coefficients it's a cheap additional process. Somewhat like doing a convolution in the frequency domain, it's basically free if you're already there.
I also played a bit with working out a sharpening algorithm on the weekend - I couldn't really find any simple papers: they all relied on adaptive processes, and the results reported didn't seems worth all the effort. In the end all I did was linearly scaled the coefficients by some made up numbers. Scale up for the highest frequency components and scale each subsequent wavelet band by 1/2 of the one above.

Unsharp Mask vs Wavelet Sharpen by scaling coefficients with approximately (but not a very good approximation) similar adjustment. Unsharp Mask is on the left.
The result is pretty much the same as unsharp-mask, but it only takes 1 tuning parameter instead of 2, and subjectively it appears to me to a smidgen less noisy. But I need to experiment a bit more, one would expect to be able to reduce the noise compared to unsharp mask and I think my low frequency scaling factors are out and it's affecting the tonal quality too much.
Sharpening ImageZ
I thought it about time to fix a few little bits and pieces with ImageZ that I actually use ... so I tackled some of that. I fixed some of the wiener deconvolution code - so that odd-sized images work for instance. I also tried thoroughly thread-ising it, although I only got a modest performance boost: jtransforms is already using multiple threads for the FFT which is the expensive bit.
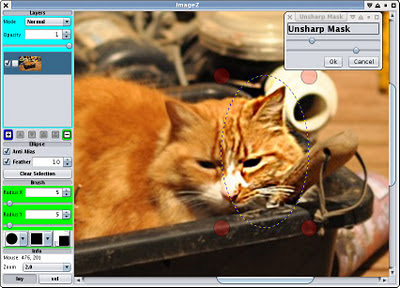
Unsharp mask in a feathered mask. I dialed it up to make it obvious.
Unsharp mask is something I always find really handy, so I finally coded that up too. Rather than start with the mess of the Gaussian filter code I already I have i coded another one from scratch. A bit simpler so I will merge and share the code at some point, or at least put it in a common place. It also mirrors the edges rather than clamping, which seems to produce a more natural response on the edges.
There are still a couple of things I use the gimp for that i'd rather not have to, but I guess that can wait for another day.
I really need to get out of the house this weekend, but i've pretty much pulled up all the weeds, it's been raining enough to water the garden, and the neighbours were using a chainsaw this morning. So I just found myself stuck at the computer again ... and I might watch the rugby on soon too.
Java v OpenCL/CPU
I've been using the AMD CPU driver a bit for debugging and testing: i never really considered it for performance but for various reasons late tonight I ended up poking around with a simple routine and wondered how it compared.
At first I thought i'd discovered a disaster, but that's because I wasn't initialising the data: too many non-normal floating point operations slowing it down significantly. Oops, glad I checked that before posting. Although it's getting late so who knows what else I may have stuffed up.
I was testing using a simple matrix multiply, a 4096x4096 matrix stored in row-major order, multiplied by a 4096 row column-vector. It isn't something i'm in any need of, but after poking around this site which i've read a few times, and with nothing on TV I decided to play around a bit. Then after exhausting my interest on the GPU I tried the CPU version - I was originally going to see if just doing it locally with the CPU driver would be quicker than a device copy and back, but it isn't, the GPU is still 5-10x faster.
I tested 4 implementations:
- OpenCL written for a CPU target using float types, one work-group and one work-item per row, 4096 work groups
- OpenCL using float4 types, same
- Java, single threaded
- Java, using a ThreadPoolExecutor w/ 12 threads, 32 jobs.
Code Time (s)
Java single 1.5
Java pool 0.39
OpenCL float 0.43
OpenCL float4 0.37
So I had to resort to float4 types to beat the thread pool code, and then only just. It's kind of debatable as to which is easier to write: the Java code must explicitly deal with the range allocation and job launching. But then it's all built-in, and doesn't require a different language, runtime, interface and foreign memory management ... and one that's prone to crashing with zero information, and otherwise and also excruciatingly difficult to debug at that. Ok scratch that: the Java clearly wins here.
One can either conclude that the AMD compiler is a bit below-par to start with (mostly likely true), and only by using vectorised code that it was able to beat the Java. Or perhaps that the hotspot compiler is rather good at this particular problem (again, most likely true), and is possibly using SSE opcodes to implement the loop too. Not that SSEn really seems to add much of a boost in general apart from a few extra registers - it's not like on an SPU where vectorised code can be 10x faster than scalar.
I had until this point thought of the CPU drivers for OpenCL providing a sort of 'portable assembly language' for higher level languages, but if you have a decent compiler already it doesn't seem worth it - at least for some problems.
I suppose another implementation might do better; but you're still stuck with a pretty hostile debugging environment and if you're after performance you'll be using a GPU anyway. So about all it seems useful for is debugging/verifying code. Given that, perhaps it would be useful to add more checking in the compiled code to help with debugging rather than worrying about performance ... Unlike C, OpenCL has a much simpler memory model for which accurate and full run-time address-range-checking can be ?easily? added.
Images vs Arrays 4
Update 7/10/11: I uploaded the array convolution generator to socles
And so it goes ...
I've got a fairly convoluted convolution algorithm for performing a complex wavelet transform and I was looking to re-do it. Part of that re-doing is to move to using arrays rather than image types.
I got a bit side-tracked whilst revisiting convolutions again ... I started with the generator from socles for separable convolution and modified it to work with arrays too. Then I tried a couple of ideas and timed a whole bunch of runs.
One idea I wanted to try was using a rolling buffer to reduce the memory load for the Y convolution. I also wanted to see if using more work-items in a local workgroup to simplify the local memory load would help or hinder. Otherwise it was pretty much just getting an array implementation working. As is often the case I haven't fully tested these actually work, but i'm reasonably confident they should as i fixed a few bugs along the way.
The candidates
- convolvex_a
- This is a simple implementation which uses local memory and a work-group size of 64x4. 128x4 words of data are loaded into the local memory, and then 64x4 results are generated in parallel purely from the local memory.
- convolvey_a
- This uses no local memory, and just steps through the addresses vertically, producing 64x4 results concurrently. As all memory loads are coalesced it runs quite well.
- convolvex_b
- This version tries to use extra work-items just to load the memory, after wards only using 64x4 threads. In some testing I had for small jobs this seemed to be a win, but for larger jobs it is a big hit to concurrency.
- convolvey_b
- This version uses a 64x4 `rolling buffer' to cache image values for all items in the work-group. For each row of the convolution, the data is loaded once rather than 4x.
- imagex, imagey
- Is from the socles implementation in ConvolveXYGenerator which uses local memory to cache input data.
- simplex, simpley
- Is from the socles implementation in ConvolveXYGenerator which relies on the texture cache only.
- convolvex_a(limit)
- Is a version of convolvex_a which attempts to only load the amount of memory it needs, rather than doing a full work-group width each time.
- convolvex_a(vec)
- Is a version of convolvex_a which uses simple vector types for the local cache, rather than flattening all access to 32-bits to avoid bank conflicts. It is particularly poor with 4-channel input.
The array code implements CLAMP_TO_EDGE for source reads. The image code uses a 16x16 worksize, the array code 64x4. The image data is FLOAT format, and 1, 2, or 4 channels wide. The array data is float, float2, or float4. Images and arrays represent a 512x512 image. GPU is Nvidia GTX 480.
Results
The timing results - all timings are in micro-seconds as taken from computeprof. Most were invoked for 1, 2, or 4 channels and a batch size of 1 or 4. Image batches are implemented by multiple invocations.
batch=1 batch= 4
channels 1 2 4 1 2 4
convolvex_a 42 58 103 151 219 398
convolvey_a 59 70 110 227 270 429
convolvex_b 48 70 121 182 271 475
convolvey_b 85 118 188 327 460 738
imagex 61 77 110 239 303 433
imagey 60 75 102 240 301 407
simplex 87 88 169
simpley 87 87 169
convolvex_a (limit) 44 60 95 160 220 366
convolvex_a (vec) 58 141
Thoughts
- The rolling cache for the y convolution is a big loss. The address arithmetic and need for synchronisation seems to kill performance. So much for that idea. I guess there just isn't enough work to do each loop to make it work it (it only requires a single mad per thread).
- Using more threads for loading, then dropping back when doing arithmetic is also a loss for larger problems since it limits how many groups of workgroups can execute on an SM.
- Trying to reduce the memory accesses to only those required slows things down until you hit 4 element vectors. I guess for float and float2 the cached reads are effectively free, whereas the divergent branch is not.
- Even with the texture cache, images benefit significantly from using a local cache.
- Even with the local cache, images trail the array implementation - until one processes 4-element vectors, in which case they are even stevens for single images.
- Arrays can also be batched - processing 'n' separate images concurrently. This adds a slight extra benefit as it can more fully utilise the SM cores, and reduces the need for extra host interaction. For smaller problems this could be important although this problem size is already giving the GPU a good sized workout so the differences are minimal.
- Using single-channel data is under-utilising the GPU by quite a bit.
When I get time and work out how i want to do it i'll drop the array code into socles.
Images vs Arrays 3
So i've been working on some code that works with lots of 2d array data: which gives me the option of using arrays or images.
And ... arrays won out: for simple memory access and writing they are somewhat faster than using images. And that's before you add the ability to batch-process: with images you're pretty much stuck with having to pass each one at a time and only pack up to 4 values in each element (3D image writes are not supported on my platform atm). With arrays you can process multiple 2D levels at once, or even flatten them if they are element-by-element - which can allow you to better fit the problem to the available CUs.
In some cases the improvements were dramatic where a lot of writes to different arrays were required (but the writes were otherwise independent).
Anyway, one particular area I thought images would still be a noticeable win is with some interpolation code I had to implement. I need to do fixed power of 2 scaling up and down. Apart from the bi-linear interpolation 'for free', there is also an interesting note in graphics gems 2 about using the bi-linear interpolation of the texture unit to perform bi-cubic interpolation using only 4 texture fetches rather than 16.
So I ran some tests with both an image and array implementation of the following algorithms:
- Bi-linear interopolation.
- Fast Bi-cubic using the graphics gems algorithm with a 64-element lookup table (I found the lookup-table version significantly faster than the calculated one).
- Bi-cubic using 64-element lookup tables generated from the convolution algorithm in wikipedia.
In both cases I was using float data, a 512x512 image, and 4x scaling in X and Y, and the numbers are in uS from the Nvidia profiler. The array implementation is doing CLAMP_TO_EDGE.
The results were quite interesting.
Image Array
bi-linear 40 36
fast bi-cubic 56 79
table bi-cubic 106 63
With this sort of regular access, the array version of the bi-linear interpolation is actually slightly faster than the image version, although they approach each other as the scale approaches 1. This is a bit surprising.
Images do win out for bi-cubic interpolation, but the array version isn't too far off.
And in either case, the bi-cubic interpolation is really fairly cheap: only about 1.5x the cost of bi-linear which is 'pretty cool' considering how much more work is being done.
I also started to investigate a bi-cubic interpolator that uses local memory to cache the region being processed by the local work-group. Since the actual memory lookups are very regular and the block will always access at most worksize+3 elements of data (for scaling=1) it seemed like a good fit. I just tried a single 64x1 workgroup and managed around 60uS with some slightly-broken code: so perhaps the gap could be closed further.
Actually one problem I have is a little more complicated than this anyway: the samples I need to work on are not the base samples, but offset by half a pixel first to produce N+1 of them. With arrays I can use local memory to cache this calculation without having to either run a separate step or do many more lookups: so in this case it will almost certainly end up faster than the image version and I will have to get that local array version working.
For float4 data the images are only about 1.5x faster for this interpolation stuff: which for my problems is not enough to make up for the slower direct access. And the bicubic resampling is also 2-3 slower than the bi-linear, the amount of extra arithmetic is catching up.
Conclusions
Well, about all I conclude is that Nvidia's OpenCL implementation sucks at texture access. I've looked at some of the generated code and each image lookup generates a large chunk of code that appears to be a switch statement. For very big problems most of this can be hidden with overlapped processing but for smaller problems it can be fairly significant. I'm surprised that they, or OpenCL doesn't have some way of telling the compiler that a given image2d_t is always a specific type: the access could be optimised then. FWIW I'm using a driver from a few months ago.
Also I guess: the global memory cache isn't too bad if you have a good regular memory access pattern. Even optimised code that resulted in 4 simple coalesced global memory accesses per thread vs 16 was only a slight improvement.
Of course the other conclusion is that it's a fairly simple problem and no amount of 'cache' optimisation will hide the fact that at some point you still need to go to main memory, for the same amount of data.
I should really do some timings on AMD HW for comparison ... but the computer is in the next room which is also cold and dark.
Final Thought
If you really are doing image stuff with affine transformations and so on, then images are going to win because the access pattern will be regular but it wont be rectangular. The data-types available also match images.
But for scientific computing where you are accessing arrays, images are not going to give you any magical boost on current hardware and can sometimes be more difficult to use. They also add more flexible memory management (e.g. i can use the same memory buffer for smaller or multiple images) and the ability to batch in the 3rd dimension.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!