About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Oooh, faster
Well, after a hair-pulling week (well I need a haircut, and i'm having a break for a few weeks next week) I'm finally getting somewhere with the HD7970. Not just having it crash the machine on me every test run makes for a much better day.
Some of that time was spent trying to track down crashes inside the clsurf code ... but they were all because I didn't notice that it needed images rounded up to 16 pixels wide ... sigh. Oops. Most of the rest was some barrier issues with my new code - it's been a while and I forgot some of the finer points. Getting it working on a CPU driver was a good help there because if you get the barriers wrong you just get nonsense results.
There was also a lot of time wasted rebooting - not only because of the code that crashes the driver, but because it still decides to start returning CL_OUT_OF_HOST_MEMORY all of a sudden. And I didn't realise till last night I can just log out of/back into X to fix this until it happens again. And time wasted verifying my drivers were ok too - which probably was wasted (and now i have a broken dependency map and catalyst libraries splatted over lib64 to boot). And finally I think I found a bug in the AMD driver as well, it's getting a divide-by-zero signal (which causes the jvm to abort!) when using a local worksize < 64 - this isn't something I normally do, but the occasional algorithm benefits from it. It's not too difficult to work around at least.
AAaaaaaanyway ...
I finally have some RANSAC code working on the new card. And it's a screamer.
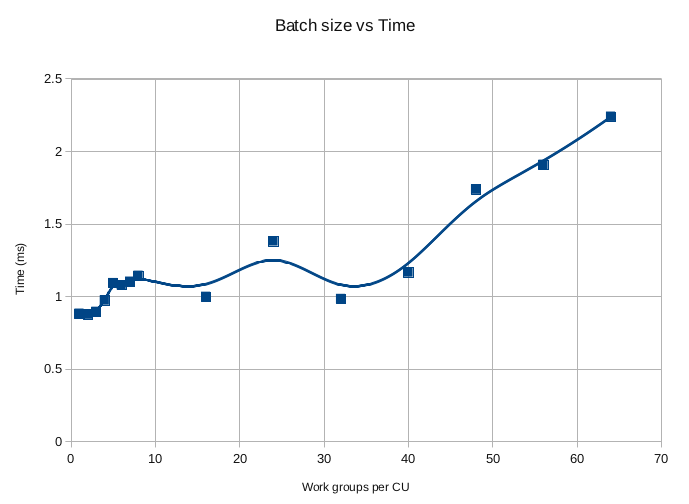
I'm getting around 2-3x total performance boost compared to the HD6950 for one run of the RANSAC code. Although I can up the number of RANSAC random probes by 4x and still run about 2x faster (this was not the case with the 6950, 2x probes meant 2x time taken) (so it's about 8x faster then). I thought i'd make a plot of the scalability to see how it does.
The stuff below 40 is pretty much 1.0ms, the ups and down are just sampling noise.
In this case, the number of work-groups per compute unit means the number of jobs queued would mean that many work-groups (wave-fronts) per compute unit. The 7970 has 32 compute units, each work-group does 7 matrices concurrently, so that means 40 on the X axis equates to 8960 RANSAC probes, i.e. solving 8960 9x9 matrices using SVD, and forming the homographic matrix with a couple of 3x3 matrix multiplies on the result takes about 1ms.
So, anything under 9000 checks is wasting resources on this machine.
So whilst writing this post and after doing all the timing i revisited a tiny part of the algorithm - the heaviest bit of the SVD is the error calculation which involves 3 sums of products across all 8 rows. For the HD 6950 I got a 2x speedup by using a simple loop vs a parallel sum - calculate the products in parallel but sum them in series directly in registers, but only in 1 thread of 9. I just noticed the ALU usage was a bit low on the 7970, and I turned back on the parallel sum. Well what do you know, ALU instruction count dropped from 9500 to 5900 and reduced the biggest case above from 2.3ms to 1.7ms (which is closer to a linear scaling anyway).
Sigh, now to debug some older and far more complex code that is not working 100%.
ARGH drivers! Code!
So, the AMD HD7970 arrived at last.
Yay!
I knew it was probably not a wise idea just yet ... but i put it in ...
The 12.4 drivers weren't too much hassle to get going on Fedora 15, I just downloaded the Fedora 16 SRPM and built that. Had a couple of library path issues/conflicts with the SDK but I got that sorted.
The "second monitor is slow as shit" problem is back again unfortunately. I had that with some other previous version, then it went away with 11.11, but now it's back again. Very annoying but not the end of the world.
Unfortunately though, lots of code crashes, even crashes the driver and system lock-ups. I haven't had that happen for a while :'(. But mostly this seems to be bugs in my code. e.g. I spotted an issue with the SURF hessian det routine - it expects the images to be multiple of 16 wide for instance otherwise it can end up over-writing the bounds of images. I guess GCN or the driver is a lot thingier about such things now.
Also a compiler crash, but i suspect that is some bad barrier() usage in my new SVD stuff - i always get caught out when trying to have sub-groups of work-items work together on a problem and i just noticed the outer loops wont be synchronised across all work-items. That's a bit of a bummer as fixing it might be a bit of a performance hit (i'll see if simply removing the barriers works first! For a CPU backend the design is wrong anyway), but it doesn't matter how fast it runs, invalid code is useless.
Ho hum. Well I knew I should've waited ... for now i've put back the old card and will have a look when i have more time next week. Thankfully everything still works even with the updated driver - i very much doubt the cayman code-base is getting much love with the GCN stuff around so it probably is the same code as in the older driver.
OpenCL SURF
Over the weekend I ported the clsurf code to socles. I had a bit of a play with a few other things as well although they didn't make much of a difference to the execution time (well, maybe 10% maximum kernel time). I guess one thing to try will be to change it so that it doesn't need to communicate with the host at all: it should be possible with some 'persistent' kernels and forcing a hard-limit on the feature point count.
I put a few more details over on the project page.
oooh fast
Well I had a frustrating yet productive day today following on from yesterday's progress.
I ported the Jacobi SVD code to OpenCL and managed to paralleise most of it. I'm using 9 threads per SVD column which lets me paralleise all of the rotations. The code itself is somewhat simpler than the LU decomposition I worked on earlier, and it parallelises more easily. Actually having 9 threads also allows me to implement a 3x3 matrix multiply in 4 lines of code as well so it all fits nicely. I'm using 63 threads per local work group so the few times I do need barriers are just compiled out anyway. I also removed some of the code I don't need: e.g. fixing up the singular values and the U matrix at the end. The only bit which isn't totally parallel is the error calculation of the columns, but even there I was able to utilise a parallel sum to help.
I'm not really sure of the numerical stability; it works for my test cases.
So yeah, it's pretty fast - I'm currently doing batch sizes of 2000 homographies, and the SVD calculation and generation of the homography matrix is taking about 3.5-4ms - somewhat better than the 200ms or so from the CUDA RANSAC code (although that does a bit more work as well). I'm still doing the randomising and setup of the input matrix on the CPU, but that's the next candidate to move to the GPU. The GPU code to check for inliers is in the range of a 140uS as well. Once I re-arrange the code a little I will be able to keep all the data on the GPU - e.g. from SURF generation all the way through to final homography matrix.
I had thought real-time was going to be impossible, but now i'm not so sure.
The 3x3 matrix multiply fell out very simply - having 9 threads already assigned to each column of the SVD meant I had 1 thread per 3x3 matrix cell as well. I haven't had to look too much into matrix stuff on the GPU so far, so it was satisfying that such a neat solution presented itself when I did.
void mult3x3_gl(uint lid, uint cid, uint ar, uint ac,
global float *a11, local float *b11, local float *lwork, local float *r11) {
lwork[lid + LSTRIDE * 0] = a11[lid - cid + ac + 0] * b11[lid];
lwork[lid + LSTRIDE * 1] = a11[lid - cid + ac + 3] * b11[lid];
lwork[lid + LSTRIDE * 2] = a11[lid - cid + ac + 6] * b11[lid];
barrier(CLK_LOCAL_MEM_FENCE);
r11[lid] = lwork[lid - ac + LSTRIDE * ac + 0]
+ lwork[lid - ac + LSTRIDE * ac + 1]
+ lwork[lid - ac + LSTRIDE * ac + 2];
barrier(CLK_LOCAL_MEM_FENCE);
}
Here lid = local id, ac = lid % 3, cid = lid % 9 (base of matrix for this work item), LSTRIDE=64. With a worksize of 63 it means this does 7 3x3 multiplies at once and the barriers vanish.
It's nice when everything totally parallelises and there are no special cases.
The most frustrating part in all of this was getting the addressing right. For the SVD I came up with a complex addressing scheme where 9x9 matrices are stored in groups of 7 side-by-side. A few more grey hairs and a hoarse voice over trying to get that to work.
Also spotted a strange problem with the AMD driver: If I use printf, then I cannot use a cached binary or it simply crashes. If I just add a space to the code to force a re-compile (my cache uses the whole source as the key) it works ok.
SURF, RANSAC, OTHERALLCAPSSTUFF
With the prototype out of the way I'm back to looking at algorithms again, at least for a couple of weeks. It seemed a good opportunity to finally try and nut-out RANSAC for building homographies for mapping between images. I've previously looked into it but got no-where because it was all totally matlabotomised code and difficult to decipher.
I thought i'd start with this CUDA RANSAC implementation since at least it had all the right structure in place.
Of course, then i needed to get SURF going ... which I had previously played with (half-heartedly) and failed, but now with clsurf around, I just ported that to JOCL (which was thankfully a simple task as the code structure is similar to the way I write stuff). And that pretty much 'just worked', so all good so far.
Porting the CUDA RANSAC code wasn't much work, but I wasn't getting great results, nor great preformance so I ported that to Java to gain a deeper understanding. After a bit of searching I found EJML which I used for the SVD this time just to make sure.
Another implementation ...
I still wasn't grokking it - although by now RANSAC itself was starting to make some sense - so I kept searching. I found this interesting homework solution which had a complete, readable, and well explained RANSAC algorithm. At last. So finally i was getting reliable results - a bit slow mind you - but reliable if I let it run long enough.
One issue I had is that I seemed to need a great number of iterations to get a quality result - several 10s of thousands. i.e. a bit slow. Something like 20s for one of the data sets I had. I found out that much of the time was taken up with in-lier check, which is quite simple and although it processes many points should've been faster. It seems the E of efficient in EJML doesn't quite stretch to small matrices. Hand-coding that, and simplifying the test to only check the forward transform sped it up considerably. With a bit more tweaking the test-case is down to around 1s - for single-threaded java code.
I also found this site which has a bunch of matlab scripts and one is for a more complex version of the homography calculator which uses less FLOPs (I started with the paper 'Computation of Homographies' by Harker and O'Leary - but for whatever reason the site I downloaded it from seems to have removed it since). That seemed worth looking into, so I created an implementation of that as well. It didn't seem much faster at first but on further investigation it seemed worth looking into. It gets most of it's speed from running two smaller SVD's (4x2 and 8x3) rather than one larger one (8x9).
I was thinking at this point I might just forget about the SVD stuff on a GPU - i can find other work for it to do and the SVD code I was looking at (in EJML) is very complex. But with the fixes to the inlier check now it was taking about 50% of the time; which meant that even with multi-threading I probably couldn't keep the GPU very busy with in-lier checks. My first attempt at this generated a single result on the CPU then double-buffered the matrices to the GPU for it to perform the inlier check. Unfortunately the driver overhead was too great; I got it down to about 4s (for 10K iterations), but most of that time was in the driver synchronisation. After thinking about it a bit more I was going to do a whole batch instead, but then I did some more profiling and realised it was only going to give me at best a 2x performance boost, so I thought i'd go for some higher-hanging fruit first.
So I revisited the thought of creating a fully-GPU implementation. So as it happens I ended up back with the GSL version of the SVD code which was in the CUDA_RANSAC stuff. I dropped that back to Java and got it working. I noticed the code almost always does operations on columns, and indeed, copies the columns around a couple of times just for good measure. So I transposed the data and operate on rows instead: which means I can parallelise some of the internal loops as well. With a few more tweaks this is now the fastest version, 50K iterations take about 0.85s.
I'm still working on implementing a version of the 'optimised' homography algorithm at the moment, as it needs some more work - e.g. an implementation of pinv. But given I have the basic version working I should probably try to port that to OpenCL first, to see if I will get much benefit.
I probably need to investigate trying to reduce the iterations required. At the moment I am doing a simple nearest-neighbour match using an L2 measure, so this could probably be improved (but given results as below, it is doing a fair job).
This is a display of the inliers. There are 249 inliers from 571 putative matching feature points.
This is the result after running clsurf to find feature points, running a sum of squares match against the feature points to find the putative matches, and then running RANSAC for 50K iterations to find the homography.
SURF and the nearest neighbour match are running on the GPU (in ~50ms total) with the RANSAC entirely on the CPU in single-threaded java - in about 0.95s for the 'unoptimised' homography calculator.
This is the image after the homography is applied to each corresponding picture. i.e. the source right-hand image has the inverse homography applied to generate the output left-hand image. And visa versa.
lalalala i can't hear you lalalala
I came across a pretty bizarre bit of information on some opencl forums yesterday and the more I think about it the more it explains quite a few things about how just strangely m$ evangelists and fanbois behave. It's not a new thought, but a timely reminder and it got me thinking further about it.
It was a question regarding some building options when using one of their developer products: presumably by someone who has a paid-for or otherwise valid license for this product. Yet this is what their response was:
BTW, I originally posted this under Microsoft‘s Visual Studio forum and had it modded off-topic and (re)moved: “Moved by DanielMoth Microsoft Employee 1 hour 38 minutes ago We do not support OpenCL questions in the Microsoft forums. (From:Parallel Computing in C++ and Native Code)“
Presumably this is only because OpenCL is not a m$ endorsed platform, but I think there is a bit more to it than just that. I think m$ are shit-scared that anyone in their protected information sphere might be made aware that there are practical alternatives to the products they push. Or worse - that anyone might actually be using them. One always notices that they don't seem to be aware that there is a whole world of developers who don't need their snot to get real work done - and might be more productive without it. Obviously this is intentional. Pretty much on-par with how the main-stream-media continually pushes a message controlled by the monied classes to ensure people behave as they want.
In my recent work with Android I had a co-worker join me on the project, but unfortunately he is a big-time m$ fanboi. He even has a m$ phone 7, uses bing as his only search engine - on IE (I mean, ... "really"?), has never rarely used anything but microsoft IDEs - since circa 1990, etc. The thing is, he was totally lost outside of that environment, and any failings of the android sdk or documentation (of which there are plenty) prompted comments on how wonderful c-hash and whatever-wpf-is-called-this-month is. Forgetting that all toolkits pretty much suck and are a huge pain to work out when starting from scratch. I spent ~3 years on c-hash bullshit because of this guy, so i know he's so full of shit when he claims otherwise - and call him out on it.
But what most surprised me is that he didn't get a google account to access the shop, nor did he download a SINGLE android tablet application to find out how they work, and what sort of user-interface features work well vs which ones don't. I don't think he even looked at the bundled ones when I wasn't driving the machine.
Why would one intentionally handi-cap your ability to do a good job? Strange ... and I don't think it was to intentionally make the result look bad - it was just too much of a culture shock for him to be outside of his protective bubble. This is why we wasted a few weeks on an aborted web front-end in the first place as well.
Anyway, I think this childish insular attitude helps to explain much of the weirdness with m$ phone and nokia's scandalous fall from the market driven by a CEO of this mould. I've been reading a lot of Tomi Ahonen's blog of late, and some of the information about m$ phone shows they are being so insular in their rejection of all possible alternatives that it is causing them to make many mistakes and create a shit product that nobody wants.
BTW the fact that Tomi had high PR reps from Nokia trying to disparage him on twatter and even on his blog shows they have totally lost the plot. Totally insane.
Ubuntu is still snot.
Some business was throwing out a couple of old laptops and my flatmate ended up with one: which means I get to try to make it work. After waiting about 8 hours for it to book the ubuntu live cd a couple of times I thought it wasn't going to be much use: until I opened the SODIMM cover and saw the 512MB module had fallen out. At least 768MB makes it almost usable ...
But yeah so I ended up installing xubuntu 12.04 (I didn't just go with fedora because that's a pain if you're using XFCE as well, not to mention all that systemd and other crap). I can't say I have much good to say about it on first impressions:
- The default theme is whack. It's hard to tell if a window is focused or not, and there's no scroll up/down buttons which makes it a pain to use. Nice to finally see someone realise black on white writing sucks though, and at least the terminals are grey. I kinda wish XFCE had window title colours other than "windows 95 blue" though (all but one).
- Way too much shit is attached to the touchpad 'scroll area'. WTF would you ever want to change desktops this way, or shade your windows?
- The "ubuntu software centre" is a complete joke. Ugly, slow, hard to use. My first impression was "must be some python crap"; confirmed. I only ran it accidentally as I was looking for the real thing, i.e. synaptic. Ok, sure if it was a few weeks work on a prototype, but if this is supposed to be a production-ready bit of code it is a total embarrassment.
- Notwork-Manager still ... doesn't work properly. I gave up on the on-board wireless which refuses to connect for whatever reason, but I have a very old PCMCIA card as well. I got that working easily by running a few commands manually but Notwork-Manager just kept retrying and failing, retrying and failing ...
All it really needs to do is play videos and visit youtube, so i'm not asking for much. If I can get it that far along I will leave it.
Citrus Day
Handed off the prototype i've been working on for the last 8 weeks to the project manager last night; fairly pleased with the result in the end. But given it was a bit of a slog and I will switch gears next week back onto algorithms (yay, and OpenCL), today seemed like a good day for a break ... and to catch up on some preserving.
The citrus has all gone crazy this year.
And this is after I've picked about 40 kaffir limes (actually, they fell off), and the bowl of kumquats in the next photo. I juiced the kaffir limes last week and ended up with about 700ml (and a whole lot of rind in the freezer), although about all i've found to do with the juice is as a scalp/hair treatment. The lemon tree in particular has been so loaded the tree itself is in fear of falling apart. But they're not quite ready yet - they're only meyers anyway, so are fairly sweet - I've already tried some by peeling them, separating the segments and sprinkling with sugar. Tastes pretty close to grapefruit actually, although not so bitter and thus a bit nicer.
The mandarine tree still has plenty on it too - we've been eating them every day and giving away bags of them but you'd barely tell looking at the tree. Most have them have been nice and tart and juicy too.
So what to do with these - they surprisingly go a long way for such a small fruit. I had previously done some brandied kumquats which a friend particularly liked, so I thought i'd start with that - and give it to him as a birthday present.
I used a recipe I found some time ago but haven't been able to re-find: equal parts by weight of kumquats, sugar, and brandy. This is a 2800ml jar, so i've got about 900g kumquats, 900g sugar, and 900ml of brandy. I got some cheap glass jars at a $2 shop, and they worked pretty well apart from some pretty cruddy seals (but they'll do). The sugar will take a few days to fully dissolve. After about 6 months you get something that takes pretty much like a citrus version of a tawny port - obviously quite sweet but with a fairly balanced flavour of tart & bitter as well.

So I still had a few left over from the initial picking so I scoured the net for some other ideas - last time I had a decent crop I made some marmalade, but I still have plenty of that left! (from 4 or 5 years ago) I thought i'd try preserving them like lemons, so a good cup-or-two of salt later, a bit of lemon and lime juice, and some stinging fingers and there you have it. I really have no idea if these will work at all, but apparently they're good for something after a few months. Based on something approaching this recipe (although "some salt" is hardly a useful fucking measure ...) together with this one for lemons from The Cook and The Chef. Who knows if i have too much salt, but if nothing else it looks nice.

And finally my lime tree has been dropping limes enough that cooking can't keep up with them, so I wanted to make some lime cordial ('syrup' for you yanks). Again this is something that goes a long way, with 7 limes I had 2l of cordial (I usually mix it about 6:1), but it's a really nice summer drink. Pity it's a long way from summer. As there are more ready to drop I will probably make ice-cubes of it next time. I used this recipe although I only used 1kg of sugar, and bottled it whilst hot without straining. The old lady had a great recipe from her Green and Gold recipe book but she threw the book away years ago ...
And yes, it's yellow, but it's still all lime juice, which was a nice shade of green going in. Although I added a bit of lemon zest, and most of the lime zest was also fairly yellow as the limes are proper-ripe. I normally leave all the zest in as the sugar more than makes up for any bitterness they might add, and it looks nice.
I also have a very small number of west-indian limes - the very small ones with seeds in them - so i'm not sure what to do with them. They are super-tart though.
Bombay Sapphire bottles with the labels removed make very nice storage bottles too. Must get some more since I have all these limes handy (for the gin that is ;-), although it's been a bit of a dangerous drink for me lately (it's just too easy to sink them down).
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!