About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

AMD Fusion Summit, HSA, etc.
Been looking forward to watching the AMD Fusion summit this year after watching a bunch of very interesting videos last year. I knew they were coming up but this month has gone faster than I thought ...
So far i've just watched the 'programmer' keynote from Phil - it's a pity about the emphasis on C++ which is such a shit language - but what are you gonna do eh? His talk on the viola-jones haar cascade algorithm was interesting, how HSA could be used to split up algorithms to move the problem to where it is most efficiently solved (not sure how it compares to face-detector in socles, as I solved the problem of idle work-items in a different way). But yeah, looking forward to that capability in the future; during my last visit to OpenCL in the last month or so I kept thinking that being able to run stuff on the CPU where it made sense would ... make sense.
I slightly disagree that the problem with the GPU parallel programming is just that it is too hard to write - all good software is hard to write - I think it more has to do with the availability of the platform. e.g. PS3 is hard to write too, but there seems to be plenty of that now because everyone's writing to the same platform. If I was a commercial developer writing software, right now it's only going to be a niche (photoshop is a niche). This is ok - because niche customers are probably already using capable hardware or don't mind buying it - but for mass market adoption it requires mass market availability of stable, quality, compatible platforms. This is still some way off.
The videos are on the summit broadcast site which requires a freely available login.
Update: Blah, ahh well, mostly a bit dull & sparse this year, or maybe they just weren't all put up on the net. The HSA stuff is the most interesting again from a software perspective.
Update 2: Apparently more content will be added over time, I guess last year I didn't spot it for a few months so had a lot more to look at off the bat.
On more reflection the HSA foundation and the HSAIL stuff is pretty big news. People don't seem to understand why it's so important though. It's really about the H in HSA - heterogeneous. Being able to support many CPUs with the same code and even the same compiler. Being able to target the code at run-time to execute on the most efficient hardware available in the current system. And being able to do that in a practical way that isn't tied to some vendor-specific secret sauce using broken proprietary compilers. At the bottom of it, it's just another attempt at 'write once, run everywhere' technology, but this time for computationally intensive processing and not for desktop user applications. I guess time will tell to see how it goes without nvidia and intel though. And the same as to whether this finally allows free software to take part.
The other part of it is coming up with a set of re-usable libraries so that the performance is opened up to non-gun-hackers (or in their terms, non-'ninja'-programmers), although TBH I don't see that is any different to any other modern hierarchical programming environment full of frame-works and tool-kits. This can already be done with OpenCL anyway, but I suppose there is still messy crap to deal with from the idiot-programmer's perspective. e.g separate memory spaces, device-host copy overheads and so on. HSA with code transparently intermingling with plain old host code means the same could be done without the overheads and make it more attractive.
I still think the biggest hurdle for application developers is platform support. Any extra work has to be justifiable if it is only going to benefit a part of your customer base.
Update: I never got around to seeing the actual talks at the time but I just found that Stream Computing have a nice index of all the OpenCL specific talks. I'm not a regular reader of their blog but every now and then I do a search in which it turns up and I do a catch up ...
Random stuff
So I spent the last couple of days playing with a few random things.
- Beat detection
- Interest in this goes way back, probably to when a few lads and I did some graphics at a rave in the early 90s ... anyway I thought i'd have another look. I started here with this rather badly formatted word 'processed' document, but ended up trying to implement a wavelet algorithm based on this paper.
I played with it a bit but didn't really get good results (as far as i could tell, and my testing code wasn't great). Next time I revisit it i will probably look at the simpler spectrum-based algorithms from the first article but with a variation on the cycle detection.
- DLNA
- Oh that DLNA crap again. Mostly because there doesn't seem a simple video player that lets one access a DLNA server from Linux in a simple way. I started with cling, and after waiting for about 20 minutes for maven to compile it decided that there really is a build tool worse than ant (surprising as that is), and then proceeded to split the project up into a pattern that netbeans can work with. I eventually got it to run and started work on a jjmpeg media renderer, got the android browser working and so on. But really wtf - it's a huge fucking pile of code just to retrieve a URL to a file on a HTTP server ...
Then this morning I read this post from the developer of libdlna (which seems to be abandoned now), and decided it was just a world of pain I wanted nothing to do with.
IF I ever bother with this again I will probably just write my own protocol but today I can't be stuffed.
- jjmpeg build
- And finally today I poked at the jjmpeg build. Looking at using the current android branch as the main code-base. The native stuff isn't that difficult (just making a decision and sticking with it is the main problem), but ant and netbeans either makes it impractical or impossible to support cross-platform development in the same project.
So I will probably need to create 3 side-by-side projects, although for various reasons this isn't terribly ideal either.
- jjmpeg-core would contain the main binding classes, native generators and so on. Probably a copy of the ffmpeg sources.
- jjmpeg-java would contain the java-specific i/o and display classes. I guess this would also build the native code.
- jjmpeg-android would contain the android-specific i/o and display classes and android native build, and probably be configured as an android library project so it can be re-used.
I didn't actually get that far, I was working on re-arranging the native build and platform-specific stuff in order to fit it in with the android build and clean it up. But I didn't really come up with great solutions, and in the end I think I solved nothing so might have to try again from scratch another time.
Just not switched on today, so might go find somewhere warm to read ...
Slow queues and big maths
After a couple of days poking at my android video player - mostly just to test jjmpeg really - and getting it to mostly work, I thought i'd have a look at some performance tuning. It even does network streaming now.
Fired up the profiler and had a poke ...
Found out it was spending 10% of it's time in the starSlash implementation I was using - I hadn't upgraded the multi-thread player to use the libavutil rescale function and it was still using the java BigInteger class. Easy fix.
And then I checked the queue stuff it's using for sending around asynchronous data. I changed from using the LinkedBlockingQueue to a lighter weight and simpler blocking queue I had tested with the simpler player code. Nearly another 10% cpu time there as well.
So with those small changes my test video went from about 30% cpu time (if i'm reading the cpu usage debug option properly) to well under 10% most of the time. It's only a fairly low-bitrate 656x400@25fps source.
The next biggest thing is the texture loading which can be a bit slow (actually depending on the video size, it's easily the single biggest overhead). I kinda mucked around with that a lot trying to debug `the crash', so that could probably do with a revisit. Right now i'm updating it on the GL thread - but synchronously with the video decoding thread, so any delay is costly (I wasn't sure if decode_video could reference an AVFrame at the next call). From memory doing it this was was quicker than using a shared gl context too. Actually whilst writing this i had a closer look and a bit of a poke - the texture loading is still really slow but i removed more overhead with a few tweaks.
The main problem with the player itself is that it still just vanishes sometimes with a SIGBUS. Android displays nothing about it apart from that the signal was '7', so i guess it's in some native thread. I thought I had gdb running a few weeks ago but i can't seem to get it to run now - although back then it didn't help much anyway. It also doesn't even try to cope well with not being able to keep up with decoding and ugly stuff happens.
Ahh well, if it was done I'd have nothing to do ...
Idle minds ...
So it turns out I have a bit of a break between contracts again - i'm always happy to have extra time off, so there's nothing to complain about there!
I sat down on the weekend and yesterday to play with some socles code, but so far it's been really slow going. I just don't feel like getting too much into it and it's easier just to put it down if i hit a problem; I guess I really do need a bit of a break. I also have tons of crap to do in the back yard, shed, and even around the house as well; but i've been a bit lazy on that front the last year or so, as such I doubt much will happen there.
But yeah, I guess eventually over this break I will get the opencl ransac stuff sorted out in socles, and probably then re-visit jjmpeg to at least check in the code I've already done on the android stuff.
I tried the 12.6 beta catalyst driver yesterday - and thankfully it seems a lot better than 12.4, so far, touch wood, etc. At least it doesn't keep throwing up OUT_OF_HOST_MEM errors after a half a dozen code runs, AND the xinerama twin-screen desktop is back up to decent performance. So after finally getting a GCN GPU I would like to have a play with that and see what I can get out of it. I should probably try and come up with a specific application I want to try to implement and work toward it as well, rather than just poking in random algorithms to socles. The thing is, computers mostly just do what I need them to do (run emacs and a terminal in overlapping windows?), so i'm not particularly driven at this point.
I'm keeping an eye on the ARM stuff; the rhombus tech guys, the open pandora (who knows if i'll ever get the one i ordered - at least an email confirming the order and address once a year would be nice), but with a bunch of beagleboards sitting idle already it doesn't seem much point in me getting another dev board to poke at. Just not enough hours to look at everything that is interesting ...
On the RANSAC code, I pretty much have it done - it's just that messy testing to go. In this version I tried to do most work in the one kernel - I will see if that added complexity makes it slower, or the lower memory demands help it overall. I also tried to parallelise absolutely everything, from coordinate normalisation/result denormalisation to matrix setup. So far i'm getting a strange result in that just the SVD is somewhat slower than just the SVD I had before: although for all intents they are the same design. Once I have it going I will try double arithmetic to see if that generates better results.
Green Tomato Sauce
So for some strange reason I have an abundance of tomatoes at the moment - being June, this is way way out of season. Considering I had tomatoes from October to February as well, it's been a strange year.
The wet is making them split a bit, and together with a lot of bug problems it means they're best picked green before they get eaten or go rotten
I started getting more than I could consume so I made some sauce (not a fan of the green tomato pickles). It's pretty much a plain tomato sauce recipe, but with green or pink tomatoes instead of red. A bit more sugar to compensate (and to compensate for not measuring the salt properly). And since I made it - a shit-load of chillies. The habanero plants are suffering in the cold too and getting a bit of mould problems, so I just grabbed all the chillies I had left on the plants as well. Chucked in a bit of sweet potato I grabbed out of the ground as well since I had it - probably should've used more as i have more of that than I use too.
So, plenty of chillies. I didn't count but it's at least 2-3 cups worth. Plus a handful of all the other green chillies i found in the garden (cayesan and serrano).
It looks much like some fermented green chilli sauce I made (tabasco style), but this has much more of a bite to it. Otherwise it tastes much like home-made tomato sauce, the red kind. While licking the spoon I had enough chilli to give me the hiccups - which means it's pretty hot.
Nearly 3 litres of that should keep me warm over winter and beyond ... I don't even use tomato sauce that often, but this stuff is great with a burnt snag or a boiled sav in a bit of bread. Used sparingly.
Was busy cooking most of the day yesterday, I also made a banana cake (a couple of bananas getting past it that needed using) and another 2l of lime cordial. I used the same recipe as last time but put twice as much lime juice in it- came out much better. More limey and less 'cane sugar'.
PS I used half a bottle of ezy-sauce in the ~2.5kg of the green fruit, so acid shouldn't be a problem.
Oooh, faster
Well, after a hair-pulling week (well I need a haircut, and i'm having a break for a few weeks next week) I'm finally getting somewhere with the HD7970. Not just having it crash the machine on me every test run makes for a much better day.
Some of that time was spent trying to track down crashes inside the clsurf code ... but they were all because I didn't notice that it needed images rounded up to 16 pixels wide ... sigh. Oops. Most of the rest was some barrier issues with my new code - it's been a while and I forgot some of the finer points. Getting it working on a CPU driver was a good help there because if you get the barriers wrong you just get nonsense results.
There was also a lot of time wasted rebooting - not only because of the code that crashes the driver, but because it still decides to start returning CL_OUT_OF_HOST_MEMORY all of a sudden. And I didn't realise till last night I can just log out of/back into X to fix this until it happens again. And time wasted verifying my drivers were ok too - which probably was wasted (and now i have a broken dependency map and catalyst libraries splatted over lib64 to boot). And finally I think I found a bug in the AMD driver as well, it's getting a divide-by-zero signal (which causes the jvm to abort!) when using a local worksize < 64 - this isn't something I normally do, but the occasional algorithm benefits from it. It's not too difficult to work around at least.
AAaaaaaanyway ...
I finally have some RANSAC code working on the new card. And it's a screamer.
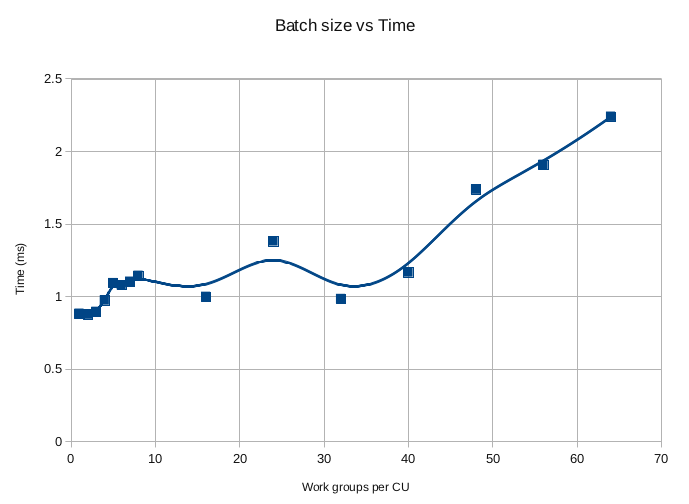
I'm getting around 2-3x total performance boost compared to the HD6950 for one run of the RANSAC code. Although I can up the number of RANSAC random probes by 4x and still run about 2x faster (this was not the case with the 6950, 2x probes meant 2x time taken) (so it's about 8x faster then). I thought i'd make a plot of the scalability to see how it does.
The stuff below 40 is pretty much 1.0ms, the ups and down are just sampling noise.
In this case, the number of work-groups per compute unit means the number of jobs queued would mean that many work-groups (wave-fronts) per compute unit. The 7970 has 32 compute units, each work-group does 7 matrices concurrently, so that means 40 on the X axis equates to 8960 RANSAC probes, i.e. solving 8960 9x9 matrices using SVD, and forming the homographic matrix with a couple of 3x3 matrix multiplies on the result takes about 1ms.
So, anything under 9000 checks is wasting resources on this machine.
So whilst writing this post and after doing all the timing i revisited a tiny part of the algorithm - the heaviest bit of the SVD is the error calculation which involves 3 sums of products across all 8 rows. For the HD 6950 I got a 2x speedup by using a simple loop vs a parallel sum - calculate the products in parallel but sum them in series directly in registers, but only in 1 thread of 9. I just noticed the ALU usage was a bit low on the 7970, and I turned back on the parallel sum. Well what do you know, ALU instruction count dropped from 9500 to 5900 and reduced the biggest case above from 2.3ms to 1.7ms (which is closer to a linear scaling anyway).
Sigh, now to debug some older and far more complex code that is not working 100%.
ARGH drivers! Code!
So, the AMD HD7970 arrived at last.
Yay!
I knew it was probably not a wise idea just yet ... but i put it in ...
The 12.4 drivers weren't too much hassle to get going on Fedora 15, I just downloaded the Fedora 16 SRPM and built that. Had a couple of library path issues/conflicts with the SDK but I got that sorted.
The "second monitor is slow as shit" problem is back again unfortunately. I had that with some other previous version, then it went away with 11.11, but now it's back again. Very annoying but not the end of the world.
Unfortunately though, lots of code crashes, even crashes the driver and system lock-ups. I haven't had that happen for a while :'(. But mostly this seems to be bugs in my code. e.g. I spotted an issue with the SURF hessian det routine - it expects the images to be multiple of 16 wide for instance otherwise it can end up over-writing the bounds of images. I guess GCN or the driver is a lot thingier about such things now.
Also a compiler crash, but i suspect that is some bad barrier() usage in my new SVD stuff - i always get caught out when trying to have sub-groups of work-items work together on a problem and i just noticed the outer loops wont be synchronised across all work-items. That's a bit of a bummer as fixing it might be a bit of a performance hit (i'll see if simply removing the barriers works first! For a CPU backend the design is wrong anyway), but it doesn't matter how fast it runs, invalid code is useless.
Ho hum. Well I knew I should've waited ... for now i've put back the old card and will have a look when i have more time next week. Thankfully everything still works even with the updated driver - i very much doubt the cayman code-base is getting much love with the GCN stuff around so it probably is the same code as in the older driver.
OpenCL SURF
Over the weekend I ported the clsurf code to socles. I had a bit of a play with a few other things as well although they didn't make much of a difference to the execution time (well, maybe 10% maximum kernel time). I guess one thing to try will be to change it so that it doesn't need to communicate with the host at all: it should be possible with some 'persistent' kernels and forcing a hard-limit on the feature point count.
I put a few more details over on the project page.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!