About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

On NEON vs OpenCL
So I just reached a 'have output' milestone on some code i'm working on and I was reflecting on how much effort it was to code a similar algorithm in NEON in assembly language compared to OpenCL on a GPU.
In my case, NEON comes out on top in terms of 'developer productivity'.
- Mistakes crash a process - not your computer.
- Easier to debug in gdb (I know there are OpenCL device debuggers now, but not when I started).
- Better libraries.
- Not portable - but OpenCL isn't portable between device-classes either, and isn't available on every system.
- Easier memory management - it's just the same as C.
- Easier to bind with C code - it's just the same as C.
- Very low call overhead.
The last two points are quite significant. Because of the overheads of OpenCL you're forced to put big chunks of complex algorithm onto the device - not to mention the hairy code required to get good performance out of not-trivially-parallel tasks.
With NEON you only need to code the stuff that runs slower than it should in C (and despite all the years of compiler advances, there's still a lot of code like this), and just leave the complex business logic and outer loops to the compiler (it usually does an ok job at that). Even without resorting to exotic bit manipulation and in-register lookup-tables, such a simple operation as a "float - scale - clamp - byte conversion" (as typically encountered in image processing) is several times faster via NEON than in C, and not a lot harder to write.
It helps that NEON has a nice orthogonal instruction set with sane mnemonics and a healthy register count, unlike some other crap one could mention ...
Pity it's still slow!
The main issue is of course that these CPU's are pretty gutless, and you can't get the sort of performance you can out of a desktop machine, let alone a GPU (but those can't fit in your pocket either). Of course, this is the type of problem the parallella project is trying to address - but they seem to be having a bit of a kickstarter melt-down and haven't updated their project in a few days. Well one hopes the publicity gained helps them get something going anyway even if this particular effort fails.
Update: Well Adapteva finally put some more stuff up. I guess going for the 'cheaper/faster beagleboard' type thing is better than their original approach, even if it de-emphasises the parallel nature somewhat. Whether it's that or the request for more noise, it seems to be picking up a good amount, although $200K in 2 days is a big ask.
NEON complex multiply
In the last post I mentioned writing a complex multiply for NEON.
It's actually a good demonstration of the use of a NEON feature - data manipulation on loads, and it's quite trivial i'll post it here.
Complex Multiply
As one might recall, a complex multiply:
C = A * B
Is implemented as the expansion:
C = A * B
= (A.re + A.im j) * (B.re + B.im j)
= (A.re * B.re - A.im * B.im) + (A.re * B.im + A.im * B.re) j
Where of course j*j = -1.
If the real and imaginary parts are stored in separate planes, this translates trivially to a set of SIMD instructions, but normally they are stored as (real, imag) pairs.
VLD2
Here is where VLD2 comes to the aid of the weary programmer. It will automatically unpack 2-element fields into separate registers and simply allow you to write the code as if the data was stored as planes to start with.
It wasn't quite clear from the documentation how it handled more than 4x2 elements but with an experiment I worked it out and it does the thing you'd expect, allowing you to use quad-word ops.
Memory:
$00000000: a.real a.imag b.real b.imag
$00000010: c.real c.imag d.real d.imag
LDR r0,=0
VLD2 { d0-d3 }, [r0]
Registers (as float2)
d0 a.real b.real
d1 c.real d.real
d2 a.imag b.imag
d3 c.imag d.imag
Registers (as float4)
q0 a.real b.real c.real d.real
q1 a.imag b.imag c.imag d.imag
Code
By unrolling the loop 4x in SIMD and 2x in instructions one can perform 8 complex multiplies per loop:
@ r0 is address of C
@ r1 is address of A
@ r2 is address of B
cmult8:
@ q8, q10 = A[0-7].real
@ q9, q11 = A[0-8].imag
@ q12, q14 = B[0-7].real
@ q13, q15 = B[0-7].imag
vld2.32 { d16-d19 },[r1]!
vld2.32 { d24-d27 },[r2]!
vld2.32 { d20-d23 },[r1]!
vld2.32 { d28-d31 },[r2]!
vmul.f32 q0,q8,q12 @ a.r * b.r [ 0-3 ]
vmul.f32 q1,q9,q12 @ a.i * b.r
vmul.f32 q2,q10,q14 @ a.r * b.r [ 4-7 ]
vmul.f32 q4,q11,q14 @ a.i * b.r
vmls.f32 q0,q9,q13 @ - a.i * b.i [ 0-3 ]
vmla.f32 q1,q8,q13 @ + a.r * b.i
vmls.f32 q2,q11,q15 @ - a.i * b.i [ 4-7 ]
vmla.f32 q3,q10,q15 @ + a.r * b.i
vst2.32 { d0-d3 },[r0]!
vst2.32 { d4-d7 },[r0]!
mov pc,lr
q4-q7 are the callee-saved registers, so I simply avoid having to save them by using the others.
There is a few cycle stall for the stores at the end, but in a loop one can load the next 8 complex values before the store to avoid it.
C, NEON
I started pulling some of my experiments together into a prototype today and started to hit some annoying issues: pretty much anything in to do with large arrays of floats in C is 3-4x slower than doing it in NEON.
I can feel a lot of NEON coming on ...
FFT convolution
So i looked into FFT convolution a bit more and nutted out a couple of useful things.
Two for the price of one
The real and imaginary parts of a complex DFT are basically independent if one performs linear operations on them in the complex space.
i.e. if you take two separate (real) images A, and B, and interleave Ai and Bi into a complex image C with Ci = Ai + Bi j, then you can do operations like a convolution in the fourier domain, and after the inverse, reversing the combination trick gives you the two separate images processed with the same operation. Nice.
I'd read this before but the explanations always got hairy - good news is it just works if you don't need to know anything about the signal in the fourier domain, and are just interested in processing each element independently using linear functions.
Cache friendlish 2D operations
Typically when using an FFT operator for 2D signals one does a couple of operations:
- forward transform of one or more signals.
- process each element by element.
- inverse transform.
But internally a 2D FFT is implemented as a two separate passes, on the rows, then on the columns (or visa-versa), and typically might be implemented with two passes:
- forward/inverse transform rows
- transpose result
- forward/inverse transform rows
- transpose result
ffts only has a single dimensional complex FFT available, so I had to implement the 2D myself. But this provides further opportunities - since for this application I don't particularly care where the various coefficients are, I can just treat each as a separate calculation.
It lets me avoid 2x transposes and also improve the cache coherence for the filter step.
- forward transform rows
- transpose result
- for each row
- forward transform row
- apply convolution/filter on row
- inverse transform row
- transpose result
- inverse transform rows
On my test example this version ran in 73% of the time compared to a fully separate 2D convolution.
NEON cmult
I also wrote a NEON complex array multiply. With LD2 this turns out to be quite simple code although I also interleaved a loop to avoid some stalls. 35 cycles to do 8 complex multiplies.
This ran at 4x the gcc performance of a simple C implementation.
Example
Filtered with a simple low-pass pedestal filter. This takes under 200ms on a beagleboard-xm, on which the break-even point for a 2D time domain convolution is around 15x15 or so (using custom NEON code). Obviously I still have some transposition issues - this is one of the things that always gives me the willies with using FFT for signal processing. (Actually I think it's a bug in ffts, it doesn't seem to like multiple plans being created at the same time, this is the same result as if the inverse fft plan was the same as the forward one).
Update: Just a bug - ffts doesn't implement inverse properly on NEON yet, so i'm just getting 2x forwards which mirrors both axes.
Update 2: ffts is now simple to build and inverse and a few other things have been fixed as well. By doing the two at once trick above, and using some NEON for type conversion and clamping, I have the beagleboard-xm (@600Mhz) doing a full byte image to byte image round trip for a Wiener deconvolution using a non-separable point spread function in about 80ms per 512x512 image.
ARM/NEON FFT, transpose, & cache fun.
For various reasons i've had to look into using an FFT to do some image processing - mostly about performance and scalability - and i didn't really want to deal with FFTW or anything too complicated. I couldn't even find a reference to the performance of a typical ARM chip at doing 2D convolutions (at best all I found was FLOP counts which don't mean much to me).
FFTS - New SIMD FFT library
But I was lucky that a new SIMD enabled FFT library 'fastest fft in the south' - ffts from work on a thesis (afaict) has just shown up, and it supports NEON. I don't know how I found it now - because I just tried to search for it now to get a link to it and I couldn't find it again, even knowing the name, hosting site, author ... from my blog stats fft's are searched for a lot, but for some reason google is shit at finding relevant results. Might've been through stackoverflow.
Anyway - it's still in early stages but with a couple of changes from the author I got it to build on the beagleboard-xm.
It seems fast, but I don't have a handle on how fast fft's are on this hardware ... Nor have I yet written the algorithm I need to test using it. Working in the frequency domain always gives me the willies, but at least C supports complex maths directly.
2D ... transpose?
No 2D FFT at the moment, but 2D is just implemented as FFT in one dimension then the other. So for practical purposes this means along the rows then columns. Which means a transpose ...
Knowing the cache penalty I expected from implementing a straight element by element transpose I tried implementing one using tiles. Works fine, and pretty fast for small image sizes, but for 512x512 (complex float) things really start to slow down ... a lot.
I tried various tile sizes and although 16x16 helped it didn't help much ...
Avoid those redundant copies?
It's all down to the cache. That size just seems to be near worst-case in terms of address aliasing between the source and the destination. The only fix is to change the addresses used ... and the only way to do that is to use a tertiary buffer.
One normally avoids 'redundant' copies, but in this case it's akin to a scatter/gather into LDS, and global memory is only ever accessed in full cache lines (ideally - although from measurements that is less important than just doing runs).
So by transposing the data from the source tile into the buffer first, and then just memcpy'ing that out to the target in rows, I gained a nearly
10x
6x speed improvement for the 512x512 complex float case, and the transpose now scales linearly with the image size (it's about 3ms 4ms for two transposes). With the fixed size of the temp buffer, the compiler generated better code too (although the code it generated before was quite poor), although it's the cache issues that totally dominate the performance regardless.
I could always do an in-place transpose with this as well, which could be handy.
I always 'knew' this stuff, but desktop cpu's have such a large cache and performance it usually doesn't matter (much), but last time I had to really deal with it was writing code for my Amiga 1200. And that was some time ago.
Update: Fixed the numbers after actually verifying the code worked - i.e. fixing the bugs. Still very much better.
NEON, timing, object detection
Well it's been an all-NEON week and together with some very poor sleep, a hangover, and bad hayfever ... i'm pretty much over it.
But I kind of have some interesting code that manages to coax a bit of performance out of the little beagleboard-xm i'm using for coding at the moment; memory is the biggest bottleneck there. It's not the target platform, but it provides a well defined minimum baseline. I also finally hit a very measurable problem with the small cache on it ... processing 512x512 images as floats just happens to be a bad size when you go over 16 rows in a vertical span - worse than 2x performance loss for some of the code.
I also found a new (to me) fft library for NEON that I will post more on once I get it to compile.
I was looking up something and (re)came across the nice little cortex-a8 static code analyser and put it through it's paces (somehow I missed that it was just a web application last time). Learnt a bit about cycle timing and dual issue, it's got a couple of bugs but works pretty well. The display of the SPU timing tool would be nice though.
Anyway for some reason I thought vext only worked on double's (probably since vtbl does), but on seeing it worked for quads due to something else I was poking at, and how quads interacted with each other (the ARM documentation on cycle timing isn't as clear as it could be), I thought i'd go revisit the LBP object detector I wrote as I remembered I didn't use quads there. I ran a whole bunch of variations of the inner loop through the tool and shaved about 7 cycles off the time. Not bad when it was only 33 to start with. Unfortunately I ran out of NEON registers (they were already all used) and had to resort to swapping 2 individual byte constants through q15 - all because vand.u8 doesn't support a general 8 bit immediate ... otherwise i could've gone 2 better (sad face).
Anyway, I gave it a go on my 'cheapie' tablet for the first time. It's fairly comparable in performance to the Galaxy Note I used last time, it's only a bit slower.
Cut a long story short, 130ms average for the original version, and now it's down to around 114ms (friggan timing stuff is all shot on this machine so it jumps around a lot, might be scheduler related, or debug output from android). Dunno if i added some bugs - it seems to work 'at all' which means they can't be big if they are there. Not quite as good as the timing analyser suggested - but then that is modelling an A8 and this tablet has an A9 which changed some of the features I was using, and I only analysed part of the loop - but all-in-all still worth the effort for something which I thought was already as tight as possible. Actually I thought it was a bit better than that at first because when I changed back to a 17x17 search window I forgot to adjust the search parameters, so it was detecting faces at about 35fps vs 30fps (search range of 6x to 20x, rather than 2x to 12x as my original test - minimum face size of (17*6)x(17*6) - which is still reasonably small on a webcam).
The better-than-1 instruction classifier!
Now i've got the classifier down to well under 1 instruction ... I should really work on improving the detector quality. I would really like to know if it can be made into a decently robust detector or not - because if it is it could be quite useful: it's trivial to train, has tiny classifiers, and can be made to run very fast on modern hardware because it is fully parallelisable down to the SIMD level, relatively cache friendly, and even has a deterministic running-time.
I've a few ideas but need to set time aside.
I've also been switching around a lot at work lately, and that's throwing me around a bit (not to mention the hayfever). When I switch between diverse areas such as NEON coding, Android applications, OpenCL, Java applications, JNI, C, jjmpeg, RESTful web services, databases ... it's taking a day or so to fully context switch, which means it's a bit hard to 'hobby' on something at the other end of the spectrum at the same time.
Parallella 2
So I start the day contemplating writing some NEON code (and as usually happens - that was from the moment I was awake), and I finally got the Parallella slogan 'A super computer for everyone'.
These days we can get more FLOPS than we can imagine for a few dollars - for the performance, GPU's are cheaper than anything that has ever come before them - but can anyone get those flops out of them?
Threads - are hard enough. And they don't even get you very far.
OpenCL - is hard. If threads were hard enough, try a SIMT programming model. Even when you know what you're doing it can still be a lot of work because once you go beyond simple 'per pixel' type algorithms you have to do all sorts of tricks to get the performance. Again a lot of fun, but rather expensive for whomever is paying the bills. OpenCL is another option for accessing SIMD units which is at least improved over intrinsics and assembly language - but it still has a lot of requirements and overheads which make it harder to code. Any any attempt to reduce that complexity through abstraction - will reduce it's performance.
Assembly language (for SIMD coding) - is even harder. It's fun, and I enjoy it (well, so long as it isn't something as fucked up as x86), but even I sometimes just want a result and not to have to deal with the complexities. But without it you're leaving a big chunk of your CPU's performance on the floor - as there's no real practical way to access the SIMD units otherwise (i include 'intrinsics' as 'assembly language' - TBH it's easier just writing the assembly).
One can get away with using pre-written libraries some of the time - but someone still has to write those libraries, and sometimes they aren't available. And even if they are libraries come with their own costs - such as first learning how to use their API, and then finding their bugs and limitations and learning how to work around those.
The Eiphany architecture does away with a huge amount of complexity on the hardware side - because it needs to to fit on the chip - but it also means it does away with a huge amount of complexity on the software side too. There is no need for SIMD as you have a ton of processors, so there is no need to learn how to write SIMD software. And since it isn't a wide vector processor, there's no need to support dozens of in-flight hardware threads and 'wavefronts', and all the complexity of coding they provide. And this goes double for compiler writers - trying to auto-vectorise code still doesn't work very well after plenty of attempts, and if there are no 'too hard to use' instructions, there's no wasted silicon either. There just isn't need for much abstraction because there isn't anything to abstract. I think it doesn't even have cache - it just has local memory - with fast access, and slower memory as you go further from the chip.
The 16 core chips might just be teasers, but 64 cores is when things start to get interesting.
Will one such architecture be the be-all and end-all for processing? Dunno. The HSA stuff from AMD+co is all about moving the processing to where it best fits. For 'wide loads' this will be a GPU, for 'branchy' stuff it will be a CPU. But GPU's are converging on CPU's anyway - the GCN ISA looks more like a scalar cpu + wide SIMD unit than a GPU. It's the complexity of the total solution that has me most worried though - can AMD pull it off?
Complexity in general is a form of vendor lock-in, so i'm all for anything that reduces it.
Update 19/10/12: So well, I put my money where my mouth is, at the moment I've chucked $550 into the hat.
One insomniacal morning this week I had a look at their facedetect code. Well, ... it's certainly not easy. Took them 7 weeks to write - apparently that indicates it is easy, but then it is a whole new architecture. Then again OpenCV is a pretty horrible library to start with.
I'm not sure on the performance as they don't specify which 'ghz class x86 cpu' they used (and even if they did that wouldn't help much), and any windowed face detection algorithm is highly dependent on the search parameters (it's in the code, but there's a lot to look through at 4am in the morning). But I think they were searching from scale 1 which is by far the most expensive step. It's a pretty strange application to port actually because windowed/cascaded object detection is such a shit algorithm fit for ANY cpu. Let alone one that is optimised for floats.
You'd think something like JPEG or video DCT would be a good example. Wavelets should be a good fit too. But if they really want the punters excited, show a video decode, or even a `phong shaded boing' demo. Fibonacci sequences ... jesus h christ.
The way they wrote the code reminded me more of SPU programming than anything else, but without all that fucking around with SIMD code required to get any performance out of it.
So all that and the fact i'm pretty sick of 'closed' hardware is why I put the dough up. I guess it wont make it anyway with only a week to go but we'll see. It's about the same amount my OpenPandora order cost me ... I wonder which I'll get first ...
Oh, and that it looks insanely fun to code for, not to mention being almost exactly the hardware I want for work ... ;-)
Parallella
Adapteva have a kickstarter project to create a $100 highly parallel computer with an "open" architecture.
It's a pity to see they aren't getting much traction - compared to other similar projects. I guess there might be a bit of SBC fatigue setting in, and the RPI seems to be getting all the limelight, even though there's no real comparison - generic ARM board with a proprietary VPU and GPU vs a highly parallel computer which is mostly open.
This is really a lot more interesting - not only from the architectural standpoint, but because it's actually an open platform - by the guys actually designing the chips too. This alone makes it a much more interesting prospect beyond the mere performance numbers and price. e.g. I already know the programming model and instruction set from a simple pdf download, without any NDA or costs. And it's an interesting model - almost a MISC cpu core (minimal instruction set) with ARM-like mnemonics, 64 registers but the bottom 16 map 1:1 to ARM usage, and a zero-page style (6502 thing) optimised 16-bit version of each instruction for a smaller sub-set of registers/offsets. Flat address space, localised memory, DMA engines, etc. (nothing I saw about about MMU/context switching though - although both are impediments to raw performance).
As we've seen with the Allwinner A10 stuff - having a cheap SOC is one thing, but without documentation and with proprietary components it's a much much less attractive deal. It doesn't matter how fast your GPU or VPU is if you can't actually use it. Reverse engineering efforts like lima are all well and good but they are a very slow and difficult way to get anywhere, and may never succeed (and from the details they've found so far, it may be impossibly complex to programme for anyway). And they have real boards - i'm not sure what the rhombus guys are doing but they keep talking about 'scaling up to millions of boards' yet don't seem to be able to get a few 10K$ together to do the hardware design. And after 3 years of talking still don't seem to have gotten anywhere. Or the OpenPandora guys who used such a complex device as the OMAP that they wasted big money and many years before they got it to function reliably.
I'm not really one to contribute to kickstarter, but maybe in this case i'll put my money where my mouth is and put up some dough, even if it looks like they wont make the target. And that just seems to be down to some poor marketing. A video with some HD video encoding or decoding would get the kids excited (sadly this is all anyone seems to care about for these low power computers), not a picture of an ammeter or some guy gushing about how fucking excellent their shit is (true as that may be!).
Update: If you read this far, see also the follow-up post.
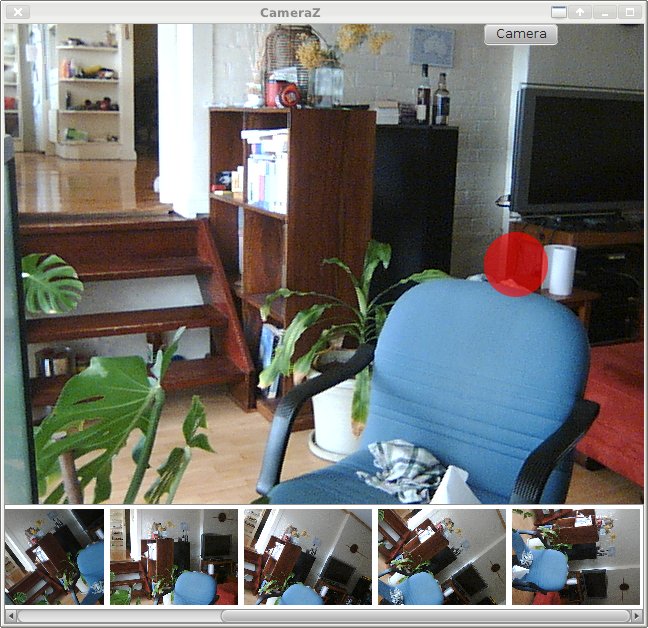
JavaFX USB Camera App for Linux
Well I thought of something relatively simple I can do with JavaFX to get familiar with it, and maybe even end up with a useful tool. And that is a Linux web-camera application - i.e. something like Cheese.
I've been playing with the idea for a week or so but haven't felt like hacking much for various reasons. Last night was a wild storm, and the wind, rain and hail, together with the neighbours broken gutter and hayfever, it kept me up much of the night. I thought rather than struggle painfully with work i'd struggle painfully with some of my own hacking instead ...
A few hours poking around later ...
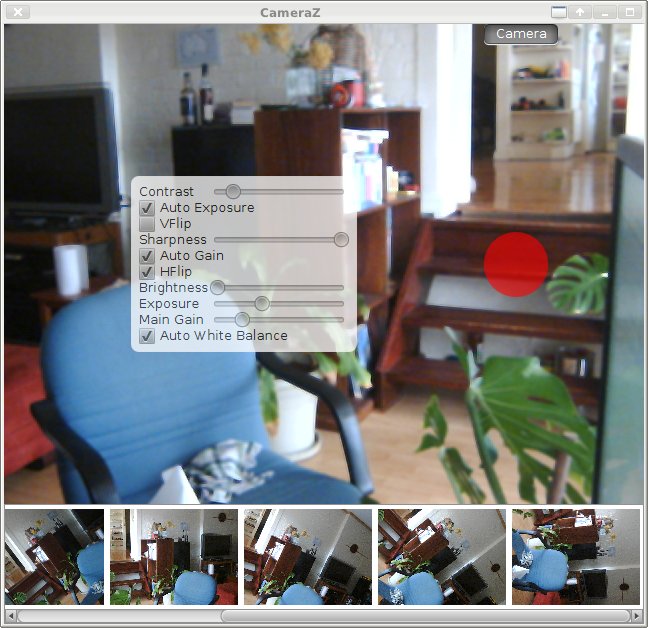
The red button takes a picture, although it just stays in memory at the moment. Then including the dynamically generated camera controls ...
Along the way I found a bug in v4l4j which was fixed very promptly - thanks Gilles.
It will let me tie in the jjmpeg code as well, if I get that far. And maybe even socles for some OpenCL processing (might get me off my arse to fix the socles filter graph stuff). Right now it doesn't do much, but on the other hand it's an almost embarassingly small amount of code too.
Layouts
So as usual - the layouts are the bane of any GUI developer. I'm using a GridPane as the base element for the on-screen controls, but it just isn't cooperating completely. e.g. the cells aren't aligning the way i tell them to - not unless I create a single-cell GridPane and align that. I guess i'm missing something, but that's all part of the learning curve no doubt.
JavaFX vs Swing
Performance is a good bit better than swing - a simple 60Hz webcam view is chugging along at about 35% cpu in Swing (the v4l4j bundled demo), whereas JavaFX is sitting around 10%. Although it goes up fairly quickly once you add blended widget overlays.
The overlays are a lot easier to code too, as are any animations and 'flashy shit', of course.
e.g. Half an hour later and I added some animation, taking a photo has it jump down to the list below, and it then fades in.
Effects
Although JavaFX has some "FX" which can be applied to scene graph nodes, i'm not sure it will be useful here. Apart from being a bit limited, the 'pulse' and asynchronous nature of the way the result can be grabbed to the host probably means it can't be used for video processing. One can have 'off-screen' scenes I believe, although i'm not sure exactly how the timing stuff is then handled.
Actually it's a task well suited to OpenCL, so if and when I get there, i'll probably just use that. It's a pity that JavaFX wont talk to OpenCL directly and the data will have to do a round-the-world trip across the PCI bus, but at webcam resolutions it shouldn't be a big issue.
As far as a 'camera app' goes, i'm personally more interested in other types of features anyway - e.g. automatic candid shooting (such as avoiding closed eyes or turned heads) for a party, or various types of image enhancement or degradation that can't be expressed using the current JavaFX effects tree.
Video ...
Another hour of hacking ... I added video recording to it via jjmpeg. I'm using mjpeg at the moment which seems to be about the only decent 'working format' I can find (fast to encode, easy to seek, commonly readable, etc). I threw everything on another thread so it easily starts recording without a glitch (at least on the workstation). It's using about 60% cpu (of 1 core) in total on this machine to capture VGA @ 60fps (although i really need to try it on a slower machine).
If only sound was that easy ...
My thinking would be that videos are recorded using a format suitable for recording (a fixed known format, high quality, low overhead, easy to manipulate), and can then be exported to another later (e.g. using ffmpeg command line).
Actually on jjmpeg, I guess I should revisit it now FFmpeg has released 1.0, maybe the api will be stable for a while. It's on the TODO list ...
I haven't checked anything in yet but it'll probably end up in mediaz/fxperiments/CamZ eventually.
Update: So I added a separate record button and flashing text and just checked it in as is, warts and all. I put it in MediaZ as a "top level" sub-project rather than inside fxperiments. Last weekend I updated jjmpeg to FFmpeg 1.0, so I changed it to use that (and found a lot of bugs along the way).
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!