About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

SNAFU!
I came across this "Kid Safe" site whilst searching for something unrelated. Just a sunshiney wrapper to Wikipedia by the looks.
The thing that piqued my interest is that many other 'online dictionaries' were abbreviating the 'fucked' to 'f*@#$d' or 'frigg'n', you know, the ones aimed at adults and not kids.
You know what so-called `dictionaries' it isn't 'friggan', it's fucked' and you're simply incorrect. SNAFU indeed.
Get it right.
Even a `kid-safe' site can!
A screenshot to preserve it for posterity:
... I guess that's what they get for appropriating Wikipedia.
And why Australian schoolchildren would be interested in some obscure dead president of the USA is beyond me ...
64 core Parallela & ARM A9 Zynq
Well it looks like the Parallella endeavour did get funded after-all (just minutes ago). They only really got organised in the last 3 days so I really thought it was too late but they managed to get the word out and excitement up enough to make it.
Well done.
As I said previously, the 16-core chip is a teaser and the 64-core is where the action is ... So I was pleased they offered a guaranteed 64-core version once it was clear that the $3M target was a bit optimistic. So even I, the cynical old c**t that I am, got caught up a bit in it myself and went for the 64 core chip plus the early 16 core one, cases and a t-shirt. A bit of an indulgence but I can afford it.
I'm sure most people don't really understand what they're getting into (that's pretty much the modus operandi of Kickstarter), but a Zynq board for $100 is still good value apparently even without the floating-point accelerator tacked on.
Although they just made it now, it's still open for a few hours, so get over there and have a poke if you're interested in a fully documented open embeddable low-power platform - i.e. ALL of the components will be documented and include ALL the free software to access it, including the accelerator. (well, this is what is promised, i'm not sure how far it stretches to the ARM/Zynq, but I presume that is already covered elsewhere).
This is in stark contrast to other 'open' boards such as:
- Raspberry PI - GPU is completely closed. The graphics driver is still just a big binary blob despite the simply fraudulent recent announcement that it was now 'fully open'. One wonders at the timing of that announcement.
- Beagleboard & friends - GPU is completely closed. The DSP and most of the on-board hardware is well documented but the OS it runs and the compiler is proprietary (last i looked).
- Allwinner A10 - GPU and VPU are both completely closed. Even if the lima driver ever gets there, it wont be thanks to the vendor.
- Any other ARM SOC you care to think of: programmable GPU ALL closed, VPU ALL closed.
As the basic board comes with a 'Zynq' processor, which is a dual-core A9 plus a FPGA on chip, it opens up more than just parallel processing to 'the masses' to include reconfigurable hardware too. I don't know much about these but I have it on good authority that they are very cool chips and i'm looking forward to investigating that aspect as well - if i ever get the time to (the lack of free tools there might impede too).
Given this open nature i've been a bit bummed by some of the hostile reception it's received in some of the 'open hardware/software' forums and mailing lists. Come on fellas, the world is big enough for more players - no need to get so defensive. And given how much of a whinge they've all had about vendor documentation, GPL violations, tainting buggy binary driver blobs, and everything else the cool reception is more than a little baffling. If nothing else some competition has to help making progress with other vendors who have all closed ranks.
Scalar vs SIMD, not all FLOPS are equal
I think some just don't see what the big deal is - it's just a chip not a solution, so and so have a chip that does x flops too, blah has something coming that will blow it all away, or those total flops just aren't that much ...
The problem with marketing numbers is that they're just marketing numbers. Peak FLOPS are impossible to achieve with any cpu and any algorithm - but the main avenue for increasing the FLOP count for the last 20 years - SIMD - only makes this much harder to achieve.
GPU's only make this worse. They throw so much hardware at it you still get very good results - but they aren't efficient at many tasks, and difficult enough to programme for the ones they are.
I'm sure you'd have to be living under a rock to miss the fact that when the Playstation 3 came out, a lot of developers made a lot of noise about how difficult it was to programme for. If you put in the time - and you really had to resort to assembly language - you could get phenomenal through-put through the SPUs, but if you didn't, all you had were 6 fairly gutless cores which were on top of that - a bit tricky to use. And it used a lot of power to get there.
Although the Eiphany shares some of the trickiness of use that the SPU's do (including the cache-less local memory, although it's easier to access off-core memory), simply because it is scalar a higher flop utilisation rate should be achievable for normal code. Without having to resort to assembly language or even worse - intrinsics. Not to mention the power differential: 90 odd gflops for the 64-core version ... in 5w system power.
A floating point MUL only has a latency of 4 cyles too - rather than the 7 on the CELL or 6 (iirc) for NEON, which makes the compiler or assembly language writer's job of scheduling that bit easier as well. Although assembly is an absolute must for NEON, the instruction set it so simple and there are so many registers i'd be surprised if it was needed in practice for the epiphany core.
Another point about competitors - ziilabs thing looks awesome! An embedded chip with a programmable multi-core co-processor! Yay! Oh, I can't actually get a machine with one in it? Oh. It only runs Android - a cut down, appliance version of Linux? Boo. Even if you could get one the grid-cpu is proprietary and secret and only we're allowed to use it, and you must go through the framework we provide? Blah, who cares.
Nothing's perfect
Engineering is not mathematics or science. Mathematics is absolute. Science is knowing to within a known degree of knowing. Engineering is a constant compromise. The real world has a habit of getting in the way. Cost, time, knowledge, physics, they all conspire to prevent the attainment of mathematical perfection.
The human curse that we all bear is that if we ever actually got what we truly wished for, we'd just think of something else we wanted.
PS This list is just my take on a fairly quick reading of the architecture documents and instruction set, it may contain wildly inaccurate misreadings and other mistakes.
- Software
- Well they're opening everything up for a reason, the 4 (or 5?) man team just doesn't have the resources to fill out everything. It's cheap enough that there should be no real barriers to entry to poking around, and the more that poke the more that gets done for free. This will be an interesting test to see how a loose group fares against multinational corporations and commercial standards bodies in coming up with usable solutions.
So it might be a while before X is accelerated, if ever.
The thing that most gives me the willies is that the sdk is based on eclipse, but it uses gcc as the backend anyway.
- Memory
- The 16 core version only has 32K SDRAM per core and 512K total per chip. And that includes both instruction and data. This per-core amount is the same as the cache on most ARM chips and will be a bit tricky to deal with. However this isn't a hard limit, just the limit on what is cheapest to access. OpenCL kernels are usually a lot smaller than this though, and so you can certainly get real work done with it. Not being confined to the OpenCL programming model would also enable efficient implementation of streaming (which is another way to save memory use).
The low latency instructions means loops wont have to be unrolled so much to hide them, so it should be able to achieve a higher code density anyway (not to mention the 16-bit versions of every instruction).
- No cache
- Only local memory. Programmers do hate this ... but the benefits you get from not having one are worth it here. A lot less power and silicon on the hardware side, and even though it might be a bit tricker to write efficient code, you're not getting hit with weird an unexpected results either because some data size hit cache tag aliasing. It goes a bit further than that too - no need for hardware memory barriers either, a write or read is a write or read to or from the target memory, not some half-way house. No cache snooping required.
I thought this (LDS) was one of the coolest features of SPUs, and it's a must-have in OpenCL too.
- Latency
- As one goes further from your local cell, the latency of memory access goes up quite quickly because as far as I can tell, each lane only goes one over and it requires multiple hops. But application-accessible DMA can be used to hide this and since you'll use it with the small local memory size anyway, it kind of comes for free.
- Memory protection, virtual memory
- None at all whatsoever on the accelerator. This is another bullet point as to how it achieves such a high flops/watt ratio.
- Hardware threads
- None. Rather than hide latency using multiple threads, one uses DMA.
- Synchronisation primitives
- None none that I noticed beyond a test and set instruction. This is a bit of a bummer actually as this kind of stuff can be very cool and very fast - but unfortunately it is also a gigantic patent minefield so i'm not surprised none is included. I'm talking about mailbox queues and mark/release type instructions for non-blocking primitives.
Since a core can only talk to its neighbours, this is probably not so useful or important anyway now I think about it.
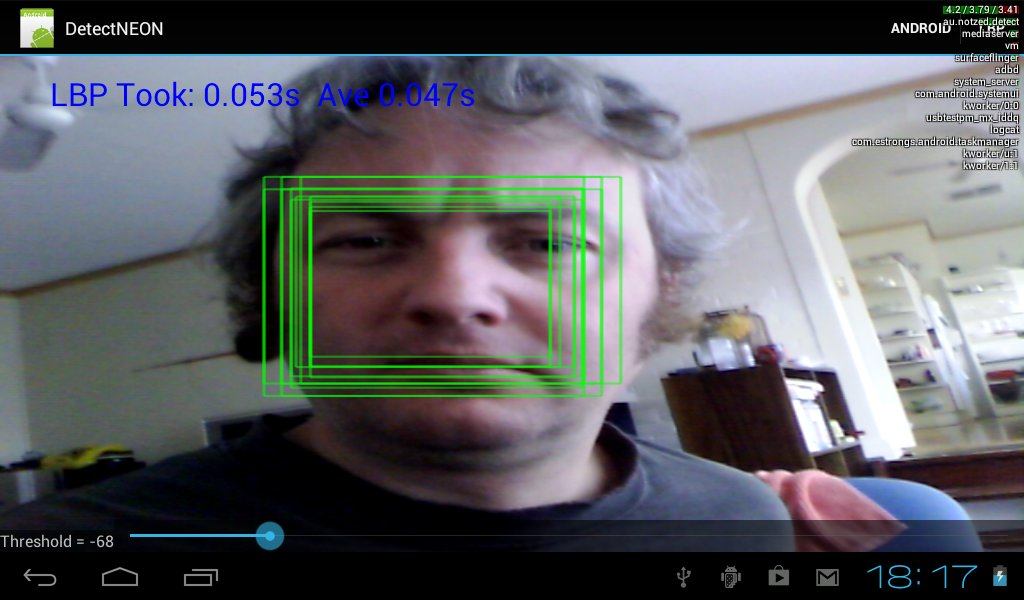
Android face detector demo
First things first, this is not about using the android api to detect a face, it's about some code i've been experimenting with over the last few months.
I decided to just upload the skeleton demo application i've been using for testing the detector on Android. It might give me the impetus to spend some more time on it.
I've put the package on google code in the MediaZ project as DetectNEON-0.apk (for want of somewhere better to put it). Note that there is no public source for it at the moment.
Update: I was a bit too lazy and only implemented code for a front-facing camera. I just uploaded another package DetectNEON-1.apk which might fix it, or just break it for everything.
The app has an inconveniently placed slider that lets one adjust the matching threshold, which may be required under different lighting conditions or due to the qualities of the camera sensor. One can also switch between android's 'built in' face detector and mine with the buttons at the top. The aspect ratio of the video display is broken, but that isn't what i was trying to test here. It is also obviously only displaying the raw hits and not grouping them in any way.
On my ainol elf 2 tablet the detector takes around 45ms on a 640x480 input frame using the settings i've set: minimum object size detected is 51x51 pixels, up to about 400x400. The code is single-threaded and I was using 'normal' mode for the CPU scheduler.
For comparison the Android face detector API takes about 500-600ms, although it does search to a smaller size - which is a critical factor in execution time for sliding window algorithms.
It seems to work better than I remembered, but I think last time i tested it was late at night in a poorly lit room.
Update 2: Just a bit more info that is scattered over the blog.
- The classifier is trained on very upright fully-front faces (the CBCL data set), so will not detect as wide a range of orientations as the typical OpenCV cascades.
- Once the training set is loaded into memory, it takes about 40ms to train a 17x17 classifier with approximately 10K images using simple Java code (i7 something cpu).
- Although there was a small amount of hand-tuning with the negative set, the training is deterministic and employs no reinforcement techniques such as boosting.
- The classifier is a fixed size in relation to the window size. The 17x17 classifier is about 2.5k bytes in total.
- There is no pre-processing of the input signal in this demo.
- Hence it is fairly sensitive to noise and camera 'qualities', however it returns a probability rather than a binary result, so can be adjusted for sensitivity.
- The NEON code classifies each single pixel in under 1 cpu cycle on a Cortex-A8 CPU.
- I've done no statistical verification on how well it works, and i'm mostly just surprised it works at all.
On NEON vs OpenCL
So I just reached a 'have output' milestone on some code i'm working on and I was reflecting on how much effort it was to code a similar algorithm in NEON in assembly language compared to OpenCL on a GPU.
In my case, NEON comes out on top in terms of 'developer productivity'.
- Mistakes crash a process - not your computer.
- Easier to debug in gdb (I know there are OpenCL device debuggers now, but not when I started).
- Better libraries.
- Not portable - but OpenCL isn't portable between device-classes either, and isn't available on every system.
- Easier memory management - it's just the same as C.
- Easier to bind with C code - it's just the same as C.
- Very low call overhead.
The last two points are quite significant. Because of the overheads of OpenCL you're forced to put big chunks of complex algorithm onto the device - not to mention the hairy code required to get good performance out of not-trivially-parallel tasks.
With NEON you only need to code the stuff that runs slower than it should in C (and despite all the years of compiler advances, there's still a lot of code like this), and just leave the complex business logic and outer loops to the compiler (it usually does an ok job at that). Even without resorting to exotic bit manipulation and in-register lookup-tables, such a simple operation as a "float - scale - clamp - byte conversion" (as typically encountered in image processing) is several times faster via NEON than in C, and not a lot harder to write.
It helps that NEON has a nice orthogonal instruction set with sane mnemonics and a healthy register count, unlike some other crap one could mention ...
Pity it's still slow!
The main issue is of course that these CPU's are pretty gutless, and you can't get the sort of performance you can out of a desktop machine, let alone a GPU (but those can't fit in your pocket either). Of course, this is the type of problem the parallella project is trying to address - but they seem to be having a bit of a kickstarter melt-down and haven't updated their project in a few days. Well one hopes the publicity gained helps them get something going anyway even if this particular effort fails.
Update: Well Adapteva finally put some more stuff up. I guess going for the 'cheaper/faster beagleboard' type thing is better than their original approach, even if it de-emphasises the parallel nature somewhat. Whether it's that or the request for more noise, it seems to be picking up a good amount, although $200K in 2 days is a big ask.
NEON complex multiply
In the last post I mentioned writing a complex multiply for NEON.
It's actually a good demonstration of the use of a NEON feature - data manipulation on loads, and it's quite trivial i'll post it here.
Complex Multiply
As one might recall, a complex multiply:
C = A * B
Is implemented as the expansion:
C = A * B
= (A.re + A.im j) * (B.re + B.im j)
= (A.re * B.re - A.im * B.im) + (A.re * B.im + A.im * B.re) j
Where of course j*j = -1.
If the real and imaginary parts are stored in separate planes, this translates trivially to a set of SIMD instructions, but normally they are stored as (real, imag) pairs.
VLD2
Here is where VLD2 comes to the aid of the weary programmer. It will automatically unpack 2-element fields into separate registers and simply allow you to write the code as if the data was stored as planes to start with.
It wasn't quite clear from the documentation how it handled more than 4x2 elements but with an experiment I worked it out and it does the thing you'd expect, allowing you to use quad-word ops.
Memory:
$00000000: a.real a.imag b.real b.imag
$00000010: c.real c.imag d.real d.imag
LDR r0,=0
VLD2 { d0-d3 }, [r0]
Registers (as float2)
d0 a.real b.real
d1 c.real d.real
d2 a.imag b.imag
d3 c.imag d.imag
Registers (as float4)
q0 a.real b.real c.real d.real
q1 a.imag b.imag c.imag d.imag
Code
By unrolling the loop 4x in SIMD and 2x in instructions one can perform 8 complex multiplies per loop:
@ r0 is address of C
@ r1 is address of A
@ r2 is address of B
cmult8:
@ q8, q10 = A[0-7].real
@ q9, q11 = A[0-8].imag
@ q12, q14 = B[0-7].real
@ q13, q15 = B[0-7].imag
vld2.32 { d16-d19 },[r1]!
vld2.32 { d24-d27 },[r2]!
vld2.32 { d20-d23 },[r1]!
vld2.32 { d28-d31 },[r2]!
vmul.f32 q0,q8,q12 @ a.r * b.r [ 0-3 ]
vmul.f32 q1,q9,q12 @ a.i * b.r
vmul.f32 q2,q10,q14 @ a.r * b.r [ 4-7 ]
vmul.f32 q4,q11,q14 @ a.i * b.r
vmls.f32 q0,q9,q13 @ - a.i * b.i [ 0-3 ]
vmla.f32 q1,q8,q13 @ + a.r * b.i
vmls.f32 q2,q11,q15 @ - a.i * b.i [ 4-7 ]
vmla.f32 q3,q10,q15 @ + a.r * b.i
vst2.32 { d0-d3 },[r0]!
vst2.32 { d4-d7 },[r0]!
mov pc,lr
q4-q7 are the callee-saved registers, so I simply avoid having to save them by using the others.
There is a few cycle stall for the stores at the end, but in a loop one can load the next 8 complex values before the store to avoid it.
C, NEON
I started pulling some of my experiments together into a prototype today and started to hit some annoying issues: pretty much anything in to do with large arrays of floats in C is 3-4x slower than doing it in NEON.
I can feel a lot of NEON coming on ...
FFT convolution
So i looked into FFT convolution a bit more and nutted out a couple of useful things.
Two for the price of one
The real and imaginary parts of a complex DFT are basically independent if one performs linear operations on them in the complex space.
i.e. if you take two separate (real) images A, and B, and interleave Ai and Bi into a complex image C with Ci = Ai + Bi j, then you can do operations like a convolution in the fourier domain, and after the inverse, reversing the combination trick gives you the two separate images processed with the same operation. Nice.
I'd read this before but the explanations always got hairy - good news is it just works if you don't need to know anything about the signal in the fourier domain, and are just interested in processing each element independently using linear functions.
Cache friendlish 2D operations
Typically when using an FFT operator for 2D signals one does a couple of operations:
- forward transform of one or more signals.
- process each element by element.
- inverse transform.
But internally a 2D FFT is implemented as a two separate passes, on the rows, then on the columns (or visa-versa), and typically might be implemented with two passes:
- forward/inverse transform rows
- transpose result
- forward/inverse transform rows
- transpose result
ffts only has a single dimensional complex FFT available, so I had to implement the 2D myself. But this provides further opportunities - since for this application I don't particularly care where the various coefficients are, I can just treat each as a separate calculation.
It lets me avoid 2x transposes and also improve the cache coherence for the filter step.
- forward transform rows
- transpose result
- for each row
- forward transform row
- apply convolution/filter on row
- inverse transform row
- transpose result
- inverse transform rows
On my test example this version ran in 73% of the time compared to a fully separate 2D convolution.
NEON cmult
I also wrote a NEON complex array multiply. With LD2 this turns out to be quite simple code although I also interleaved a loop to avoid some stalls. 35 cycles to do 8 complex multiplies.
This ran at 4x the gcc performance of a simple C implementation.
Example
Filtered with a simple low-pass pedestal filter. This takes under 200ms on a beagleboard-xm, on which the break-even point for a 2D time domain convolution is around 15x15 or so (using custom NEON code). Obviously I still have some transposition issues - this is one of the things that always gives me the willies with using FFT for signal processing. (Actually I think it's a bug in ffts, it doesn't seem to like multiple plans being created at the same time, this is the same result as if the inverse fft plan was the same as the forward one).
Update: Just a bug - ffts doesn't implement inverse properly on NEON yet, so i'm just getting 2x forwards which mirrors both axes.
Update 2: ffts is now simple to build and inverse and a few other things have been fixed as well. By doing the two at once trick above, and using some NEON for type conversion and clamping, I have the beagleboard-xm (@600Mhz) doing a full byte image to byte image round trip for a Wiener deconvolution using a non-separable point spread function in about 80ms per 512x512 image.
ARM/NEON FFT, transpose, & cache fun.
For various reasons i've had to look into using an FFT to do some image processing - mostly about performance and scalability - and i didn't really want to deal with FFTW or anything too complicated. I couldn't even find a reference to the performance of a typical ARM chip at doing 2D convolutions (at best all I found was FLOP counts which don't mean much to me).
FFTS - New SIMD FFT library
But I was lucky that a new SIMD enabled FFT library 'fastest fft in the south' - ffts from work on a thesis (afaict) has just shown up, and it supports NEON. I don't know how I found it now - because I just tried to search for it now to get a link to it and I couldn't find it again, even knowing the name, hosting site, author ... from my blog stats fft's are searched for a lot, but for some reason google is shit at finding relevant results. Might've been through stackoverflow.
Anyway - it's still in early stages but with a couple of changes from the author I got it to build on the beagleboard-xm.
It seems fast, but I don't have a handle on how fast fft's are on this hardware ... Nor have I yet written the algorithm I need to test using it. Working in the frequency domain always gives me the willies, but at least C supports complex maths directly.
2D ... transpose?
No 2D FFT at the moment, but 2D is just implemented as FFT in one dimension then the other. So for practical purposes this means along the rows then columns. Which means a transpose ...
Knowing the cache penalty I expected from implementing a straight element by element transpose I tried implementing one using tiles. Works fine, and pretty fast for small image sizes, but for 512x512 (complex float) things really start to slow down ... a lot.
I tried various tile sizes and although 16x16 helped it didn't help much ...
Avoid those redundant copies?
It's all down to the cache. That size just seems to be near worst-case in terms of address aliasing between the source and the destination. The only fix is to change the addresses used ... and the only way to do that is to use a tertiary buffer.
One normally avoids 'redundant' copies, but in this case it's akin to a scatter/gather into LDS, and global memory is only ever accessed in full cache lines (ideally - although from measurements that is less important than just doing runs).
So by transposing the data from the source tile into the buffer first, and then just memcpy'ing that out to the target in rows, I gained a nearly
10x
6x speed improvement for the 512x512 complex float case, and the transpose now scales linearly with the image size (it's about 3ms 4ms for two transposes). With the fixed size of the temp buffer, the compiler generated better code too (although the code it generated before was quite poor), although it's the cache issues that totally dominate the performance regardless.
I could always do an in-place transpose with this as well, which could be handy.
I always 'knew' this stuff, but desktop cpu's have such a large cache and performance it usually doesn't matter (much), but last time I had to really deal with it was writing code for my Amiga 1200. And that was some time ago.
Update: Fixed the numbers after actually verifying the code worked - i.e. fixing the bugs. Still very much better.
NEON, timing, object detection
Well it's been an all-NEON week and together with some very poor sleep, a hangover, and bad hayfever ... i'm pretty much over it.
But I kind of have some interesting code that manages to coax a bit of performance out of the little beagleboard-xm i'm using for coding at the moment; memory is the biggest bottleneck there. It's not the target platform, but it provides a well defined minimum baseline. I also finally hit a very measurable problem with the small cache on it ... processing 512x512 images as floats just happens to be a bad size when you go over 16 rows in a vertical span - worse than 2x performance loss for some of the code.
I also found a new (to me) fft library for NEON that I will post more on once I get it to compile.
I was looking up something and (re)came across the nice little cortex-a8 static code analyser and put it through it's paces (somehow I missed that it was just a web application last time). Learnt a bit about cycle timing and dual issue, it's got a couple of bugs but works pretty well. The display of the SPU timing tool would be nice though.
Anyway for some reason I thought vext only worked on double's (probably since vtbl does), but on seeing it worked for quads due to something else I was poking at, and how quads interacted with each other (the ARM documentation on cycle timing isn't as clear as it could be), I thought i'd go revisit the LBP object detector I wrote as I remembered I didn't use quads there. I ran a whole bunch of variations of the inner loop through the tool and shaved about 7 cycles off the time. Not bad when it was only 33 to start with. Unfortunately I ran out of NEON registers (they were already all used) and had to resort to swapping 2 individual byte constants through q15 - all because vand.u8 doesn't support a general 8 bit immediate ... otherwise i could've gone 2 better (sad face).
Anyway, I gave it a go on my 'cheapie' tablet for the first time. It's fairly comparable in performance to the Galaxy Note I used last time, it's only a bit slower.
Cut a long story short, 130ms average for the original version, and now it's down to around 114ms (friggan timing stuff is all shot on this machine so it jumps around a lot, might be scheduler related, or debug output from android). Dunno if i added some bugs - it seems to work 'at all' which means they can't be big if they are there. Not quite as good as the timing analyser suggested - but then that is modelling an A8 and this tablet has an A9 which changed some of the features I was using, and I only analysed part of the loop - but all-in-all still worth the effort for something which I thought was already as tight as possible. Actually I thought it was a bit better than that at first because when I changed back to a 17x17 search window I forgot to adjust the search parameters, so it was detecting faces at about 35fps vs 30fps (search range of 6x to 20x, rather than 2x to 12x as my original test - minimum face size of (17*6)x(17*6) - which is still reasonably small on a webcam).
The better-than-1 instruction classifier!
Now i've got the classifier down to well under 1 instruction ... I should really work on improving the detector quality. I would really like to know if it can be made into a decently robust detector or not - because if it is it could be quite useful: it's trivial to train, has tiny classifiers, and can be made to run very fast on modern hardware because it is fully parallelisable down to the SIMD level, relatively cache friendly, and even has a deterministic running-time.
I've a few ideas but need to set time aside.
I've also been switching around a lot at work lately, and that's throwing me around a bit (not to mention the hayfever). When I switch between diverse areas such as NEON coding, Android applications, OpenCL, Java applications, JNI, C, jjmpeg, RESTful web services, databases ... it's taking a day or so to fully context switch, which means it's a bit hard to 'hobby' on something at the other end of the spectrum at the same time.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!