About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Mailing lists. Or the lack of self censoring shame
I'm subscribed to a few developer mailing lists, not that I post too much anymore but I scan them occasionally. I also 'hang out' on a couple of OpenCL forums, or at least keep an eye out for something interesting going on.
Lazy kids of today
I'm a bit shocked at how little shame people have in asking obviously idiotic, lazy, indolent, somnolent, and torpid questions. I presume they are mostly students trying to get the internet to do their homework, which is bad enough to start with. But when they clearly don't have the faintest idea about basic software development, let alone advanced concepts such as parallel programming, you'd think they'd have the personal shame to get off their lazy fucking arses and try to learn a bit more on their own before begging experts for help and showing to the world just what a waste of space they are.
Being a newbie is one thing, we were all one once (although when I was a hacking newbie, I had no modem and no internet, so nobody to annoy but myself). But being a noisy, lazy, selfish, idiot is another matter entirely.
Particularly today - with such an enormous amount of quality information at our fingertips INSTANTLY. Doesn't anybody try to learn on their own? It works much more effectively than getting someone else to do the work ...
It seems that the easier it gets, the lazier people are.
Maybe it's too many single child or two-parents-working families - kids these days don't seem to even know how to eat properly with knives and forks or chew with closed mouths. Probably because they never have a sit-down meal with the old's as they're either working or out or don't care themselves. Or too many molly-coddling parents too scared to tell young Bruce or young Doreen that they aren't acting in an acceptable manner or that they fucked something up, least they hurt his or her feelings.
The arsehole brigade
Then there's the other type - someone who asks a question in such a way to imply that they're a bit lost and after some help. Then any advice given is bluntly and rudely rejected because they 'know' the real problem and you have it all WRONG. Yeah, that's why they came asking questions in the first place ... obviously.
Show us the sauce?
And everyone seems to think their crappy fucked up and not working piece of shit routine is so precious they wont post any of the source code - and then expect someone to blindly determine why it isn't working/isn't running fast enough/wont solve world hunger. If you're lucky they post some small chunk of some unimportant routine and even then miss the actually important bits.
I'm getting a bit sick of it to be honest - and tending to be less involved in the various forums as a result. What's the point? There's no peer-to-peer communication going on with the sharing knowledge and building of 'community' (whatever that's supposed to be) - it's all just a one way street of me me me, take take take. Particularly on forums for multi-national bodies and companies - they can pay someone to do that shit. At least they should have someone with some authority to tell people to get a clue or to grow up. Regularly.
Unfortunately when such policing exists it seems far more worried about 'top posting' in replies than anything else, which just goes to lower the tone even further. It's about fucking time people got over that by now. They've probably forgotten the reason they're even still complaining about it.
Disabling Focus in JavaFX
Had the need to disable focus on a ScrollPane (in the image viewer of the previous post) - for simplicity I wanted to keep the focus elsewhere.
Although one can set FocusTraversable to false and the TAB key will no longer iterate through it, it still gets focus when you click on it.
I had to sub-class the ScrollPane and override requestFocus to NO-OP.
scroll = new ScrollPane() {
public void requestFocus() { }
};
Obviously something to use judiciously, as it removes the ability for keyboard control of that Node.
Quick and Dirty image viewer: Eye of FX
Although it's pretty bare of features given it's long development, one of the tools I use quite often is Eye of GNOME. It feels like an Amiga tool - i.e. it's a GUI tool which is easily used from either the command line or in a GUI context. One of the more useful features is to give it a list of only a few files which you can flick through - rather than being forced to navigate through a complete directory listing as in other tools.
Well, where it is available - Image viewers seem to have a strange habit of disappearing from distributions because "mature with no bugs" seems to be interpreted by distribution vendors as "unmaintained". Sigh.
This is not a post about that ... but it is about a quick and dirty multiple-image viewer I needed for a project which I easily turned into a similar tool. I called it EOFX in homage to eog, even if Federico was the one who confusingly decided "Recents" was the most useful way to open a Save file requester in gtk+ applications (until that started showing up, I never new Recents even existed).
Although it's rather bare, it's functional and could be extended fairly easily. Scroll-wheel zooms, pointer pans, you can sort of navigate with the keyboard (if the slider has focus).
I used a trick to get the scrollbars to work properly - by placing the ImageView inside a Group inside the ScrollPane, zooming resizes the layout and forces the scrollbars as appropriate. Without that setting the zoom factor merely changes the rendering of the ImageView, and it doesn't work properly. And then you must restort to other nasty hacks to get it to size like binding dimensions and so on - which seems to be the method de jour in JavaFX circles, even if it just doesn't work properly (it still causes issues with automatic layouts). Unfortunately Group's also interfere with automatic layout so it might not work if I wanted to fix some of the zooming issues.
But one thing i've noticed about using JavaFX so far is that it just doesn't take much code to do common things. Although it isn't the prettiest or nicest implementation of it, this image viewer allows pan and zoom and flicking through a set of images in only a handful of lines of code. Just getting a basic version of this going in Swing (or any other toolkit i've used) requires a lot of custom code and faffing about.
As a bonus, I wrote the argument passing in a way which allows one to give it arbitrary URLs as well as files, it uses a file requester if no arguments are given (so can be launched by a desktop os), and it remembers the last visited directory if using the file requester (a pet peeve of many a similar application).
I've checked it into EOFX in MediaZ/fxperiments.
I can feel a JavaFX coming on ...
The project i'm working on has changed direction again, and part of that is a desktop version of some android stuff - and this gives me an opportunity to explore JavaFX more seriously. I guess I will soon see how it really stacks up.
Mythbusting for novices
One of the Mozilla guys had a go at mythbusting for HTML5.
Hint: Don't start busting your first myth by agreeing that it is true! And worse, then proceed to try to make excuses!
And worse again, claiming that it isn't their fault!
I made a couple of long comments on the blog and from one he accused me of 'standing in the way' of the project. I would think that trying to pretend that there aren't technical problems that need to be overcome is more likely to hinder a project than comments from the peanut gallery.
The adversarial attitude was a bit of a surprise actually - from a guy who is paid to be liked and to make people like his employer. He just made me want to troll!
It's not a political problem, it's a technical one
Unfortunately I didn't notice the 'evangalist' tag: the guy's just a talker. But no amount of talking will fix the technical problems in making a browser a viable application platform.
But I think given how much money and time has been poured into it already, one might reasonably come to the conclusion that the whole task is simply an engineering feat beyond the technology being used.
For example, although you could conceivably take an every day sedan and turn it into a usable armoured vehicle: this is just not "the way you do it" - at least, if you want to do it in a technically competent and cost effective manner.
This is how I see HTML5. Although you can do all sorts of amazing and tricky stuff with it, it's not the way you would choose to do it if you had a free choice in the matter and a wide experience of the options available.
Stick to your strengths (or, "The world is not enough?")
The delivery of information and entertainment through the world wide web was a revolution which has impacted all of our lives.
Should they not be satisfied with that?
This "holy grail" of a web delivery of desktop-style applications through a platform delivered by multiple vendors is an expensive experiment which looks set to continue.
SNAFU!
I came across this "Kid Safe" site whilst searching for something unrelated. Just a sunshiney wrapper to Wikipedia by the looks.
The thing that piqued my interest is that many other 'online dictionaries' were abbreviating the 'fucked' to 'f*@#$d' or 'frigg'n', you know, the ones aimed at adults and not kids.
You know what so-called `dictionaries' it isn't 'friggan', it's fucked' and you're simply incorrect. SNAFU indeed.
Get it right.
Even a `kid-safe' site can!
A screenshot to preserve it for posterity:
... I guess that's what they get for appropriating Wikipedia.
And why Australian schoolchildren would be interested in some obscure dead president of the USA is beyond me ...
64 core Parallela & ARM A9 Zynq
Well it looks like the Parallella endeavour did get funded after-all (just minutes ago). They only really got organised in the last 3 days so I really thought it was too late but they managed to get the word out and excitement up enough to make it.
Well done.
As I said previously, the 16-core chip is a teaser and the 64-core is where the action is ... So I was pleased they offered a guaranteed 64-core version once it was clear that the $3M target was a bit optimistic. So even I, the cynical old c**t that I am, got caught up a bit in it myself and went for the 64 core chip plus the early 16 core one, cases and a t-shirt. A bit of an indulgence but I can afford it.
I'm sure most people don't really understand what they're getting into (that's pretty much the modus operandi of Kickstarter), but a Zynq board for $100 is still good value apparently even without the floating-point accelerator tacked on.
Although they just made it now, it's still open for a few hours, so get over there and have a poke if you're interested in a fully documented open embeddable low-power platform - i.e. ALL of the components will be documented and include ALL the free software to access it, including the accelerator. (well, this is what is promised, i'm not sure how far it stretches to the ARM/Zynq, but I presume that is already covered elsewhere).
This is in stark contrast to other 'open' boards such as:
- Raspberry PI - GPU is completely closed. The graphics driver is still just a big binary blob despite the simply fraudulent recent announcement that it was now 'fully open'. One wonders at the timing of that announcement.
- Beagleboard & friends - GPU is completely closed. The DSP and most of the on-board hardware is well documented but the OS it runs and the compiler is proprietary (last i looked).
- Allwinner A10 - GPU and VPU are both completely closed. Even if the lima driver ever gets there, it wont be thanks to the vendor.
- Any other ARM SOC you care to think of: programmable GPU ALL closed, VPU ALL closed.
As the basic board comes with a 'Zynq' processor, which is a dual-core A9 plus a FPGA on chip, it opens up more than just parallel processing to 'the masses' to include reconfigurable hardware too. I don't know much about these but I have it on good authority that they are very cool chips and i'm looking forward to investigating that aspect as well - if i ever get the time to (the lack of free tools there might impede too).
Given this open nature i've been a bit bummed by some of the hostile reception it's received in some of the 'open hardware/software' forums and mailing lists. Come on fellas, the world is big enough for more players - no need to get so defensive. And given how much of a whinge they've all had about vendor documentation, GPL violations, tainting buggy binary driver blobs, and everything else the cool reception is more than a little baffling. If nothing else some competition has to help making progress with other vendors who have all closed ranks.
Scalar vs SIMD, not all FLOPS are equal
I think some just don't see what the big deal is - it's just a chip not a solution, so and so have a chip that does x flops too, blah has something coming that will blow it all away, or those total flops just aren't that much ...
The problem with marketing numbers is that they're just marketing numbers. Peak FLOPS are impossible to achieve with any cpu and any algorithm - but the main avenue for increasing the FLOP count for the last 20 years - SIMD - only makes this much harder to achieve.
GPU's only make this worse. They throw so much hardware at it you still get very good results - but they aren't efficient at many tasks, and difficult enough to programme for the ones they are.
I'm sure you'd have to be living under a rock to miss the fact that when the Playstation 3 came out, a lot of developers made a lot of noise about how difficult it was to programme for. If you put in the time - and you really had to resort to assembly language - you could get phenomenal through-put through the SPUs, but if you didn't, all you had were 6 fairly gutless cores which were on top of that - a bit tricky to use. And it used a lot of power to get there.
Although the Eiphany shares some of the trickiness of use that the SPU's do (including the cache-less local memory, although it's easier to access off-core memory), simply because it is scalar a higher flop utilisation rate should be achievable for normal code. Without having to resort to assembly language or even worse - intrinsics. Not to mention the power differential: 90 odd gflops for the 64-core version ... in 5w system power.
A floating point MUL only has a latency of 4 cyles too - rather than the 7 on the CELL or 6 (iirc) for NEON, which makes the compiler or assembly language writer's job of scheduling that bit easier as well. Although assembly is an absolute must for NEON, the instruction set it so simple and there are so many registers i'd be surprised if it was needed in practice for the epiphany core.
Another point about competitors - ziilabs thing looks awesome! An embedded chip with a programmable multi-core co-processor! Yay! Oh, I can't actually get a machine with one in it? Oh. It only runs Android - a cut down, appliance version of Linux? Boo. Even if you could get one the grid-cpu is proprietary and secret and only we're allowed to use it, and you must go through the framework we provide? Blah, who cares.
Nothing's perfect
Engineering is not mathematics or science. Mathematics is absolute. Science is knowing to within a known degree of knowing. Engineering is a constant compromise. The real world has a habit of getting in the way. Cost, time, knowledge, physics, they all conspire to prevent the attainment of mathematical perfection.
The human curse that we all bear is that if we ever actually got what we truly wished for, we'd just think of something else we wanted.
PS This list is just my take on a fairly quick reading of the architecture documents and instruction set, it may contain wildly inaccurate misreadings and other mistakes.
- Software
- Well they're opening everything up for a reason, the 4 (or 5?) man team just doesn't have the resources to fill out everything. It's cheap enough that there should be no real barriers to entry to poking around, and the more that poke the more that gets done for free. This will be an interesting test to see how a loose group fares against multinational corporations and commercial standards bodies in coming up with usable solutions.
So it might be a while before X is accelerated, if ever.
The thing that most gives me the willies is that the sdk is based on eclipse, but it uses gcc as the backend anyway.
- Memory
- The 16 core version only has 32K SDRAM per core and 512K total per chip. And that includes both instruction and data. This per-core amount is the same as the cache on most ARM chips and will be a bit tricky to deal with. However this isn't a hard limit, just the limit on what is cheapest to access. OpenCL kernels are usually a lot smaller than this though, and so you can certainly get real work done with it. Not being confined to the OpenCL programming model would also enable efficient implementation of streaming (which is another way to save memory use).
The low latency instructions means loops wont have to be unrolled so much to hide them, so it should be able to achieve a higher code density anyway (not to mention the 16-bit versions of every instruction).
- No cache
- Only local memory. Programmers do hate this ... but the benefits you get from not having one are worth it here. A lot less power and silicon on the hardware side, and even though it might be a bit tricker to write efficient code, you're not getting hit with weird an unexpected results either because some data size hit cache tag aliasing. It goes a bit further than that too - no need for hardware memory barriers either, a write or read is a write or read to or from the target memory, not some half-way house. No cache snooping required.
I thought this (LDS) was one of the coolest features of SPUs, and it's a must-have in OpenCL too.
- Latency
- As one goes further from your local cell, the latency of memory access goes up quite quickly because as far as I can tell, each lane only goes one over and it requires multiple hops. But application-accessible DMA can be used to hide this and since you'll use it with the small local memory size anyway, it kind of comes for free.
- Memory protection, virtual memory
- None at all whatsoever on the accelerator. This is another bullet point as to how it achieves such a high flops/watt ratio.
- Hardware threads
- None. Rather than hide latency using multiple threads, one uses DMA.
- Synchronisation primitives
- None none that I noticed beyond a test and set instruction. This is a bit of a bummer actually as this kind of stuff can be very cool and very fast - but unfortunately it is also a gigantic patent minefield so i'm not surprised none is included. I'm talking about mailbox queues and mark/release type instructions for non-blocking primitives.
Since a core can only talk to its neighbours, this is probably not so useful or important anyway now I think about it.
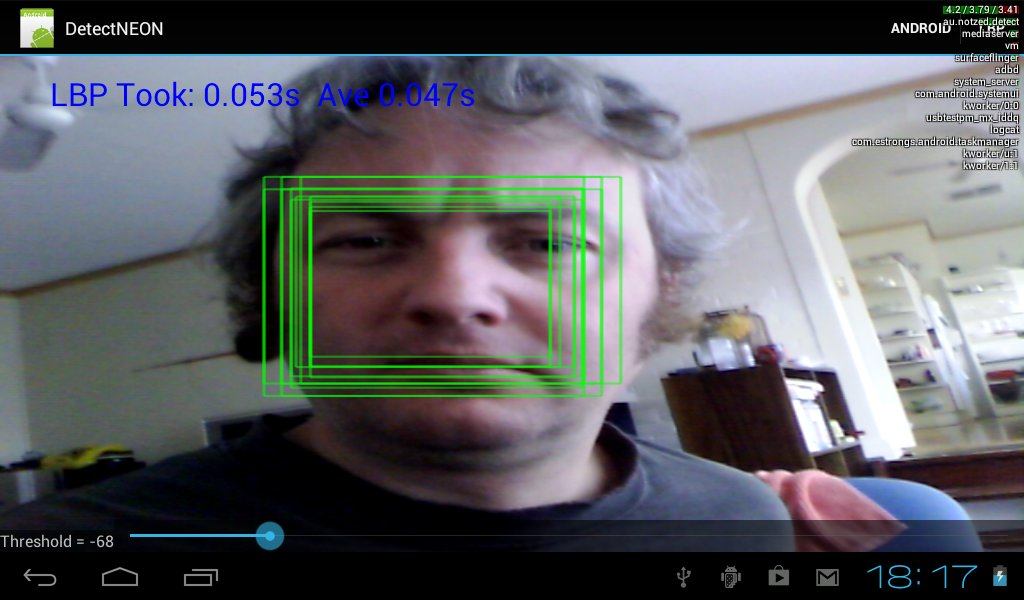
Android face detector demo
First things first, this is not about using the android api to detect a face, it's about some code i've been experimenting with over the last few months.
I decided to just upload the skeleton demo application i've been using for testing the detector on Android. It might give me the impetus to spend some more time on it.
I've put the package on google code in the MediaZ project as DetectNEON-0.apk (for want of somewhere better to put it). Note that there is no public source for it at the moment.
Update: I was a bit too lazy and only implemented code for a front-facing camera. I just uploaded another package DetectNEON-1.apk which might fix it, or just break it for everything.
The app has an inconveniently placed slider that lets one adjust the matching threshold, which may be required under different lighting conditions or due to the qualities of the camera sensor. One can also switch between android's 'built in' face detector and mine with the buttons at the top. The aspect ratio of the video display is broken, but that isn't what i was trying to test here. It is also obviously only displaying the raw hits and not grouping them in any way.
On my ainol elf 2 tablet the detector takes around 45ms on a 640x480 input frame using the settings i've set: minimum object size detected is 51x51 pixels, up to about 400x400. The code is single-threaded and I was using 'normal' mode for the CPU scheduler.
For comparison the Android face detector API takes about 500-600ms, although it does search to a smaller size - which is a critical factor in execution time for sliding window algorithms.
It seems to work better than I remembered, but I think last time i tested it was late at night in a poorly lit room.
Update 2: Just a bit more info that is scattered over the blog.
- The classifier is trained on very upright fully-front faces (the CBCL data set), so will not detect as wide a range of orientations as the typical OpenCV cascades.
- Once the training set is loaded into memory, it takes about 40ms to train a 17x17 classifier with approximately 10K images using simple Java code (i7 something cpu).
- Although there was a small amount of hand-tuning with the negative set, the training is deterministic and employs no reinforcement techniques such as boosting.
- The classifier is a fixed size in relation to the window size. The 17x17 classifier is about 2.5k bytes in total.
- There is no pre-processing of the input signal in this demo.
- Hence it is fairly sensitive to noise and camera 'qualities', however it returns a probability rather than a binary result, so can be adjusted for sensitivity.
- The NEON code classifies each single pixel in under 1 cpu cycle on a Cortex-A8 CPU.
- I've done no statistical verification on how well it works, and i'm mostly just surprised it works at all.
On NEON vs OpenCL
So I just reached a 'have output' milestone on some code i'm working on and I was reflecting on how much effort it was to code a similar algorithm in NEON in assembly language compared to OpenCL on a GPU.
In my case, NEON comes out on top in terms of 'developer productivity'.
- Mistakes crash a process - not your computer.
- Easier to debug in gdb (I know there are OpenCL device debuggers now, but not when I started).
- Better libraries.
- Not portable - but OpenCL isn't portable between device-classes either, and isn't available on every system.
- Easier memory management - it's just the same as C.
- Easier to bind with C code - it's just the same as C.
- Very low call overhead.
The last two points are quite significant. Because of the overheads of OpenCL you're forced to put big chunks of complex algorithm onto the device - not to mention the hairy code required to get good performance out of not-trivially-parallel tasks.
With NEON you only need to code the stuff that runs slower than it should in C (and despite all the years of compiler advances, there's still a lot of code like this), and just leave the complex business logic and outer loops to the compiler (it usually does an ok job at that). Even without resorting to exotic bit manipulation and in-register lookup-tables, such a simple operation as a "float - scale - clamp - byte conversion" (as typically encountered in image processing) is several times faster via NEON than in C, and not a lot harder to write.
It helps that NEON has a nice orthogonal instruction set with sane mnemonics and a healthy register count, unlike some other crap one could mention ...
Pity it's still slow!
The main issue is of course that these CPU's are pretty gutless, and you can't get the sort of performance you can out of a desktop machine, let alone a GPU (but those can't fit in your pocket either). Of course, this is the type of problem the parallella project is trying to address - but they seem to be having a bit of a kickstarter melt-down and haven't updated their project in a few days. Well one hopes the publicity gained helps them get something going anyway even if this particular effort fails.
Update: Well Adapteva finally put some more stuff up. I guess going for the 'cheaper/faster beagleboard' type thing is better than their original approach, even if it de-emphasises the parallel nature somewhat. Whether it's that or the request for more noise, it seems to be picking up a good amount, although $200K in 2 days is a big ask.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!