About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

jjj sequence editor
Sometimes I hate it when I have ideas in my head and they just wont go. Last night I was getting bored with TV and kept thinking about a sequence editor - the most complex single interface component I'm after - so I fired up the computer and hacked from 11pm till 3am or so. The the less sleep I get the more "anxious to get shit done" I seem to be, until I fall apart.
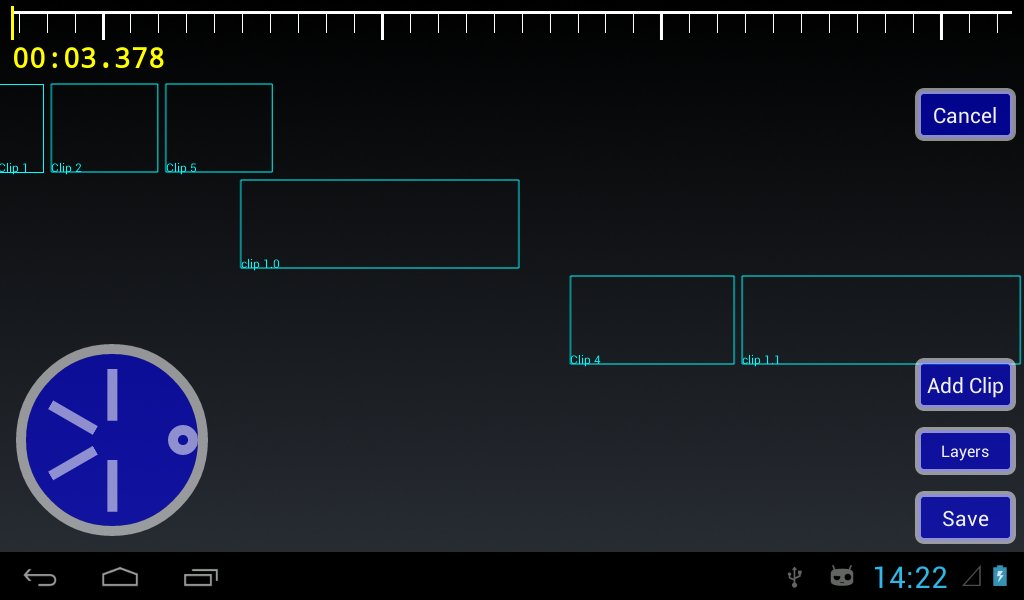
So although it's not much to look at yet - and the code behind it is even worse - last night together with a few hours today I came up with the following interface and all the guts to make it work.
I'm not sure if i need the jog-wheel there as the functionality is provided by the scale too, but it lets one move the timeline forwards/backwards. I also doubt i need to support any-number-of-layers, but I suppose I may as well - once you have more than one, any number isn't much harder.
The scale at the top can be dragged - it acts like a scroll-bar, or two fingers pressed on it can be used to zoom in and out.
The main sequence interface is modal, in that you are either working with 'layers' (or 'tracks'?) or clips. The "Layers" button is a toggle which switches modes, although I think I need a better interface design for that.
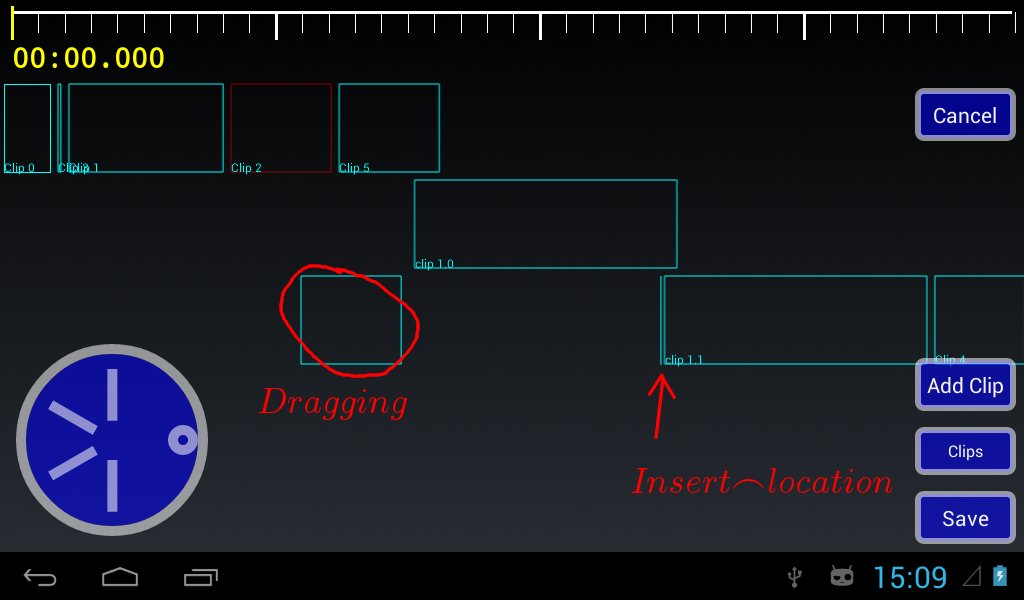
I don't have animations (i'm kind of up in the air on them as most of the time they just piss me off with their added delay) but the clips can be "drag and dropped" around the sequence in fairly obvious ways. So for example dragging a clip creates a layer-locked box which follows your finger, and a | indicator where it can be inserted. Letting go moves the clip to the new location, creating new layers as required.
Layers work similarly, except layers can be re-arranged, and the start position for the layer can be altered. All clips within a layer always run one after another. Doing things like moving the first clip causes the layer origin to be moved so the rest of the content isn't changed and so on, so it kind of 'just works' like you'd expect.
I have a basic single-item selection mechanism too, for deleting or other item-sensitive operations (e.g. where does 'add clip' add?).
So although the code is a complete pigs breakfast it is quite functional and stable, and with a bit of styling and frame graphics it's almost feature complete. Probably the last major functionality missing would be some start/end 'snapping' - but that's more of a nice-to-have.
Compositor too
Yesterday afternoon - when I was supposed to be relaxing - I worked on a prototype of a compositing and video creation engine. Initially I tried to use the ImageZ approach of compositing in floats, row-by-row, but android's java just isn't fast enough to make that practical. So I fell back to just using android's Canvas interface as the compositor. I guess it makes more sense anyway as it gives me a lot of functionality for free. I could get more performance bypassing it, but it's going to be a great deal of work. Obviously, I didn't attempt audio.
Initially I just wanted to see how performance was, but I ended up adding video and text "sources", which can be mixed/matched together. Performance is ... well it's ok, it's just a mobile platform with a purely CPU pipeline. A 10 second 800x600@25fps MP4 medium-quality clip takes about 20 seconds to decode+render+encode on the *ainol elf 2. For the compositor, about half the time is spent in decoding the source material and half spent in compositing, which isn't exactly flash - but it's all bytebuffers and Bitmaps and copying shit around multiple times so it's hardly surprising.
As usual the ideas in my head exploded yesterday and I thought about all sorts things: ways to create an interesting and usable interface, keyframe animation of clips and properties, multiple 'use modes' such as a simple video cutter, potential local client/server operation, using your pc to do the rendering, or using the tablet as an interactive control surface for a pc based application. But whether i'll have the time and motivation to see any of it through is another matter.
If i remember to, I'm going to try to track how much time i've spent on this project, so far it's about 3 days. I initially thought I could do a quick-and-dirty "weekend hack" and see how far I got and just leave it at that, and then thought the better of it. It's a 5-day long weekend for me so that's too much like hard work!
jj .. jay?
Time to drop another ``prototype-bomb'' on the unsuspecting world ..

Ultimate goal is some sort of simple-to-use video editor, but to begin with there are a lot of user interface and algorithmic problems to work out. I tried to find some simple editors in the android store but they pretty much sucked - based on server processing, questionable advertising, difficult and confusing to use, and usually quite slow.
However, a few hours hacking so far and I have a fully functioning "clip" editor, which is one of the basic components required.

I've actually been meaning to play with something like this for quite a long time, and finally the planets aligned such that it was an opportune time to look into it (nothing to do with any internet goings ons). I will probably also dabble in a JavaFX version if I get anywhere with it; although the interface requirements there are very different.
jjmpeg android hardware decoding
I somewhat embarassingly just discovered that FFmpeg already has some support for using libstagefright for hardware video decoding on Android.
I always thought this was the place it should go, since mucking around with OMX or other junk is just such a pain, and it belongs there.
Bit of a headfuck getting it to compile, particularly since this adds a C++ dependency, and then after all that ... it just crashes.
I/ffmpeg (10484): Assertion i < avci->buffer_count failed at
/home/notzed/svn/jjmpeg-1.0/jjmpeg-core/jni/ffmpeg-1.0/libavcodec/utils.c:603
F/libc (10484): Fatal signal 11 (SIGSEGV) at 0xdeadbaad (code=1), thread 10607 (VideoDecoder)
I/DEBUG ( 1894): *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
I/DEBUG ( 1894): Build fingerprint: 'samsung/m0zs/m0:4.1.2/JZO54K/I9300ZSEMB1:user/release-keys'
I/DEBUG ( 1894): pid: 10484, tid: 10607, name: VideoDecoder >>> au.notzed.jjmpeg <<<
I/DEBUG ( 1894): signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr deadbaad
I/DEBUG ( 1894): r0 00000027 r1 deadbaad r2 40126b0c r3 00000000
I/DEBUG ( 1894): r4 00000000 r5 620f2a04 r6 60bfcc00 r7 61d0b8b0
I/DEBUG ( 1894): r8 5b127c80 r9 61bd5718 sl 000104d5 fp 61bd5718
I/DEBUG ( 1894): ip 5dc4bcbc sp 620f2a00 lr 400f8c65 pc 400f52fe cpsr 60000030
I/DEBUG ( 1894): d0 0000000200000000 d1 4b0000004b000021
I/DEBUG ( 1894): d2 000000094b000021 d3 0000000000000000
I/DEBUG ( 1894): d4 3ce5999061da5385 d5 3f34e1653f349a33
I/DEBUG ( 1894): d6 3f35287b3f356f75 d7 0106999ec0000000
I/DEBUG ( 1894): d8 0000000000000000 d9 0000000000000000
I/DEBUG ( 1894): d10 0000000000000000 d11 0000000000000000
I/DEBUG ( 1894): d12 0000000000000000 d13 0000000000000000
I/DEBUG ( 1894): d14 0000000000000000 d15 0000000000000000
I/DEBUG ( 1894): d16 8000000000000000 d17 ffffffffffffffff
I/DEBUG ( 1894): d18 416347d4c0000000 d19 3fe0000000000000
I/DEBUG ( 1894): d20 3fe0000000000870 d21 0000000000000000
I/DEBUG ( 1894): d22 0000000000000000 d23 0000000000000000
I/DEBUG ( 1894): d24 0000000000000000 d25 0000000000000000
I/DEBUG ( 1894): d26 0000000000000000 d27 0000000000000000
I/DEBUG ( 1894): d28 3f3504f3bf3504f3 d29 bf3504f33f3504f3
I/DEBUG ( 1894): d30 0000000000000000 d31 3f3504f33f3504f3
I/DEBUG ( 1894): scr 20000010
So yeah, i dunno. Perhaps it is a bug in jjplayer, but I tried removing all output handling, and it still just crashes inside codec->decode(), and the api to that point is so simple I don't think I can screw it up.
I've wasted half a day on this and it's losing it's interest very fast ...
Update: So, just when I was about to give up, I found a threading bug in the codec implementation. This at least lets it decode more frames but it's still crashing later on inside the GLES library.
I haven't got the NV21 image format working properly yet, so it may be related to that, maybe.
Update: Well that was pretty much a full day down the drain, I submitted a patch to the ffmpeg-devel mailing list (yay, subscribe to a high volume list of zero interest to me just to submit a 10 line patch).
It turned out that the file I was testing against refuses to play at all in the bundled players, so it's something to do with the hardware/firmware. At best they load the first frame then abort, although they don't segfault (probably the parser/demux stops it going as far as the codec).
On a video recorded from the camera it seems to work ok, although it certainly doesn't appear particularly smooth - I would need to do some timings to see what's going on. I haven't written the NV21 support either. And the build stuff needs cleaning up and parameterising before I can check it in.
If it's going to still be so useless i'm not sure I really care to be honest. And I've had more than enough for today so whatever I decide will have to wait.
duckduckgo
I've decided that i'll be giving duckduckgo a 'go' for a while for my search.
I've been an extremely heavy user of google's search for many years, and it is an indispensible tool for saving time. But i'm getting sick of it trying to be 'smarter than me' - I pretty much have to manually tell it to do a verbatim search every fucking time I search for anything technical (i.e. almost every search) which makes every new search that bit more tedious and frustrating than it already is. And given their spate of recent prunings who knows how long that will even last.
And just in the last couple of days they seem to have fucked around with it even more: i get 4-5 results and then a 'similar searches' section, which I do not find useful whatsoever. Sadly I often find searches I do pointing back to my own posts or code, which indicates to me that perhaps I really am a beautiful and unique snowflake after-all, and subsequently knowing what is "popular" isn't terribly useful to me.
Targetted search based on seeker popularity by default really seems a pretty strange feature unless you're writing a search engine for pop-culture or a shop (insight: oh hang on, that must be exactly what they are doing! silly me). Searches should first be for facts, not for reinforcing currently popular interests or fasionable trends. I already felt extremely uncomfortable with the fact that google search was customising results at all, but this is so much worse. If you went to a researcher and asked for detail on a topic, would you want them to take into account both your appearance and other customer's desires when they fulfilled the request, or would you prefer an unbiased, objective collection of all available information?
I guess those of us working niche fields or with niche interestes are going to have to get used to the fact that we are simply not enough of a product-base for Google to care about (remembering we are the product). They don't really care if they lose us because their customers don't really care if google loses us. Based on "The story so far", I think we can expect to see more of a mainstream/pop/fashion based focus to their products, which is very sad turn of events. With the closing down of various networked services, we're also going to start to lose trust in their long-term commitment to some of them. Surely blogger will not live outside of Google+ for much longer (tbh, not sure i care, so long as google+ is linkable and crawlable by any other search engine), and what about google code?
I also finally worked out one major reason why firefox was constantly using a good chunk of cpu time: apart from adverts and other annoyingly pointless crap, the main culprit was simply the google search results page. Which I find quite baffling because there are no visually moving parts whatsoever. I really wish firefox would simple disable javascript on tabs you're not currently looking at, because all it does is let crappy web page coders make firefox look like a bloated piece of shit, even if it isn't really.
Duckduckgo is certainly more concise, perhaps overly so to the point of missing relavant information, so it may not fullfill my requirements. A search for jjmpeg only finds 1 post from this blog for instance, and I often prefer to see multiple in-site references (perhaps it is an option: at this point i've used it only a few times). But i'll see how it goes, my search needs vary depending on what i'm doing. I just wish it paged the results using numbers mind you, I'm using the html version since the infinitely scrolling "Web 2.1.x(tm)" page completely sucks: as they all do.
Bummed out, or am i?
This week I've been experimenting with the performance of some NEON code. It is from an algorithm which was developed in OpenCL for desktop GPUs and then downscaled to fit on a beagleboard (only for development purposes). The overall algorithm is identical but the way some of the steps are implemented is different (and for some significant components much less computationally and bandwidth intensive).
The OpenCL code took many months to develop - although that included dead-ends, multiple steps if refinement, and other distractions including completely unrelated work. Even with that, I'd put the effort at around 4-10x that for the NEON code.
The NEON code took a few weeks. It obviously helped immensely that the algorithm was primarily known in advance although the downscaling alterations were not. On the other hand, my total experience with NEON is far less than OpenCL and certainly C or Java in terms of hours.
One reason the NEON code was much easier to write is that because as it is so cheap to invoke, one can just concentrate on the bottlenecks, and leave the housekeeping to C. e.g. I can write a routine that processes as little as 16x16 pixels in assembly, and leave the addressing crap to C. There is also no marshalling or other api binding to worry about: the C is plain C, and the assembly is plain assembly, and even though JOCL is far far better than using the C api directly it's still quite a bit of work. As much fun as OpenCL is, it's even more fun hacking NEON because you can concentrate on the fun bits even more.
Although the OpenCL model is also based on simple kernels which should equally be simple and isolated - it isn't really quite like that in practice. All but the simplest of kernels end up turn into 64-way parallel subroutines utilising LDS, barriers, and so on. Without that you end up leaving skads of performance on the floor, so it really is necessary. Not to mention all the marshalling and boilerplate in the host-code to communicate with it. And because of the marshalling and invocation latencies pretty much everything is forced onto the GPU.
So what's the point i'm getting at?
Well after all that, the projected performance on the previously-latest-version of a popular handset is only about 5x slower than a HD7970 on a pretty beefy desktop!
Yes that 5x speedup is important enough that it is worth it and opens it up to more applications, but on a personal level i'm just totally bummed it isn't much more. It's a highly parallel and bandwidth intensive workload which should be well-suited to a GPU. Obviously opencl has the advantage that it isn't tied to a single bit of hardware. It's a pity SSE sucks so much otherwise it would be interesting to see how a desktop cpu fared on it's own.
I plan to "back port" the algorithms so it can be improved on the GPU, but I have a fairly educated feeling that another 2000% performance isn't very likely. I will also need to use some AMD proprietary extensions, so the portability will suffer too.
I'm sure I can improve it, but I just take it as a big personal slap in the face for all the effort that's gone into it so far!
Of course, the alternative view is that ARM+NEON is the bees knees - with less effort i'm getting relatively great performance. But we all knew that so it isn't such a revelation ...
The main bottleneck on ARM cpus at the moment is the memory, and if you can utilise the cache effectively it really flies. I would really like to see how a beagleboard like machine with big/little A15/A7 quad core and much faster memory would fare, all these cheap android dongles are far too constrained by their form-factor.
Update: Well I might need to eat my words here. Today I started to look at GPU optimisations based on what i'd learnt from the ARM experience and trying to reduce the bottlenecks of the GPU code.
The key word of the day: batching.
One reason I wasn't previously batching the processing is because it didn't really fit the data-flow of an earlier application. But I have now achieved something like a 50x boost in one key algorithm by a combination of batching the work more aggressively and some other significant algorithmic changes.
This is more like it. No longer bummed out ...
Another pointless bruhaha at an IT conference
I just have 2 words to say: Google Glass.
Better get used to it, and more.
#$#@$ Android
One of those "I can feel the hair going grey and falling out" mornings. Although at least it wasn't one of those "I made every mistake I could have, every time I did anything" one. My throat is hoarse from all the screaming of definitely un-pc obscenities.
I'm trying to get some jjmpeg stuff working on android - but I can't use the jjmpeg android branch due to licensing issues. I need to use a fully shared library version.
Compiling the code was easy enough but trying to use shared libraries on Android turned out to be a complete head-fuck.
First, for some fucked reason although shared libraries are placed into a per-architecture location, the bloody library path isn't setup to automatically use it. So you have to hard-code all the architecture into the dlopen() calls.
Actually second, it's even worse than that, you need to use absolute paths for dlopen() otherwise it doesn't work. I just hard-coded it, a stack overflow answer stated that finding the path from Java was 'trivial', but then neglected to include which api trivially provided it. I didn't really want to change jjmpeg anyway.
And thirdly, it's flaccid linker doesn't support versioning of the shared libraries. To fix that I hacked up ffmpeg/library.mak to only create non-versioned sonames, and then hacked a build script to make it compile properly as with that change it didn't seem to want to build the libraries properly. I did this by specifying each lib*/*.so manually as the build target.
And the fun's only just started, i've still got a pile of C and NEON code I've got to get to work ...
Update: Oh fucking joy, no complex numbers now.
Update 2: Well I managed to replace complex.h with a few lines of #defines - fortunately they're complex numbers are in the compiler, just not in libm, and apart from the basic arithmetic I only needed creal/cimag and conjf.
And somehow, after re-arranging 1500 lines of C and 1500 lines of NEON assembly language, creating JNI wrappers, and hooking it into ffts and jjmpeg/head ... it worked almost first time. I'd set myself all week to get that far so i'm pretty chuffed, even if the headache from the days earlier tribulations hasn't yet receded.
I really have the beagleboard and a GNU operating system to thank for that - without being able to develop on a proper system first it would've been a nightmare.
Time for a couple of glasses of nice Barossa red methinks.
clAmdFft
Just a quick note, I created a small JNI wrapper using JOCL to access the clAmdFft library from AMD, to see how it compared to the Apple FFT I ported to Java.
Bummer, the Apple FFT is still faster for my problem size - image processing. Kernel time on a 1024x1024 sp fft is ~0.5ms vs ~0.38ms for the Apple one (HD7970). And the apple one only requires 3 passes. Smaller and/or batches seems to scale linearly too.
All that (minor) frustration with the clMiXeDAbbrCamlCase API for nought.
Update: So I actually tried writing a 64-element parallel FFT to see how I could do ... well, not good. Apart from wasting a lot of time wondering why "no matter what I did it took 15ms" because I hadn't allocated a properly sized buffer (out of range access I guess), when I finally got it going it was about 10x slower than the Apple one. Blah. Actually the apple one was about the same speed (if not faster) than a simple memcpy (using float2).
I wasn't being very smart about it, I just broke a 64-element FFT into one-calculation steps and used shared memory to communicate the results. A big overhead was the index twiddling for which I just used lookup-tables, but even the shared memory communication was expensive.
I may have gotten something wrong anyway, the profiler said the apple fft code had many many fewer global read/write operations, and I couldn't work out why. Although I was trying to do it all in LDS in a single kernel.
Since I didn't verify the results - I was just seeing how the memory access patterns would work - I have no real idea whether it worked or not anyway. But I may have another play another day, I wrote some code which outputs the expressions required between two arbitrary "layers" of the calculation so I can use larger kernels than the radix-2 ones I was testing with.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!