About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

asm vs c II
I dunno, i'm almost lost for words on this one.
typedef float float4 __attribute__((vector_size(16))) __attribute__((aligned(16)));
void mult4(float *mat, float4 * src, float4 * dst) {
dst[0] = src[0] + mat[0];
}
notzed@minized:src$ make simd.o
arm-linux-gnueabihf-gcc -c -o simd.o simd.c -O3 -mcpu=cortex-a9 -marm -mfpu=neon
notzed@minized:$ arm-linux-gnueabihf-objdump -dr simd.o
simd.o: file format elf32-littlearm
Disassembly of section .text:
00000000 :
0: f4610aef vld1.64 {d16-d17}, [r1 :128]
4: ee103b90 vmov.32 r3, d16[0]
8: edd07a00 vldr s15, [r0]
c: e24dd010 sub sp, sp, #16
10: ee063a10 vmov s12, r3
14: ee303b90 vmov.32 r3, d16[1]
18: ee063a90 vmov s13, r3
1c: ee113b90 vmov.32 r3, d17[0]
20: ee366a27 vadd.f32 s12, s12, s15
24: ee073a10 vmov s14, r3
28: ee313b90 vmov.32 r3, d17[1]
2c: ee766aa7 vadd.f32 s13, s13, s15
30: ee053a90 vmov s11, r3
34: ee377a27 vadd.f32 s14, s14, s15
38: ee757aa7 vadd.f32 s15, s11, s15
3c: ed8d6a00 vstr s12, [sp]
40: edcd6a01 vstr s13, [sp, #4]
44: ed8d7a02 vstr s14, [sp, #8]
48: edcd7a03 vstr s15, [sp, #12]
4c: f46d0adf vld1.64 {d16-d17}, [sp :64]
50: f4420aef vst1.64 {d16-d17}, [r2 :128]
54: e28dd010 add sp, sp, #16
58: e12fff1e bx lr
notzed@minized:/export/notzed/src/raster/gl/src$
I thought that the store/load/store via the stack was a particularly cute bit of work, especially given the results were already in the right order and in adequately aligned registers. r3 also seems a little too popular.
I guess the vector extensions to gcc just aren't finished - or just don't work. Maybe I used the wrong flags or my build is broken. It produces similar junk code for the epiphany mind you. I've never really tried using them but after a bunch of OpenCL in the past I thought it might be worth a shot to access SIMD without machine code.
My NEON is very rusty but I think it could be something like this:
notzed@minized:src$ arm-linux-gnueabihf-objdump -dr neon-mat4.o
neon-mat4.o: file format elf32-littlearm
Disassembly of section .text:
00000000 :
0: f4a02caf vld1.32 {d2[]-d3[]}, [r0]
4: f4210a8f vld1.32 {d0-d1}, [r1]
8: f2000d42 vadd.f32 q0, q0, q1
c: f4020a8f vst1.32 {d0-d1}, [r2]
10: e12fff1e bx lr
As can be seen from the names I started with a "simple" matrix multiply but whittled it down to something I thought the compiler could manage after seeing what it did to it - this is just a meaningless snippet.
After a pretty long day at work I was just half-heartedly poking at filling out the frontend to the epiphany gpu but just got distracted by whining at the compiler again. I should've just started with NEON, after a little poking I remembered how nice it was.
And I thought I hated tooltips ...
Found on some m$ site whilst looking for how to turn off tooltips:
I've spent over 10 hours the last two days trying to solve the same problem. Apparently it is impossible to get rid of tooltips in Win7, which makes it absolutely unusable for me. I've wasted my time. I've wasted my money. Just installed Ubuntu which doesn't cost a penny and with one checkmark I get to disable all tooltips. With Microsoft I get to pay $100 for something that seems intentionally designed for maximum annoyance. Goodbye Microsoft. Last dime you ever got from me.
Had a laugh then thought fucking around in regedit wasn't worth it and so left it at that.
But yeah tooltips suck shit. If your GUI needs tooltips to be usable, it just needs bloody fixing. Icons just don't work when you've got more than a dozen or so choices (not much does for a human).
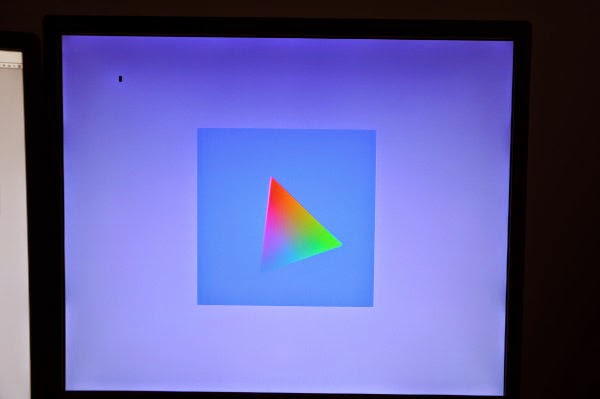
first triangle from epiphany soft-gpu
I was nearly going to leave it for the weekend but after Andreas twattered about the last post I figured i'd fill in the last little bit of work to get it running on-screen. It was a bit less work than I thought.
- One epiphany core is a bit faster than one Zynq ARM core! 15s vs 18s (but a small amount of neon and a slightly different inner loop would make a huge difference);
- Scaling is ok but not great at the high end, 4 cores = 5.5s, 8 cores = 4.6s, 16 cores = 3.9s;
- The output dma isn't interlocked so it's losing about 1/2 the write performance once more than one core is active;
- All memory and jobs are synchronous (
ezesdk's async dma routines aren't working for some reason luser error on that one);
- Scheduling is static, each core does interleaved rows;
- Over half of the total processing time for rendering this single triangle is spent on the float4 to uint32 rgba clamping and conversion and it can't be sped up. This cost is fixed per frame, but who would have thought the humble clamp() could be the main bottleneck?
- Total on-core .text is under 2K (could easily increase the render size to 768 pixels wide?);
- It's all just C but I don't think significant gains are possible in assembly.
The times are for rotating the triangle around the centre of the screen for 360 degrees, one degree per frame. The active playfield is 512x512 pixels. Z buffer testing is on.
Actually the first triangle was a bit too boring, so it's a few hundred triangles later.
Update: I was just about to call it a night and I spotted a bit of testing code left in: it was always processing 1280 pixels for each triangle rather than the bounding-box. So the times are somewhat out and it's more like arm(-O2)=15.5s, epu 1x=11.5s 4x=3.9s 8x=3.1s 16x=2.4s. I also did some double-buffering and so on but before I spotted this bug but the timing is so shot it turned out to be pointless.
I did confirm that loading the primitive data is a major bottleneck however. But as a baseline the performance is a lot more interesting than it was a few hours ago.
epiphany soft-gpu thoughts
I've been feeling a bit off of late so not hacking much of an evening but I did get a spare couple to poke at the soft-gpu and finally write some epiphany code.
Of course I got completely side-tracked on the optimisation side of things so I didn't get terribly far. But I solidified the plan-of-attack and sorted out some way to provide C based shader code in a way which will still get some performance. I have much of the interesting setup code done as well (although there is more uninteresting stuff, maybe I will just use java as the driver).
I've re-settled on the earlier idea of separating the rasterisation from the fragment shading but it will all run on the same core. There will be 3 loops.
- Rasteriser which performs in-triangle and Z/W buffer tests and generates the X coordinate and interpolated 1/W value for all to-be-rendered fragments;
- Reciprocaliser[sic] which inverts all the 1/W values in a batch;
- Fragment processor which interpolates all of the varying values and invokes the fragment shader.
This allows each loop to be optimised separately and reduces register pressure. Due to the visual similarity of some of the setup I thought there would be some duplicated calculations but there actually isn't since each is working with different values.
1 and 2 will be hard-coded as part of the platform but 3 will be compiled separately for each shader so that the shader can be compiled in-line. This is the only way to get any performance out of the C code.
The shaders will be compiled something like this:
/*
* Shader fragment to call
*/
#define SHADER_INVOKE(colour) solid_gourad(colour, uniform, var0, var1, var2)
/*
* An example shader - solid (interpolated) colour
*/
static inline void solid_gourad(float *colour, float *uniform, float var0, float var1, float var2) {
colour[0] = var0;
colour[1] = var1;
colour[2] = var2;
colour[3] = 1.0f;
}
/*
* Include the actual routine to use
*/
#include "e-fragment-processor.h"
And e-fragment-processor will have a generic inner loop which will be something like:
void draw_row(... arguments) {
... setup
const float var0x = v[VS_X+0];
const float var1x = v[VS_X+1];
const float var2x = v[VS_X+2];
// Set start location for interpolants
float var0_w = (var0x * fx + v[0 + VS_Y] * fy + v[0 + VS_Z]);
float var1_w = (var1x * fx + v[1 + VS_Y] * fy + v[1 + VS_Z]);
float var2_w = (var2x * fx + v[2 + VS_Y] * fy + v[2 + VS_Z]);
// ... up to whatever limit I have, 16 is probably practical
for (int i=0;i<count;i++) {
struct fragment f = fragments[i];
// divide by w to get interpolated value
float var0 = (var0_w + f.x * var0x) * f.w;
float var1 = (var1_w + f.x * var1x) * f.w;
float var2 = (var2_w + f.x * var2x) * f.w;
// .. etc
// shader says how many varX's it uses so compiler automatically
// removes any redundant calculations: so only one version of this file
// need be created
SHADER_INVOKE(colour + f.x * 4);
}
}
Written this way a simple colour gourad shader is around 500 bytes or so and the inner loop is 20 instructions although not very well scheduled.
The end goal would be to have multiple shaders loaded dynamically at runtime but that sounds like too much work so i'll keep it simple and just link them in.
It's a trade-off between ease of use and performance although from some preliminary benchmarking (well, looking at what the compiler produces) I think this is about as good as the compiler is going to get. Being able to provide a programmable shader at near-optimal performance would be a nice bullet-point.
An alternative is that the shader must just implement draw_row() and the code template above is copied; this might be useful if some other hard-to-calculate value like the reciprocal is required per-pixel and it can separate that pass into a separate loop.
Memory
On memory i've decided to set the rendering size to 512 pixels. I was hoping for 1024 but that's just a bit too big to fit and a bit too much work for the memory bus besides.
- 8192 float Colour buffer - 4x4x512
- 2048 Z/W buffer - 4x512
- 2048 1/W work - 4x512 (could be done in batches)
- 2048 X work - 5x512 (could be done in batches, or use int16)
- 2048 Frame buffer colour transfer 4x512
- 1024 Primitive transfer buffers (at least 2).
That leaves 7K 15K (oops, out by 8k) for code and stack and some other control structures - which should be enough to do some interesting things. I decided the data needs to be transferred using DMA because the final pass only needs to scale and clamp the floating point framebuffer data to bytes: this is not enough work to prevent the output writes stalling the CPU. Having a separate buffer for the DMA allows the rest to run asynchronously. I will need to round-robin the DMA writes for greatest performance or run them via a central framebuffer controller (and/or dedicate a whole core to the job, in which case it would maintain the colour transfer buffers too).
Actually the above design does let me efficiently split the fragment shaders into separate cores too if I want because they only need to transfer (x,1/w) tuples for each fragment to render - this was my original idea. If I did that then I could probably fit a 1024-pixel row in memory too.
The bottlenecks?
The gpu will work most efficiently by processing every triangle in the scene in one pass: this allows the framebuffer to stay on-core (and in the native floating point format) which provides very high bandwidth and blending essentially free. One every primitive on that row has been rendered the local framebuffer row cache is converted to bytes and flushed out to the real framebuffer (multipass rendering would also require loading from the framebuffer first, but lets not get carried away here).
I'm intentionally not worrying about texture maps (as in, not implement anything for them). Yes they could be used but the performance hit is going to be so dire that it is not going to be desirable to use them. If they were to be used I think a separate texture fetch pass will be required before the fragment shader - so that can fire off some scatter-gather DMA and then process the results as they arrive. I think this is not going to be easy or efficient with the current DMA capabilities.
So, ... ignore that. I will need some useful noise functions so that interesting textures can be procedurally generated instead.
The epiphany to framebuffer speed is pretty low, but that's fixed: there's nothing I can do about that, so no use wasting time crying over spilt milk on that one.
So, ... ignore that too.
I think the main bottleneck will be the transfer of the primitives - because they will all have to be loaded for each row. I will add some input indexing mechanism to separate them into bands so the loading of out-of-range primitives is reduced but fully indexing every row would be costly. If I can work out how to get the broadcast DMA to work (if indeed, it does actually work) then that may help alleviate some of the bandwidth requirements although it comes at a cost of forcing all rasterisers to operate in lock-step across the same band of framebuffer - which might be worse.
I may be completely off on this though - I really gotta just code this up and see how it works.
Deferred Rendering
Actually just to get way ahead of myself here; another alternative is a type of deferred rendering. Rather than keep track of the colour buffer it could just keep of (triangle id, x, 1/w) for each visible pixel. Once it's finished it could then just process the visible pixels - at most once per pixel.
This could be implemented by splitting the triangle primitive into two parts - first the bounding box, edge and z/w and 1/w interpolation equations, and the second being the varying equations. Each pass only needs that set of data - so it could reduce bandwidth requirements too.
Blending is more difficult. With it on every visible triangle would need to be rendered immediately and any previously rendered triangles waiting in the deferred buffer would need to be flushed.
Something to defer till later I guess (ho ho).
Starting JavaFX from random Java code
I write a lot of prototype routines - too many to keep track of in separate projects so I end up with a ton of mains(). Best practice? Who gives a shit: its a prototype, played with for a day or a week and then forgotten.
So far for graphical output i've just been using Swing: actually there's probably not much reason not to use it for that because it does the job but once you need to add some interactivity it becomes a bit of a pain if you've been playing with JavaFX. I might add a 'display intermediate image' anywhere in the code and up it comes.
But JavaFX doesn't let you just call Platform.runLater() or new Stage() from anywhere as with Swing: the system needs initialising within an Application context.
Here's a solution. I have no claims it's a good one but it works for me so far.
// This code is placed in the public domain
public class FXUtils {
static FXApplication app;
static Semaphore sem = new Semaphore(0);
public static void startFX(Runnable r) {
if (app == null) {
try {
Thread t = new Thread(() -> {
FXApplication.start(r);
});
t.start();
sem.acquire();
} catch (InterruptedException ex) {
}
} else {
Platform.runLater(r);
}
}
public static class FXApplication extends Application {
WritableImage image;
static Runnable run;
public FXApplication() {
}
@Override
public void start(Stage stage) throws Exception {
app = this;
run.run();
sem.release();
}
public static void start(Runnable r) {
run = r;
// Application.launch() can only be called from a static
// method from a class that extends Application
Application.launch();
// no windows - no app!
System.exit(0);
}
}
}
Whether start() calls System.exit() or not is up to you - personally when I close a window i'm prototyping stuff on I want everything else to fuck off for good.
And this is how to use it:
public static void main(String[] args) {
FXApplication.start(() -> {
// Now on javafx thread
Stage s = new Stage();
s.setScene(new Scene(new VBox(new Label("foobar!"))));
s.show();
});
// Will wait for javafx to start, but then continue here
// exiting will leave the windows open, till they're closed
}
This uses a thread to launch javafx so that the original main thread can continue; Application.launch() doesn't return until the last window is closed so would otherwise block. The thread could be made a daemon too for some different behaviours.
If you just want to launch a full JavaFX application from multiple mains then none of this is required, just create a static start() method which calls Application.launch().
lambdas & streams
As part of the experiment with the histogram equalisation stuff I started writing a utility library for playing with images for prototyping code.
One thing I was curious about was whether I could use streams to simplify the prototyping by saving having to type and retype the typical processing loop:
for (int y = 0; y < image.height; y++) {
for (int x = 0; x < image.width; x++) {
do something;
}
}
When i'm prototyping stuff I type this in ... a lot.
I had mixed results.
Because I wanted to support arbitrary 2d subregions of an image which might be a mapping of an arbitrary 2d subregion I had to create my own 'spliterator' to do the work. After a couple of aborted attempts I came up with one that just turns the widthxheight range into a linear stream and then maps that to the local (x,y) when retrieving the pixel values (i tried to avoid the divide first, but made a pigs breakfast of the maths).
It lets me write something like this to calculate the histogram over a sub-range of an image:
Image2D img;
byte[] hist = new byte[256];
img.bytes(0, 0, 16, 16).forEach((v) -> > {
hist[v] += 1;
});
Ok, so far so good. It's not necessarily the best way to do it - it can't be parallelised for instance, but this is fine, it saves a few keystrokes and it lets one access a whole bunch of stream functionality "for free".
The problem is with images you normally want to write to them or modify them. So you're back to just using a loop, or maybe a custom foreach which supplies coordinates to a lambda function: again this is fine but then you don't get any of the stream functionality for free here (although as in the next section: it's good enough?). You could just use an IntStream, ... but that doesn't really save any typing over a for loop.
Staying within the confines of the existing IntStream type for the sake of argument, the solution is a little clumsy. One first has to create a class which implements the functions required to be used as a collector.
static class ByteArray {
byte[] data;
public void add(int b);
public void addAll(ByteArray b);
}
With that in place it can be used to collect the results of the calculation. In this case performing the pixel mapping from one set of intensity values to another.
byte[] pixels = img.bytes()
.map((int v) -> map[operand])
.collect(ByteArray::new, ByteArray::add, ByteArray::addAll)
.data;
Image2D dst = new ByteImage(src.width, src.height, pixels);
This can run in parallel: the downside is that each stage needs to allocate its own buffers and then allocate copies of these up to the final result. Probably works but yeah, it's not that pretty or efficient.
Indexed Stream
So I thought about it a little and perhaps a solution is to create another type of stream which indexes over the values. Some of the api usage gets a bit fatter if you want to use some of the basic stream facilities like sums and so on: but that's what .map() is for. I think it can get away without having to allocate the indexing object for each iteration: it is only needed when the stream range is split.
class IndexedInt {
int value;
int x;
int y;
}
dst = new ByteImage(src.width, src.height);
img.bytes().forEach((ii) -> {
dst.set(ii.x, ii.y, ii.value);
});
I dunno, I suppose that's better than a double-for-loop, once the not-insignificant scaffolding is in place.
Actually; why bother even passing the value in this case, it may as well just be calculating indices. It doesn't really make any difference to the code and having a general purpose 2D indexer is somewhat useful.
class Index2D {
int x;
int y;
}
dst = new ByteImage(src.width, src.height);
Index2D.range(0, 0, src.width, src.height)
.forEach((ii) -> {
dst.set(ii.x, ii.y, src.get(ii.x, ii.y));
});
Some of the functionality is a little less concise but the simplicity of the above is probably worth it.
double average = Index2D.range(0, 0, src.width, src.height)
.mapToInt((ii) -> img.get(ii.x, ii.y))
.average()
.getAsDouble();
Much of that could be hidden in helper functions and the external interface could remain an IntStream, for cases where the pixel locations are not required.
Seems like a lot of work just to get a free parallelisable 'sum' function though? The implementing classes still need a bunch of boilerplate/helpers and they could have just implemented most of that themselves. I don't find the forkJoin() approach to paralellisation (which is used by the streams code) to be very efficient either.
But this is my first real look at it : experiments ongoing.
Parallel histogram
I mentioned earlier that the histogram calculation using a forEach isn't paralleisable as is (one could add a synchronized block inside the loop but one would have to be both naive and stupid to do so).
It can be parallelised using a collector. TBH it's a lot of boilerplate for such a simple function but the algorithm is identical to the one you would use in OpenCL even if it doesn't look the same.
First, one needs the class to hold the results and intermediate results.
class Histogram {
int[] hist;
public Histogram() {
hist = new int[256];
}
public void add(int value) {
hist[value] += 1;
}
public void addHistogram(Histogram o) {
for (int i = 0; i < hist.length; i++)
hist[i] += o.hist[i];
}
}
And then the code:
int[] hist;
Image2D img;
hist = img.bytes().parallel()
.collect(Histogram::new, Histogram::add, Histogram::addHistogram)
.hist;
*shrug*. I guess it saves some typing?
tunable histogram equalisation
So this is a rather simple but quite effective improvement to the basic histogram equalisation operation for automatic image correction.
I got the main idea from a paper: ``A Modified Histogram Equalization for Contrast Enhancement Preserving the Small Parts in Images''. Bit of a mouthful for what is just a bounded histogram.
I also made made another small modification which makes it tunable. Allowing for a fairly smooth range from what should be the same as 'normalise' in paint programs, up to the fully sun-seared over-exposed normal result from histogram equalisation.
Here's an example of the range of output.
The value is the proportion of the mean to which the histogram input is limited: a value of 0.0 should be equivalent to a contrast stretch or normalise operation, 1.0 matches the paper, and some large number (depending on the input, but approximately greater than 2) will be the same as a basic histogram equalisation.
One has to look closely with this particular image because they are already fairly balanced but a smooth range of 'enhancement' should be apparent.
I also played with a colour version which applies the histogram to the Y channel of a YUV image.
As of now it does tend to upset the colour balance a little bit and tends toward a metallic effect; but it's arguable better than what the gimp's equalise does to colour images.
Yikes. Although the image on the right is arguably more agreeable - the colour is very different from the source. Histogram equalising each component separately is effectively applying a white-balance correction where the colour temperature is some sort of flat grey: this sometimes works ok but it messes with the colour balance by definition.
I have some thoughts on applying the algorithm to floating point values using polynomial curve fitting, but I haven't tried them out yet. This would be to prevent binning from quantising the output.
For such a simple adjustment to the algorithm it's quite a good result - histogram equalisation is usually too harsh to use for much on it's own.
On my god, it's full of local binary patterns!
I recently had need to look into feature descriptors. I've previously played with SURF and looked into others but I wasn't really happy with the complexity of the generator and needed something Java anyway.
A small search turned up FREAK (why the silly 'catchy' acronym names? Maybe it started with S-USANs?) which looked doable so I had a bit of a play. There is code available but it's OpenCV and C++ and the version I saw just wasn't very good code. I wrote up my own because I had some different needs for what I was looking at and porting the C++/OpenCV was going to be a pain.
I guess they work as advertised but i'm not sure they're what I want right now. I tried porting the AGAST detector as well but it wasn't really getting what I was after - i'm after specific features not just 'good features'.
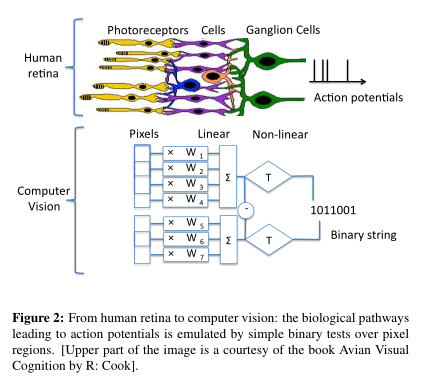
The paper does include this interesting diagram though:
Although the paper doesn't reference them this diagram is pretty much a description of local binary patterns. The FREAK descriptor itself is just a very long local binary pattern with optional orientation normalisation.
Perhaps more interestingly is that this specific diagram could just as well be a description for how my fast object detector works. It is effectively a direct implementation of this diagram.
Assuming the above diagram is representative of human vision I guess one could say that the whole of visual reality is made of local binary patterns.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!