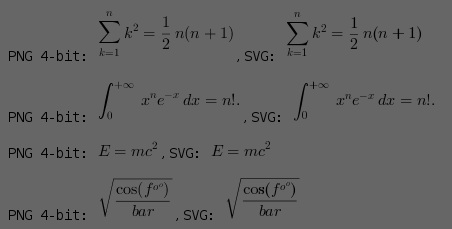About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Losing a chunk.
So i've mentioned it a few times on here - i've been steadily losing weight since February. It's settled now at about 74kg - in part because it just seemed to stop on it's own and its enough off so i'm no longer trying to actively lose weight. It is surprising to me how little food it takes to maintain this so far but i haven't been exercising a lot either.
I'm not sure if the initial trigger was all mental or all physical but in part the shock of getting gout and a full freezer and pantry bereft of 'gout friendly' foods kicked off a period of simply being able to lose weight on whim. I guess I somehow shrank my stomach enough to change how my body detects hunger and once it started I just ran with it - i can't say I tried too hard but I wanted to lose a bit for years. I still get hungry, it just doesn't really bother me like it used to and turn into an overwhelming need to eat. I did a few experiments in the midst to see how little I could get away with and it wasn't hunger that drove me to eat but a sore stomach.
At 92kg I was sadly bang on average for a bloke my age; but that is a lot more than my body can take. Although the belt was the first indication of making progress it wasn't till i broke under about 84kg that I looked (to myself) like I was making any progress; that's probably about when my waist to hip ratio broke under 1.0. After that each kg seemed noticeable one way or another.
I don't feel great or anything, but I would be lying if i didn't say I felt `less shit'.
Looking more like a Clark every year (matriarchal ancestry).
A couple of friends (but thankfully not all!) are already saying I "need to eat" like i'm underweight or something. I'm quite some way from that even if i'm below the average these days. I was skinny until I got a job in the city and started having rich lunches and regular Friday drinks together with a shorter commute cycle and it's slowly accumulated since.
The All Fat Diet
SBS has had a series of diet/health related shows on recently and out of curiosity I looked up some of the stuff i've been typically eating.
Apart from a very low total number of joules around 2/3 of the energy was from fats and oils. Protein was low. I think "diet", "light", "lite" and "low fat" foods are complete nonsense so I certainly wasn't having any of that.
Just bread and butter ended up being a big part of what I was eating (and i don't hold back on the butter). A few spuds and some rice at times. Lots of nuts, mostly almonds. Matured cheddar cheese. Lemons and limes as they are in season. Almost no meat, some but not much grog. Lots of coffee (usually black+none) and tea (green, or white+1/4). But I also had what herbs i could find in the garden mostly in tom-yum-like soup, and plenty of chillies and other random stuff along the way (the chillies were important in one critical way beyond making the bland more palatable). Lots and lots of water.
This isn't what I had all of the time but it was in the majority. It's also not something i'll be continuing but it was certainly effective at losing some weight this time.
One thing I did notice is that big dinner means big morning hunger. I'd already noticed this before but i'm now more convinced of it. If you ignore it it just goes away but it's also easy to eat less at night.
A wretched hive of scum and villainy
This episode of gout also enforced just how useless the internet has become as a source of general information. Almost all the gout 'advice' is useless, being generous. Even the stuff from established medical sources wasn't terribly applicable to me due to being neither 70 nor obese.
For example low-fat is always recommended: but it's never specified whether that has anything (at all) to do with gout or merely just being overweight.
Anyway i'm glad I lost the weight, I wonder if it will stay off this time?
Update: Well 6 weeks later and it's still dropping - 72-73Kg now. I'm eating properly now too - probably better than i have for years and certainly not going hungry.
Update: 14 weeks from the first post and it kept dropping slowly - bang on 70kg has been the base for a couple of weeks now. Damn I haven't been this skinny in a long long time and i like returning to it. Except the fucking arthritis keeps coming back. So despite the good, actually the present is very dark and the future looks even more grim.
all gout, all the time
So my sore foot just kept getting worse despite all efforts of rest so I returned to a doctor. One quick look and he just said 'gout' and prescribed some drugs.
I was a little sceptical and the list of side-effects of the colchicine was a little off-putting but I gave it a go. Well within a few hours all the pain was gone and within a day so was the redness and swelling of both feet.
I guess what I had the last couple of winters was also gout - even though it didn't really appear that way.
Drugs were the last thing I wanted but lifestyle wasn't doing it so that's that I guess. It's probably still going to take a while to get the dosages and medications correct but at least this rules out everything else and has me mobile enough to get back to living.
Despite the weather last weekend I hit the road for a ride intending to just visit friends but nobody was home so ended up doing the 65km round-trip city to coast triangle. It was cold and windy and I took it pretty easy (i'd only just taken the drugs a couple of days before) so it took me over 3 hours and fortunately I missed the rain. Despite freezing my knees and toes (the rest was rugged up adequately) it was more enjoyable than I expected.
Now, if only winter would end ... it's been bitterly cold this year.
Update: Through the last 3 weeks i had some symptoms return a couple of times. Taking some colchicine cleared it up and it seems to be reducing in frequency and intensity ... but yeah it's still around and that colchicine is not good stuff. I'm not really sure the allopurinol is helping or hurting just yet, or if diet is still an issue or not, or really resolved anything; something for the next dr visit. But apart from one day a week ago i've been mobile enough to live normally; although it's been cold, wet, and pretty bloody dull for the most part so it hasn't made much difference. At least the wet has cut the edge from the bitter cold so it feels like winter is finally on it's receding edge. Update 2: I went back to a doc and he took me off the allopurinol. That seems to have been keeping the gout going. So after a week or so its cleared up and i've not had an attack since. It's still a bit sore and not fully vanished but it's the best it's been for months and now i'm doing enough just to get sore from doing too much. I'm pretty much eating normally but i haven't tried grog yet.
the risk of centralisation
So I don't really have much to say here but this is mostly just to add a "see, that's what happens" with regards to an apparent on-going problem with sourceforge.
I noticed a maintenance message a couple of times in the last few days and just put it down to being on the wrong side of the world as per usual; but it seems they've had some disk failures and restoring a site of that magnitude to full functionality isn't a trivial task.
Of course, the catch-cry is to use github, but that is also at the whim of hardware faults or just economics (as in the case of google code's demise), and savannah isn't immune to either. This also holds for blogger and wordpress and all these other centralised services, whether they be 'free-but-you-are-the-product' ones or paid services.
Not that I think the software i've been playing with has any intention to be the solution to this problem but decentralisation is an obvious answer to managing this risk. It may mean individual sites and projects are more susceptible to overload, failure, or even vanishing from history; but by being isolated it better preserves the totality of the culture represented in these sites and projects. Economically it may also be more expensive in total but as the cost is spread wider that concern just doesn't apply (parallelism and concurrency is wonderful like that).
I was already focusing on my current software project being 'anti-enterprise' - not in an economic or political sense but in an engineering sense - but events like this encourage me.
digest nonce
Intended to do nothing with the weekend ... but then i had "nothing better to do" so did a bit more hacking on the server. I had intended to go look for an updated distro for the xm, but promptly forgot all about it.
I did a bit of work on a `cvs-like' tool; to validate the revision system and to manage the data until I work out something better. The small amount I did on this exposed some bugs in some of the queries and let me experiment with some functions like history logging. The repository format is such that data updates are decoupled from metadata updates so for a history log they have to be interleaved together. I also came up with a solution for delete and other system flags: I already had an indexed 'keyword' set for each artifact so I just decided on using that together with single-character prefixes to classify them. Apart from these flags I will also use it for things like keywords, categories, cross-reference keys, and whatever else makes sense. System flags probably don't need indexing but it's probably not worth separating them out either. But the short of it is I can now mark a revision as deleted and it doesn't show up on a `checkout' of the branch containing that mark.
I did a bit of investigation into berkeley db je to see about some features I was interested in and along the way upgraded to the latest version (damn that thing doesn't sit still for long). This is also AGPL3 now which is nice - although it means I have to prepare a dist before I can switch anything on. Probably for now i'll stick with what I have; I was looking into having a writer process separate from the readers but I didn't get to reading very much about the HA setup before moving onto something else. It's just getting a bit ahead of where i'm at.
The driver of this is more thinking about about security than scalability. It's not really a priority as such; but its too easy to do stupid things with security and i'm trying to avoid any big mistakes.
So I had a look at what plain http can do and toward that vain implemented a chunk of RFC2617 digest authentication. This guy's code helped me get started so I could just skim-read the RFC to start with but eventually I had to dig a bit further into the details and came up with a more reusable and complete implementation. The main differences are requiring no external libraries by using javase stuff and the nonces are created randomly per-authentication and have a configurable timeout. It all works properly from a browser although nobody seems to use any http auth anymore; I presume it's all just done with cookies and if we're lucky some javascript now (and perhaps, or not, with ssl).
After I did all this I noticed the Authenticator class that can be plugged into the HttpContext and with not much work I embedded it into a DigestAuthenticator. Then made sure it will work free-threaded.
One problem with digest auth is that a hash of the password needs to be stored in plaintext. Although this means the password itself isn't exposed (since people often reuse them) this hashed value is itself used as the shared secret in the algorithm. And that means if this plaintext hash is accessed then this particular site is exposed (then again, if they can read it then it's already been completely exposed). Its something I can put in another process quite easily though.
I'm not sure if i'll even use it but at least I satisfied my curiosity and it's there if i want it.
Oh, along the way I (re)wrote some MIME header parsing stuff which I used here and will help with some stuff later. It's no camel but I don't need it to be.
On Sunday I thought i'd found a way to represent the revision database in a way that would simplify the queries ... but I was mistaken and since I still had nothing much better to do end up filling out some of the info implementation and html translator and found a way to approximately align the baselines of in-line maths expressions.
bring out the maths.
I wasn't going to bother with supporting the @'math{}'[sic] command in my texinfo backend, but a quick search found jlatexmath so I had a bit of a poke and decided to drop it in.
He's some examples as rendered in my browser:
The first of each row is rendered using jlatex math using Java2D, and the second is rendered by the browser (svg). They both have anti-aliasing via alpha and both render properly if the background colour is changed. Most of the blur differences seems to be down to a different idea of the origin for pixel centres although the browser is probably hinting too (ugh). But the png's are also only 4 bit as well; but they hold up pretty well and actually both formats look pretty decent. Alas the poor baseline alignment, but this is only a quick hack and not a complete typesetting system.
The SVG should at least scale a bit; unfortunately it tends to get out of alignment if you scale too much. Hinting maybe fucking it up?
When I did it I first I hacked up a really small bit of code which directly outputs SVG. It implements enough of a skeleton of a Graphics2D to support the TeXIcon.paintIcon() function. Only a small amount is needed to track the transform and write a string or a rectangle.
As an example, @math{E=mc^2} gets translated into this:
<svg xmlns="http://www.w3.org/2000/svg" width="65" height="18" version="1.1">
<text x="2.00" y="15.82" font-family="jlm_cmmi10" font-size="16.00">E</text>
<text x="18.26" y="15.82" font-family="jlm_cmr10" font-size="16.00">=</text>
<text x="35.14" y="15.82" font-family="jlm_cmmi10" font-size="16.00">m</text>
<text x="49.19" y="15.82" font-family="jlm_cmmi10" font-size="16.00">c</text>
<text x="56.12" y="9.22" font-family="jlm_cmr10" font-size="11.20">2</text>
</svg>
There are some odd limitations with svg used this way, no alt tag or way to copy the image pixels is a pretty big pair of problems. So I also looked into inline PNG and since I was going to that much effort seeing how small I could make it by using a 4-bit image.
After a bit of poking around I worked out how to generate a 4-bit PNG with the correct alpha directly out of javase. I render to a normal 8-bit image and then copy the pixels over to a special 4-bit indexed image using get/setRGB(), and the ImageIO PNG writer writes it correctly. Rendering directly to the image doesn't work (wrong colour selection or something to do with the alpha channel), nor does image.createGraphics().writeImage(8bitimage), although a manual data elements write should and will be the eventual solution.
It makes for a compact image and in base64 the image is about the same size as the svg.
<img alt="e=mc^2" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEE
AAAASBAMAAAD2w64vAAAAMFBMVEUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAABaPxwLAAAAD3RSTlMAESIzRFVmd4iZqrvM3e5GKvWZAAAA+0lEQVR42mNgoAg
wBhFSIcqRwMDAhE+F888GAip2MT4AWsXAwLbi1UfVpgvYlHCqQ4TzgEzshgQzQGyxYWD4i1UBy1k
HmAqHf1hVWO0F+oUFqIiXweEAknjlGSGZh7H+TJMvzFaG2MLybTbYVTOBYAqQu65mZeOaLwxa1Wo
wPVwLmByQjGDmCmA5wHCE4RiDEpgPMuMAwwFlhIq/LBeYLzDKMGsz3IM4l4FB8cA/Bt8JDJwTgNz
fOQwM+oe5D7BuUHoP8xADg/0kBrYPDAzf06FCOodZDrBulAUG5S+wrQyak7R96zORHFK4zvQWi+E
WNi7rC/iiRACMiAMA0lo9OMkFb4YAAAAASUVORK5CYII="></img>
FWIW this is how I create the image that I write to the PNG:
static BufferedImage createImage4(int w, int h) {
int[] cmap = new int[16];
for (int i = 0; i < 16; i++)
cmap[i] = (i + (i << 4)) << 24;
IndexColorModel cm = new IndexColorModel(4, 16, cmap, 0, true, 0, DataBuffer.TYPE_BYTE);
return new BufferedImage(w, h, BufferedImage.TYPE_BYTE_BINARY, cm);
}
One might notice that the colour palette is actually all black and only the alpha changes - if a browser doesn't support the alpha colourmap then the image will be black. Bummer.
Wikipedia uses 4-bit png's for it's maths equations but I think it only has a transparent colour - and in any event they clearly only work if the background colour of the browser is white. Starting at fully white pages for 10+ hours pre day just burns your eyes out so I force my browser to roughtly amiga-console-grey because that's a colour someone actually thought about before using it. I think we can 'thank' microsoft for the brilliant white background in browsers as before IE they weren't so stupid to choose it as the default. White on black isn't much better either.
But as a result this is the sort of fucked up crap I get out of wikipedia unless I disable my style overrides:
I've started exporting it's pages to PDF so I can actually read them (using a customised mupdf which uses a grey background) but it's formatting leaves a little to be desired and if anything by making it appear like a paper it just emphasises any (of the many) shortcomings in the information content and presentation.
Pretty much any site with maths is pretty shit for that matter; everything from missing or low-quality 2-bit renders to fat javascript libraries that do the layout client-side. Dunno if this approach will be much better but I'm not going to need it very often anyway.
For various reasons from the weather to health to work I've been feeling pretty flat lately and it had me thinking about the past a bit. To think that i've gone from hand-coding raster interrupts and sprite multiplexors to writing information serving software "for fun" is pretty depressing. Computers used to be a much much more fun hobby.
texinfo is still TeX
I've been poking at the texinfo parser this week. I was hoping to do a quick-and-dirty parser of a sub-set of it but with a bit more ... but that bit more turns it into something a lot more complex.
The problem is that texinfo isn't a 'file format' as such; it's just a language built on tex. And tex is a sophisticated formatting language that can change input syntax on the fly amongst other possibilities. Unlike xml or sgml(html) there are no universal rules that apply to basic lexical tokens, let alone hierarchical structuring.
After many abortive attempts I think i've finally come up with a workable solution.
The objects in the parser state stack are the parsers themselves so it various the parsing and lexical analyis based on the current environment. Pseudo-environments are used for argument processing and so on. The lexical analyser provides multiple interfaces which allows each environment to switch analysis on the fly.
Error handling or recovery? Yeah no idea yet.
Streaming would be nice but I will leave that for another day and so far it dumps the result to a DOM-like structure. I could implement the W3 DOM interfaces but that's just too much work and not much use unless I wanted to process it as XML directly (which i don't).
I still need to fill out the solution a bit more but it's nice to have the foundation of the design sorted out. It's been a long time since I worked on trying to write a `decent' solution to a parser as normally a hack will suffice and i was pretty rusty on it.
puppeteer
Took a break from the break from hacking and started looking through the old PS+ games I hadn't gotten around to downloading. Also cleared out some of the lesser ones; things i thought might be worth looking at further but now there's just not enough time for really good games so i know i'll never look at them again. Could always re-download anyway.
Anyway one of those games I downloaded was Puppeteer.
Very impressed with the game. By setting it on a small stage they managed to craft a quite exquisite piece of software. A very solid frame rate with NO TEARING, with very good use of per-object motion blur and decent AA. Very high quality textures and models with detailed and charming animation. Short loading times. Absolutely incredible presentation that makes it look like a real puppet stage setting up and tearing down between stages. I only found it too dark and had to turn up the brightness on my tv.
I kept thinking it must've cost a packet to make ... and in this day and age when a piece of shift flash or phone game passes as 'good enough', and even triple-a games are often a lot of technically incompetent snot, it's disappointing that the game didn't get much higher sales.
It's obviously a childrens game but the narrator and players don't mind throwing in some humour for the adults and even though I wasn't thoroughly enthralled myself (just can't seem to care about anything much) I laughed out loud more than once. And of course the puppet-stage setting is perfect for breaking the 4th wall at any time, which it does often. The two player mode seems to revolve around controlling a faery (in one player mode you control both) so it's also a perfect play-with-your-kid game.
Definitely a case of restaurant food vs chucky-d's. I guess it's a question of whether there is a commercial place for this quality in the 6-12 age bracket? I guess not going by it's sales. It deserves a PS4 port and technically (and for that matter aesthetically) it's already better than most PS4 games i've seen even without any enhancements whatsoever.
Anyway, definitely worth getting if you have kids and a ps3 or even if you just appreciate well-made software. It shows what games could be like if people didn't just put up with jank.
Others
I haven't even looked at the other PS+ stuff yet and I got a few disks last week, and bought some other PSN goodies: resogun+driveclub expansions, astebreed and jamestown. (+ maybe more on sale, i can't remember).
I'm pretty shit at resogun but it's just too good; the added modes aren't as varied as the base game but they're going to take a lot of playing to get good enough to know that for sure. As for driveclub I barely know most of the cars in the base game and although i've nearly finished it I don't really care much about the pre-set races for the most part (they can be good filler though) - and this is all the season pass adds (and mostly super-cars at that) - but well I'm a fan I guess.
jamestown is very 90s arcade stuff and like with those i'm kinda shit at it. Each level is fairly short but fun enough but I need quite a few more DEX points before I can weave my way through all the bullets on screen without just dying. It's no SWIV and i'll probably never finish it but it's there I guess (need another controller and visitors I would say).
astebreed was pretty much on a whim and I went in totally blind. It's the only thing I regret now, at least so far. It's fast and well presented but the gameplay mechanics are just not for me. There are 3 main weapons. A magical machine-gun thing; which you pretty much just constantly hold down the button for. A sword thing which causes damage and destroys yellow and purple (iirc) projectiles; so you pretty much just trigger it constantly, occasionally holding it down for a super-swish. And a ranged/targetted rocket-spray weapon which uses a mechanic I've seen in other jap games that I quite dislike. You hold down a button to target (fucking R3 at that) and then release to fire. i.e. you're constantly just holding that and releasing that as well. So the game pretty much devolves into maneuvering between the red projectiles or beams overlayed with a mass of visual noise whilst you're incessantly pumping the other weapons. There's a bit of timing/rhythm to it but to be honest it pretty much just sucks. ~$25 I could've spent on something else but I guess it's no big deal and maybe i'll find something i like if i play it more later (he says knowing full well he's spent $80 and never gotten around to even opening the box, and he has tons of other things he needs to go through).
No Man's Sky
ign and a few other places have a few bits and bobs about this during this through July. Nothing really new but a few things more fleshed out slowly, presumably as part of the PR build-up to launch.
I'm still blown away by the graphics here but for different reasons I might be blown away by a game like The Order. It's unclear if it's running on a PS4 but it feels quite alive for something running at that framerate (and thank fuck: no tearing). Much like it felt the first time I visited a city in ratchet and clank; except here it is not merely background decoration. Yet all some sad cunts can do is complain about a little bit of latency in the terrain generation around the periphery; jesus get a fucking life. Although it has it, I would myself be fine even if it had no anti-aliasing whatsoever; I find that aesthetic quite pleasing on low-texture models just as I did back on the Amiga.
At first I was a little shocked at how quickly the wanted level escalated into the players death - but then I thought it's actually a good idea. I like the idea that the universe itself is trying to stop you being a fuckwit and just indiscriminately killing every animal that moves and mining every bit of land you see. This is very good.
It also means that it's decidedly not a tourist or walking simulator; it's actually a game with high risks for player actions or even just mistakes. All other things look gamey too; clockwork atro-physics, simple flying and shooting. Nice, although there can be satisfaction in becoming a master airliner pilot; most people just want to have the fun bits.
Crafting looks, well, like crafting in any other game. Seems the point is to buy or find blueprints for the upgrades, find or buy the raw materials, hit a button to combine. Buying new ships/suits/guns will provide a new thing to look at as well as a different number of upgrade/storage slots.
I like the cleaninless of the UI which bares some similarity to Destiny. But it also shared Destiny's shitty finger-cursor-thing. Why then the dpad works so well for this kind of menu? Could redeem itself if it runs of the touch-pad.
Confirmation of rotating planets is nice; one hopes that extends to the whole solar system. I mean Damocles did that on an Amiga (w/ day/night) so it should be the bare minimum expected to be honest. Sure it will be a clockwork universe but that's good enough.
I'm rather pleased that it is a single-player game. The whole point of 2^64 planets is that everyone gets their own game to play - despite it all being in the same universe. I'm not sure how one will navigate given it's size but it should also be interesting to see the galactic map fill out by other players - maybe the blink or light up as they are discovered or maybe you can only find them with effort or locally. And for those that want a 'social' experience; there's the whole fucking internet there to enable that, let alone just turning to those in the same room. I imagine there will be a lot of streams/video recordings and screenshots of this one; i'm sure it wont hurt that it such an appealing facade and it may be the only way anyone else ever sees what you saw.
I'm actually pretty surprised how many people seems disappointed this game doesn't have pre-defined story or NPCs. Surprised just doesn't do my feelings half a justice: baffled, confused, somewhat disgusted to be frank. Are people lacking even the smallest amount of mental maturity that they cannot partake in some activity without explicit directions? Jesus how the fuck do they know when to go do a shit? Minecraft demonstrates that at least some children still have some curiosity bones left so at least it's not everyone stuck with this severe mental handicap. Anyway; there's simply no physical or economical way to create a game this big and put any sort of meaningful pre-generated assets in it. I think there will be some lore related things but hopefully not too many, or any tutorial things. With only a dozen people making it, any extraneous fluff seems unlikely.
Or stuff like base building? 2^64 is a number so big it's clearly impossible to comprehend for most and they just relate it to something they know already without realising it has no worth.
Another good thing is that Hello Games' director Sean Murray seems very set on the game he wants to make and isn't interested in any outside noise. Once you start listening to whiners you can easily break your vision and end up with a broken game or just make silly mistakes. I think the driveclub director gives a little too much weight to internet forums for instance. From the IGN video view count it looks like he's onto a winner anyway, even if many people seem to let their imagination escape reality a bit too far.
It still bugs me that people pronounce this as 'nomansky', have they got 'diagon alley' disease from mr potter or something? (i always thought that was such an awfully cheesy and dumb bit of the movies).
Anyway i'm obviously rather interested in this game; excited even.
From what I know (and because of what I don't know) it seems like the game I never knew I wanted, But I actually always wanted, from the first day I worked out how to play a bare-disk pirate copy of Mercenary: Escape from Targ.
the future is micro?
Although i haven't been terribly active on it i've still been regularly mulling over a few ideas about the future of the stuff i did on google code, and this blog.
My plan some time ago was to setup a personal server locally - it wouldn't handle much traffic but I never got terribly much - and this is still the plan. The devil is of course in the details. If it turns out to be inadequate I can always change to something else later but given the site history I find this unlikely.
This choice is also intentionally something of a political one. Centralised control of information is becoming a significant societal problem and with the cheap availability high speed internet, computing power, and storage provides a means to tackle it head on via decentralisation.
Micro-Server
So after a few small experiments and mostly in-head iterations i've settled on a implementing stand-alone micro-server with an embedded db. I was going to play with JAX-RS for it but the setup required turned me off it. I think the tech is great and the setup is necessary but I just don't need it here. I have the knowledge and skills to do almost everything myself but at least initially i'm going to use the JavaSE bundled http server with berkeley db je as the transactional indexing and storage layer.
After many iterations I have designed an almost trivial schema of 3 small core tables which sits atop JE which allows me to implement a complex revision history including branches and renames. Think more of a `fixed' cvs rather than subversion; copies aren't the basis of everything and therefore aren't `cheap', but branching and especially tagging is (revisions are global like svn). Earlier prototypes supported both cheap copies and branching but i felt they lead to unworkable cognitive complexity and I realised that since I think the subversion approach just isn't a good solution at all I should not even try to support it. The work I did on DEZ-1 was for this history database and revisions are stored using reverse deltas. Although this is not the aim or purpose it should be possible to import a full cvs or subversion revision tree and retrieve it correctly and accurately; actually I will likely implement some of this functionality as a basis of testing as this is the easiest way to obtain effectively unlimited test data.
Atop this will sit a wiki-like system where nodes are referenced by symbolic name and/or branch/revision. Having a branch-able revision tree may allow for some interesting things to be done: or it may just collapse in an unscalable heap. Binary data will be indexed by the db but storage may be external and/or non-delta where appropriate.
From very long ago I was keen on using texinfo as the wiki syntax; i'm still aiming for this although it will mean a good deal of work converting the blog and posts over even if automated. The syntax can be a bit verbose and unforgiving though so i'll have to see how it works in practice. There are some other reasons i'm going this route although it is unclear if they will prove useful or not yet; some potential examples include pdf export, response optimisation, and literate programming. Its likely i'll end up with pluggable syntax anyway.
The frontend will be mostly be html+css and perhaps small amounts of javascript; but it's not going to be anything too fancy initially because I want to focus on the backend systems. Authoring is likely to be through external command line and/or desktop tools because I find the browser UX of even the most sophisticated applications completely shithouse and the effort i can afford them would render any I made even more pathetic.
The project itself will also be a personal project: it will be Free Software (AGPL3) and maybe someone else will find it interesting but providing a reference product for others isn't a goal.
Living prototype
This project actually started years ago as everything from a C based bdb prototype to a JavaEE learning exercise. In the distant past I have ummed and ahhed over whether it should be absolute bare-bones C or full-blown JavaEE. I think it may well never get much beyond these experiments but unless I start it definitely will not. So I thought it's about time to put a stake in the ground and get moving beyond experimentation.
So my latest current plan is to begin with implementing my internode software pages. A read-only version covers the basic response construction, namespace and paths, and file and image serving mechanisms. Then moving on to authoring touches on revision and branch management. Adding a news system will allow this blog to be moved across. Comments would make sense at this stage but aren't trivial if moderated, as I would desire. This is most of the meat and would also allow some version of the google code stuff to make it across. Then I could think about what next ...
The idea would be to go live as soon as I get anything working and just continue working on it 'live'; availability not guaranteed. A system in constant pre-alpha, beta, production.
I'm pretty sure i've got the base of the revision systems working quite well. Object names (& other metadata) and object data history are tracked separately which allows for renames and version specific meta-data. It's actually so simple i'm not quite sure it will support everything I need but every use-case i've tried to test so far has been solvable once I determined the correct query. I've still to get a few basic things like delete implemented but these are quite simple and the hardest part now is just deciding on application level decisions like namespaces and path conventions. Other application level functionality like merging is something for later consideration and doesn't need implementing at the db layer. I still need to learn some JE details too.
Initially the architecture will be somewhat naive but once I see how things start to fall out I want to move to a more advanced split-tier architecture based on messaging middleware. This is a long term plan though. I will aim for scalability and performance but am not aiming for "mega"-scalability as that is simply out of scope. Things like searching (lucene) and comments can be tacked on later. Being a personal server authentication/authorisation and other identity related security systems aren't an initial focus.
I've done the texinfo parsing a few times and my current effort is still some way from completion but i will probably just start with the basics and grow it organically as I need more features and only worry about completeness or exporting later on. I will start with processing everything live but resort static snapshots if it proves too burdensome for the server. Actually the revision tree provides the perfect mechanism for efficiently implementing incremental snapshots so it will probably just fall out of testing stuff anyway.
The why of the what
I was prompted to think about this again by the only request about jjmpeg source i've had and i'm also in the middle of a 2-week break. I've spent a couple of those break days poking around but so far it hasn't really gotten it's teeth into me so it will continue to be a slow burn (and i really do just want a short break).
Apart from setting up the hardware and deciding on some `simple' decisions i'm quite close to having something running.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!