About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Source Code Browser
I've just installed a source code browser
on code.zedzone.au
and re-added Code back to the main menu of most pages.
I'm using a slightly hacked up version of gitweb. I needed to add
a bit more structure and style stuff to get the look I wanted and
disable some junk I didn't need. Some more Commodore
colourations for a bit of fun.
This is still work in progress and i'm still trying to decide how
i'll manage the repositories but hey it works. I'll be slowly
migrating all my projects over to it over time. Any java projects
will become modular projects first. I'm not bothering to keep any
history because I don't need it.
libeze 2.0, 1.1
I had a few fixes I did ages ago I thought I should push out.
Mainly some stupid list errors.
I also redid the tree api such that a version bump was required.
The changes are sore of either/or and add an extra argument to
several functions but it was for some consitency with the list api
(no allocations, static init) and I found some intersting uses for
changing the comparison function at search time while working on
playerz.
The software is on the libeze
page as usual. I also added a CHANGES file with the release
notes/changelog.
Weeks ago I also did a lot of other experiments and played with
ideas but they never fully formed. Support for more sophsiticated
serialisation, elf stuff, and lots of experiemnts with memory and
pool allocators. Just can't make a decision on those and I forgot
where they were at so who knows.
I haven't done it for libeze yet but i've started moving my
projects to using git. I don't really like it (the commands are
often obtuse and the documentation isn't user oriented) but CVS
support is starting to wane quite markedly in modern tools. Sigh.
Big Easter Software Bundle!
After basically spending the entirety of Easter (a 4 day holiday
here in Australia) plus half of today I've packaged up and
released a big ol bunch of stuff.
NativeZ 1.0 is an updated version
of CObject which is
portable and modular. I've moved my other projects to use it
rather than their own copies which had evolved and diverged over
time.
jjmpeg 4.0 is updated to use
NativeZ as described on the previous post. There are also a bunch
of bug fixes and small improvements. It now includes a module for
some demos.
zcl 1.0 has been converted to a
modular project and mostly to using NativeZ apis. The tools
package has moved to a demo module.
They are all now capable of cross platform builds and they all
generate platform specific .jmod files as one of the outputs. To
do this they all use a new common java.make which is
a modular and updated version
of an earlier java.make
as covered in the last post (and I made further improvements).
Apart from modules it supports parallel builds, generated java
sources, native code libraries, and cross platform builds using a
very simple configuration mechanism.
They're also a bit smaller due to compression used for some
initialisation tables.
Another project I have gone quite far on is an incremental java
compiler. By scanning the .class files and .java timestamps i'm
able to generate complete and accurate lists of both files that
need to be rebuilt and files that need to be deleted across a
multi-module source compilation. I have all the parts and I think
they should work but I need to tie them together into a usable
system, and then extensive testing.
Sigh, but I need a holiday. I might take most of the week off - like
pretty much everyone else is anyway.
Development Ongoing
I've spent all of Easter so far just hacking away at a bunch of
stuff. Today looks nice so I think I will try to get out of the
house, but who knows. My sleep apnoea has been pretty terrible
lately and when I foget to use my MAD (mandicular advancement
device) i've been wiped out all day, which has been most of this
week. Sigh.
I've primarily been working toward a new modular and portable
release of jjmpeg and zcl, but i've been distracted along the way
and also had some difficulty just making basic decisions.
java.make
I spent way too long on trying to perfect the build system and
things like where intermediate files are stored. There are still
trade-offs that might mean another change, sigh.
But it does work pretty well. The main makefile isn't
particularly complicated even if some of the macro quoting makes
it messy to read. The driver makefiles are trivial - like a
simpler version of automake.
It works by the master makefile including config.make, defining
some variables, and then including java.make.
This for example is the complete Makefile for nativez.
dist_VERSION=1.0
dist_NAME=nativez
dist_EXTRA=README \
build.xml \
nbproject/build-impl.xml \
nbproject/genfiles.properties \
nbproject/project.properties \
nbproject/project.xml
include config.make
java_MODULES=notzed.nativez
include java.make
It's a trivial case so it has a trivial makefile. I added a make
dist target to build up an archive of the source so that meta-data
is really most of the file.
The makefile also builds the native libraries and that is covered
by another makefile
fragment src/<module>/jni/jni.make which is
automatically included if detected.
This is likewise quite trivial for such a trivial example.
notzed.nativez_JNI_LIBRARIES = nativez
nativez_SOURCES = nativez-jni.c nativez-$(TARGET:-amd64=).c
nativez_CFLAGS = -Os -Wmissing-prototypes
nativez_HEADERS = nativez.h
This includes the main .c file and either nativez-windows.c or
nativez-linux.c depending on the current target.
So make does this:
- Compiles all .java under src/notzed.nativez/classes to .class files.
- Generates all native binding headers (from javac -h).
- Automagically creates .d dependency files for all .o files.
- Compiles all .c into .o objects.
- Copies nativez.h file into a staging area for the .jmod.
- Links the .o files into libnativez.so or nativez.dll depending on the target.
- Copies all the .class files into a modular .jar file.
- Copies all the .class files, the .so file, the .h files and license files into a .jmod file.
And only does each step if necessary. For example step 2 doesn't
just take the output of javac which would force every .c file to
be recompiled any time any .java file changes regardless of what
it included. So I use install -C to only copy
changed headers from a staging area. I also use some tricks to
avoid building all the .c dependencies (which requires first
compiling all the java) when you do make clean or make dist.
I'm still debating whether i blow away some of the javac output
directories to ensure an absolutely correct build, or let that be a
separate step and just rely on using the per-module compile flag
which is much faster if less accurate.
I'm also still debating whether it builds the .jar and .jmod files
by default or as a seprate target. For these trivial projects it
doesn't really take any time but if it did it could become a pain
as the code can be executed without either.
jjmpeg is a somewhat more complex case which includes
generated java sources, external dependencies, and (now) generated
c sources and it isn't much more complex to define.
Initially I had everything in the same project but decided to
split it out. The former did allow me to hone down the details on
the build system though and i'm pretty happy with it now; it's
very accurate, simple, flexible, and easy to use.
nativez
I mostly just moved over to the new build system (trivial) and
added a few new functions.
However due to some of the latest in jjmpeg I will probably
revisit some of the underlying ideas here.
zcl
I converted this into a modular project which mostly meant moving
some stuff around. I also changed it to use NativeZ as it's
GC/binding mechanism and to use nativez utility functions where
appropriate. Being modular lets me split of auxilliary demo code
more cleanly so i've done that too.
zcl is all pretty much implemented in a single large (5KLOC) file.
I actually spent a couple of hours splitting it apart into
multiple files because I thought it was getting a bit unwieldy
(and modern emacs struggles with the size of the file
unfortunately). But then I changed my mind and threw it all away.
zcl uses a generated pointer table and typedef casts to manage the
OpenCL function linkage and while it works i'm thinking of
revisiting it again.
I haven't used OpenCL for a while and don't need it at work at the
moment and I can never really think of anything useful to do with
it. So it hasn't been tested much.
jjmpeg
I already had a modular jjmpeg so this wasn't a big change, until
I decided to keep going. First I moved to the new build system.
I already had moved it to NativeZ but there were some lingering
functions that I hadn't cleaned up.
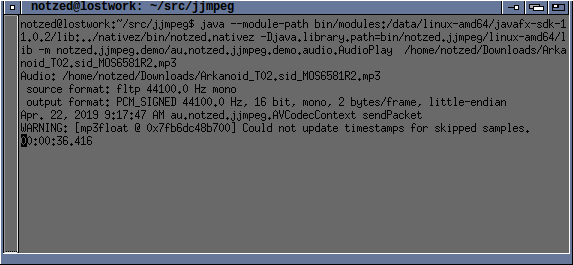
Then I wrote some demos. A simple example to read video frames.
One that saves frames to image files via Java2D functions.
Another that displays video frames in a resizable window at about
the right speed (i.e. a mute video player). And then a music
player, which lets you adjust output parameters.
The music player needed some more bindings and converted enums so
I added that. And it needed a way to get to the samples in a
format I could play.
First a bit of background. In earlier versions of jjmpeg I just
exposed the data pointer array of an AVFrame as a ByteBuffer and
provided entry points into libswscale to allow one to convert
frame data formats. This is very messy and error prone and really
quite pants to use. So copying the ideas from
the PixelReader
from JavaFX I've created a similar AVPixelReader which is flexible
enough to implement MOST of the PixelReader api and hide all the
details of libswscale. The current implementation works by
creating an AVPixelReader targeting the size you want and then you
can write it various Java targets in whatever pixel format you
want. I've got some nice helpers that wrap this to write to some
Java2D BufferedImage (via the DataBuffer) or JavaFX WritableImage
(via a PixelReader).
So I decided to do the same thing with libswresample and samples.
But I don't need to support other pixel readers/writers and only
just dump out arrays of bytes so I made a much simpler interface.
Although libswresample can stream I basically enforced that a
whole buffer needs to be converted at a go otherwise the logic of
tracking the frame gets a bit messy.
At this point I was cleaning things up and thinking about a
release but got side-tracked again ...
jjmpeg - bindings
jjmpeg has a couple of different ways that things are
semi-automated. All simple parameter accessors are created using
C macros. Java JNI handles are loaded via a table which describes
the type, name, and signature. Library functions from
libavcodec.so et al are defined by a table and loaded by a simple
platform-specific function. The tables are all const'd, the
variables are mostly static, so everything should go in read-only
memory and be fairly efficient to utilise.
The tables are handrolled. As are the variables which hold the
function pointers - which means i'm copying them directly from
header files and turning them into variables. This is error prone
and provides no compile time safety confirming that the function
matches the prototype.
And with 64-bit pointers the tables themselves are quite large.
Each entry has pointers to strings, pointers to pointers, and some
flags.
So I thought i'd revisit that.
With a simple code generator I create a struct with all function
variables in it, extracted from the headers at compile time. I
have a compact descriptor - essentially a stream of bytes - to
encode enough information in order to fill out said structure.
It's a mess of shit perl but it works.
The resolution of java objects for jni use is also likewise table
driven, so I did the same for that. It makes the assumption that
jclass, jmethodID, and jfieldID are all pointer sized but that
seems a pretty safe bet.
In short I shaved off about 20% of the size of libjjmpeg.so doing
this.
This is an example of the driver file which defines things of interest.
header avutil libavutil/opt.h {
av_free
av_dict_free
av_set_options_string
av_opt_serialize
av_opt_copy
av_opt_next
av_opt_find
av_opt_set
av_opt_get
...
}
java AVOption au/notzed/jjmpeg/AVOptions$AVOption {
<init>, (JLjava/lang/String;Ljava/lang/String;IILjava/lang/String;)V
p, J
}
I'm not particularly enamoured of the Java definitions but it
simplifies the generator. Hmm, looking now I can use javap to get
this info so maybe I can simplify this somewhat whilst performing
additional verification checks at the same time.
The generator creates a couple of static anonymous structs and a
descrption string, and as a bonus includes the required header
files. There are also some #defines so I didn't have to change
any of the code that uses them.
/* This file was autogenerated on Monday 22 April 09:35:47 ACST 2019: */
/* src/notzed.jjmpeg/jni/extract-proto.pl src/notzed.jjmpeg/jni/extract-proto.pl -f /opt/ffmpeg/4.0 src/notzed.jjmpeg/jni/jj-avoptions.def */
#include <libavutil/opt.h>
static struct functable {
/* libavutil */
void (*av_free)(void *ptr);
void (*av_dict_free)(AVDictionary **m);
int (*av_set_options_string)(void *ctx, const char *opts, const char *key_val_sep, const char *pairs_sep);
int (*av_opt_serialize)(void *obj, int opt_flags, int flags, char **buffer, const char key_val_sep, const char pairs_sep);
int (*av_opt_copy)(void *dest, const void *src);
const AVOption *(*av_opt_next)(const void *obj, const AVOption *prev);
const AVOption *(*av_opt_find)(void *obj, const char *name, const char *unit, int opt_flags, int search_flags);
int (*av_opt_set)(void *obj, const char *name, const char *val, int search_flags);
int (*av_opt_get)(void *obj, const char *name, int search_flags, uint8_t **out_val);
} fn;
static const char *fn_names =
"#avutil\0"
"av_free\0"
"av_dict_free\0"
"av_set_options_string\0"
"av_opt_serialize\0"
"av_opt_copy\0"
"av_opt_next\0"
"av_opt_find\0"
"av_opt_set\0"
"av_opt_get\0"
;
static struct {
// au/notzed/jjmpeg/AVOptions$AVOption
jclass AVOption_classid;
jmethodID AVOption_new_jlliil;
jfieldID AVOption_p;
} java;
#define AVOption_classid java.AVOption_classid
#define AVOption_new_jlliil java.AVOption_new_jlliil
#define AVOption_p java.AVOption_p
static const char *java_names =
"#au/notzed/jjmpeg/AVOptions$AVOption\0"
".<init>\0(JLjava/lang/String;Ljava/lang/String;IILjava/lang/String;)V\0"
",p\0J\0"
;
Rather than have a single global table I have one per file
(roughly on per class). This leads to a small amount of
duplication but keeps everything simple and isolated and also aids
incremental compilation. By having each table static to the
compilation unit also allows the optimiser to remove any address
calculation - it just goes to the linker via the .bss section.
I'm still thinking of other ways to reduce the binding size and/or
overhead. For example the accessors are pretty small ... but
there's many of them. The problem is if I use tables I need to
keep them in sync between Java (e.g. field ids), or if I use
strings then I need table lookups. ffmpeg seems to be moving
toward the 'libavutil/opt.h' mechanism for accessing everything
anyway (probably because of python influence?) so perhaps I should
just use that or at least evaluate it.
But I will first have to move these changes to nativez and perhaps
zcl.
Other
I fixed a few bugs along the way. I wasn't creating a few objects
correctly so they weren't being tracked by the recovery process -
mainly a holdout from earlier implementations which tracked
objects differently. I wasn't freeing an AVFormatContext properly
- these can be created in two different ways and need to be freed
differently. Sigh, even the free functions take different
argumements (some of the avcodec api is such a mess). Anyway I
use the opaque pointer to track this so I could do it properly.
There are probably other leaks but it's rather much harder to test
than a standalone C program like playerz.
I also looked very briefly at writing a Vulkan binding as well.
Hmm, i'm not sure on this one, it's a pretty big API although as I
learn more it will probably shrink in apparent size. But
regardless it's a bit more than a weekend project that OpenCL was.
It will probably need a code generator to make it managable, at
least for certain objects like the construction parameters. I'm
mostly concerned with the overheads so will be looking into
different mechanisms.
And these might trigger a reworking of everything else along the
way.
Still, i'm not sure yet on it, I don't really have a need for it
or know it well enough to do a good job either.
Modular Java, Make. FTW!
I've been working on packaging up the modular versions of various
bits of software I have. One big change is that due to the way
javac (and to a lesser extent netbeans) works I had to rearrange
the source tree, and it also completely changes the way javac is
invoked. So my
previous java.make
is no longer useful.
As i've now added some inter-module dependencies (e.g. nativez)
there's a another question: do I keep them as separate packages,
or do I just combine them into a single modular project?
For work I went through the same question previously and ended up
just putting everything in the one project.
- It has implications on version repository maintenance - all in
one project makes it a bit simpler;
- I've got makefiles to handle native and generated code and it
fits fairly cleanly into the way netbeans enforces the source
tree (for better or worse). In addition to src/module/classes
there is optional src/module/jni/Makefile (native code) and
src/module/gen/Makefile (generated java) which are automagically
included in the build at the right times.
- I have build dependencies at the module level and a makefile
which builds each java module separately. To guarantee correct
builds it purges all classes before building;
- netbeans (≤ 10) doesn't seem to work well with foreign
modular projects. When you add them as a dependency it just
references the build directory but wont rebuild them and wont let
you navigate to them. It's a fucking pain.
So ... for similar reasons i'll probably do the same.
One strong reason not to is that the projects aren't as closely
related - jjmpeg, zcl, and so on.
So what to do ...
Recursive Makefiles
I thought one solution is to just have a build system which
isolates the modules so that you can only build the ones you're
interested in. i.e. if you don't have external dependencies for
one you're not interested in, just build the rest.
So ... based on the structure I have already I spent an inordinate
amount of time trying to get the separate makefiles to work. In
short: I fucking couldn't. I got 95% of it working, and the
dependencies were relatively simple (yet very fragile!) but I just
couldn't get make to rebuild some targets on a single run. A
second run would always work. Just not good enough.
The problem is that as the toplevel makefile doesn't know when the
sub-makefiles need to run it has to try to run them every time
using phony targets. But it has to run them at the correct time.
Generators are run first, then the module is compiled (which
generates any native .h files), then jni is built if it exists,
resources are copied, and jmod or jars created as appropriate. I
could almost get it to work but some of the dependencies weren't
recognised as updated; make would say 'this target needs
rebuilding' then the next line 'this target is updated'. I think
it has something to do with the way it handles phony targets and
because I had multiple references to a status file from different
levels. It would recognise one update but not another. I could
get accurate builds, but not always get the jar/jmod from 'make
jar'. I also had to do some other weird tricks like dummy actions
on rules which where updated by dependencies via phony rules. I
mean it worked but it was very obtuse.
I actually got it very close and it even supported parallel make
quite well, but fuck what a pain to get working.
One Makefile To Rule Them All
So I did some searching and came across a chapter of a book that
suggested using a single makefile, but using includes to make the
parts more manageable.
So I took the per-module makefiles and stripped out some common
stuff, renamed some variables and redid the toplevel makefile.
After a little mucking about with the generated depenedencies a
little bit I had something working within an hour. And parallel
make works even better.
As an example this is what the toplevel makefile currently looks
like. It automatically finds various things like java source,
generators, and native sub-systems and runs them all at the
correct time via the dependency graph.
nclude config.make
java_MODULES=notzed.jjmpeg notzed.nativez notzed.jjmpeg.fx notzed.jjmpeg.awt
notzed.jjmpeg_JDEPMOD=notzed.nativez
notzed.jjmpeg.awt_JDEPMOD=notzed.jjmpeg
notzed.jjmpeg.fx_JDEPMOD=notzed.jjmpeg
notzed.jjmpeg.fx_JAVACFLAGS=--module-path /usr/local/javafx-sdk-11/lib
include java.make
Provided targets include '{module}', 'jar', '{module}-jar'.
So now I have that working I can think about separating the
projects into separate ones rather than modules in way that lets
them all be built together. Probably in that case I would add an
{module}_XDEPMOD variable which references the location and
module(s) and just builds them before doing anything else. On the
other hand this isn't the way you do it with autoconf (and other
build systems, although some handle it) for external dependencies
so maybe it's not worth it.
Faster ... Faster Builds
Whilst doing this I noticed early on that javac has a '-m' flag
for building modules that performs dependency checking. Either I
didn't notice this when I first wrote the modular build system or
I didn't think it important: while it only rebuilds what is
necessary it doesn't remove stale files (deleted inner/anon
classes or colocated classes).
Slightly stale builds are not the end of the world so it's
probably not a big ask to require a make clean occasionally anyway
as the improved build time is significant.
But there is a better way to do it!
Using the jdk.compiler one can wrap access to javac and do some
interesting things. To cut a long story short I wrote a javac
server that monitors which source files are recompiled and
automatically deletes any stale files. This works if all compiles
go through the server but can result in stale files if files are
compiled otherwise.
So I wrote some more code that scans the compiled class files once
and then does a reverse lookup based on the SourceFile,
this_class, and module-source-path to discover stale files and
prime the database. This is done at server startup. Actually it
should be able to be run at any time to post-fix the class tree,
so it could be incorporated into the build in other ways.
I wrote a simple .class parser (almost trivial infact) to be able
to retrieve the class metadata and some other simple code to do
the source lookup.
I wrapped this up in a simple REST-like-service and a script
'sjavac' that compiles and runs the server on demand and then
passes requests to it. The server just shuts itself down if it's
idle for too long. The compile times for jjmpeg+nativez isn't
very long anyway but using the compile server alone speeds up
complete builds significantly, and incremental builds are now
sub-second.
Another issue is concurrency from parallel builds. javac will
recompile any out of date classes it encounters even if it isn't
in the module specified by -m - which can lead to two separate
compilers working on the same files. This conflict can break a
build run. But I think this is due to incorrect makefile
dependency definitions as if they are done properly this shouldn't
happen.
sjavac serialises compiles at the module level anyway because the
compiler uses multiple threads already (afaict, it's a bit too
fast to find out on this project) and I haven't set the code up to
handle concurrent compile requests anyway, but I want it to be a
drop-in replacement for javac for a project build.
Now that i've moved to a single toplevel makefile it's actually a
very simple setup. The java.make referenced above is only 100
lines long. sjavac is 100 lines of bash and 600 lines of
stand-alone java. And together these provide faster, more
accurate, and repetable builds than a special tool like ant or
maven. With significantly less setup.
Update 10/4/19: Oh for fucks sake!
It turns out that javac -m doesn't recompile dependent classes if
they are out of date, just the first-level dependencies or any
missing classes they require. This doesn't make a lot of sense
because there are many changes where this behaviour would lead to
an inconsistent build so it makes this option fairly useless.
It's a trivial change to the makefile to fix it but it means that
it only builds incrementally at the module level.
I guess this gives me the next problem to solve. I think I have
enough scaffolding to be able to extract the dependency tree from
the .class files. Well I'll see on that.
modular cross-platform jjmpeg
So well this isn't an announcement of a new release because i'm
basically too lazy to package it up at the moment.
But I have created a modular jjmpeg for Java 11 and added support
for cross compilation. I'm going to be playing with some videos
for work so I thought it might be useful if I generate any tools
for other users.
As part of it i've moved it's use of CObject over to using the
previously mentioned nativez stuff. I also moved a bunch of the
JNI utility functions over to nativez because they're generally
useful elsewhere.
Who knows when i'll get to publishing it.
ez-alloc, libeze, that music player thing
So it's been a pretty long week of hacking. I went deep on the
memory allocator and eventually got one debugged and working. I
made some very silly mistakes which made what is fairly
straightforward code a lot harder to get working than it should
have been but that's the nature of the beast.
It grew into about 1000 lines w/ comments, but then again GNU libc
malloc is 5000 in just the main file.
I'm kinda bummed out about the performance after all that though,
which is leading down another hole ...
ez-alloc
So basically I started by taking a few ideas from GNU libc malloc:
- Separate free lists for every size of small allocations.
- Coalescing of free blocks is done before a large allocation not at free.
- Best fit.
- There is an 8 byte (size_t) allocation overhead which contains
some management bits.
- The minimum allocation size is 32 bytes.
- There is a previous size field if the previous block is free
to speed up coalescing.
Plus some other ideas and changes.
- Large free blocks are stored in a balanced binary tree rather
than an approximate skip-list (I think this is what malloc
uses).
- Tiny allocations use a completely different page based allocator.
- They have zero per-allocation overhead;
- The minimum size is 8 bytes (void *) with an 8 byte alignment;
- Power of 2 sizes are aligned to their size;
- Allocations are never coalesced.
- If a 'large' free block is within the tiny allocation range
then it will never be found by the large allocator so to avoid
polluting the index they are stored in a 'lost' list. These
are not really lost and will be coalesced automatically.
Before I got this working I decided to drop the per-size small
lists. It was cluttering the code and I wanted to see how it
worked without it.
I also added a huge allocator which uses a separate mmap for very
large allocations, which is also what GNU libc does.
For accuracy testing I created a LD_PRELOAD module which replaced
the memory allocation calls with my own and ran some binaries like
ls or xterm. I can also use it to create a log of memory actions
which I can replay so I can actually debug the thing.
For performance and overhead testing I have a small
not-particularly representative test using libavl (it just
allocates 1 larger block then thousands of 32-byte blocks). I
read /usr/share/dict/words into an array. Then in order I insert
them all into the tree, look them all up, then remove them.
And another also not-particularly representative loop which frees
and allocates random amounts.
Things that work well
I think the tiny allocator quite neat. It uses page alignment and
a magic number to be able to allow ez_free() to quickly check
whether an allocation is a tiny allocation and handle it
appropriately.
It helps avoid fragmentation in the main memory and can save a lot
of memory if there are many allocations of the same size.
It would be a big problem if a pointer was mis-identified as a
tiny address when it wasn't. The possibility of this is not zero
without additional checks, although very very unlikely.
Using ez-list and ez-tree makes the code relatively
straightforward and easy to read. Having the same node pointers
being used for either is a big plus - I can move nodes between
trees or lists easily. List nodes can be removed without knowing
the list header so I can have many lists but not care where they
come from when performing a coalsecing (I use a single status bit
to indicate wheather the block is in a list or the one tree).
This makes the coalescing function 'just work' without having to
worry about maintaining other state as mergable blocks are merged.
Things I really fucked up
Probably the worst was that I forgot to mask out the status bits
of the size in the tree compare function. So ... nodes would go
missing when I fiddled with the bits! These bits don't get
changed very often while the node is in the tree so that lead
to difficult to track down problems.
Idiot. Idiot.
gcc and weirdness
The C99+ aliasing rules broke certain sequences of ez-list calls
as well. For example if you perform node.remove on the head of
the list and then list.addhead, it would write the pointers back
in the wrong order. Another subtle and hard to find bug and gcc
didn't warn about it. I found a workaround using a soft
barrier asm volatile ("" : : : "memory"); in
node.remove but I don't really like it as I can't be sure other
sequences might break. Using -fno-strict-aliasing works too of
course. Maybe i'll just make the list and node pointers volatile,
I don't think it will affect performance negatively doing this and
the code pretty much requires them to behave that way.
I've had some other very strange behaviour with gcc as well,
sometimes the optimiser makes radically different decisions for no
obvious reason. It appears to do it even when I haven't
made any code changes, but I don't think my memory is reliable to
be absolutely sure on that.
Another waste of time?
The xterm test was quite interesting. With the tiny allocator
enabled it quickly reaches a steady state with 21 pages of tiny
allocations having over 50% occupancy. There are only 6 free
large blocks, and 13 lost ones.
However pmap indicates more total memory is consumed vs glibc
malloc which was a bit of a bummer.
For the performance tests I fix my CPU at a specific frequency to
get more consistent and repeatable results.
The tree test runs about 10% faster than system malloc and saves
roughly 1MB of maximum rss (/usr/bin/time), about 8.5MB vs 9.5MB.
At least that's a winner. Actually if I remove the lookup loop so
that the alloc code is more of the total time then the performance nearly
equalises. So most of the performance improvement is down to
allocation alignment and not using a tiny allocator. Which is quite useful all the same.
However the random test runs about 2-3x slower than system malloc
and uses about the same total amount of memory. That was a real
bummer and every time I compile the code it seems to get a bit
slower (and use more peak memory to boot). But ... this is
absolutely nothing like the allocation used in a real program such
as xterm so I don't even know if it's worth worrying about. I
should try with something more demanding but they likely already
use pools or the like.
I suppose even if it is a bit slower it can be used as a
low-overhead free-supporting pool allocator which might be useful.
I did some shitty profiling and found that the biggest cost was
probably the tree manipulation during ez_alloc(). There are some
simplish things I haven't tried that should help it.
For example when i split a free block I always remove the node and
then re-insert it if there's any of it left (either the lost list
or back into the tree). If I can determine that the new node has
not changed ordering then it is possible to just replace the entry
directly and save both the remove and insert.
When I coalesce nodes I find full consecutive runs and remove all
the ones i've found as I go. Then insert the coalesced one back.
It should be possible to do the same check here and save one of
the removes and the insert in some cases but it is a bit more
difficult to determine (maybe just find the largest node that
belongs to the tree and try that?).
All non-tiny allocs trigger a coalesce and then search the free
block tree. GNU malloc can sometimes use the most recently freed
block here, which in this case would avoid the tree altogether.
Finally, I could always add back the specific-sized 'small' lists
for recently freed blocks but I want to avoid that for various
reasons.
I can't see these doubling the speed for this silly random
test-case but I could be wrong.
I suppose I could also try other indexing structures as an
alternative to the balanced tree such as a skip-list (really, a
skip-index-array I guess). I've not used them before but I had a
break yesterday and today it seems like it shouldn't be too
difficult.
Update: 3/2/2019 I tried the skip-index idea. And lo, once
I got it working the random test is now on par with GNU libc. I
guess I will go with that then. I suppose then all i've really
done is re-implement GNU libc malloc in the end; although the tiny
allocator might benefit some usages. And well - the
code is 1/5 the size and considerably more readable. And
i'll wrap it up in a way that can be used as a pool allocator.
I'm back to work this week so i'll have to give it a break for a
while anyway; i'm also exhausted and need to get away from it.
Spent some time in the garden today although I discovered the 47C
head might've killed more roses out the front. Sigh.
Profiling
I haven't really looked into C profiling for years. Well apart
from /usr/bin/time or gettimeofday() (although I just found
clock_gettime()).
I suppose people use oprofile? I should at least look into it.
gprof is pretty much useless. Well I guess it did identify the
tree manipulation as the major cost but looking at the code would
tell you that anyway. It just doesn't sample often enough (i'm
getting well under 1% sampling of running time).
Searches tend to turn up advice to use cachegrind, ... but I can't
see anything resembling cycle counts in any of it's output.
Ubuntu wont let me install kcachegrind because of some dependency
issue (probably because i've blacklisted some snot like
fucking-shit-audio) but I can't see how that can make up numbers
which aren't there already
So ... I started working on my own as well. Yeah like that's a
good idea! Ok, maybe it's really time to give it a break. It's
really not something I need and i'm not sure
-finstrument-functions is going to do a good enough job. I'll see
i'll see.
I did snarf some more code out of ezesdk that I've added to
libeze. I've got a very small ez-elf that lets you do basic but
useful things like lookup function names.
That music player thing
So this has been a pretty extended foray well beyond the code I
needed to implement a music player! I haven't touched that for
weeks - on the other hand I have just left it running for those
weeks and it's still going fine. The remote works well. I've got
some tools to send commands around and it all just works.
The last time i mentioned it I was wondering how to do a menu but
that night I came up with the obvious answer for a device with no
display. Just make it talk!
So I poked around with espeak-ng for a while and fiddled with the
player code so I can inject synthesised signal into the audio
stream.
I got as far as implementing a say-this-song function. When you
press the lips button it says the title and artist of the current
song if they're available or just the filename if they're not. As
I saw mention in a mailing list; it's quite a clear voice but
unintentially quite hilarious at times! It also speaks too fast
and doesn't pause anywhere nearly long enough for full stops but
at least the former can be adjusted.
I then hit a bit of a design snag. The keyboard monitor takes the
keys pressed and turns them into high level player commands. For
example the cursor keys are
fast-forward/rewind/next-track/previous-track. But during a menu
these would change behaviour and be for navigating the menu.
So I wasn't sure where I should put the menu driver logic. If it
was in the player then the keyboard module would just send through
raw keypresses for the other keys and the player would behave
differently depending on what's going on.
If it's in the keyboard module then it could route messages around
to potentially other components and the player would implement
higher level functions like 'enter menu mode', 'say this',
'preview that', 'rename playlist' and so on.
My initial ideas were a but muddled and the second case seemed a
bit messy. But now I think about it again it makes a lot more
sense and I can leave the player to playing music and it only
really needs to maintain a 'playing' or 'not playing' state and do
some low level stream pause management to make sure it all works
with alsa.
Regardless, I do have a goal here and once I add a basic menu that
would basically be a working player but i'm not sure when i'll get
back to it.
Bugz
Fixed a couple of bugs in the blogz code to do with post urls, and
added newer/older links on the individual post page.
I think I can now setup robots.txt so it doesn't over-index.
Should be able to just block '/tag' and '/blog?' I think. So it
just indexes the front page and then anything /post/* it finds
from it. Any cralwer should be able to find the whole blog from
one post now they're linked.
Well i've put it in and i'll keep an eye on the logs to see what
happens.
I can't add the post title to the prev/next post links yet but
i've been working on a database based index which will allow it
and some other useful things. I could just hack another index
into the compiled-in indices but I think that path has outlived
it's usefulness.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!