
Object detector in action
Well I really wanted to see if the object detector I came up with actually works in practice, and whether all that NEONifying was worth it. Up until now i've just been looking at heat-maps from running the detector on a single still image.
So I hacked up an android demo (I did start on the beagleboard but decided it was too much work even for a cold wintry day), and after fixing some bugs and summation mathematics errors - must fix the other post, managed to get some nice results.
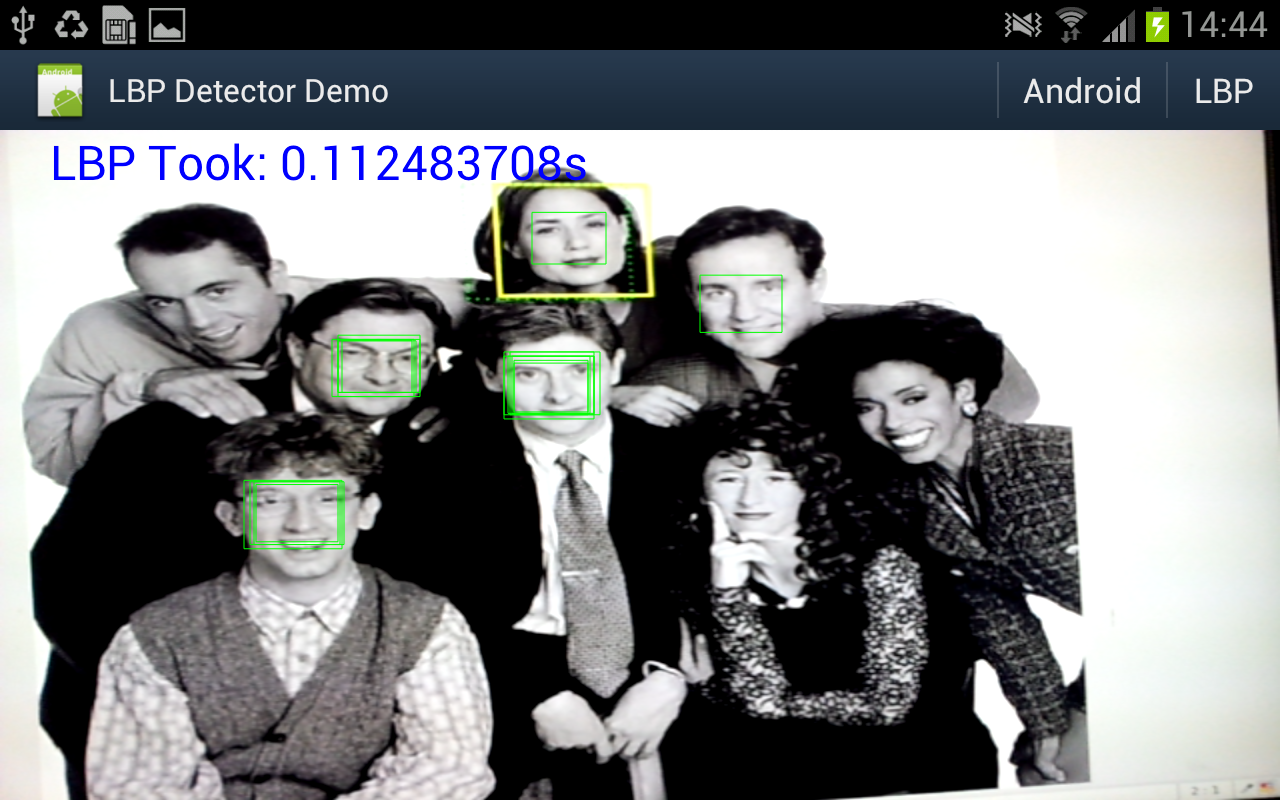
A bit under 10fps. And for comparison I hooked up some code to switch between my code or the android supplied one.
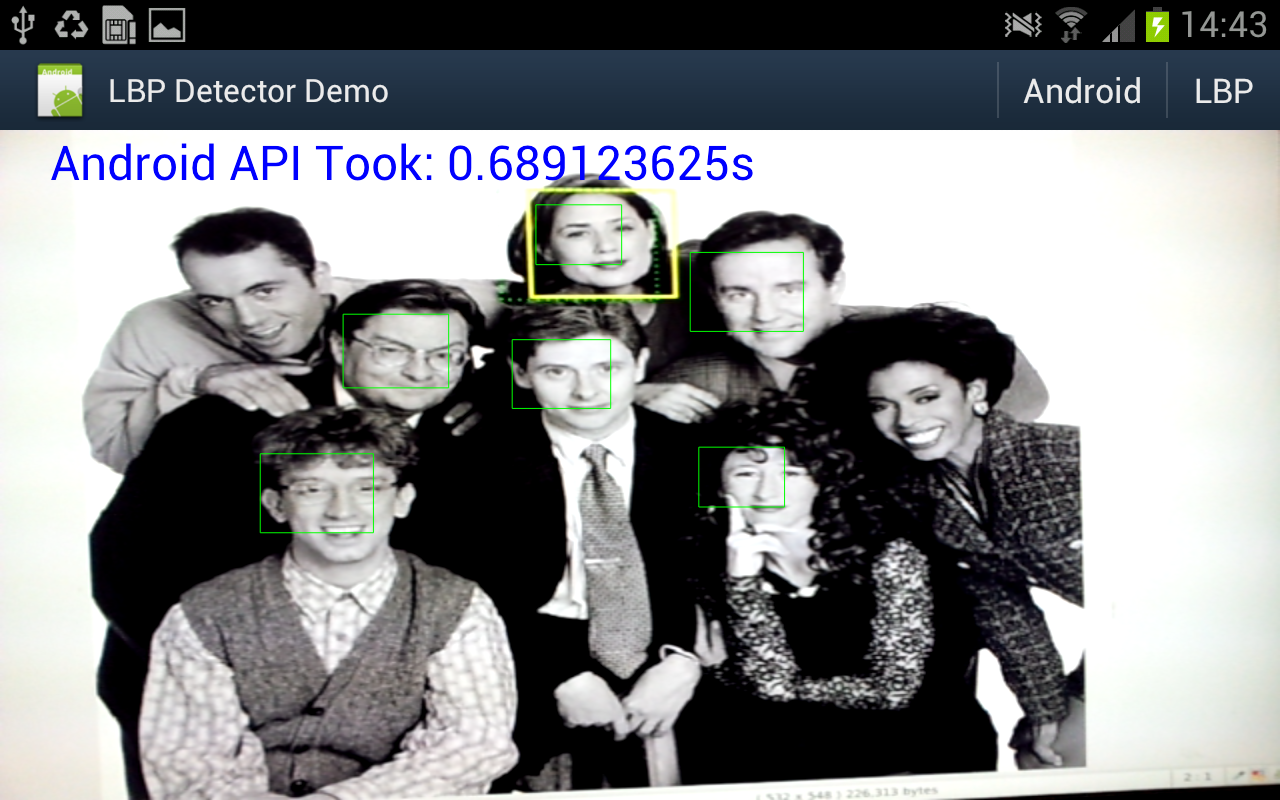
Well under 2fps.
I was just holding the "phone" up to a picture on my workstation monitor.
Some information on what's going on:
- Device is a Samsung Galaxy Note GT-N7000 running ICS. This one has a dual core ARM cortex A9 CPU @ 1.4Ghz.
- Input image is 640x480 from the live preview data from the Camera in NV12 format (planar y, packed uv).
- Both detectors are executing on another thread. I'm timing all the code from 'here's the pixel array' to 'thanks for the results'.
- The LBP detector is using very conservative search parameters: from 2x window (window is 17x17 pixels) to 8x window, in scale steps of 1.1x. This seems to detect a similar lower-sized limit as the android one - and the small size limit is a major factor in processing time.
- At each scale, every location is tested.
- Android requires a 565 RGB bitmap, which i create directly in Java from the Y data.
- The LBP detector is just using the Y data directly, although needs to copy it to access it from C/ASM.
- The LBP detector pipeline is mostly written in NEON ASM apart from the threshold code - but that should optimise ok from C.
- A simple C implementation of the LBP detector is around 0.8s for the same search parameters (scaling and lbp code building still uses assembly).
- The LBP detector is showing the raw thresholded hits, without grouping/post-processing/non-maximum suppression.
- The LBP code is only using a single core (as the android one also appears to)
- The LBP classifier is very specifically trained for front-on images, and the threshold chosen was somewhat arbitrary.
- The LBP classifier is barely tuned at all - it is merely trained using just the training images from the CBCL data set (no synthesised variations), plus some additional non-natural images in the negative set.
- Training the LBP classifier takes about a second on my workstation, depending on i/o.
- Despite this, the false positive rate is very good (in anecdotal testing), and can be tuned using a free threshold parameter at run-time.
- The trained classifier definition itself is just over 2KB.
- As the LBP detector is brute-force and deterministic this is the fixed-case, worst-case performance for the algorithm.
- With the aggressive NEON optimisations outlined over recent posts - the classifier itself only takes about 1 instruction per pixel.
A good 6x performance improvement is ok by me using these conservative search parameters. For example if I simply change the scale step to 1.2x, it ends up 10x faster (with still usable results). Or if I increase the minimum search size to 3x17 instead of 2x17, execution time halves. Doing both results in over 25ps. And there's still an unused core sitting idle ...
As listed above - this represents the worst-case performance. Unlike viola & jones whose execution time is dynamic based on the average depth of cascade executed.
But other more dynamic algorithms could be used to trim the execution time further - possibly significantly - such as a coarser search step, or a smaller subset/smaller scale classifier used as a 'cascaded' pruning stage. Or they could be used to improve the results - e.g. more accurate centring.
Update: Out of curiosity I tried an 8x8 detector - this executes much faster, not only because it's doing under 25% of the work at the same scale, but more to the point because it runs at smaller image sizes for the same detected object scale. I created a pretty dumb classifier using scaled versions of the CBCL face set. It isn't quite reliable enough for a detector on it's own, but it does run a lot faster.