
that 'graphical' demo
Ended up coding that 'graphical' demo. Just another mandelbrot thingo ... not big on the imagination right now and I suppose it demonstrates flops performance.
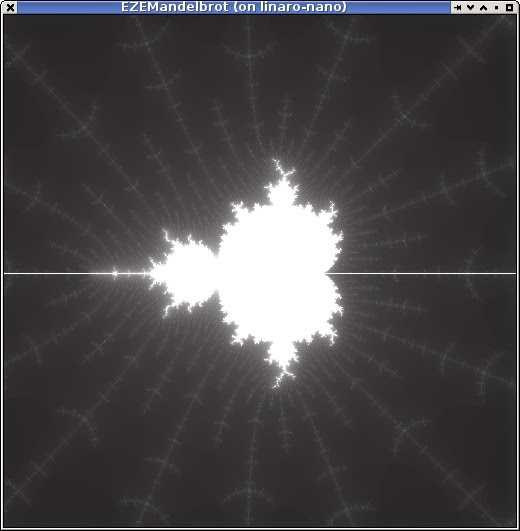
This is using JavaFX as the frontend - using the monocle driver as mentioned on a previous post. I'm still running it via remote X11 over ssh.
I have each EPU core calculating interleaved lines which works quite well at balancing the scheduling - at first i tried breaking the output into bands but that worked very poorly. The start position (not shown, but is (-1.5,-1.0) to (0.5,+1.0) and 256 maximum iterations) with 16 cores takes 0.100 seconds. A single-threaded implementation in Java using Oracle JDK 1.8 on the ARM takes 1.500 seconds, i'm using the performance mode. A single EPU core takes a little longer at 1.589s - obviously showing near-perfect scaling of the trivially paralellisable problem here even with the simple static scheduling i'm using.
For comparison my kaveri workstation using the single-core Java takes 0.120 seconds. Using Java8 parallel foreach takes that down to 0.036 seconds (didn't have this available when I timed the ARM version).
Details
The IPC mechanism i'm using is an 'ez_port' with a on-core queue. The host uses the port to calculate an index into the queue and writes to it's reserved slot directly, and so then the on-core code can just use it when the job is posted to the port.
The main loop on the core-code is about as simple as one can expect considering the runtime isn't doing anything here.
struct job {
float sx, sy, dx, dy;
int *dst;
int dstride, w, h;
};
ez_port_t local;
struct job queue[QSIZE];
int main(void) {
while (1) {
unsigned int wi = ez_port_await(&local, 1);
if (!queue[wi].dst) {
ez_port_complete(&local, 1);
break;
}
calculate(&queue[wi]);
ez_port_complete(&local, 1);
}
return 0;
}
This is the totality of code which communicates with the host. calculate() does the work according to the received job details. By placing the port_complete after the work is done rather than after the work has been copied locally allows it to be used as an implicit completion flag as well.
The Java side is a bit more involved but that's just because the host code has to be. After the cores are loaded but before they are started the communication values need to be resolved in the host code. This is done symbolically:
for (int r = 0; r < rows; r++) {
for (int c = 0; c < cols; c++) {
int i = r * cols + c;
cores[i] = wg.createPort(r, c, 2, "_local");
queues[i] = wg.mapSymbol(r, c, "_queue");
}
}
Then once the cores are started the calculation code just has to poke the result into the processing queue on each core. It has to duplicate the struct layout using a ByteBuffer - it's a bit clumsy but it's just what you do on Java (well, unless you do some much more complicated things).
int N = rows * cols;
// Send job to queue on each core directly
for (int i = 0; i < N; i++) {
int qi = cores[i].reserve(1);
// struct job {
// float sx, sy, dx, dy;
// int *dst;
// int dstride, w, h;
//};
ByteBuffer bb = queues[i];
bb.position(qi * 32);
// Each core calculates interleaved rows
bb.putFloat(sx);
bb.putFloat(sy + dy * i);
bb.putFloat(dx);
bb.putFloat(dy * N);
// dst (in bytes), dstride (in ints)
bb.putInt(dst.getEPUAddress() + i * w * 4);
bb.putInt(w * N);
// w,h
bb.putInt(w);
bb.putInt(h - i);
bb.rewind();
cores[i].post(1);
}
The post() call will trigger the calculation in the target core from the loop above.
Then it can just wait for it to finish by checking when the work queue is empty. A current hardware limitation requires busy wait loops.
// Wait for them all to finish
for (int i = 0; i < N; i++) {
while (cores[i].depth() != 0) {
try {
Thread.sleep(1);
} catch (InterruptedException ex) {
}
}
}
These two loops can then be called repeatedly to calculate new locations.
The pixels as RGBA are then copied to the WritableImage and JavaFX displays that at some point. It's a little slow via remote X but it works and is just a bit better than writing to a pnm file from C ;-)
I've exhausted my current ideas for the moment so I might drop out another release. At some point. There are still quite a lot of issues to resolve in the library but it's more than enough for experimentation although i'm not sure if anyone but me seems remotely interested in that.