About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Cheese & Rosemary Biscuits
I did some midnight baking a couple of days ago, and tried making cheese and rosemary biscuits this time.

It's mostly butter and cheese. It was very greasy. I added more flour than the recipe called for too, although since I used cheddar rather than parmesan it probably had a lot more grease to absorb. It's not that I didn't have parmesan handy, but it was easier grating the cheddar.

I don't think my oven is the correct temperature. The recipe called for 6-8 minutes but after 10 they were still quite not yet done. I cooked them a bit more to brown them up.
Once they cooled down they were quite tasty, the rosemary sharpens the cheese taste quite well. I added some chillies too for a little bite in the after-taste.
They were a little crumbly and fragile so not really a great biscuit, although they do 'melt in your mouth'.
Cheese & Chive Biscuits
I tried making some cheese and chive biscuits.

It looks like I added a bit too much garlic chives. And the food processor over-processed them.

And the garlic was a bit overpowering. The recipe called for oil and not butter, which seems wrong.

They look a lot better than they tasted. Very tough and too heavy, with a strange flavour. It was almost like a thick tough party-pie base. Not cheesy enough either, despite using plenty of parmesan.
CLGLTexture2d
Hmm, bit of a slow and frustrating today although it felt like I did something by the end of it. I was up till nearly 4 but couldn't last it out to watch the Australian soccer game - pity, it sounds like it was a decent match. Just as well as some tree loppers came cutting trees around 10am and woke me up with the chainsaw and mulching machine. The fence and wall where my bedroom is seems to act like a wave guide for audible sound waves, so anything on the street immediately in front of the house is loud and clear through the closed window.
I was trying to play with using image2d_t objects in the OpenCL code to see how they work. I didn't get very far - not a lot of documentation and the whole api is still a little too new. I eventually found one simple but show stopper bug, but there was also other puzzling behaviour such as not being able to use mono-channel textures. I think I filed the first bug for JOCL on the jogamp bugzilla with that patch which either implies it's quite stable, or nobody else is using it. I haven't had much luck building JOCL so I might have to wait for a new build to include the patch I sent before progressing along that track.
I guess i'll leave that stuff for now and just try to get the basic algorithm working. I'll be happier once I can remember the bits of API i need without having to lookup every single change so I don't have to spend so much time mucking about with the setup.
This call may be monitored ...
For once I asked that the unsolicited call I got from someone trying to sell me something that I didn't want the call monitored.
And they said well we can't continue as it has to be monitored ...
Well fuck 'em then, not like I was going to change my phone account anyway as I know i'm on the cheapest one and I never make calls. Pity everyone didn't do it, hardly a way to sell something if they can't talk to you, they'd quickly change their tune.
Telstra btw ... actually they shouldn't even be calling me, last time they asked me (a very long time ago) I said I didn't want to know about 'special offers' anymore - probably just trying to drum up more business with the NBN deal.
Update: I'm not entirely sure of this, but it seems from some whirlpool discussions that any call involving a potential financial transaction must be recorded for legislative requirements. Still, they should not have been calling me anyway, and as soon as Internode offer a way to switch from ADSL2+ to Naked ADSL2+ in a way which I wont potentially lose an ADSL capable phone line (crowded copper issues), then the big T can get the big F..
convert_uint4
Got the main algorithm i'm working on converted to run on the GPU today - it doesn't seem to be producing the correct results yet, but it should be doing the right steps. Speed is a bit disappointing so far too. But on linux you're flying pretty blind as to what is going on on the card so I don't know if it's merely an uncoalesced memory access problem, not mapping well to the multiprocessors, or something else. I guess I should work out the FLOPS and see if i'm just pushing any limits.
Because local memory is so limited i'm storing data packed in bytes (I need to re-read the same section of data many multiple times), but the unpacking into vectors is pretty inefficient. Even the built-in functions provided aren't as efficient as they could be:
uchar4 *src;
uint4 work = convert_uint4(src[0]);
Compiles into more code than:
uchar4 *src;
uchar4 v = src[0];
uint4 work = ((uint4) { v.x, v.y, v.z, v.t }) & ((uint4)0xff);
Which surprisingly compiles into more code than:
uint *src;
uint v = src[0];
uint4 work = (uint4) { v.x>>24, (v.y<<8)>>24, (v.z<<16)>>24, (v.t<<24)>24 };
The latter would be pretty nasty with SIMD (without an unpack or shuffle at least), but with at least the AMD GPU it is only a half dozen shifts and and's.
Changing a single convert_float4 to a variation of the last one above gave me a 20% speedup ... which probably means i'm just doing it the wrong way to start with ... If I had more local memory I'd convert to a more convenient working size as I loaded it, but alas I don't have enough for this algorithm.
Next i'm going to look at using image objects to access the memory instead. This gives automatic format conversion and caching, and removing the need to manually cache stuff in local memory allows for more flexibility in parallelisation. Unfortunately JOGL doesn't seem to expose the basic image routines from OpenCL without using OpenGL as well which I was hoping to put off for a bit.
I guess I should really try and get a version that at least gives correct results too.
vloadn
Well I finally have a lowly OpenCL capable card to play with. Just an ATI HD 5770, mostly because of the power budget. Unfortunately that was still enough to make an almost silent machine into a loud fan, and there's another card in where which almost completely covers the fan inlet on the graphics card, so it might have to be removed.
I have been using a simple bit of code to play around with to learn how the device accesses memory and processes jobs and discovered a few things along the way. The code does a simple debayering, converting 5 channel data into 5 separate data planes.
vloadn seems to be something to avoid. It appears to treat the input as unaligned, even though the documentation implies it should be aligned. Perhaps I need to use an aligned directive on the parameters too ... but an easier solution seems to be just to change the source datatype to a vector type and just index it as an array.
Just by changing the code to use a vector array type versus a vload I got a 24x speedup(!).
Some other less obvious results ... If I remove the output of one or two of the channels, the code runs nearly 50% slower. Running on the CPU (quad phenom II something or other) using the same OpenCL code via AMD's CPU backend is about 8x slower than the GPU. I wonder what hand tuned SIMD code could manage ... given they have comparable power profiles.
Splitting the job into multiple parts effectively - both `horizontally' to allow coalesced memory access, and `vertically' to allow greater concurrency - seems to be a bit of an art, and no-doubt very architecture dependent. And unfortunately critical to getting better output.
Horizontally I assign a work-item to each column of 8 output bytes, for 16 bytes of input, across 128 work items. I think that should be an optimal memory access pattern.
Vertically I'm sticking to powers of 2 since the algorithm needs it, but it seems splitting the local work-groups into sets of the number of compute units (i.e. 10 on this card) seems to work better. But I'm not really clear how the global/local work dimensions really maps to the hardware once you get beyond the trivial case of single jobs.
I'm not sure if i'm interpreting the disassembly correctly, but the processor appears to be more VLIW than SIMD. Each of the 5 channels seems to execute independent instructions on independent data. I guess this should allow it to execute scalar code better, but it must come at a pretty significant cost to die space and power. I wonder if this is also why they still clock relatively slowly versus something like the CELL.
My final code equates to about 12000 decodes per second of a 1024x768 frame, which is more like what I was expecting - my first cut was doing about 400 which was obviously way out. I'm not sure if using image accessors rather than arrays would be a win either - it's a bit fiddly to fit it in with this code. It might be though, since I think you get format conversion 'for free' rather than requiring a bunch of shifts and fart arsing about.
On thin and fat clients
Like chicks (and blokes too for that matter) it seems even the thin ones are now fat.
Moving all your apps to a browser is all well and good, but they seem to be getting bigger and slower - and no matter how 'nice' they might be in relation to other 'web apps', they just don't stack up against 'thick clients'.
Case in point: google mail.
It actually makes a pretty shitty mail client, and it only gets worse once you're on a few mailing lists with multiple conversations going on. It's quite difficult - and rather slow - navigating conversations and everything needs a click-and-wait. Not to mention the single 'modal' message editor. And is it just me or has it become a lot slower lately? Maybe it's because i'm using a different machine with higher resolution, but it's taking about a second to do things like delete one message. It took 3 seconds to open the inbox after I was looking at 'all messages'. I've only got 7K messages in total, hardly enough to blink at.
I used to be able to easily read a few hundred mails a day with evolution, and there's no way I could get even close to that using gmail; and still get anything else done. So one tends to skim the subjects a lot more rather than scanning the message - and you can often miss important things doing this.
So now I have firefox using more memory than evolution did, handling a tiny fraction of the mail in a less usable manner, more slowly, and using more cpu time, much more network bandwidth, and more power. That's progress?
Scribd
I noticed that 'scribd' has moved from it's awful flash app (which meant I never bothered to follow scribd links) to an awful HTML app (which means I will continue not to follow scribd links). Try overriding your fonts and loading a page - weird things happen that make it completely unreadable. Absolute winner for something designed to share documents, wouldn't you think?
Well that's if it'll even let you read anything - I get the following on one of my computers when I go to the front page (or click on the big link it gives me on this page).
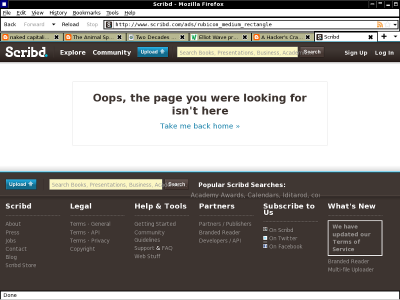
Even if it worked it is such a horrid thing anyway - I have a perfectly serviceable (if a little flawed) PDF viewer on my computer, why not just give me a link to a PDF? If you want to share documents, just put a PDF somewhere people can see it, you don't need these horrid online viewers.
Or just use plain HTML without all those shitful scrolling boxes and other useless clingons which make it harder to use.
facebook
Hmm, i got suckered into using facebook again - since none of my 'friends' ever mail me any more there doesn't seem to be any other way to stay in touch or talk to them. Which sucks. The shallowness and emptiness of it all rubs me up the wrong way, like Twatter(tm) every utterance needs to be made in tiny truncated sentence form. Also I'm not really sure I want to know what teenage nieces and nephews are up to in the sort of detail they tend to put online. And I find it deeply disturbing that visiting totally unrelated websites now have dynamic 'facebook social' crap coming up if you were ever logged into facebook with 'keep me logged in'. It doesn't seem to be something you can 'log out' of.
And although I know google tracks everything you do to the same extent, knowing that, and being shown blatantly that a visit to a news story is being linked back to your account - is another matter entirely.
The Wall
Current state of my back yard.

The wall will only be 4 high, the other bricks are there to get them out of the way.

I've finally just about levelled off the main area which will be planted with buffalo grass - the grass partially visible grew in under a season from a few cuttings so it wont take long. The sand left-over from under the long-removed pool will top-dress the grass.

Looking down the yard, on the left is a large garden bed - which will be herbs and vegetables. It gets full sun in winter and most of the day in summer.

Behind that - under the Golden Rain Tree is to be paving, made from the old bricks stacked up next to the house. Unless they end up being too ugly.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!