About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Processing Graphs
So, I've been looking into how to re-do the processing graph stuff in my customer's application over the last few days. First reason is I need to change the way it works, from a real-time interface to an interactive/batched one. And the second reason is that thinking about how Aparapi works (or could work with added concurrency) got me thinking that I really could do a better job at simplifying the whole lot, whilst making it more useful.
Currently I have a processing tree, and use threads and multiple queues to feed the data around so the main feeding thread isn't blocked on long-running tasks. There are basically 3 levels of abstraction: the top-level tree which consists of processing nodes which are invoked in the correct order: these might call kernels directly or higher level components. The middle level is only there sometimes, and includes more complex routines which consist of several opencl kernels combined in various ways with it's work data (e.g. something like KLT). And the lowest level is the direct kernel bindings (which usually do not manage their own data) very much the same as the ones in socles. The tree only defines the invocation order; data relationships are statically created/assigned at tree creation time or dynamically synchronised at run-time.
This works ok, but it is pretty messy and none of the top level is re-usable in the least (and there's little middle-level to re-use). It is actually fairly efficient - 'real time' means for some tasks I have plenty of spare time to waste and give up to to background jobs, so small bits of cpu-synchronous code aren't a deal-breaker. Obviously I want to simplify the usage of this, whilst increasing the possibilities for automatic job-level-parallelism.
My first re-cut of this was to take much the same idea, but make a couple of alterations. Firstly to re-arrange the abstraction levels, so that the top-level doesn't do so much direct kernel invocation but move this code to more second-tier components which are hopefully more re-usable. Either way this should be a big plus. And secondly to simplify the data management; use the tree to define data flow, automatic data conversion between stages, plus a bit of double buffering to cope with cpu synchronisation and some cpu parallelism (at least, one-way cpu-to-gpu). But otherwise basically just a synchronous fixed call-tree managed by a single queue.
But I don't think this is going to cut it either. It's not really flexible enough and unless I have lots of batch processes running concurrently (which i wont) the device will be underutilised in many cases.
Last night I started working on a socles version of something similar but quickly got bogged down in the data-conversion issues which get messy pretty fast (I want to be able to mix and match image, array, and java native graph nodes without each having to worry about where the data is coming from). And that was before I got onto the synchronisation stuff.
Yesterday was just a crap day anyway: very little sleep, grumpy as hell, and not able to think straight, so it was flying blind a bit by just not being on the ball ...
Then I realised this morning (i'm sure now that i knew this, and this is one reason I didn't want to do a call-graph interface in the first place; i'd just forgotten about it); opencl already has all of the stuff required to manage the processing graph (and it can handle a graph, not just a tree) (or I would've realised earlier if my searches hadn't have kept pointing to the 1.0 spec). The graph invoker just has to call the processing nodes in the right order, and it can build and maintain the event nodes used to link them all together. User events can be used to synchronise with (asynchronous/mt) java-side processing so I don't need to stop that branch entirely just to do some cpu code. All the processing nodes need to do in addition to their work is use the standard opencl condition/event set to ensure synchronisation. I can possible even manage queue stuff automatically. The data conversion stuff will still be a pain - but it's just a pain anyway and just can't be avoided.
Representing the graph in a simple way and turning that into an invocation sequence with events is another issue, but at least it gives me something new (to me) and useful to learn about.
Aparapi
So, I kept watching some more of the AMD fusion summit videos yesterday evening - and now I remember one reason I haven't watched them before: they take a long time to get through!
The GCN one was interesting (from 'Mike and Mike'), although the first Mike was a bit nervous and together with his Texan accent and rushing a bit, made him a bit hard to follow.
But the Aparapi one gave me some new respect for the project.
Although one thing I didn't think was correct was he kept going on about how Java programmers are completely braindead and don't know how to code for performance or deal with other issues (it's not like they're Python coders FFS):
- Pointers?
- Java coders have never seen a pointer eh? Object references behave the same because they are the same, and although you can't increment/index them, most coders stick to direct pointer dereferencing and array indexing anyway: i.e. exactly the same way they're used in Java. And they both have null pointer dereferences, it's just that Java's are non-fatal. So one could say Java programmers have never seen a fatal pointer access, but just because they're called object references or arrays, doesn't mean they're not pointers ...
- Other languages?
- Java programmers seem to love XML for some reason: they can cope with other languages. Look at ant: it's an XML form of bourne-shell! Not to mention Scala and so on.
- Performance
- Actually any of them already using Java for engineering/science know how to get performance: use objects of (single-dimensional) arrays, not arrays of objects. Write really ugly maths to cope with it. There's just no other practical choice without taking unacceptable performance hits.
And this goes for more fundamental understanding of the underlying architecture too. I know everyone likes to make out that abstraction means you don't have to know about registers and cache and how language constructs are executed by the hardware (and I know some schools of computer science try to hide such details), but that's bunkum. It affects every language because at the end of the day they're all executed as machine instructions.
- Threading, barriers, etc.
- Again for performance you can't avoid these. Java barriers are also the same semantically as OpenCL barriers and are a very simple concept if you're able to cope with the concept of concurrency at all.
- Dynamic memory
- Absolutely agree here, this is one thing Aparapi should hide.
So if a coder can't cope with these concepts already they are not going to be a potential user of Aparapi, so it seems strange to only target them as a potential adopter of the technology.
As with these concepts in Java, these 'braindead' coders will just use third party libraries and (ugh) frameworks to do this fiddly stuff for them, because even the simplest concurrency model that Aparapi presents (which is more like an OpenGL shader than a CL kernel) will be beyond them.
It's the actual concurrency which is the hard part: and for the most part OpenCL's concepts make the concurrency easier to deal with (or even, possible to deal with). So hiding the tools to deal with the concurrency whilst exposing the concurrency does seem a little counter-productive.
So I don't think hiding all the details of OpenCL is necessarily a good idea: sometimes one does need to know about data flow, local memory, 3-d workgroups, and barriers. 'system' and 'framework' programmers already need to know about threads and concurrency and so these related concepts will not be foreign to them. Although I noticed that Aparapi now has support for local memory blocks and so there's hope yet.
I'm not sure why Aparapi uses such an explicit memory transfer model either, when it could have managed the buffer memory in a simpler way. e.g. Java has accessors, why not use them to determine when buffer memory needs to be returned to the host? The data flow should be quite explicit from the kernel invocation order: no need to analyse the host code for this (and this is problematic: I don't see how the host code can invoke multiple kernels in a sequence from the example, since each kernel has its own single 'host' method - imho 'host' should be an attribute on any method rather than a single one, but maybe the api has moved on since then).
However, taking into account the future plans of the AMD/ARM platforms ... Aparapi has the potential to be much much more useful as the programming model could map quite well to the future target design. i.e. once one has zero-copy unified memory and a low-overhead job queue mechanism the cost of an Aparapi kernel call will become very low.
Although reviewing the plans, I suspect they're being a bit optimistic: i only recently discovered for example that async memory copies between CPU and GPU is only an 'preview' feature in the current sdk ... which was quite a 'WTF' moment - how seriously IBM-PC-XT is that ... OTOH moving the ringbuffer processing to the hardware removes most of the OS-specific code required to talk to the hardware and so will reduce the resource requirements for driver development (i.e. we wont have to wait for the driver devs, it'll already be done by the hardware guys).
I think the biggest problem for Java however is in the language itself, and in particular it's lack of mathematical expressivity[sic]. It doesn't support vector types for starters - which are handy in this case more for their ability to concisely realise mathematical expressions than the ability to map efficiently to SIMD processors. And even if one does wrap these in objects, using them is clumsy, error prone, and even messier if you're aiming for efficiency. e.g. it's simply cleaner writing C or OpenCL C code to perform most maths than it is doing the same in Java (in it's most purest object form, let alone optimised for practicality).
So although a lot of problems will probably map fine enough, occasionally one will be better off with lower-level access. If one could override the kernel code with your own string, but let Aparai handle the buffer management and let them all interoperate it would be very cool. Even if for example, it compiled the OpenCL code in to Java bytecode as the fallback (ok, this is a rather much bigger problem to solve ...).
OpenCL
So i've been wondering just what opencl can be 'used for'. Apart from making an image editor or video tool run faster, I can't really think of what it might enable. As important as those tools are - and OpenCL does make some features possible now which were not before - the are very niche products of little direct benefit to most of us (unless all you do all day is sit on your arse consuming hollywood movies and glossy magazines, which is probably - utterly sadly - a majority or at least major minority).
Unfortunately when searching for 'opencl kill app' the first hit is my own post of the same title ... ahh well.
Anyway, along the way I found this this blog which has some interesting observations and ideas about OpenCL hacking.For one I had missed that opencl 1.1 added a shuffle instruction: which is pretty much required for good performance for 'data streaming' applications: using SIMD to access non-aligned data. It can also be used to implement a vector index lookup. However, I'm not sure if this is a single-instruction function on GPU hardware, and it was just added to the spec for the CELL BE backend (without shuffle, the SPU's are kneecapped). Although it isn't too hard to find out by dumping the source code - which I did, and found that it isn't efficient at all. Oh well.
So back to the question of OpenCL applications: as from the last time I wrote about, enabling desktop performance on a hand-held computer is probably still the main thing we will all eventually see (although it's taking it's sweet time). This latest iteration of the thin client/server model (which harkens back to the original mainframe idea) wont necessarily last, as no previous iteration ever did. And although having an internet connectedness will be pervasive, you wont need to go to a back-end server to do the work when you have 100G/flops in your pocket.
The other thing, which I think is more interesting, is that OpenCL will enable cheaper design of complex systems - which means more competition and more products for the general public. So for example it has always been that even from the days of 8 bit computers you could design a hardware component to increase performance (sprite hardware, sound synth, etc), and this still allows advanced performance from portable or low-power devices. As OpenCL technology matures and die sizes continue to shrink, it will become feasible to replace the expensive custom silicon with more and more software, and so as we went from custom silicon to fpgas, we may well move toward more software-only solutions even in portable devices. OpenCL might be a prick to code in, but it's a lot easier than FPGAs are, and you can still get higher performance from purpose-built functional units (FPGA's big edge is in power requirements, and concurrency).
So I think OpenCL's killer application is not so much a consumer-facing one as a tool for system developers. Or at least, removing the need for system design input for a given application-specific device, and opening up similar facilities to all developers. This is pretty much the gist of one of the AMD talks from a couple of years ago (I think from the AMD developer summit, perhaps from 2010 as I can't see it in the 2011 talks - many of which look interesting enough to watch) about how they were able to produce results in less time and with fewer steps than going the hardware route. i.e. lower costs, higher payoffs, and so on. I.e. pretty much what FPGAs did for system design, OpenCL may do as well: it might not be as fast, but the reduced development costs and overheads for low-volume production, Moore's Law and so on more than make up for it.
As an aside, when I was playing around with the beagleboard I also looked up some arduino stuff from time to time. I thought it was amusing that so many 'old hands' would whine about how overpriced the arduino was and that you could get away with something simpler like a PIC and so on. It was amusing because we can all see where this is going with a computer such as the Raspberry PI coming out: these things are getting so cheap and ubuquitous, before too long those 'low cost' simple parts will only be made by niche manufacturers to service dying equipment: i.e. they will become too expensive for anything (not to mention the skills required). Before too long it wont be economically viable to use anything smaller than a 32-bit floating point cpu for anything requiring some calculations.
It's a pity that the whole patent issue is getting so ridiculously out of hand: now that we are on the verge of effectively commoditising the entire platform as it pertains to signal processing, we're all going to be thrown into a dark age of propping up the leeches and rentiers who seem to have captured governments the world over for their own benefit.
Update: So ... I did end up spending a couple of hours today watching some of the AMD fusion summit videos from 2011 (with a bit of a hangover i wasn't up for much more than this!). Quite interesting, I guess I should keep an eye out on this stuff a bit more, but when i'm busy with work or on leave I don't always keep up with it.
The first keynote was quite interesting (after the waffle from the first guy), the future direction of the 'HSA' (heterogeneous system architecture) platform. At one point there is a graphic showing a bunch of hardware driven queues where applications feed in job tasks directly from their process space and they are picked up and executed by the hardware directly ... without a cpu context switch or kernel-mode memory copy in sight.
Now THAT is interesting.
Although ... TBH what the diagramme most reminded me of was ... non-copying asynchronous message passing, and where have I seen that before? Oh ... AmigaDOS 1!? Well, it only took nearly 30 years to finally catch up ... sure there are differences in the capability, but given the technology of the time it's definitely the closest to the model proposed here. i.e. unified memory (CHIP ram!), separate processors working together, non-copying data flows, etc. It's more than just about the non-copying of data (although that is pretty important too), it's about keeping the ALUs fed with data, and avoiding the overheads of system interactions and exception/syscall processing (this is of course why AmigaOS worked in a similar way). Already with GPUs keeping them fed with data is basically impossible - they spend a lot of time waiting around twiddling their thumbs.
Still, it's funny how nice hardware design is when intel aren't involved ...
Speaking of not-intel, the talk from the ARM guy also was quite interesting. From their perspective the push for non-heterogeneous compute is not just about getting the job done faster, it's about getting it faster whilst using less power. With the process shrink there isn't enough power/heat sink to run all the transistors at once, so you have to divvy up the work in a way which gets it done the fastest without wasting the silicon, the power, and so on. And on a mobile device it's about trying to utilise all the extra gates are your disposal to keep pushing the edge of performance; whilst still keeping within heat and power budget. This obviously fits directly in with AMD's software stuff: how to actually programme such a chip in a practical way.
Although to me what is most interesting about this approach is that it acknowledges that there really is a hard physical limit on the amount of work a single silicon chip can do. And even though they're making them smaller and can fit more transistors they can't turn the new ones on at the same time. I had seen this in the OMAP processors but I thought that was just about power saving: not burning out the chips. Thus the only way to improve performance and utilise the extra silicon further is not by increasing the concurrency but by increasing the specialisation of the functional units, and having more of them. This is quite a fundamental change to hardware design: where normally one tries to maximise resource utilisation. (and yes, it contradicts my speculation above to some extent: but I wrote that before seeing the talk)
And it has pretty far reaching implications for software development too. And particularly for free software; if the specific functional units aren't available to everyone or use proprietary instruction sets or firmware.
I'm not sure i'm convinced of the whole cache coherency model though: I thought the CELL BE was a better idea for high performance since each CPU had it's own dedicated simple memory that runs fast (=== LDS), and knowing you have no cache coherency just means you code differently (and avoid a few pitfalls along the way). The main benefit you get is much higher effective bandwidth: if it has to go through a global cache you're still hitting a bottleneck. Still, it's all about the system performance not just the fpu, and also being able to practically achieve a good fraction of its theoretical peak in a reasonable time with a decent programmer: and these are system issues beyond the raw numbers and queue mathematics.
Well off to the GCN video: although from the last AMD roadmap there is a NEW GPU architecture headed our way by the end of the year, so I'm not so sure what's going on with GCN.
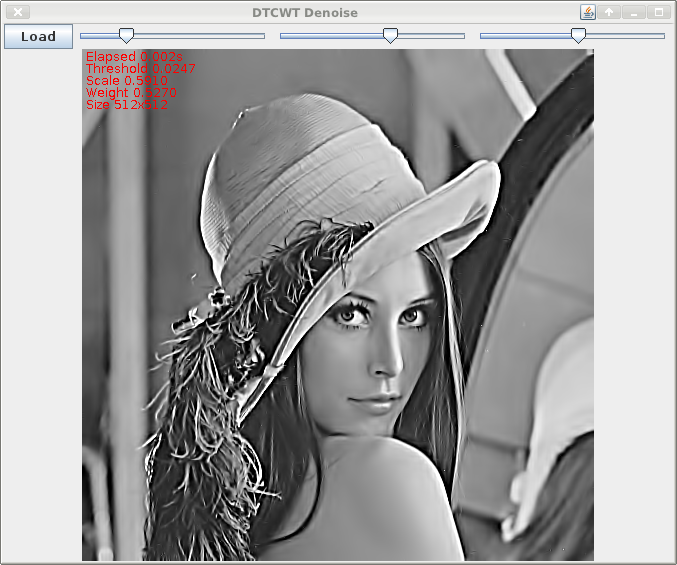
socles denoise/sharpen
This morning I ported the ImageZ denoise & sharpen stuff to soclesdemo now that I have the QWT code (mostly?) working.
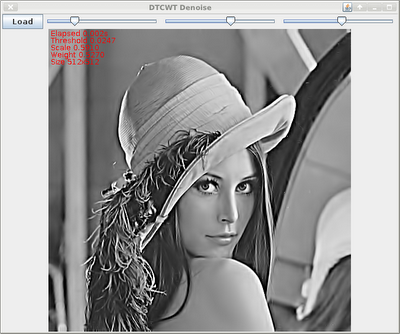
I still get occasional GPU hangs, but it is completely random: maybe it's code bugs, maybe it's driver bugs ...
It scales fairly well: I tried a 4288x2848 pic, and it was still interactively-quick (swing stuffed up visually since it isn't in a scroll-pane, so I couldn't see how long it was taking), and much of that time was to/fro java/swing/X. For a 1546x1178 image it was about 8ms for a the full wavelet processing (kernel times). It's only greyscale. This 1-2 orders of magnitude faster than a contemporary high-end cpu, so is well worth it: and it makes real-time 1080P processing possible.
But for an interactive application however you would only need to perform the forward transform once and just apply the thresholding and inverse with each change. So in that case it could be quite a bit faster.
Source
QWT
Since I haven't done any work in OpenCL for a while I thought on my hacking-day today I'd poke around socles for something different.I managed to mostly get the quaternion wavelet transform code I started pre-xmas working, at least for the forward transform. It is based on the code I have in ImageZ, which i've mentioned before. This can then be used to form a dual-tree complex-wavelet-transform 'on the fly' as I do in ImageZ, or by copying to another structure (these both have some fairly interesting properties, so far i've only done work with denoise/sharpen, but there are also other applications such as registration).It was actually a bit of a ramp-up to remember where the code was at. And then to decipher what it was supposed to do. For what consists a fairly simple algorithm (dual-convolution - the difficulty in wavelets is the filter design) there is a lot of very fiddly addressing and mucking about. Implementing upfirdn which is essentially what it uses is a pain even with such simple ratios as 1:2 and 2:1.
Although I seem to be getting an ok result, sometimes when I execute it on my GPU I end up having to hit the reset button ... so it's stuck on the CPU for now. Probably just some bounds checking errors. I'm not really on the ball today, pretty tired and grumpy, and I spent the better part of the day working on it so far; bit shit considering I already had a working Java implementation and most of the OpenCL scaffolding done. I guess not every day can be a super-productive one.
As above, i've only worked on the forward transform so far. Most of the tricky stuff is in the DWTGenerator which started as a copy of the convolution generator class, although QWT.forward() is a lot hairier than it looks too. I also managed to improve on the ImageZ code a tad: the redundant copies and vertical transforms aren't needed as I in-lined the sub-routines and have simpler data management.Update: Well I just kept poking at it, and eventually ended up with getting the inverse transform working: sometimes it just takes perseverance. Unfortunately the forward transform still crashes my GPU quite regularly and I haven't traced that down yet.
Between the resets I did manage to get a couple of runs through sprofile: it's about 350uS per transform for a 512x512 depth=1 transform, on a Radeon HD 6950. There are some LDS bank conflicts in the X convolutions, although the main bottleneck is the Y convolution since it cannot benefit from LDS and relies on coalesced reads and the global cache. I'm reasonably happy with that, and i'm not sure I can get much more out of it.
jjmpeg updates
I finally checked in some jjmpeg changes I had lying around, added seeking to JJMediaReader and an icon creation helper (hmmm, maybe that was api bloat ...) and a few other odds and sods.
I've been playing with some interactive video stuff for work and when the video file is in good condition (i.e. seeking works properly) it's quite amazing to me just how zippy it all is - coming from the days of the C=64 I still can't get over just how fast modern machines are. And Java of course makes the multi-threading required to make the GUI very responsive an absolute doddle.
Absorbing rapid events
One idea I borrowed from my experiments on ReaderZ was a fairly simple mechanism to collapse rapidly incoming events. e.g. for a slider bar calibrated in ms, one can get many many updates as the slider moves; more than can be accommodated whilst panning an e-ink display or seeking around HD video. In the past i've either used a timeout, or some other throttling mechanism on the caller end such as a 'i'm busy' flag. This usually needs some other logic to handle completion cases, perhaps cancelling of jobs and other quite complex synchronisation tasks to ensure valid programme state when it's all done and dusted.
In ReaderZ I tried a different approach in order to simplify serial processing:
- Incoming tasks are queued as they arrive into a blocking queue.
- A consumer thread waits until something arrives on the queue.
- The consumer thread then polls the queue for any other tasks waiting to be processed.
- Based on the class of the request, jobs are discarded explicitly. For example, if you have a seek followed by an open or another seek, the first seek can be thrown away. i.e. the command is either kept, changed, or nullified.
- Then at most, 1 job each of each class are executed in the correct order.
- Repeat, go back to 1.
So basically a simplified broken-apart state-machine with explicit state reduction. If a given job is indivisible/can't be ignored (say, 'save current image'), then the collapse processing is cut short, and it jumps to step 5.
This way there's no need for any locking (apart from the task queue): the code is always called from a single thread, with guaranteed execution order and with simple state management. And even when something does take a while to run; it eventually catches up and never does more than less than one lot of extra work. It does need to ferry ALL sequentially oriented tasks through the command queue, but usually one has a fairly limited number of operations required.
Because the same thread is used to decode and play the video for my video player, if it is in 'play' mode, this just polls the command queue after each frame is displayed rather than waiting for it to contain something; but the overall logic is the same.
Also because it's done in one place I can more easily add a timeout if I really want to make sure the system is idle: rather than a separate timeout callback which needs resetting and gets called once things are done, I can just add a timeout to the Queue.poll() invocation. Or just as easily not, for example if it's been faffing around collapsing too many commands and hasn't updated the output for a while.
Speaking of ReaderZ, although I don't have any other plans for it at the moment, I am waiting for the next version of mupdf to be released at which point I will update PDFZ to match that. It should be quite soon.
Although I wasn't going to look into JavaFX too closely, every time I hit a problem in Swing I keep thinking the solution is a dead-end and the time spent on it is wasted. Unfortunately the one thing I need the GUI toolkit to to: i.e. display an array of pixels generated elsewhere: is one of the major things it cannot do yet! It can only read images from a url/disk, and that feature is targeted for 3.0 - about 18 months away. I suppose i'll just have to wait ...
Damn I wish I wasn't so tired. Must be the weather ... Autumn started very suddenly on the 29th.
It's scary joining a free software project?
I started writing a comment on this this post about contributing to free software: and it got so long I thought I'd move it here.
Overall I agree: it is quite scary, but the comment I was writing follows, somewhat expanded.
For the types of people for whom meeting people is difficult, software projects cannot be any different because the same notions apply: you don't really know how someone will react to you and whether you will be accepted or respected. I've been writing free software for about 15 years, and before that I gave away 'freeware' as well, and i'm probably more anxious about contributing to a new project than i've ever been ...
It is also unfortunate you use the term 'open source', because clearly merely having access to the source code makes no representation on whether a project is even interested in contributions. There are many reasons people write software and publish it freely, and for many projects, success or popularity is simply not a concern: the developers don't really care what anyone thinks because they have something they use themselves and the sharing is already an end in itself.
However ignoring the specific terminology used, trying to brush a wide audience with their sole unique characteristic is generally a pointless exercise. e.g. that all Greens voters are smelly hippy vegetarians, conservatives are all gun tot'n 4WD drivers, etc. People with only a few things in common are still very different from each other.
And just because the source is available and has a project page and a mailing list, it doesn't mean the project is interested in contributions from the general public. But clearly Layfield's experience is pretty poor - if a project purports to desire contributors and has a work wanted list, then at the bare minimum civility and politeness should be present. If such a project intends to survive by using external contributions, then it wont live too long.
Some of my experiences:
a) 'my first elisp' code, which turned into a handy script to add java-doc like comments to C functions. I submitted this to emacs, but RMS wanted it integrated into CC mode and a bunch of other stuff which was well beyond the time I wanted to spend on it or the features I needed (and I wasn't particularly interested in the kudos of contributing to a high-profile project). So I just added it to the project repository and my .emacs and left it at that.
(needless to say, I never wrote any elisp subsequently, but that's because I just wasn't interested in lisp as a language and that was the sum-total of the lisp I ever wrote).
b) AROS - these guys were very easy, commit access was easy to get, and then it was pretty much commit what you liked - obviously avoiding stepping on any toes. Even for a project with a lot of politics, there were plenty of small holes to fill.
c) I submitted a patch to mplayer, which was accepted without too much fuss. Just a bit of formatting changes iirc. In hindsight this was smoother than i'd have thought: certainly at the time they gave an abrasive impression of themselves on their web-site.
d) I think the first free software i contributed to was a patch to amanda circa 1995 - amanda is a distributed backup system. It was a horrible patch in hindsight but they accepted it easily. Of course this was back in the day when the internet was only accessible to academics, students, engineers, and sysops and overall was a much nicer place (yes, despite the flame-wars).
e) Working on Evolution. This was a commercial product with a (reasonably) defined direction and design. It was also complex enough and with enough of a user-base that any changes needed a lot of checking to make sure they were going to work technically and be up to scratch in terms of quality. Although the whole team spent quite a bit of effort trying to increase the community involvement: In the end I didn't really like being offered all but the most trivial of patches because it was always much faster just to write the code myself. Or I felt like a real heel telling some young lad that we couldn't use his patch because it didn't fit with the PM driven agenda. The one time we did accept a sizeable patch (and I was on holidays so was overridden), I spent weeks replacing a poor implementation which caused a lot of problems with a decent one. Nobody ever became a long-term contributor so we were left to learn and maintain any patches they gave us as well. I thought the 'bounty' system was an unmitigated disaster and would never consider such an approach again. People who are desperate for the paltry money on offer are probably not the cream to start with, and it is also very unlikely to lead to long term unpaid commitment.
Developers ...
Developer scalability was a huge issue in evolution: with thousands of reported bugs/feature requests and 2-3 coders there's just nowhere to even start making a dent. People wanted stuff we could never deliver (either too costly, unfit for the application, etc), and some people were nasty and insistent arseholes who wouldn't take no for an answer, or wouldn't take any time to try a patch or other work-around suggestions (which obviously took non-trivial effort to suggest). Crash reports were rarely followed up, and without being able to re-create them were basically useless. Not to mention distributions (esp debian) re-packaging the code in ways we only had to guess, and maintaining their own separate patch-sets. Placing bugs into 'wishlist' limbo was just as bad as saying 'wontfix', since they were never going to happen.
This latter point about scalability can't be ignored even for projects which do actively seek contributors. Every contributor comes along with a clean slate and thinks they're the first to be in their position. Yet for developers they might be one of hundreds, and even after giving out the same information only 10 times one gets pretty sick of it. This is actually one reason I find it more difficult to contribute to projects now: I don't want to piss someone off because I couldn't find their FAQ or didn't search the email archives enough, or they're still anal about 'top posting' (I really can't believe anyone still gives a rats-arse about that anymore ...).
Submitters ...
The 'problem' isn't just with the developers either: for example, what is the motivation behind the people submitting the patch? Why should a developer be particularly interested in a patch from someone who is just after the experience of submitting a patch? Or hoping for the fame of having a bit of their code included in a popular application?
I would certainly be much more interested in a patch from an active user who has found a deficiency in their day-to-day active use of the project versus someone who is just looking for something to do or something to add to their CV.
And if you're not a direct or close peer to the developer: the relationship is in quite a different space and now the developer has become a mentor. It takes far more effort and resources to be a mentor and in the vast majority of cases that effort is never returned to the project. The goal of most projects is to provide a solution to a problem, not to train people how to code or interact with a public project. It's quite arrogant and rude to assume that just because it's code and mailing list is available to the public that it gives the public a free reign on developer time ...
Me ...
Now, i'm definitely not interested in authoring applications for the general public. I get paid to work on a research project with a single individual as the sole customer I deal with. And for my free software projects the only ones of worth are only useful for other developers. And even then most of those are just stuff i'm playing with for my own entertainment; it is therefore costing me nothing to share it with the world and i'm more interested in helping people learn than solving their problems (that's not to say I don't get a buzz out of knowing my stuff is used - I check the stats all the time - but it isn't the motivation at all).
I don't think it will happen any time soon (not the least reason being that I'm miles away from building anything useful to the average user): but having a project of mine picked up by a distribution would be quite unappealing.
As for patches, I still submit the odd small patch here and there. But what turns me off is:
- Anal retentiveness about specific code style, mailing list etiquette and so on.
- I used to do this way way too much in evolution: If the patch was basically ok I should've just taken it and fixed it up to match my preferences and fixed minor errors. Once one has submitter access things are different, but for a random patch it's just not worth the to-fro and agro. Previous to ximian I'd had a pretty unpleasant experience working with an Indian sub-contractor (TATA Infotech) and we were being anal about their (really bad) code because we were paying a lot for it for no reason - so I was a bit thingy with code reviews.
Worrying about 'top posting'? How 90s, get-the-fuck over it.
- Using git (or some obscure cms)
- I just hate git to start with. And being asked to create a public fork of a project for a one-off small patch is low on my list of `things to do before i die'.
The first patch I ever created I used 'diff -ruN' to create, and that's still a reliable way to do it without having to learn obscure commands for half a dozen popular systems.
- Too many pre-requisites.
- e.g. joining a mailing list and a bug tracker in which you must create a bug and attach the patch, copyright assignments, and so on. It's ok for a couple of projects or if you become an active long-term participant, but it quickly gets far too unwieldy if you're just submitting a rare patch to some product you use occasionally. Another thing we (totally!) fucked up in evolution.
Obviously for a team project a mailing list (or forum) is pretty much essential, and legalities might require a copyright assignment or other agreement, but the bug systems tend to give me the willies.
- Build complexity.
- Some projects are just too complex to build or require too many pre-requisites: rubbish like ant, cmake, and all the other weird arsed build systems (jam, bitbake, custom python, rake ...) become insurmountable barriers that stop you even getting started.
I was quite astonished the other day that I even got a cmake based project to compile at all. If it wasn't for netbeans I wouldn't be using ant, and even then it sometimes fucks it up.
- Python.
- Which reminds me ... it's just a personal thing but I detest python in any form. tcl isn't far behind.
- Arrogance.
- Using a project leader's celebrity or the project's popularity to make one feel like it is an absolute privilege to be doing some of their work for free. I don't really encounter this because I'm just not attracted to such projects, but there needs to be some sort of recognition that work is being done for free (assuming it's at an adequate level for the complexity of the patch).
Concluding ...
To respond to the final question of what can be done to improve first impressions, I think i'd just say 'not much'.
Unless your specific goal is to maximise user contributions and popularity amongst potential contributors you're probably not too concerned about what they think. And if you are, you're probably already doing all you need to do.
And importantly beyond some fairly basic civility, there should be absolutely no obligation on you, as a free software developer, to provide any sort of expected level of support or accept patches in any form from anyone whatsoever.
If one wishes to be popular and extra-friendly then all the better for you and your users, but it is certainly no pre-requisite to calling your software free (or the related but somewhat meaningless term 'open source').
socles updated for jogamp 2
Just to show that it's not all angry rants around here ...
Continuing my mirror of the news items on my projects, I just updated socles to include jogamp 2.0 - fortunately the API was the same so it was just changing the included libraries in the build.
I still have a JOAL patch outstanding but just haven't been in the right mood to work on it for a while. Getting back to work last week was a bit of a shock to the system; but i'm slowly getting back into the groove and will eventually have time and energy left over for hacking.
I've been doing a bit of video stuff which is helping to harden and clean up jjmpeg a bit more, and I have a few minor patches pending for that. I've also been poking very tenatively at a slideshow creator/video compositor: but there's a lot of crap I don't really want to have to write (ugh, timeline anyone) so i'm not exactly making any headway yet.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!