About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Filter Graph
This morning I threw together an implementation of some of the ideas I mentioned in the last few posts for a filter/processing graph and checked them into socles.
I had a pretty good result applying the same ideas to my work stuff and I want to eventually use them elsewhere and experiment as well. The main thing I'm trying to resolve is the memory management and scheduling issues. Well I guess the other thing which is also pretty `main' is that by having a component framework it is easier to encapsulate functionality into re-usable connectible parts: i.e. less code, more functionality.
At the moment I have a dummy graph executor (it executes jobs in the right order, but not with any event management), and I still need to play with the queuing. But simple examples work because it's always using the same queue, and the climage-to-java-image conversion is necessarily synchronous. If I get it all working right, separating the graph execution from the nodes will allow me to try out different ideas - e.g. multiple queues, even multiple devices(?) without having to change the underlying code.
Actually one of the biggest hassles was attempting to support Java2D images as much as possible. I've tried to ensure images never lose any bits, although they may need format conversion (e.g. there are no 3-channelx8 bit image formats). I haven't tested all the formats as yet so quite likely the channel orderings are broken for the colour images (it's usually easier to just run it and tweak it till it works rather than try to grok all the endian-ness issues and ordering nomenclature of every library involved). I've got a feeling it was a bit of overkill - Greyscale/RGBA, UNORM_INT8/FLOAT are probably the only formats one really needs to handle at this level. Given that there are efficiency issues, it may be that I throw some of the code away so they can be addressed with less work.
Anyway, a simple example shows that even at this stage it can be used to create useful code: SimpleFilter.java. (at this stage it's not doing resource management, but most of the skeleton is there to handle it).
Eventually I want to be able to do similar things with video sequences (via jjmpeg).
(To what end? Who knows?)
Processing Graphs 3
So based on the stuff in my previous post I decided to ditch the stuff I had already done for work and start with the stuff I worked on in socles on my hack-day as a baseline.
I had to fill out the event management stuff, and then I had to port the few processing nodes I had already ported to my other half-arsed attempt - which apart from a couple of cases was fairly straightforward. I kept the getInputX/getOutputX stuff, implemented some image converters, and wrote a video frame source node (which turned out a bit more involved than I wanted).
Some of the code is a bit messier, and now i've implemented the event stuff I had to go back and fill that out: which was a bit tedious. The 'source' interfaces are a bit of extra mess too but aren't any worse than implementing bound properties and in some cases I can sub-class the implementation.
The graph executor is nice and simple, it visits all nodes and runs every one once in the right order based on the graph. Each execution produces a CLEvent, and takes a CLEventList of the all events from pre-requisite incoming nodes. Each node takes a queue, a CLEventList of conditions, and a CLEventList to which to add it's (one-and-always-one) event output. It wont handle all cases but it will do what I need.
Because input/outputs use simple component-ised syntax, I can auto-connect some of the sources as well using some simple reflective code: this is only run once per graph so isn't expensive.
Possibly I want to allow individual 'source' instances to be able to feed off their own valid-data events too: although I think that's just adding too much complication. If nodes produce partial results the nodes themselves can always be split.
So after all of that (it's been a long day for unrelated reasons), I think it's an improvement ... at least the individual nodes are more re-usable, although some of the glue code to make the stuff I have work is a bit shit. I still have a bunch of cpu-synchronous code because I can't tie in user events with the api I have (I need to update my jocl for that), but with the api i've chosen I should be able to retro-fit that, or other possible design changes later on (e.g. multiple devices? multiple queues?) without needing to change the node code.
Actually I wish I had had more time to play with it in socles before I went with it, because there are always things you don't notice until you try it out. And things are a lot simpler and easier to test in the 'WebcamFX' demo than in a large application. This is also just a side-issue which is keeping me from the main game, so I want to get clear of it ASAP, whereas in socles it's just another idea to play with.
Processing Graphs 2
So, I looked into implementing the graph idea on Friday.
I came up with a really simple bit of code that runs everything in the right order, and a few 'nodes' which wrap some of the stuff in socles in re-usable components. I'm working on a simple component architecture that could let a GUI for example auto-query some of the node capabilities and data i/o ports.
I changed my idea on the data format stuff, and now the components explicitly import and export a given type: so either the application can know what is needed to interface disparate functions, or potentially graph code could just add it in as needed.
For example, something that might take two images and blend them together might have:
ImageSouce getOutputImage();
void setInputA(ImageSource);
void setInputB(ImageSource);
void setInputFactor(ValueSource);
The *Source types are interfaces which let you retrieve the actual data or value (and perhaps meta-data thereof). Reflection can be used based on the names (setInput/setOutput) and/or the argument/returns (instanceof Source) in order to auto-create GUI or auto-connect parts.
Although I didn't quite get that far I pretty much worked out the event generation stuff too: each node takes a CLEventList condition, and CLEventList events (these are the way all CL calls are synchronised) and honours/updates them as if it were a single call. i.e. waits on the condition, and then sets a single event on events either via a enqueue call or using user events when it's done. And although the graph is invoked synchronously, this allows for asynchronous operation: i.e. any call that might block (e.g. read-modify-write from gpu) just shuffles it's work off to another thread/work queue and it can sync up later. Well that's the intention anyway. I'd like to be able to automate the parallelisation via queues across the graph paths as well, but I should get something working first.
I hit a bit of a hurdle with JOCL not allowing user events to be added to an event list: which means I couldn't get much further with some of the stuff I wanted to do (allow java code to participate in the OpenCL managed event graph). If JOCL wasn't such a pain to build and then propagate to the various projects I would've added the trivial patch to get it working, but by then it was pretty much the end of the productive day anyway so I left it at that.
As an aside: i'm not sure what possessed me to actually start work on this, but I have previously considered - and dismissed - hacking together another jni binding for opencl (there's little things every now and then that get me thinking about it, but usually my senses kick in before I start). Because there's a lot more involved than just the code it's really not an avenue I want to cycle down. But this morning - complete with hangover - ugh, which still seems to be lingering now at the other end of the day - I started with openal and then looking into opencl. I use gcc and cproto to simplify the stuff I need to parse, filtered further by a few greps in a shell script. Then another big ugly perl script to process these into bindings and classes. Anyway, that stuff probably wont go anywhere. Probably.
Processing Graphs
So, I've been looking into how to re-do the processing graph stuff in my customer's application over the last few days. First reason is I need to change the way it works, from a real-time interface to an interactive/batched one. And the second reason is that thinking about how Aparapi works (or could work with added concurrency) got me thinking that I really could do a better job at simplifying the whole lot, whilst making it more useful.
Currently I have a processing tree, and use threads and multiple queues to feed the data around so the main feeding thread isn't blocked on long-running tasks. There are basically 3 levels of abstraction: the top-level tree which consists of processing nodes which are invoked in the correct order: these might call kernels directly or higher level components. The middle level is only there sometimes, and includes more complex routines which consist of several opencl kernels combined in various ways with it's work data (e.g. something like KLT). And the lowest level is the direct kernel bindings (which usually do not manage their own data) very much the same as the ones in socles. The tree only defines the invocation order; data relationships are statically created/assigned at tree creation time or dynamically synchronised at run-time.
This works ok, but it is pretty messy and none of the top level is re-usable in the least (and there's little middle-level to re-use). It is actually fairly efficient - 'real time' means for some tasks I have plenty of spare time to waste and give up to to background jobs, so small bits of cpu-synchronous code aren't a deal-breaker. Obviously I want to simplify the usage of this, whilst increasing the possibilities for automatic job-level-parallelism.
My first re-cut of this was to take much the same idea, but make a couple of alterations. Firstly to re-arrange the abstraction levels, so that the top-level doesn't do so much direct kernel invocation but move this code to more second-tier components which are hopefully more re-usable. Either way this should be a big plus. And secondly to simplify the data management; use the tree to define data flow, automatic data conversion between stages, plus a bit of double buffering to cope with cpu synchronisation and some cpu parallelism (at least, one-way cpu-to-gpu). But otherwise basically just a synchronous fixed call-tree managed by a single queue.
But I don't think this is going to cut it either. It's not really flexible enough and unless I have lots of batch processes running concurrently (which i wont) the device will be underutilised in many cases.
Last night I started working on a socles version of something similar but quickly got bogged down in the data-conversion issues which get messy pretty fast (I want to be able to mix and match image, array, and java native graph nodes without each having to worry about where the data is coming from). And that was before I got onto the synchronisation stuff.
Yesterday was just a crap day anyway: very little sleep, grumpy as hell, and not able to think straight, so it was flying blind a bit by just not being on the ball ...
Then I realised this morning (i'm sure now that i knew this, and this is one reason I didn't want to do a call-graph interface in the first place; i'd just forgotten about it); opencl already has all of the stuff required to manage the processing graph (and it can handle a graph, not just a tree) (or I would've realised earlier if my searches hadn't have kept pointing to the 1.0 spec). The graph invoker just has to call the processing nodes in the right order, and it can build and maintain the event nodes used to link them all together. User events can be used to synchronise with (asynchronous/mt) java-side processing so I don't need to stop that branch entirely just to do some cpu code. All the processing nodes need to do in addition to their work is use the standard opencl condition/event set to ensure synchronisation. I can possible even manage queue stuff automatically. The data conversion stuff will still be a pain - but it's just a pain anyway and just can't be avoided.
Representing the graph in a simple way and turning that into an invocation sequence with events is another issue, but at least it gives me something new (to me) and useful to learn about.
Aparapi
So, I kept watching some more of the AMD fusion summit videos yesterday evening - and now I remember one reason I haven't watched them before: they take a long time to get through!
The GCN one was interesting (from 'Mike and Mike'), although the first Mike was a bit nervous and together with his Texan accent and rushing a bit, made him a bit hard to follow.
But the Aparapi one gave me some new respect for the project.
Although one thing I didn't think was correct was he kept going on about how Java programmers are completely braindead and don't know how to code for performance or deal with other issues (it's not like they're Python coders FFS):
- Pointers?
- Java coders have never seen a pointer eh? Object references behave the same because they are the same, and although you can't increment/index them, most coders stick to direct pointer dereferencing and array indexing anyway: i.e. exactly the same way they're used in Java. And they both have null pointer dereferences, it's just that Java's are non-fatal. So one could say Java programmers have never seen a fatal pointer access, but just because they're called object references or arrays, doesn't mean they're not pointers ...
- Other languages?
- Java programmers seem to love XML for some reason: they can cope with other languages. Look at ant: it's an XML form of bourne-shell! Not to mention Scala and so on.
- Performance
- Actually any of them already using Java for engineering/science know how to get performance: use objects of (single-dimensional) arrays, not arrays of objects. Write really ugly maths to cope with it. There's just no other practical choice without taking unacceptable performance hits.
And this goes for more fundamental understanding of the underlying architecture too. I know everyone likes to make out that abstraction means you don't have to know about registers and cache and how language constructs are executed by the hardware (and I know some schools of computer science try to hide such details), but that's bunkum. It affects every language because at the end of the day they're all executed as machine instructions.
- Threading, barriers, etc.
- Again for performance you can't avoid these. Java barriers are also the same semantically as OpenCL barriers and are a very simple concept if you're able to cope with the concept of concurrency at all.
- Dynamic memory
- Absolutely agree here, this is one thing Aparapi should hide.
So if a coder can't cope with these concepts already they are not going to be a potential user of Aparapi, so it seems strange to only target them as a potential adopter of the technology.
As with these concepts in Java, these 'braindead' coders will just use third party libraries and (ugh) frameworks to do this fiddly stuff for them, because even the simplest concurrency model that Aparapi presents (which is more like an OpenGL shader than a CL kernel) will be beyond them.
It's the actual concurrency which is the hard part: and for the most part OpenCL's concepts make the concurrency easier to deal with (or even, possible to deal with). So hiding the tools to deal with the concurrency whilst exposing the concurrency does seem a little counter-productive.
So I don't think hiding all the details of OpenCL is necessarily a good idea: sometimes one does need to know about data flow, local memory, 3-d workgroups, and barriers. 'system' and 'framework' programmers already need to know about threads and concurrency and so these related concepts will not be foreign to them. Although I noticed that Aparapi now has support for local memory blocks and so there's hope yet.
I'm not sure why Aparapi uses such an explicit memory transfer model either, when it could have managed the buffer memory in a simpler way. e.g. Java has accessors, why not use them to determine when buffer memory needs to be returned to the host? The data flow should be quite explicit from the kernel invocation order: no need to analyse the host code for this (and this is problematic: I don't see how the host code can invoke multiple kernels in a sequence from the example, since each kernel has its own single 'host' method - imho 'host' should be an attribute on any method rather than a single one, but maybe the api has moved on since then).
However, taking into account the future plans of the AMD/ARM platforms ... Aparapi has the potential to be much much more useful as the programming model could map quite well to the future target design. i.e. once one has zero-copy unified memory and a low-overhead job queue mechanism the cost of an Aparapi kernel call will become very low.
Although reviewing the plans, I suspect they're being a bit optimistic: i only recently discovered for example that async memory copies between CPU and GPU is only an 'preview' feature in the current sdk ... which was quite a 'WTF' moment - how seriously IBM-PC-XT is that ... OTOH moving the ringbuffer processing to the hardware removes most of the OS-specific code required to talk to the hardware and so will reduce the resource requirements for driver development (i.e. we wont have to wait for the driver devs, it'll already be done by the hardware guys).
I think the biggest problem for Java however is in the language itself, and in particular it's lack of mathematical expressivity[sic]. It doesn't support vector types for starters - which are handy in this case more for their ability to concisely realise mathematical expressions than the ability to map efficiently to SIMD processors. And even if one does wrap these in objects, using them is clumsy, error prone, and even messier if you're aiming for efficiency. e.g. it's simply cleaner writing C or OpenCL C code to perform most maths than it is doing the same in Java (in it's most purest object form, let alone optimised for practicality).
So although a lot of problems will probably map fine enough, occasionally one will be better off with lower-level access. If one could override the kernel code with your own string, but let Aparai handle the buffer management and let them all interoperate it would be very cool. Even if for example, it compiled the OpenCL code in to Java bytecode as the fallback (ok, this is a rather much bigger problem to solve ...).
OpenCL
So i've been wondering just what opencl can be 'used for'. Apart from making an image editor or video tool run faster, I can't really think of what it might enable. As important as those tools are - and OpenCL does make some features possible now which were not before - the are very niche products of little direct benefit to most of us (unless all you do all day is sit on your arse consuming hollywood movies and glossy magazines, which is probably - utterly sadly - a majority or at least major minority).
Unfortunately when searching for 'opencl kill app' the first hit is my own post of the same title ... ahh well.
Anyway, along the way I found this this blog which has some interesting observations and ideas about OpenCL hacking.For one I had missed that opencl 1.1 added a shuffle instruction: which is pretty much required for good performance for 'data streaming' applications: using SIMD to access non-aligned data. It can also be used to implement a vector index lookup. However, I'm not sure if this is a single-instruction function on GPU hardware, and it was just added to the spec for the CELL BE backend (without shuffle, the SPU's are kneecapped). Although it isn't too hard to find out by dumping the source code - which I did, and found that it isn't efficient at all. Oh well.
So back to the question of OpenCL applications: as from the last time I wrote about, enabling desktop performance on a hand-held computer is probably still the main thing we will all eventually see (although it's taking it's sweet time). This latest iteration of the thin client/server model (which harkens back to the original mainframe idea) wont necessarily last, as no previous iteration ever did. And although having an internet connectedness will be pervasive, you wont need to go to a back-end server to do the work when you have 100G/flops in your pocket.
The other thing, which I think is more interesting, is that OpenCL will enable cheaper design of complex systems - which means more competition and more products for the general public. So for example it has always been that even from the days of 8 bit computers you could design a hardware component to increase performance (sprite hardware, sound synth, etc), and this still allows advanced performance from portable or low-power devices. As OpenCL technology matures and die sizes continue to shrink, it will become feasible to replace the expensive custom silicon with more and more software, and so as we went from custom silicon to fpgas, we may well move toward more software-only solutions even in portable devices. OpenCL might be a prick to code in, but it's a lot easier than FPGAs are, and you can still get higher performance from purpose-built functional units (FPGA's big edge is in power requirements, and concurrency).
So I think OpenCL's killer application is not so much a consumer-facing one as a tool for system developers. Or at least, removing the need for system design input for a given application-specific device, and opening up similar facilities to all developers. This is pretty much the gist of one of the AMD talks from a couple of years ago (I think from the AMD developer summit, perhaps from 2010 as I can't see it in the 2011 talks - many of which look interesting enough to watch) about how they were able to produce results in less time and with fewer steps than going the hardware route. i.e. lower costs, higher payoffs, and so on. I.e. pretty much what FPGAs did for system design, OpenCL may do as well: it might not be as fast, but the reduced development costs and overheads for low-volume production, Moore's Law and so on more than make up for it.
As an aside, when I was playing around with the beagleboard I also looked up some arduino stuff from time to time. I thought it was amusing that so many 'old hands' would whine about how overpriced the arduino was and that you could get away with something simpler like a PIC and so on. It was amusing because we can all see where this is going with a computer such as the Raspberry PI coming out: these things are getting so cheap and ubuquitous, before too long those 'low cost' simple parts will only be made by niche manufacturers to service dying equipment: i.e. they will become too expensive for anything (not to mention the skills required). Before too long it wont be economically viable to use anything smaller than a 32-bit floating point cpu for anything requiring some calculations.
It's a pity that the whole patent issue is getting so ridiculously out of hand: now that we are on the verge of effectively commoditising the entire platform as it pertains to signal processing, we're all going to be thrown into a dark age of propping up the leeches and rentiers who seem to have captured governments the world over for their own benefit.
Update: So ... I did end up spending a couple of hours today watching some of the AMD fusion summit videos from 2011 (with a bit of a hangover i wasn't up for much more than this!). Quite interesting, I guess I should keep an eye out on this stuff a bit more, but when i'm busy with work or on leave I don't always keep up with it.
The first keynote was quite interesting (after the waffle from the first guy), the future direction of the 'HSA' (heterogeneous system architecture) platform. At one point there is a graphic showing a bunch of hardware driven queues where applications feed in job tasks directly from their process space and they are picked up and executed by the hardware directly ... without a cpu context switch or kernel-mode memory copy in sight.
Now THAT is interesting.
Although ... TBH what the diagramme most reminded me of was ... non-copying asynchronous message passing, and where have I seen that before? Oh ... AmigaDOS 1!? Well, it only took nearly 30 years to finally catch up ... sure there are differences in the capability, but given the technology of the time it's definitely the closest to the model proposed here. i.e. unified memory (CHIP ram!), separate processors working together, non-copying data flows, etc. It's more than just about the non-copying of data (although that is pretty important too), it's about keeping the ALUs fed with data, and avoiding the overheads of system interactions and exception/syscall processing (this is of course why AmigaOS worked in a similar way). Already with GPUs keeping them fed with data is basically impossible - they spend a lot of time waiting around twiddling their thumbs.
Still, it's funny how nice hardware design is when intel aren't involved ...
Speaking of not-intel, the talk from the ARM guy also was quite interesting. From their perspective the push for non-heterogeneous compute is not just about getting the job done faster, it's about getting it faster whilst using less power. With the process shrink there isn't enough power/heat sink to run all the transistors at once, so you have to divvy up the work in a way which gets it done the fastest without wasting the silicon, the power, and so on. And on a mobile device it's about trying to utilise all the extra gates are your disposal to keep pushing the edge of performance; whilst still keeping within heat and power budget. This obviously fits directly in with AMD's software stuff: how to actually programme such a chip in a practical way.
Although to me what is most interesting about this approach is that it acknowledges that there really is a hard physical limit on the amount of work a single silicon chip can do. And even though they're making them smaller and can fit more transistors they can't turn the new ones on at the same time. I had seen this in the OMAP processors but I thought that was just about power saving: not burning out the chips. Thus the only way to improve performance and utilise the extra silicon further is not by increasing the concurrency but by increasing the specialisation of the functional units, and having more of them. This is quite a fundamental change to hardware design: where normally one tries to maximise resource utilisation. (and yes, it contradicts my speculation above to some extent: but I wrote that before seeing the talk)
And it has pretty far reaching implications for software development too. And particularly for free software; if the specific functional units aren't available to everyone or use proprietary instruction sets or firmware.
I'm not sure i'm convinced of the whole cache coherency model though: I thought the CELL BE was a better idea for high performance since each CPU had it's own dedicated simple memory that runs fast (=== LDS), and knowing you have no cache coherency just means you code differently (and avoid a few pitfalls along the way). The main benefit you get is much higher effective bandwidth: if it has to go through a global cache you're still hitting a bottleneck. Still, it's all about the system performance not just the fpu, and also being able to practically achieve a good fraction of its theoretical peak in a reasonable time with a decent programmer: and these are system issues beyond the raw numbers and queue mathematics.
Well off to the GCN video: although from the last AMD roadmap there is a NEW GPU architecture headed our way by the end of the year, so I'm not so sure what's going on with GCN.
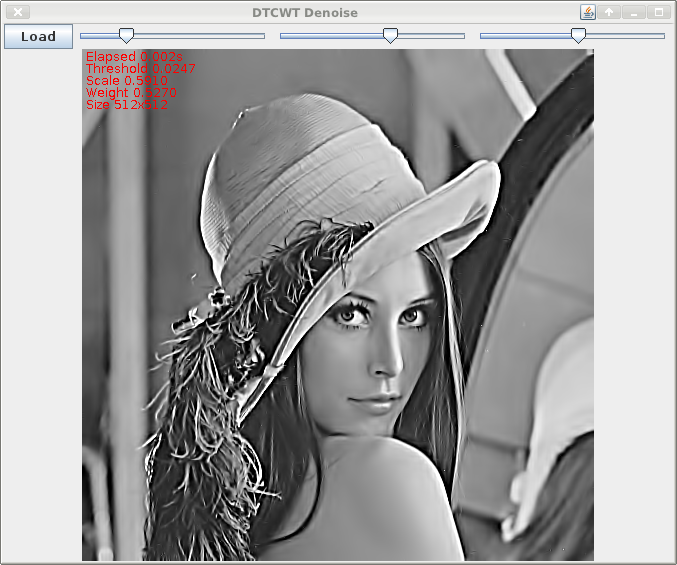
socles denoise/sharpen
This morning I ported the ImageZ denoise & sharpen stuff to soclesdemo now that I have the QWT code (mostly?) working.
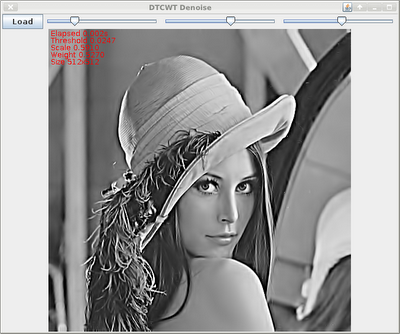
I still get occasional GPU hangs, but it is completely random: maybe it's code bugs, maybe it's driver bugs ...
It scales fairly well: I tried a 4288x2848 pic, and it was still interactively-quick (swing stuffed up visually since it isn't in a scroll-pane, so I couldn't see how long it was taking), and much of that time was to/fro java/swing/X. For a 1546x1178 image it was about 8ms for a the full wavelet processing (kernel times). It's only greyscale. This 1-2 orders of magnitude faster than a contemporary high-end cpu, so is well worth it: and it makes real-time 1080P processing possible.
But for an interactive application however you would only need to perform the forward transform once and just apply the thresholding and inverse with each change. So in that case it could be quite a bit faster.
Source
QWT
Since I haven't done any work in OpenCL for a while I thought on my hacking-day today I'd poke around socles for something different.I managed to mostly get the quaternion wavelet transform code I started pre-xmas working, at least for the forward transform. It is based on the code I have in ImageZ, which i've mentioned before. This can then be used to form a dual-tree complex-wavelet-transform 'on the fly' as I do in ImageZ, or by copying to another structure (these both have some fairly interesting properties, so far i've only done work with denoise/sharpen, but there are also other applications such as registration).It was actually a bit of a ramp-up to remember where the code was at. And then to decipher what it was supposed to do. For what consists a fairly simple algorithm (dual-convolution - the difficulty in wavelets is the filter design) there is a lot of very fiddly addressing and mucking about. Implementing upfirdn which is essentially what it uses is a pain even with such simple ratios as 1:2 and 2:1.
Although I seem to be getting an ok result, sometimes when I execute it on my GPU I end up having to hit the reset button ... so it's stuck on the CPU for now. Probably just some bounds checking errors. I'm not really on the ball today, pretty tired and grumpy, and I spent the better part of the day working on it so far; bit shit considering I already had a working Java implementation and most of the OpenCL scaffolding done. I guess not every day can be a super-productive one.
As above, i've only worked on the forward transform so far. Most of the tricky stuff is in the DWTGenerator which started as a copy of the convolution generator class, although QWT.forward() is a lot hairier than it looks too. I also managed to improve on the ImageZ code a tad: the redundant copies and vertical transforms aren't needed as I in-lined the sub-routines and have simpler data management.Update: Well I just kept poking at it, and eventually ended up with getting the inverse transform working: sometimes it just takes perseverance. Unfortunately the forward transform still crashes my GPU quite regularly and I haven't traced that down yet.
Between the resets I did manage to get a couple of runs through sprofile: it's about 350uS per transform for a 512x512 depth=1 transform, on a Radeon HD 6950. There are some LDS bank conflicts in the X convolutions, although the main bottleneck is the Y convolution since it cannot benefit from LDS and relies on coalesced reads and the global cache. I'm reasonably happy with that, and i'm not sure I can get much more out of it.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!