About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

NEON, timing, object detection
Well it's been an all-NEON week and together with some very poor sleep, a hangover, and bad hayfever ... i'm pretty much over it.
But I kind of have some interesting code that manages to coax a bit of performance out of the little beagleboard-xm i'm using for coding at the moment; memory is the biggest bottleneck there. It's not the target platform, but it provides a well defined minimum baseline. I also finally hit a very measurable problem with the small cache on it ... processing 512x512 images as floats just happens to be a bad size when you go over 16 rows in a vertical span - worse than 2x performance loss for some of the code.
I also found a new (to me) fft library for NEON that I will post more on once I get it to compile.
I was looking up something and (re)came across the nice little cortex-a8 static code analyser and put it through it's paces (somehow I missed that it was just a web application last time). Learnt a bit about cycle timing and dual issue, it's got a couple of bugs but works pretty well. The display of the SPU timing tool would be nice though.
Anyway for some reason I thought vext only worked on double's (probably since vtbl does), but on seeing it worked for quads due to something else I was poking at, and how quads interacted with each other (the ARM documentation on cycle timing isn't as clear as it could be), I thought i'd go revisit the LBP object detector I wrote as I remembered I didn't use quads there. I ran a whole bunch of variations of the inner loop through the tool and shaved about 7 cycles off the time. Not bad when it was only 33 to start with. Unfortunately I ran out of NEON registers (they were already all used) and had to resort to swapping 2 individual byte constants through q15 - all because vand.u8 doesn't support a general 8 bit immediate ... otherwise i could've gone 2 better (sad face).
Anyway, I gave it a go on my 'cheapie' tablet for the first time. It's fairly comparable in performance to the Galaxy Note I used last time, it's only a bit slower.
Cut a long story short, 130ms average for the original version, and now it's down to around 114ms (friggan timing stuff is all shot on this machine so it jumps around a lot, might be scheduler related, or debug output from android). Dunno if i added some bugs - it seems to work 'at all' which means they can't be big if they are there. Not quite as good as the timing analyser suggested - but then that is modelling an A8 and this tablet has an A9 which changed some of the features I was using, and I only analysed part of the loop - but all-in-all still worth the effort for something which I thought was already as tight as possible. Actually I thought it was a bit better than that at first because when I changed back to a 17x17 search window I forgot to adjust the search parameters, so it was detecting faces at about 35fps vs 30fps (search range of 6x to 20x, rather than 2x to 12x as my original test - minimum face size of (17*6)x(17*6) - which is still reasonably small on a webcam).
The better-than-1 instruction classifier!
Now i've got the classifier down to well under 1 instruction ... I should really work on improving the detector quality. I would really like to know if it can be made into a decently robust detector or not - because if it is it could be quite useful: it's trivial to train, has tiny classifiers, and can be made to run very fast on modern hardware because it is fully parallelisable down to the SIMD level, relatively cache friendly, and even has a deterministic running-time.
I've a few ideas but need to set time aside.
I've also been switching around a lot at work lately, and that's throwing me around a bit (not to mention the hayfever). When I switch between diverse areas such as NEON coding, Android applications, OpenCL, Java applications, JNI, C, jjmpeg, RESTful web services, databases ... it's taking a day or so to fully context switch, which means it's a bit hard to 'hobby' on something at the other end of the spectrum at the same time.
Parallella 2
So I start the day contemplating writing some NEON code (and as usually happens - that was from the moment I was awake), and I finally got the Parallella slogan 'A super computer for everyone'.
These days we can get more FLOPS than we can imagine for a few dollars - for the performance, GPU's are cheaper than anything that has ever come before them - but can anyone get those flops out of them?
Threads - are hard enough. And they don't even get you very far.
OpenCL - is hard. If threads were hard enough, try a SIMT programming model. Even when you know what you're doing it can still be a lot of work because once you go beyond simple 'per pixel' type algorithms you have to do all sorts of tricks to get the performance. Again a lot of fun, but rather expensive for whomever is paying the bills. OpenCL is another option for accessing SIMD units which is at least improved over intrinsics and assembly language - but it still has a lot of requirements and overheads which make it harder to code. Any any attempt to reduce that complexity through abstraction - will reduce it's performance.
Assembly language (for SIMD coding) - is even harder. It's fun, and I enjoy it (well, so long as it isn't something as fucked up as x86), but even I sometimes just want a result and not to have to deal with the complexities. But without it you're leaving a big chunk of your CPU's performance on the floor - as there's no real practical way to access the SIMD units otherwise (i include 'intrinsics' as 'assembly language' - TBH it's easier just writing the assembly).
One can get away with using pre-written libraries some of the time - but someone still has to write those libraries, and sometimes they aren't available. And even if they are libraries come with their own costs - such as first learning how to use their API, and then finding their bugs and limitations and learning how to work around those.
The Eiphany architecture does away with a huge amount of complexity on the hardware side - because it needs to to fit on the chip - but it also means it does away with a huge amount of complexity on the software side too. There is no need for SIMD as you have a ton of processors, so there is no need to learn how to write SIMD software. And since it isn't a wide vector processor, there's no need to support dozens of in-flight hardware threads and 'wavefronts', and all the complexity of coding they provide. And this goes double for compiler writers - trying to auto-vectorise code still doesn't work very well after plenty of attempts, and if there are no 'too hard to use' instructions, there's no wasted silicon either. There just isn't need for much abstraction because there isn't anything to abstract. I think it doesn't even have cache - it just has local memory - with fast access, and slower memory as you go further from the chip.
The 16 core chips might just be teasers, but 64 cores is when things start to get interesting.
Will one such architecture be the be-all and end-all for processing? Dunno. The HSA stuff from AMD+co is all about moving the processing to where it best fits. For 'wide loads' this will be a GPU, for 'branchy' stuff it will be a CPU. But GPU's are converging on CPU's anyway - the GCN ISA looks more like a scalar cpu + wide SIMD unit than a GPU. It's the complexity of the total solution that has me most worried though - can AMD pull it off?
Complexity in general is a form of vendor lock-in, so i'm all for anything that reduces it.
Update 19/10/12: So well, I put my money where my mouth is, at the moment I've chucked $550 into the hat.
One insomniacal morning this week I had a look at their facedetect code. Well, ... it's certainly not easy. Took them 7 weeks to write - apparently that indicates it is easy, but then it is a whole new architecture. Then again OpenCV is a pretty horrible library to start with.
I'm not sure on the performance as they don't specify which 'ghz class x86 cpu' they used (and even if they did that wouldn't help much), and any windowed face detection algorithm is highly dependent on the search parameters (it's in the code, but there's a lot to look through at 4am in the morning). But I think they were searching from scale 1 which is by far the most expensive step. It's a pretty strange application to port actually because windowed/cascaded object detection is such a shit algorithm fit for ANY cpu. Let alone one that is optimised for floats.
You'd think something like JPEG or video DCT would be a good example. Wavelets should be a good fit too. But if they really want the punters excited, show a video decode, or even a `phong shaded boing' demo. Fibonacci sequences ... jesus h christ.
The way they wrote the code reminded me more of SPU programming than anything else, but without all that fucking around with SIMD code required to get any performance out of it.
So all that and the fact i'm pretty sick of 'closed' hardware is why I put the dough up. I guess it wont make it anyway with only a week to go but we'll see. It's about the same amount my OpenPandora order cost me ... I wonder which I'll get first ...
Oh, and that it looks insanely fun to code for, not to mention being almost exactly the hardware I want for work ... ;-)
Parallella
Adapteva have a kickstarter project to create a $100 highly parallel computer with an "open" architecture.
It's a pity to see they aren't getting much traction - compared to other similar projects. I guess there might be a bit of SBC fatigue setting in, and the RPI seems to be getting all the limelight, even though there's no real comparison - generic ARM board with a proprietary VPU and GPU vs a highly parallel computer which is mostly open.
This is really a lot more interesting - not only from the architectural standpoint, but because it's actually an open platform - by the guys actually designing the chips too. This alone makes it a much more interesting prospect beyond the mere performance numbers and price. e.g. I already know the programming model and instruction set from a simple pdf download, without any NDA or costs. And it's an interesting model - almost a MISC cpu core (minimal instruction set) with ARM-like mnemonics, 64 registers but the bottom 16 map 1:1 to ARM usage, and a zero-page style (6502 thing) optimised 16-bit version of each instruction for a smaller sub-set of registers/offsets. Flat address space, localised memory, DMA engines, etc. (nothing I saw about about MMU/context switching though - although both are impediments to raw performance).
As we've seen with the Allwinner A10 stuff - having a cheap SOC is one thing, but without documentation and with proprietary components it's a much much less attractive deal. It doesn't matter how fast your GPU or VPU is if you can't actually use it. Reverse engineering efforts like lima are all well and good but they are a very slow and difficult way to get anywhere, and may never succeed (and from the details they've found so far, it may be impossibly complex to programme for anyway). And they have real boards - i'm not sure what the rhombus guys are doing but they keep talking about 'scaling up to millions of boards' yet don't seem to be able to get a few 10K$ together to do the hardware design. And after 3 years of talking still don't seem to have gotten anywhere. Or the OpenPandora guys who used such a complex device as the OMAP that they wasted big money and many years before they got it to function reliably.
I'm not really one to contribute to kickstarter, but maybe in this case i'll put my money where my mouth is and put up some dough, even if it looks like they wont make the target. And that just seems to be down to some poor marketing. A video with some HD video encoding or decoding would get the kids excited (sadly this is all anyone seems to care about for these low power computers), not a picture of an ammeter or some guy gushing about how fucking excellent their shit is (true as that may be!).
Update: If you read this far, see also the follow-up post.
JavaFX USB Camera App for Linux
Well I thought of something relatively simple I can do with JavaFX to get familiar with it, and maybe even end up with a useful tool. And that is a Linux web-camera application - i.e. something like Cheese.
I've been playing with the idea for a week or so but haven't felt like hacking much for various reasons. Last night was a wild storm, and the wind, rain and hail, together with the neighbours broken gutter and hayfever, it kept me up much of the night. I thought rather than struggle painfully with work i'd struggle painfully with some of my own hacking instead ...
A few hours poking around later ...
The red button takes a picture, although it just stays in memory at the moment. Then including the dynamically generated camera controls ...
Along the way I found a bug in v4l4j which was fixed very promptly - thanks Gilles.
It will let me tie in the jjmpeg code as well, if I get that far. And maybe even socles for some OpenCL processing (might get me off my arse to fix the socles filter graph stuff). Right now it doesn't do much, but on the other hand it's an almost embarassingly small amount of code too.
Layouts
So as usual - the layouts are the bane of any GUI developer. I'm using a GridPane as the base element for the on-screen controls, but it just isn't cooperating completely. e.g. the cells aren't aligning the way i tell them to - not unless I create a single-cell GridPane and align that. I guess i'm missing something, but that's all part of the learning curve no doubt.
JavaFX vs Swing
Performance is a good bit better than swing - a simple 60Hz webcam view is chugging along at about 35% cpu in Swing (the v4l4j bundled demo), whereas JavaFX is sitting around 10%. Although it goes up fairly quickly once you add blended widget overlays.
The overlays are a lot easier to code too, as are any animations and 'flashy shit', of course.
e.g. Half an hour later and I added some animation, taking a photo has it jump down to the list below, and it then fades in.
Effects
Although JavaFX has some "FX" which can be applied to scene graph nodes, i'm not sure it will be useful here. Apart from being a bit limited, the 'pulse' and asynchronous nature of the way the result can be grabbed to the host probably means it can't be used for video processing. One can have 'off-screen' scenes I believe, although i'm not sure exactly how the timing stuff is then handled.
Actually it's a task well suited to OpenCL, so if and when I get there, i'll probably just use that. It's a pity that JavaFX wont talk to OpenCL directly and the data will have to do a round-the-world trip across the PCI bus, but at webcam resolutions it shouldn't be a big issue.
As far as a 'camera app' goes, i'm personally more interested in other types of features anyway - e.g. automatic candid shooting (such as avoiding closed eyes or turned heads) for a party, or various types of image enhancement or degradation that can't be expressed using the current JavaFX effects tree.
Video ...
Another hour of hacking ... I added video recording to it via jjmpeg. I'm using mjpeg at the moment which seems to be about the only decent 'working format' I can find (fast to encode, easy to seek, commonly readable, etc). I threw everything on another thread so it easily starts recording without a glitch (at least on the workstation). It's using about 60% cpu (of 1 core) in total on this machine to capture VGA @ 60fps (although i really need to try it on a slower machine).
If only sound was that easy ...
My thinking would be that videos are recorded using a format suitable for recording (a fixed known format, high quality, low overhead, easy to manipulate), and can then be exported to another later (e.g. using ffmpeg command line).
Actually on jjmpeg, I guess I should revisit it now FFmpeg has released 1.0, maybe the api will be stable for a while. It's on the TODO list ...
I haven't checked anything in yet but it'll probably end up in mediaz/fxperiments/CamZ eventually.
Update: So I added a separate record button and flashing text and just checked it in as is, warts and all. I put it in MediaZ as a "top level" sub-project rather than inside fxperiments. Last weekend I updated jjmpeg to FFmpeg 1.0, so I changed it to use that (and found a lot of bugs along the way).
Multi client offline DB master-slave sync
As a bit of a throwaway request, the client asked for a multi-way offline database sync thing for the current prototype. Probably a bit more involved than he thought.
Anyway, based on some searches and a bit of pokery jiggery I came up with a fairly simple solution that I think will work based on 'update serial numbers' (USNs). It still needs a single master server, but can support multiple clients, and it should even support concurrent updates (with the correct transactional isolation). It also works in a completely streaming mode, and can be supported by database indices.
I didn't find any simple and complete description of the algorithm itself, so here's an outline of how mine works. There are a couple of unresolved issues wrt merges, but they weren't important for me at the moment.
Master
The master database keeps track of some metadata:
- ClientID sequence
- Used to assign new client id's to clients.
- USN sequence
- Used to track updates
Slave
The slave database needs some metadata:
- ClientID
- A globally unique number assigned by the server, used to assure every object has a globally unique primary key.
- USN
- Records the serial number of the last update with the server.
The slave needs to have a ClientID assigned before it creates any records.
Records
Finally, each object in the database needs a few fields:
- ID
- A globally unique primary key. This is a combination of the ClientID in the high bits plus a locally generated sequence as a 64-bit number. A compound primary key of clientid+sequence would also work.
- USN
- The serial number of the last time the record was updated or when it was created. Every time a record is written, this is set to the current local USN + 1.
- Flags
- I'm not using this yet - but the idea is that a deleted bit is used to indicate deletions, as otherwise deletions become somewhat problematic.
- mtime
- Last modified time. Used as one possible algorithm for resolving conflicts. Not a very good one.
Update Algorithm
The update algorithm runs in 4 distinct steps.
Slave Changes
First, the slave sends it's changes to the master server.
output magic, version, clientid, usn
for each table
for each record
if record.usn ≥ (usn+1)
output record
fi
done
done
This just outputs every record which we wrote locally since the last update. They will all have a usn of usn+1.
Master Update
The master then loads these changes into the database.
allocate new usn from USN sequence
read magic, version, clientid, clientusn
perform sanity checks
for each table
for each record
if record exists
merge/ignore update depending on usn, mtime, and business rules
else
set record.usn = new usn
write record
fi
done
done
The merging is the tricky part, and depends on the business rules of the application. But otherwise it is straightforward - the new records are set to the newly allocated USN.
Master Changes
The master then exports a list of changes that have occurred since the last update from the server.
output magic, version, clientid, new usn
for each table
for each record
if record.usn ≥ (clientusn+1) AND record.usn < (new usn)
output record
fi
end
end
Here it just outputs all records from the last time the client updated (client usn) to the new usn (exclusive - i.e. excluding the updates just received from the client).
Slave Update
The final step is for the slave to update from the new server changes.
input magic, version, clientid, new usn
perform sanity checks
for each table
for each record
write record
end
end
update slave usn to new usn
All changes from the server are simply stored locally, and the local usn is updated. This step and the first step must be executed as part of the same transaction for this to operate reliably. Note that the client will not have the same USN as the server for the client records - but this is
Issues
Some notes for thought:
- Deletes
- The use of a DELETED flag is the easiest way to implement deletes - if this is updated like any other record, and then ignored in the clients, it should 'just work'. The sync code doesn't need to know about deletes at all.
- Conflicts
- This mechanism provides a reliable direct indication of when conflicts occur. It is then up to business logic to determine how to resolve the conflicts.
- Merging
- As it stands, the given algorithm does not however directly support merging - where both clients must end up with a new combined record. It can only support either first come or last served. However it shouldn't be too difficult to extend the algorithm to support merging with ancillary lists. The current client needs a copy, but it must be marked with the new usn.
- Transactions
- If the two slave steps together, and the two master steps together, are both executed within local transactions, then the updates should be reliable. Even if the client fails the first time and must resend the update and the server runs the `same' transaction twice, the result should be the same (apart from the master records having a higher usn).
FX'd ARM
I noticed Oracle have a developer preview for javafx on arm ... so I thought i'd give it a go.
My beagleboard isn't properly configured so I don't have EGL, but I did find an (obvious) option to enable software-only frame-buffer mode:
-Djavafx.platform=fb
I also turned off the embedded mode, otherwise the mouse didn't work:
-Dcom.sun.javafx.isEmbedded=false
Well it's definitely not speedy, but I did manage to get Ensemble to work, sort of. I'm not sure if it's so slow as it's crashed or just busy but i didn't get past the front page without losing patience (it's minutes) ... the mouse over animated tiles (e.g. 'Rotate Transition') manage about 1fps. The StopWatch is so slow it barely updates the screen, best I got was about 1fps out of that too.
BrickBreaker works (and whilst a bit slow does animate at multiple fps!), but I had trouble getting the beagleboard to output any screen resolution my old monitor liked ... so I stuck with the 1024x600 from the Oracle setup instructions, however at that size the paddle is off the screen.
Actually I was more interested in running it on the Kobo as that would be really interesting - but it fails to run there. Apart from complaining about the input devices it seems to crash opening fonts. I copied over libfontconfig from my beagleboard but that wasn't enough on it's own. I guess with a bit more work I could get it going (partially, i'm sure the E-Ink wont update properly) but I spent enough time just trying to get telnet re-enabled on firmware 2.0 on the kobo touch. The new firmware turns the radio on/off very fast so you have to be quick after starting the browser to telnet in and kill off nickel (otherwise, it just appears as though there is no network).
Actually now I have that going again (I've been using it to read books lately, and the 2.0 firmware was a big big improvement - even if i keep falling asleep 1 page in most nights and then lose my place as i flip a few pages with my hand as i fall asleep) I might revisit ReaderZ with the public JRE now available. Well, if I ever get the spare time ...
I noticed whilst using strace on the kobo that it's doing thousands of gettimeofday() calls, so it's obviously some sort of profiling build. Obviously software rendering is never going to be lightning, but I was using Java2D on the Kobo with adequate performance, so it should be fast enough for simpler scenes (using the embedded jre helped quite a bit there though).
Anyway, the news that JavaFX will be fully 'open sauced' by the end of the ?calendar? year is very good to hear.
But for now I have to delve into some mobile-to-server multi-client database sync stuff. Oh joy.
Linux desktop
I wrote this a week ago and wasn't sure about posting it, but since others seem to be sinking the boot in, why not as well ... Boy Sam Varghese has some 'GNOMEic issues' and doesn't pull too many punches.
So now BN is back to updates, I see Miguel is at it again - blaming others for things he had a hand in. He has arguably had more of an impact than any other individual on the "linux desktop", so we all know where the buck stops. About time he manned up and admitted he was a good part of the 'problem'.
However - there are a few big problems that Linux really has fucked up - sound is the prime example here. Removable and network disks could definitely be better too. Unfortunately by not fixing these things properly where they should be fixed - it has left a vacuum which has been filled by the 'desktop' application developers. And not surprisingly, taking a desktop approach to a system problem leads to the sort of rubbish we have infecting our systems these days. Witness the continual parade of shitty audio solutions; from esd onwards. Compare this to DVB-T, or video drivers: there's just no comparison.
Otherwise, the kernel together with GNU libc has done enough to isolate applications from internal changes, as one would expect from an operating system kernel. It's job is to isolate software from hardware, and both the api and abi is part of that isolation.
The poisonous idea?
So when it boils down to the argument seems to be that the "idea" of not worrying about binary compatibility is the root of the issue of the failure of GNU/Linux desktop's failing to gain traction.
It's a strange argument; the kernel is distributed in source form, so internal binary compatibility simply isn't an issue by design.
And It's no different from any other internal api for an application. So long as the external interfaces remain compatible (if that is important), it should be up to the application's designers to re-arrange the internals as they see fit. Forcing some arbitrary and meaningless internal-binary-compatibility layer there would just be a costly waste of time.
So this 'stance' is simply common engineering technique, it is nothing special at all.
Perhaps it's just a language or translation issue.
Nothing to fix anyway ...
Of course, the base of the argument is coming from the premise that there is something technically wrong with the GNU/Linux desktop to start with; a premise I believe is simply incorrect.
A decade ago we had a usable stable desktop, and by now I really cringe any time I have to use a lesser one - that's the one that's slow, cumbersome, out-dated, and feature-limited compared to what I'm used to day to day.
There is simply nothing wrong with it technically.
So it just comes down to popularity. There are other measures but that seems a popular one these days amongst the kids ...
And how soon some forget that the thugs at Microsoft gained their premier position simply through illegal activity - which has been successfully prosecuted several times around the world. There certainly seems to be circumstantial evidence that they are still using questionable practices to keep their position - for example by paying "ISV's" one way or another not to release software on competitive platforms. Or bribing educators to use their software as "training tools". Or other questionable contractual terms in government and business deals.
Developers Developers Developers
If there are issues with the lack of developer resources on modern 'desktop' solutions, it may be because most of them see it as a solved problem. Whilst it was fun at the time, i'm not terribly interested in that kinda shit anymore myself. And if we had even a fraction of the resources today available - it wouldn't really be much of an issue. But rather than leave a solved problem solved, those working on these systems seem hell-bent on either copying something else which keeps changing simply to justify repurchase (e.g. apple, microsoft), targeting new platforms which aren't all that relevant (tablets), or just making busy work for the sake of some ethereal goal they will never reach.
At this point, gtk+ should be stable and mature and stop changing, and it's up to the vendors who make money off this shit to supply the labour for it. Which is the current state afaik (although why Federico recently changed the default file requester location to 'recents' is beyond me - totally worthless feature i never used anyway). Qt was pretty much always there.
As for Miguel, his projects have all been basically 'copying microsoft', so excuse me if i'm not very interested: and i'm sure i'm not alone here. If i was i'd just use the real thing. The same for GNOME's Apple-filled fantasies. It might be different if we had nothing and were looking for inspiration, but we don't really need another weird version of FVWM ... yet again ... which is all they seem to end up being.
Most software written is in-house special-purpose software: this stuff doesn't need to 'integrate' with the desktop any further than cut and paste and a file requester (if that). Actually apart from a few simple desktop utilities, no software really needs to - for it to be valuable, usable software. And on a platform like GNU/Linux which has no unified `desktop', tying yourself to one or another is a bit of a risky approach. For such software the platform is already decided, and not a particularly important factor.
So the other tiny part of the software pile - 'isv's writing boxed software - will just go where the money is. And that's either where the volume is - which will depend on the operating system - or high value niche markets where the operating system is not an issue. GNU/Linux will only have a small part in the former for the foreseeable future, but has a place in the latter.
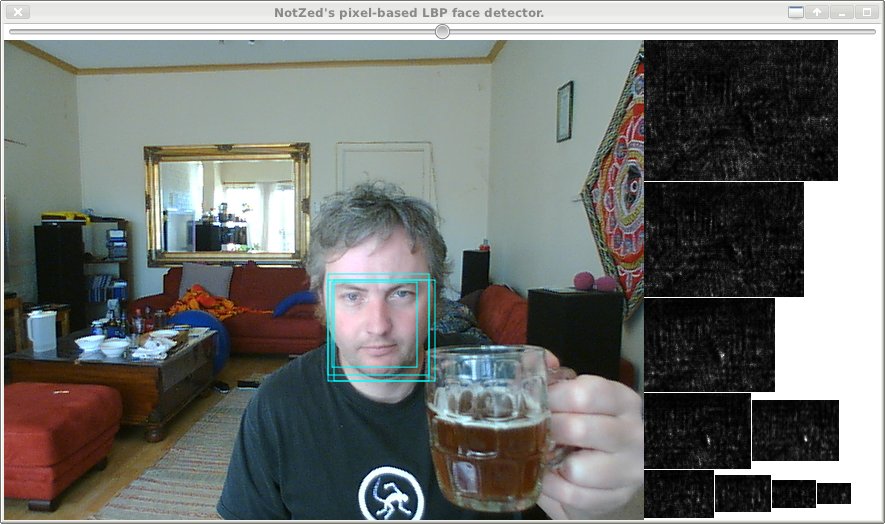
The Thick Object Detector
This was one of the first JavaFX things I played with - I was just hoooking up a web camera, but since that isn't too much on it's own I added a bit of code I'd been playing with at the time. An object detector.
It only works on systems with a Linux kernel.
Using pretty simple single-threaded Java code on the 640x480 input including generating the heat-maps, totals about 55ms per frame on my workstation. But the algorithm is parallelisable[sic] right down to the SIMD level, and because it's so simple it isn't even hard to do.
I'm not going to go into the training algorithm I'm using at the moment, but suffice to say it's very simple and very fast. Even though it's so brain-dead thick it still shows some promise - but still needs more work.
Source is over in MediaZ under fxperiments/FXDetectLBPP.
Beer time ...
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!