About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Reading comprehension, hUMA, NUMA, HSA, FSA, WTF?
I really need to find something better to do in my spare time than read ars "tech" nica and the like, but whilst doing a pass over the confusing front-page I came across an article about AMD's hUMA press. At least the front page isn't as bad as anandtech - i''m not sure what 'pipeline stories' are supposed to be, and to be honest i'm not sure why I bother reading a site which is full of computer case and psu reviews (ffs) and otherwise rather personally biased coverage of pretty random topics.
Anyway back to the arsetechnica piece. Pretty lazy article all round but I guess it summarised some of the points.
The real laff is with the comments.
Quite a few people seem to be getting "hUMA" confused with "NUMA". Hint: The N is for "NOT". Detail: Non-Unified-Memory-Architecture is exactly the opposite to Unified-Memory-Architecture which is the UMA part of the hUMA acronym.
NUMA is a way to add a lot of memory to a system with a lot of processors and not be bottlenecked by concurrent access issues (this is very much a good thing, it scales very well). UMA just makes the memory fast enough that the concurrent access shouldn't matter and then puts everything on the same memory ... (but it can't scale as well).
The rest of the comments just show that nobody knows what the 'h' means either. Probably understandable, it's a bloody horrid acronym and the article goes no way to explaining what's going on beyond the one set of slides in that press pack - however the information is readily available on AMD's site.
i.e. the h is for HSA, ... which is the other side of the coin. Another mouth-full at Hetereogenous Systems Architecture (off the top of my head, could be off a bit - i'm not a journalist).
In a nut-shell, AMD and the other HSA co-conspirators are working on turning their custom processors, DSPs, FPGAs, and GPUs into first-class CPU-compatible co-processors. They will all need to share the same virtual (and protected) address space that the CPU does. They will need to support a coherent cache (at some level, L2 at least). Obviously (like duh) this will require operating system support although apart from the CPU I would suspect it can just be hidden in the driver. Personally I hope the coherency isn't too fine-grained otherwise it will be a bottleneck on it's own.
And the other big part (from the last information I read on it at least) is that HSA uses a common assembly language/binary format/bytecode which can be re-targetted to different platforms cheaply, at run-time. So if the hardware provides the resources required, it will just run from a single compile. Although I suspect for performance it will have to target 'classes' of hardware, since to get good GPU performance you really need to write things very differently. I presume this will be based capability based on things like LDS memory.
Obviously AMD have to do this so that developers are able to target legacy Intel/PC hardware for free as well since neither Intel nor Nvidia are part of HSA - nor are they likely to be if they have any choice in the matter since it's such a big benefit to AMD's technology.
I think the commenters are also missing the point on just how much GPUs and CPUs have already converged. CPUs keep getting a wider MMX, as well as 'hyper-threading' and so on. And GPUs now have scalar units running the show, pre-emptive threading (in addition to the super-hyper threading they already have) and other processor features. The new GPUs will be capable of directly executing other languages like Java or Python or whatever - how those would handle vectorisation is another issue.
Anyway ... man, I hope they can pull it off. Right now working with a GPU it's like trying to solve every transport problem with a frieght-train. Sure you can get a lot of work done but it's not the best suited tool to every transport job - sometimes you can just walk. Like everything in the peecee wintel world getting to this point has been the product of throwing enough hardware and power at a problem until the architectural inefficiencies are inconsequential. This isn't good system design unless you're trying to sell the big hardware parts that drive it (i.e. you're intel).
The technology is great. The challenges are great. The wintel inertia which must be overcome is great too. The challenge of making the hardware easy enough to programme that all developers can take advantage of it ... is nigh on insurmountable.
With lambda's and the parallel collections Java could be a perfect fit. Well that language will be. With the JVM being so friggan complex, hopefully the implementation wont be a decade getting there as it was with cpus.
0k503
This is the 503rd post to this blog.
I was going to do a 'status update' on everything at the 500 mark, but I just can't be bothered right now and it's not that interesting anyway.
Which pretty much sums up everything else at the moment too.
After some intense activity at work and home i'm a little drained so taking it easier for a bit. Going from sprint to winter always seem to trigger a bit of don't-care too.
In perspective
Every day in the USA alone, around 12 pedestrians are killed every day and a further 200 or so injured (information readily found from official sources).
Every day.
And yet those deaths and injuries don't receive wall-to-wall news scaremongering news coverage and demands for more oppressive law enforcement.
Map Viewing Tool
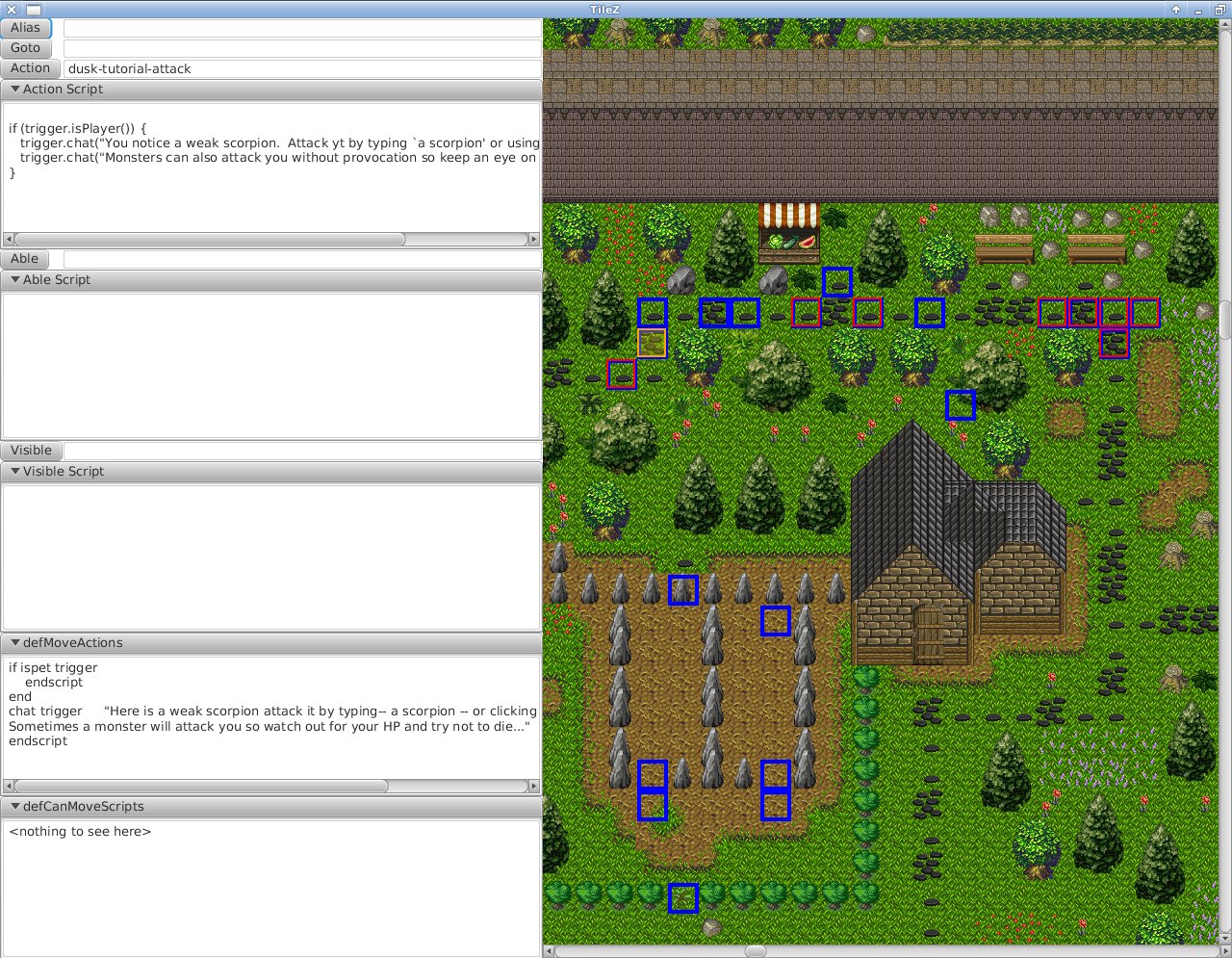
I had a couple of hours after waking up too early so I hacked a couple more things into the prototype map viewer - almost making it a useful-if-a-bit-crude tool.
First it displays any 'interesting' tiles - ones with any associated game behaviour - using red squares. Then as it was so simple even though it isn't terribly useful more than once, it does the same for the original dusk game - using blue squares. Then down the left-hand side it shows all the details of the scripts.
For starters it shows that I didn't get the tutorial complete after-all, although one of those squares just has an empty script.
Not a lot more work is required to turn it into a useful if basic game behaviour editor. Just the ability to save and create scripts and a few little lookup and navigation functions.
A couple of days ago after some work on jjjay I had a fleeting thought about how the game might be transformed to use a database backend. With Berkeley DB JE it would be a cinch, I could reliably persist all the live game objects into a single table with very little work indeed - the subclassing stuff is better than I can recall from last time i looked at it but I suspect I just didn't look too closely. I shouldn't need any DTO's. Actually it would probably turn out to be easier than all the text-mode import/export stuff I had to come up with and it could also be used to replace some of the internal indices. Using a db means that a text editor can no longer be the primary development tool so it would also require additional tooling. Something to ferment in the wort a bit longer ...
I had some other fleeing thought about something about the game, but it just flitted away ...
On an unrelated note, ScrollBar doesn't support middle-click. Annoying.
Oh thats right on the flittery thought. The way JavaScript is being used in the scripts is so simple, I wonder if it isn't easier just using Java instead. The scripts would stay in their format but could inserted into a template before being compiled. Might be an option for rarely-changing/performance critical tasks, but might not be so easy for any dynamic content. Definitely not something i'm going to rush into without a lot of experimentation.
Virtual tile grid
So I have been busy with quite a lot of other stuff lately and haven't really been looking at duskz much for a while. Partly there are some biggish problems to do with tooling and game-building that i'm not sure how to address off the top of my head, partly my mind is too full of NEON/Android/OpenCL and takes too long to context switch, and partly I just have other distractions.
This long weekend (every weekend for me is a long one now! yay for me!) the weather is too unseasonably nice to be stuck inside and I need to do some work in the yard too, so I probably wont do any more soon either.
However the other evening I had a short look at addressing one of the problems - how to find out where interactive things are set up within the map. Oddly enough looking at coordinate pairs and using command line globbing isn't a very friendly way to navigate through the game ...
To that end I have had the idea of a JavaFX fork of Tiled, just forking Tiled as is, or creating something more task specific ... that idea is still on the back-burner (one gets a little over-excited at times) but I did investigate how JavaFX would go about displaying the map layers in such a tool. Possibly it should just be a 'creator' mode within the game itself, but a separate tool has it's advantages too.
JavaFX scalability
I tried loading the Dusk map into a Pane using ImageViews, and it just exhausted memory after a very long pause. Yes the map is a very impractical 700x700 tiles which is not necessary anymore with the multi-map support, but if it would be nice if it coped.
JavaFX isn't really 'lightweight' as is mentioned in places - just looking at Node would tell you this.
It would be nice if there were Array versions of some of the basic Nodes that could manage state in a much more efficient manner. e.g. an imageview that could draw thousands of images, but tracks the coordinates or other adjustables in arrays of primitives which are more compact and can be processed efficiently. i.e. by using a structure of arrays rather than an array of structures. Such an approach has some pretty big benefits for things like parallelisation and animation too, but might be hard to fit into a general purpose object-oriented api such as JavaFX.
But even for something like this an Array implementation would need to virtualise it's coordinate generation to be efficient - 16 bytes per coordinate is a lot of memory particularly when the coordinate can be calculated faster on the fly from the tile location than it could ever be loaded from memory, even without an object dereference.
But since no such mechanism exists, one is left with ...
Virtualisation
So basically you get to throw out all that nice scene-graph stuff and have to manage the viewable objects yourself. This management of the viewport is kind of the whole point of scene-graphs (or at least a very major part of it), so for a scene-graph implementation to require manual virtualisation is a bit of a bummer. But what can you do eh? Fortunately for 2D the problem is relatively simple but it will fall down completely for 3D.
I started by trying to read through the ListView source to see how it virtualised itself. After half an hour trolling through half a dozen classes spread across a few namespaces I can't say i'm much the wiser. It seems to be based on the layout pass, but how the layout is requested is a mystery ... Although I did gather that unlike Swing (which to be honest was confusing and difficult to understand) which allows Gadgets to render virtually within any ScrollView (as far as i can tell), JavaFX's ListView just does the scrollbar management itself.
I figured that perhaps I could just use a TableView too, but as i'm not familiar with it at this point I thought i'd give it a pass. It didn't quite seem to be the right approach anyway as as far as I can tell the data still needs to be added as fielded rows, whereas my virtual data 'model' is a 1D array of shorts and it would be easier just to access it directly as 2D data.
As I couldn't really work out how the ListView was working I just took a stab with what I could figure out. I do everything in the layoutChildren() function. First I ensure there are enough ImageView objects just to cover the screen, and then update the tile content to match when the location changes. Per-pixel scrolling is achieved by a simple modulo of the location if you really must have it (personally I find it annoying for lists).
Pane graphics;
ScrollBar vbar;
ScrollBar hbar;
int vcols, vrows;
double oldw, oldh;
protected void layoutChildren() {
super.layoutChildren();
if (oldw != getWidth() || oldh != getHeight()) {
vcols = (int) (getWidth() / 32);
vrows = (int) (getHeight() / 32);
oldw = getWidth();
oldh = getHeight();
ObservableList<Node> c = graphics.getChildren();
c.clear();
for (int y = 0; y < vrows; y++) {
for (int x = 0; x < vcols; x++) {
ImageView iv = new ImageView();
iv.relocate(x * 32, y * 32);
c.add(iv);
}
}
}
updateMapVisible();
}
If the size has changed, it creates enough ImageView's to cover the screen (actually it needs to do one more row and column, but you get the idea).
updateMapVisible(), well updates the visible map oddly enough.
private void updateMapVisible() {
int y0 = (int) (vbar.getValue() / 32);
int x0 = (int) (hbar.getValue() / 32);
// Set per-pixel offset
graphics.setTranslateX(-((long)hbar.getValue() & 31));
graphics.setTranslateY(-((long)vbar.getValue() & 31));
for (int y = 0; y < vrows; y++) {
int ty = y + y0;
for (int x = 0; x < vcols; x++) {
int tx = x + x0;
ImageView iv = (ImageView) graphics.getChildren().get(x + y * vcols);
int tileid = map.getTile(0, tx, ty);
data.updateTile(iv, tileid, tileSize, tileSize);
}
}
}
Initially I just created new ImageViews, but just updating the viewport and/or the image was faster. Obviously updateMapVisible could optimise further by only refreshing the images if the tile origin has changed, but it's not that important.
There is only one extra bit required to make it work - manage the scrollbars so they represent the view size.
protected void layoutChildren() {
... other above ...
vbar.setMax(map.getRows() * 32);
hbar.setMax(map.getCols() * 32);
vbar.setVisibleAmount(getHeight());
hbar.setVisibleAmount(getWidth());
}
It's only an investigative bit of prototype code so it doesn't handle layers, but obviously the same is just repeated for each tile or whatever other layer is required.
It's NOT! magic ...
And I gotta say, this whole thing is a hell of a lot simpler to manage than any other virtually scrollable mechanism I've seen. General purpose virtually scrollable containers always seem to get bogged down in how to report the size to the parent container and other (unnecessarily) messy details with scrolling and handle sizes and so on. A complete implementation would require more complication from selection support and so on, but really each bit is as simple as it should be.
One thing I do like about JavaFX is that in general (and so far ...) it doesn't need to rely on any weird 'magic' and hidden knowledge for shit to work. The scenegraph is just a plain old data structure you can modify at whim without having to worry too much about internal details - the only limitation is any modifications to a live graph needs to be on a specific thread (which is trivially MT-enabled using message passing). I've you've ever worked with writing custom gadgets for any other toolkit you're always faced with some weird behaviour that takes a lot of knowledge to work with, and unless you wrote the toolkit you probably will never grok.
Although having said that ...
What I didn't understand is that simply including a ScrollBar inside the view causes requestLayout() to be invoked every time the handle moves. I'm no sure if this is a feature (some 'hidden' magic) or a bug. Well if it is at least it's a fairly sane bit of magic. The visibleAmount stuff above also doesn't really work properly either - as listed it allows the scrollbar to scroll to exactly one page beyond the limit in each direction. If i tried adjusting the Max by the viewport size ... weird shit happened. Such as creating much too big handle which didn't represent the viewable area properly. Not sure on that, but it was late and I was tired and hungry so it might have been a simple arithmetic error or something.
I suspect just using a WritableImage and rendering via a Canvas would be more efficient ... but then you lose all the animation stuff which could come in handy. The approach above will not work well for a wide zoom either as you may end up needing to create an ImageView for every tile anyway which will be super-slow and run out of memory. So to support a very wide zoom you'd be forced to implement a Canvas version. i.e. again something the scene-graph should handle.
I'm still struggling a bit with general layout issues in JavaFX - when and when not to use a Group, how things align and resizing to fit. That's something I just need a lot more time with I guess. The tech demo I wrote about in yesterday's post was one of the first 'real' applications I've created for my customer that uses JavaFX so I will be getting more exposure to it. Even with that I had a hard time getting the Stage to resize once the content changed (based on 'opening a file') - actually I couldn't so I gave up.
Update: Well I worked out the ScrollBar stuff.
When you set VisibleAmount all it does is change the size of the handle - it doesn't change the reported range which still goes from Min to Max. So one has to manually scale the result and take account of the visible amount yourself.
e.g. something like this, which scales the maximum from 0-(max-visible) linearly, where Max was set to the total information width, and VisibleAmount was set to the width, in pixels.
double getOriginX() {
return hbar.getValue() * (hbar.getMax() - getWidth()) / hbar.getMax();
}
TBH it's a bit annoying, and I can't really see a reason one would ever not need to do this when using a ScrollBar as a scroll bar (vs a slider).
Beware the malloc ...
So one of the earliest performance lessons I learnt was to try to avoid allocating and freeing memory during some processing step. From bss sections, to stack pointer manipulation, to memory pools.
This was particularly important with Amiga code with it's single-threaded fit-first allocator, but also with SunOS and Solaris - it wasn't until a few versions of glibc in, together with faster hardware, that it became less of an issue on GNU systems. And with the JVM many of the allocation scenarios that were still a problem (e.g. many small or short-lived objects) with libc simply vanished (there are others to worry about, but they are easier to deal with ... usually).
It was something I utilised when I wrote zvt to make it quick, unfortunately whomever started maintaining it after I started at Ximian (I wasn't allowed time to work on zvt anymore, and ximian was a bit too busy to keep it as a hobby) didn't understand why the code did that and it was one of the first things to go ... although by then on a GNU system it wasn't so much of an issue.
But even with a super-computer on the desk it's still a fairly major issue with GPU code. Knowing this I always pre-allocate buffers for a given pipeline and let OpenCL virtualise it if required (or more likely, just run out of memory) but today I had a graphic reinforcement of just why this is such a good idea.
After hacking all week I managed to improve the 'kernel time' of a specific high-level algorithm from 50ms to about 6ms. I was pretty damn chuffed, particularly as it also works better at what it's doing.
However when I finally hooked it up to a working tech demo, the performance improvement plummeted to only about 3x - one expects quite a lot of overhead with a first-cut synchronous implementation from c-java-opencl-java-javafx, but that just seemed unreasonable, it seemed like every kernel invocation had nearly 1ms overhead.
Without any way to use the sprofile output at that level (nanosecond timestamps aren't visually rich ...) I added some manual timing and tracked it down to one routine. Turned out that my port of the Apple FFT code was re-allocating temporary work-space whenever the batch-size changed (rather than simply if it grew). Simply those 2 frees and 2 allocations were taking 20ms alone and obviously swamping the processing and other overheads completely.
Whilst at 15ms with about 60% of the time spent in setup, data transfer, and invocation overheads it is still pretty poor, it is acceptable enough for this particular application for a first-cut single-queue synchronous implementation. Actually apart from running much faster, the new routine barely warms up the GPU and the rest of the system remains more responsive. I must try a newer driver to see if it improves anything, i'm still on 12.x.
Bring on HSA ... I really want to see how OpenCL will work with the better architecture of HSA. Maybe the GCN equipped APUs will have enough capability to show where it's headed, if not enough to show where it's going to end.
Why is the interesting hardware always 6-12 months away?
industrial fudge
It survives ... nearly 20 years on.
Never did finish and write the 'AGA' version ... but there were some pretty good reasons for that. When it was released some scumbag stole my second floppy drive, the next night I shorted my home-made video cable and blew out the blue signal, and I had only 2 hours sleep over a 96 hour stretch ... so I kinda lost interest for a while. Can't remember ever having slept particularly well ever since.
Hardware was so much simpler (and more fun) back then.
ActionBar, cramped screen-space, etc.
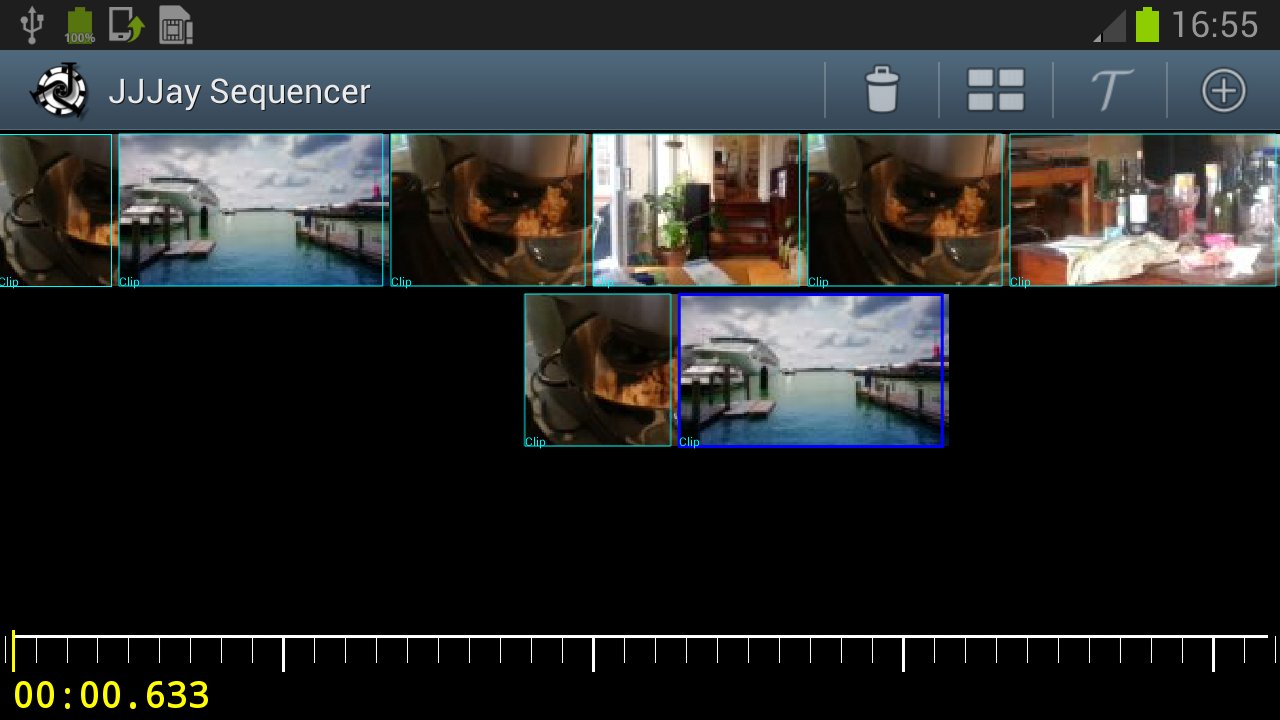
So after a few ui changes I tried jjjay on the tablet ... oh hang on, there's no menu button and no way to bring it up.
That's one ui design idea out the window ...
So basically I am forced to use an actionbar, and seeing how that is the case I decided to get rid of everything else and just use the actionbar for the buttons. Goodbye jog-wheel, it wasn't really doing anything useful on that screen anyway (unless I added a preview window, but that's going to be too slow/take up too much room on a phone). I also moved the scale/scrollbar thing to the bottom of the screen which is much more usable on a phone as otherwise you accidentally hit the action bar or the notification pull-down too easily.
It creates a more uncluttered view so I suppose it was a better idea anyway.
I fixed a few other little things, played with hooking up buttons to focus/action, and experimented with a 'fling' animator, but at this point some bits of the prototype hacked-up code is starting to collapse in upon itself. It's not really worth spending much more time trying to get it to do other things without a good reorganisation and clean up of some fairly sizeable sections.
I need a model for the time scale pan/zoom although I could live without that for the time being. A model for the sequencer is probably more necessary otherwise adding basic operations such as delete get messier and messier. There's still a bunch of basic interface required too; setting project and rendering particulars, and basic clip details such as transition time and effects.
So this is basically where the prototype development ends and the application development begins. 90% of the effort left? Yes probably. 6 days of prototype to 2 months of application development ... hmm, sounds fairly reasonable if a little on the optimistic side, generally it takes 3 writes to get something right.
I guess i'll find out if I keep poking at it ...
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!