About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

It worked again!
Just had my first success at launching a cooperative multi-core programme on the epiphany using my own loader.
... lots of spew ...
Loading workgroup
writing 'e-test-workgroup-b.elf' len 8208 to core 0, 1 0xb6f11000 <- 0x1d618
writing 'e-test-workgroup-b.elf' len 8208 to core 1, 1 0xb6e1a000 <- 0x1d618
writing 'e-test-workgroup-b.elf' len 8208 to core 2, 1 0xb6e08000 <- 0x1d618
writing 'e-test-workgroup-b.elf' len 8208 to core 3, 1 0xb6df6000 <- 0x1d618
writing 'e-test-workgroup-a.elf' len 2808 to core 0, 0 0xb6f19000 <- 0x154c8
writing 'e-test-workgroup-a.elf' len 2808 to core 1, 0 0xb6e23000 <- 0x154c8
writing 'e-test-workgroup-a.elf' len 2808 to core 2, 0 0xb6e11000 <- 0x154c8
writing 'e-test-workgroup-a.elf' len 2808 to core 3, 0 0xb6dff000 <- 0x154c8
find symbol _shared
section base = 8e000000 val=00000000
Global shared = 0xb4df5000
Reset cores
Start cores: 0,0 0,1 1,0 1,1 2,0 2,1 3,0 3,1
Waiting for results
result 0 = 000013ab
result 1 = 000130ab
result 2 = 001300ab
result 3 = 013000ab
I have two columns each with different programmes. The two cores in each row communicates individually on their problem and writes the result to shared memory. I came up with a queing primitive an 'eport' which handles arbitration on a 1:1 basis.
Although the per-core e_workgroup_config is in the elf file, it is uninitialised, so I had to set that up during the loading phase ... which took me an hour or so of faffing about to realise ...
The Code
So the whole point of this exercise is to write non-hetereogeneous multi-core programmes without having to hard-code addresses or manually extract symbols from elf files. The code below demonstrates that i've managed this to about as good a level as one can expect without having to customise any of the toolchain.
Program A defines the global shared resource (even though in this case it doesn't use it), a local eport endpoint, and a remote queue address (bbuffer).
struct interface shared __attribute__((section(".bss.shared")));
extern struct eport bport __attribute__((weak));
extern int bbuffer[4] __attribute__((weak));
struct eport aport = EPORT_INIT(4);
int main(void) {
int lid = e_group_config.core_row;
int *bbufferp;
bbufferp = e_get_global_address(lid, 1, bbuffer);
eport_setup(&aport, e_get_global_address(lid, 1, &bport), 4);
for (int i=0;i<20;i++) {
int wid = eport_reserve(&aport);
bbufferp[wid] = i == 19 ? -1 : (i + (1<<((4*lid)+8)));
eport_post(&aport);
}
}
It feeds out numbers to add one at a time to the ecore in the same row but in column 1. The 'eport' handles arbitration and blocking and so no 'critical section' arises at either end by passing ownership from the queue slot from one to the other (well it will when i fix a bug i just spotted) in an asynchronous manner; which is critical for performance.
Program B takes the values as they arrive adding them up - until a sentinal arrives. It then saves the result and pings the host.
extern struct interface shared __attribute__((weak));
extern struct eport aport __attribute__((weak));
struct eport bport = EPORT_INIT(4);
int bbuffer[4] __attribute__((section(".data.bank1")));
int main(void) {
int lid = e_group_config.core_row;
unsigned int qid;
int val;
int sum = 0;
eport_setup(&bport, e_get_global_address(lid, 0, &aport), 4);
do {
qid = eport_wait(&bport);
val = bbuffer[qid];
if (val != -1)
sum += val;
eport_done(&bport);
} while (val != -1);
shared.sum[lid] = sum;
shared.c[lid] = 1;
}
The only 'pain' is that each endpoint of the eport needs to be pointed to the other end explicitly - it can't be handled in the linker. Oh and symbols outside of the sub-workgroup must be accessed using weak references, which can be a bit easy to mess up (I think i can use void *, which helps protect against errors). These ecore programmes must be linked with '-r' to create relocatable elf files but otherwise do not need a linker script.
The host code is fairly straightforward too although I haven't yet got anything tidy for the return communications (actually eport would work too but you'd need one pair for each result core).
struct interface *shared;
e_init(NULL);
e_reset_system();
wg = ez_open(0, 0, 4, 2);
ez_bind(wg, "e-test-workgroup-a.elf", 0, 0, 4, 1);
ez_bind(wg, "e-test-workgroup-b.elf", 0, 1, 4, 1);
ez_load(wg);
shared = ez_addr(wg, 0, 0, "_shared");
ez_reset(wg);
for (int i=0;i<4;i++)
shared->c[i] = 0;
ez_start(wg);
for (int r=0;r<4;r++) {
while (shared->c[r] == 0)
usleep(100);
printf("result %d = %08x\n", r, shared->sum[r]);
}
Still a few bugs and things to finish off but it's a solid foundation.
Unfortunately ... it's nowhere near as trivial as loading a demand-paged elf file. The code has to do some of the linking and a few other bits and pieces - it's about 1 000 lines at the moment.
The e-zed runtime ...
I thought i'd have a quick look at hacking on parallella today - I thought about trying a multi-core algorithm again but in the end I decided I didn't want to code up all that boilerplate and worked on the elf-loader code again.
The last time I looked at it I had tenatively started hacking up an api to support multi-core loading but it was pretty pants and so I left it there.
This morning i started afresh, and it worked out much simpler than I thought.
This is the API I am currently working towards:
ez_workgroup_t *ez_open(int row, int col, int nrows, int ncols);
void ez_close(ez_workgroup_t *wg);
int ez_load(ez_workgroup_t *wg, const char *path, int row, int col, int nrows, int ncols);
void *ez_addr(ez_workgroup_t *wg, int row, int col, const char *name);
void ez_start(ez_workgroup_t *wg);
void ez_reset(ez_workgroup_t *wg);
(I called it ez_ to avoid namespace clashes and I use z a lot in software, not to make it sound like easy; although it turned out that way - remember, it's e-zed, not e-zee!)
At present ez_workgroup_t is a subclass of e_dev_t so they can just be cast as well, although i'm not sure how long adapteva will keep the api the same such that this works.
The idea here is that a workgroup represents a rectangular group of cores which will be cooperating together to work on a job. It doesn't quite fit with the opencl workgroup topology of homogenous multi-core, nor particularly with the way i think the parallella sdk is heading; but it can be fine-tuned.
In the end it was more work thinking up the api than implementing it - I already have much of it working. Because I was too lazy I just tried out the single-core test code but one at a time on different cores. It worked.
Issues remaining
- The loader relocates each loaded code once and then splats it to each target core. This means they all share off-core addresses and there is no ability to create thread-local / private storage.
I will think about this, probably the easiest way is to implement support for thread-local storage sections. Even without compiler support this can (sort of) just go straight into the loader, it would require some more work since it would have to handle each target core separately. Otherwise it would need some runtime setup.
- There's still no easy way to create linkage between on-core code.
e-lib has some support for relocating a known address to a different core - but that only works automatically if you're running the same code on that core. In a non-homogenous workgroup scenario you have to find this information externally.
Oh hang on, actually I can do this ... nice.
Code for each core can define weak references to code in other cores. Once all the code has been loaded into the workgroup it could just resolve these references. The code would still need to use the e-lib functions (or equivalent) for turning a core-relative-address into a grid-relative one, but this is not particularly onerous compared with having to manually extract symbol values from linker files at link or run-time ...
- But if i do that ... what happens with .shared blocks? Are they really shared globally amongst all grids in the workgroup, or are they local to each grid? Hmm ...
Doable technically, once I decide on an acceptable solution. Probably a new section name is needed.
- The newly published workgroup hardware support stuff should map nicely to this api. e.g. blatting on the code and starting the workgroup.
- It would be nice to have a way to manage multiple programmes at once in some sort of efficient manner. e.g. being able to change the set of programmes on-core without having to relocate them again and re-set the shared data space. Because LDS is so small real applications will need to swap code in and out repeatedly.
- I'm not aiming for nor interested in creating an environment for loading general purpose code which wasn't written for the parallella. This is for loading small kernels which will have all code on-core and only use external memory for communicatons.
I guess once I get the globally weak reference stuff sorted out I can finally tackle some multi-core algorithms and go back to the face recognition stuff. But today is too nice to spend inside and so it waits.
Update: I had another short hacking session this morning and came up with a simple solution that handles most problems without too much effort.
First, I changed the load api call to 'bind' instead, and added a separate load call.
int ez_bind(ez_workgroup_t *wg, const char *path, int row, int col, int nrows, int ncols);
int ez_load(ez_workgroup_t *wg);
Internally things are a bit different:
- Bind opens the elf file and lays out the sections - but does no reloc processing nor does it write to the target cores.
- A separate link is performed which processes all the reloc sections, and resolves symbols across programs. Again this is all implemented off-core.
- The load stage just copies the core binaries to the cores. This is literally just a bunch of single memcpy's per core, so it should be possible to switch between programs relatively quickly.
At the moment the linking/reloc is done automatically when needed - e.g. if you call ez_addr, but it might make sense to have it explicit.
When working on the external-elf linking I realised I didn't need to implement anything special for globally-shared resources, they can just be weak references as with any other run-time linked resources.
e.g. program a, which defines a work-group shared block and references a buffer local to another core:
struct interface shared __attribute__((section(".bss.shared")));
extern void *bufferb __attribute__((weak));
int main(void) {
// needs to map to global core-specific address
int *p = e_get_global_address(1, 0, bufferb);
p[0] = 10;
shared.a = shared.b;
}
And program b which references the shared block from program a, and defines a core-local buffer (in bank 1):
extern struct interface shared __attribute__((weak));
int bufferb[4] __attribute__ ((section(".bss.bank1")));
int main(void) {
// can use shared or bufferb directly
}
One of the other issues I was worried about was allocating thread-private storage. But that can just be done manually by reserving specifics slots in shared resources in a more explicit manner.
DuskZ + embedded db
So after being on the backburner for a while i've started thinking about duskz again.
Apart from finding other things to do with my time one reason I shelved it that I was pretty unhappy with the i/o mechanism i came up with. It was just a pile of pointless boilerplate and fucking around and it wasn't fun to write and wouldn't be to maintain ...
Thus I think the first thing I want to work on is changing to an embedded database, and let that handle all the shit. Fortunately berkeley db-je has a rather awesome persistence interface and so i'll be using that. The only thing I need to manage is tracking unique instances of live objects, but that is really very little work.
At first I thought i'd have an issue with prototypical objects - i.e. loading base state from an object, which then becomes a live copy - but I can just use a separate store (aka 'database') for that.
Anyway this isn't going to be a high priority and i'll only hack on it in bits and pieces when I have the time and energy. I think the design work I did earlier will make it fairly simple, although it might need some tweaking to fit.
Revamped Streaming Internode Radio Player
Although I errr, blew up my amplifier a few weeks ago (gin & tonics and amiga demos DO mix, altogether too well, from what little I remember anyway) ... I went to look up some internet radio today and noticed they prettied up the index page and included icons.
So what was going to be a short hacking session ended up with a much improved "internode radio app" compared to the last one.
Rather than a hardcoded list it retrieves and parses the RSS feed for the list of stations every time it starts up, so it's current and now has the icons too.
Handles rotation without resetting the stream.
I spent close to an hour fighting with LinearLayout and RelativeLayout so i'm too pissed off to upload it right now.
I also just discovered that the layout is all fucked on a phone so i'll have to fix that first. So I wont be in any rush for that because the layout is fine on all the devices i own myself ...
Update: Didn't even let the ink dry on this but thought i'd get it out of the way. It can be downloaded over on my shitty internode page for it. I tweaked the layout too - it works ok on a tv, 7" tablet and an SG3, beyond that who knows with how android does its resolution stuff.
Update: Moved the app home page.
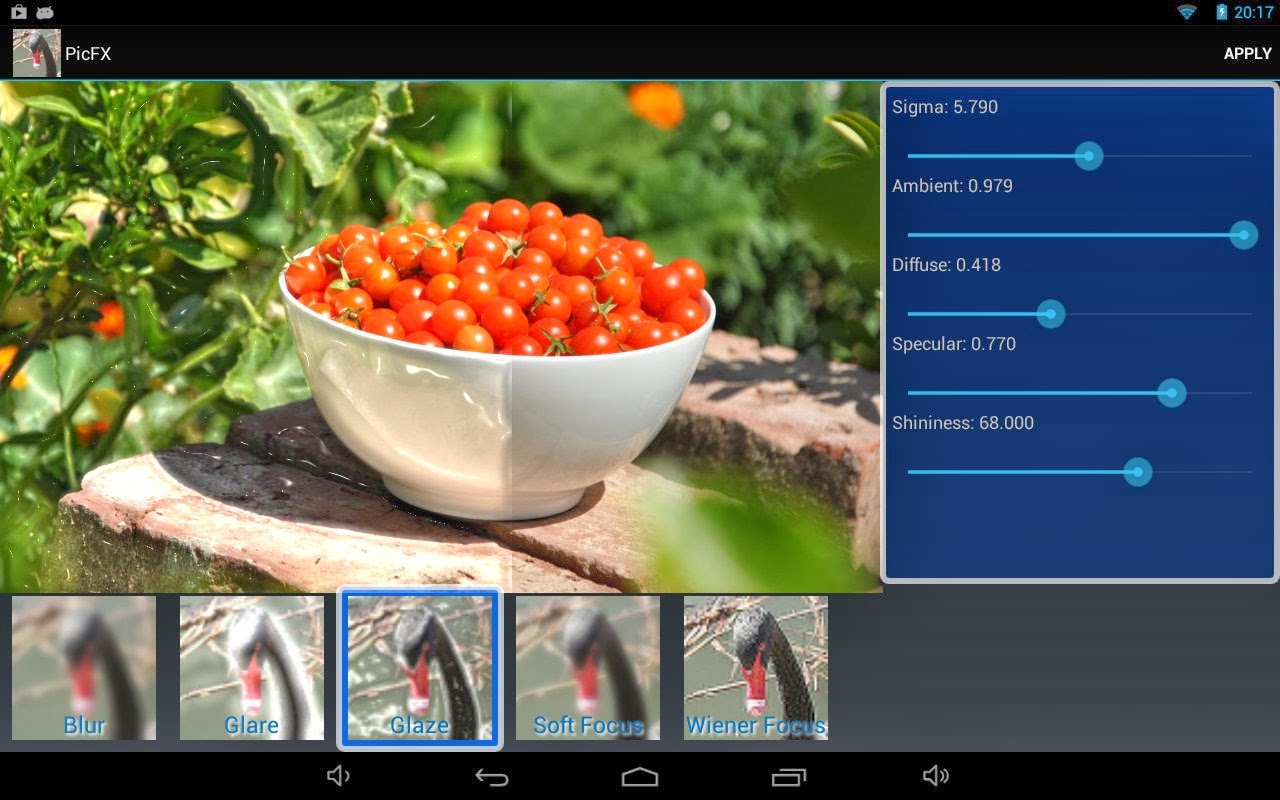
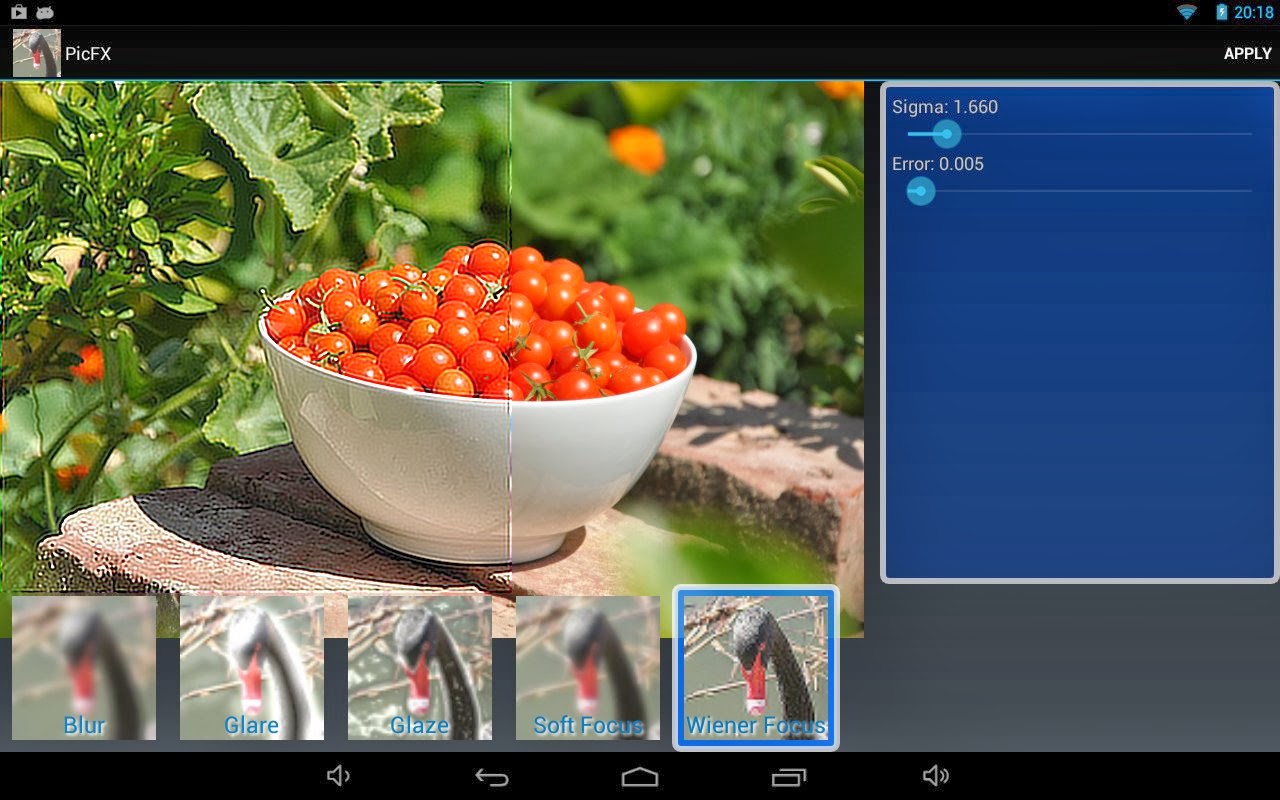
PicFX
I haven't been working on this nearly as regularly as I should've been but here's a bit of an update on the demo android app I was doing for ffts (an fft library).
It was looking a bit bare so I added in the effects I came up with on the weekend. This pretty much forced me to revamp the whole backend again ... but after a few hours work it's all roses. Or tomatoes.
Because I was aiming for some performance the code isn't the best 'example' code, but what can you do eh. Some of the design made code re-use difficult so there's a bit of copy/paste. Even with straight C the interactive performance is very good - over 10fps during a basic convolution of 4 channels. Of course it's only updating a 512x512 tile to help with this interactive speed, but i'm using multiple threads for most of the work. I took the NEON code out for now so there's a little more to be gained although most of the time is spent within the fourier transforms.
Today I added a bit of branding and cleaned up the GUI a bit and so (finally!) it's almost to a releasable state.
Gradients, lights, FFTs, &c
I've been playing with some gradient based "visual effects" and finally have a couple that look interesting.
This i'm calling glare, it's just an additive solid colour being modulated by the magnitude of the gradient. I guess it's a sort of HDR bloom effect.
This is a fancy emboss using a phong shading model for lighting with a small ambient source. I'm using the opportunity to learn a bit about lighting models - the last time I did anything related to lighting was on an Amiga and that amounted to little more than a dot product of the normal for 'light sourced vectors'. I finally get to use my Foley & van Dam!
This is the same algorithm with different parameters - upped the ambient, reduced the diffuse and specular and with a slightly smaller gaussin filter. Gives more detail to the surface as well as showing the original image (which could also work in colour).
I'm using a differential of Gaussian to calculate the gradients in each direction. This is basically a tunable sobel filter.
From these gradients I just directly create a surface normal which feeds into the phong calculations.
3 pass affine fourier resample
Just an example from the resample stuff I was looking at recently.
Source input - Lenna scaled by 1/8 using imagemagic with a Lanczos filter:
I'm applying an affine matrix with a 7° rotation and a 8x scale in each dimension. Apart from the test algorithm the rest are just using Java2D for the resampling on 8-bit images.
Just to see how little information is present i'll start with the nearest-neighbour version. The ringing at the top of the hat suggests artefacts have been added by the downsampling process.
Now for bilinear, which makes a right pigs breakfast of things:
Then comes bicubic. Which really isn't much better than bilinear once you get to this kind of scale. It's still making a mess of things:
And finally the one which is based on a three-pass shear and/or scale algorithm. It comprises three separate stages.
- Horizontal shear and scale;
- Vertical shear and scale;
- Horizontal shear.
Each operates only in a single dimension which greatly simplifies the resampling required - one only needs to be able to resample and scale in one dimension.
I'm using a trick to avoid the typical sinc filter ringing along the edges of the image itself, and i'm not cropping the result properly yet.
Unfortunately due to using a Fourier Transform for scaling I end up with a bit of ringing primarily due to the Gibbs Phenomenon. How much of this is present depends on the source image too, and even the nearest-neighbour result shows that the Lanczos downsampling has added some ringing to start with.
Even with the ringing certain features are significantly smoother - such as the brim of her hat, top of her shoulder, or the frame of the mirror.
Most of the design including using the Fourier Transform for arbitrary shift/scaling is from the paper Methods for Efficient, High Quality Volume Resampling in the Frequency Domain; Aili Li , Klaus Mueller. But i'm using the affine matrix decomposition in ``Bottleneck-free separable affine image warping''; Owen, C.B. ; Makedon, F. Image Processing, 1997. Proceedings., International Conference on (Volume:1 ). A related paper which just covers rotation is High Quality Alias Free Image Rotation; Charles B. Owen, Fillia Makedon.
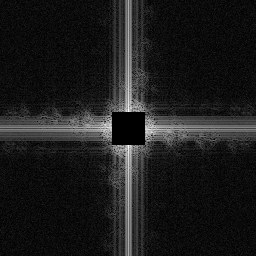
Spectral Analysis
Visual appearnce is one thing, but how true to the desired signal is each result mathematically? Taking a log power spectrum of a portion of the image (without edges) allows me to look a bit deeper.
Since i've upscaled by 8x in each dimension an ideal (i.e. sinc filter) resampling will contain no higher frequencies than were originally present - i.e. for a 64x64 image upscaled by any amount, only the lowest 64x64 frequencies should contain any information at all (it will be rotated along with the signal however). To emphasise this I've zeroed out the signal-bearing frequencies in the following spectrograms so that only the distortion added by each algorithm is displayed.
To be "farier" on the 8-bit resampling i've also taken the power spectrum of the quantised 8-bit result of the Fourier based algorithm as used to generate the PNG. This quantisation mostly shows up (?) as noise along the axes.
Note that each spectrum is auto-scaled so the brightness levels do not necessarily represent equivalent amounts of distortion.
To the spectrums ... first the nearest-neighbour. This basically leaks a copy of the original signal as a grid across the whole spectrum.
Bilinear reduces these signal copies significantly apart from along the axes.
Bicubic reduces them further but there is still significant signal leaking out to the adjacent frequencies. Approximately 1.5x along each axis.
And finally the result from the Fourier based method. Apart from the axes which are primarily due to the quantisation to 8-bit (i think), most of the signal is just noise plus a little from the rotation leaking past the mask.
Hardware scheduling & stuff
Came across an interesting article on the hardware scheduling stuff AMD is finally getting together.
One of the more interesting aspects of the hardware and their HSA efforts. I'm surprised it took so long to finally realise something like this. But when I think about it, it CAN only work if the GPU goes through the same memory protection mechanisms as the CPU, and they've only just done that.
This should mean much faster graphics drivers as well as significnatly reduced OpenCL job dispatch overheads. I've had issues with large job dispatch overheads on AMD before so i'm interested in seeing what difference it makes.
I wonder how the job queues for CPU jobs are handled by the operating system and it's scheduler? Can they replace the run-queue entirely?
On a side note I haven't been doing a lot of hacking outside of work lately. Too many family related distractions, a wedding, and other stuff. Just don't have the energy at the moment.
At work i've been playing with some interesting resampling techniques using fourier transforms, I might post a bit about it later.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!