About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

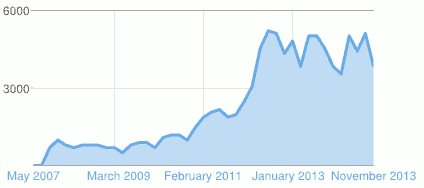
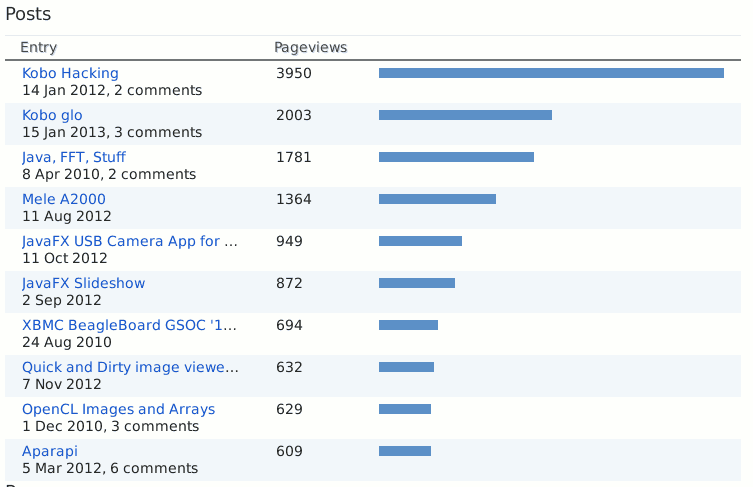
100K
In the next hour or so or whilst i'm wrting this (under 15 to go), this blog will hit 100K pageviews over it's lifetime; since early 2007.
So seems like a good time for another update - the last 50K certainly happened a lot faster than the first.
It bumbled along till about this time of the year in 2011 and then bumbled along at a higher level ever since. The big leap was from being added to the JavaFX feed surreptitiously IIRC, and it's been propped up lately from the occasional twat from the parallella devs.
I'm pretty sure a good proportion of it is just search engines and web crawlers, and lately a sharp rise in link spammers. I'm not sure why as the number of pages grows the page hits don't. Maybe it's because of these automaton views, or just because the web itself grows at a similar rate. I'm still occasionally dissapointed to see my blog show up too near the front when I try to whittle down a search on a topic (i.e. am i the only person in the whole world looking at that problem?), although that hasn't happened much lately.
I don't have the data to show it (maybe i can get it off analytics, but that doesn't cover the whole range and i'm not that narcissistic), but the general ebb and flow i've seen over a week suggests most human readers are reading the blog during the work-week and not on the weekends. Which is a bit of a bummer since almost the whole blog is about a hobby. If i were to guess: students appropriating work as their own, programmers looking for free code, and probably a good bit of general skiving.
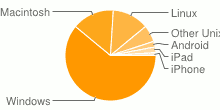
Just looking into some of the stats is a bit weird to be honest. The operating system skew for instance. I absolutely detest Apple Macintosh computers, yet that seems to have led to a pretty significant proportion. I think there might be some scientific Java and OpenCL programmers lending their weight to that stat. Good to see a decent 17% or so on some sort of Unix at least.
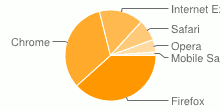
The browser share is also likewise atypical of the internet as a whole. Although personally I don't find the appeal of Google Chrome - not that Mozilla Firefox isn't without it's considerable problems mind you. Poor little IE, sucked in you pile of shit.
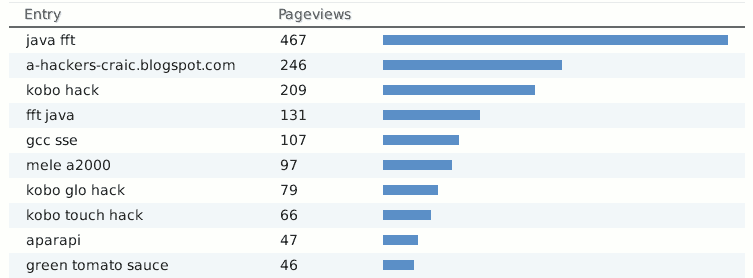
Because the search terms list has such a long tail it's hard to really tell what is bringing people here - but "java fft" continues to be the clear leader. The second is no doubt just an automatic browser resolving an invalid url (hint: url's start with the protocol ...), and kobo seems popular (is, below). Nice to see at least one other type of open sauce made the list too. Unfortunately spikes in the stats tend to hang around forever.
All I can think of is that there's a lot of people with kobo's that don't want adverts or to pay for books. Which is an attitude i can fully agree with, they just wont get anything to help them with that here. The OpenCL post in there is also not particularly useful, but who can tell what people find interesting.
I think the main reason I continue to blog is simply for the cartharsis of it. I don't care if people think i'm a bit nutty, a total cunt and a boorish prick, or if i'm really just talking to a wall. I'm not terribly interested in using this format for holding a conversation with peers and even less so with freeloaders; which is just as well as I haven't had much of that - I just got my 200th comment this minute infact.
Well, on to the future I guess.
lambdas to the slaughter ...
Had a look at a couple of the videos from the AMD developer summit going on at the moment. One was about how Java is a pretty good fit with the heterogeneous (i'm a bit sick of typing that word already) world. A short demo by Gary Frost of aparapi fame got me to finally pull my finger out and finally have a look at lambdas and how they work. Half an hour of hacking later and I think i've pretty much sussed them out for what i'm interested in!
As i've mentioned several times on the blog and elsewhere i'm pretty excited about the possibilities HSA provide, and i'm still surprised at how good a fit Java is for it - all because of the JVM and that 'pesky' bytecode and a few -very well thought out- language extensions. Until now I just haven't really had the time to look into them and have been limited by using JDK 7 as well. I'm also worried that once I use it I wont want to go back to the old way of doing things ...
I'm still using netbeans 7.3 so the lambda support is shit (totally nonexistant) but I played a little bit with a few things ...
Took me a while to realise when you iterate an array you don't iterate the items but the indices, but once that was out of the way it was plain sailing. Also had a look at 2d iteration as well. Some surprising results.
So a simple loop:
for (int i=0;i<a.length;i++) {
a[i] = sqrt(a[i] * b[i]);
}
Can become:
IntStream.range(0, a.length).forEach(i -> a[i] = sqrt(a[i] * b[i]));
(I'm not really a big fan of the syntax which hides so many details, but whatever).
Knowing that the lambda expression is converted to a private function suggests it should run slower, but thanks to the jvm ... it runs just about as fast as the simple array - infact with some tests it was slightly faster (oddly). Which is nice - because simple arrays are fast.
However the real benefit comes when you can then utilise all cores on your cpu ... (or eventually ... gpu) ...
IntStream.range(0, a.length).parallel().forEach(i -> a[i] = sqrt(a[i] * b[i]));
Now it uses all CPU cores available on the machine and executes appropriately faster. Well that was hard?
So what about 2D loops? The supplied streams only create 1D sequences.
A typical 2D processing loop:
float[] values;
int width;
int height;
for (int y=0;y<height;y++) {
for (int x=0;x<width;x++) {
float v = values[x+y*width];
.. do something ..
}
}
Which is simple enough but if you type it several times a day for weeks it gets a bit tiring (i'm pretty fucking tired of it). And I rarely even bother to parallelise these things because it's just too much work and I keep writing new code too rapidly. I suppose I could come up with some class to encapsulate that and use a callback, but then it becomes a bit of a pain to use due to finals or an explosion in one-off worker classes.
In a lot of cases 1D operations as above on 2D arrays suffice (when the coordinates don't matter) but sometimes one needs the coordinates too. So my first-cut-worked-first-time approach was just to create a '2D' consumer interface and map the 1D index to 2D using the obvious maths:
public interface Consumer2D {
void accept(int x, int y);
}
public class Array2D {
float[] values;
int width;
int height;
public void parallelForeach(Consumer2D ic) {
IntStream.range(0, width*height).parallel().forEach(i -> {
int x = i % width;
int y = i / width;
ic.accept(x, y);
});
}
public float get(int x, int y) {
return values[x+y*width];
}
}
...
a.parallelForeach((x, y) -> {
float v = a.get(x,y);
... do something ...
});
Now one would think all that extra maths would make it "a bit slow", but at least for my simple tests the JVM must be optimising it to pretty much the same code as it executes at the same speed ... as the straight 1D version!
Nice.
One still has to be somewhat cognent of the pitfalls of concurrent processing so it doesn't really make the solutions any easier to come up with, but at least it throws out a pile ... a big big pile ... of boilerplate ... which means you don't even have to think about the mechanics anymore and can focus on the maths. And that's only talking about CPU resources, trying to leverage a GPU is even worse (well in some respects it's easier because the job concurrency is automatic, but in other's it's much more painful do the native api's and data conversion). I still think there will be applications where OpenCL is useful (all that LDS bandwidth) - hopefully HSA will make that work nicer with Java as well in the future.
Damn, once I get used to this, Android and it's fucked up ancient shitty version of Java-esque is going to suck even more than it does already.
The other thing I still have to wait for is that HSA capable hardware, hopefully a decent minipc / laptop is available in Australia when they finally arrive early next year. And that it all works properly in Linux.
There's also an effort to port the same stuff to the parallella board, and it will be interesting to see how well that works in practice. I'm keeping an eye on it but it's a bit out of my area of expertise/current interests to help more than that right now.
Who'd have thunk Java being completely in it's own league when it came to support for massive parallelism and the high performance it can provide?
PS on another note it's interesting to see the latest GPUs are becoming completely bounded by both power and heat requirements - given the designs are now quite mature and advanced and there isn't much scope for performance increases due to architectural improvements as there has been in the past. Has a practical total-flop ceiling been hit outside of process changes (and how much can they even provide with the head dissipation issue)? The move to trying to improve utilisation via software improvements - HSA, Mantle, and so on - will only help so far - the more efficiently you utilise these chips the hotter they get too. Food for thought.
Little tool things & anim stuff
I was poking around at making a simple map viewer in a way that works directly with tiled output mainly as a way to see the animation stuff in motion. But I looked a bit further at using it for some other map related things.
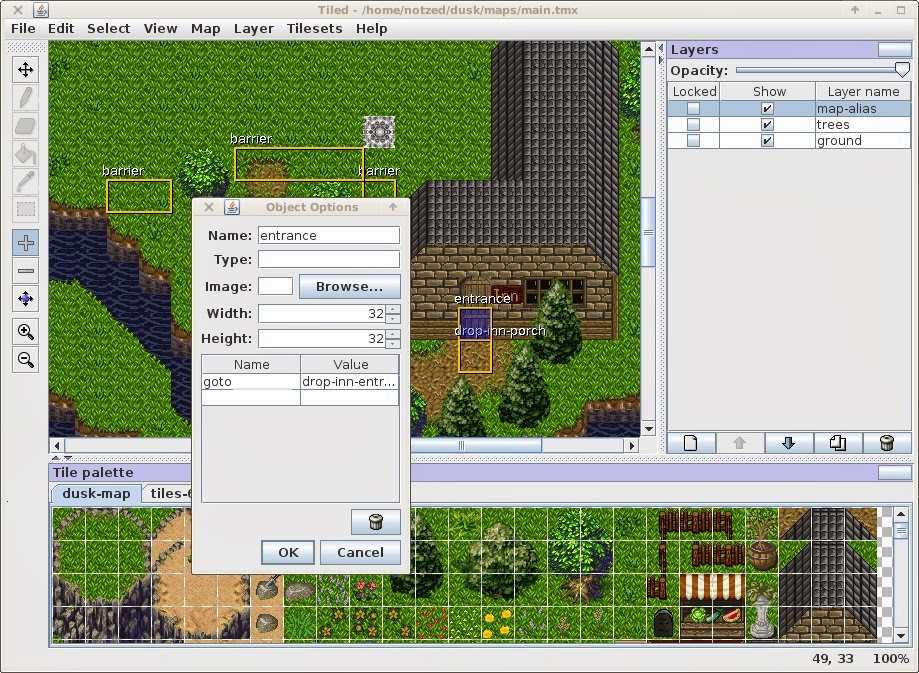
I store everything in a jar file - from a set of pngs for the tilesets, to the multi-layered map, the tile 'script' information, and I just had a quick 15 minute poke to see how to add the location based script information shown here as well. This allows one to define some basic behaviour like impassable barriers, doors/portals, and calls out to scripts directly in the tiled.
per-tile properties allow one to define impassable/un"stand"able objects, or calls to scripts, and the animation sequences - i'm still coming up with a simple enough design for the last point, but it will probably be something like:
anim=group,step[,duration]
Where group is symbolic, step is a sequence number, and the duration is the number of milliseconds per step taken from the tile with a step of 0. To make a tile animatable, one draws using the tile with step 0. This allows the same tiles to be used in different animation sequences so long as step 0 is unique. I'm still debating whether i have an extra layer of indirection and define animation sets which operate together to ensure they are always in sync. However i'm not sure it's worth the complication as I think the lower level animation system can ensure that anyway.
How on earth did ant become the build tool for java?
I got pretty sick of netbeans taking forever to build a very simple JavaFX app on my apparently now-too-slow (too-little-memoried) dual-core laptop, and so looked into why it was taking so long by creating a Makefile.
I wasn't expecting this ...
[notzed@unknown001fe11d1e42 MapViewer]$ time ant clean jar
... many pages of completely illegible and altogether
meaningless-to-human-or-computer output ...
BUILD SUCCESSFUL
Total time: 22 seconds
real 0m22.527s
user 0m32.211s
sys 0m1.919s
[notzed@unknown001fe11d1e42 MapViewer]$ make clean all
... a succinct if not particularly human-friendly list
of the specific commands executed ...
real 0m1.563s
user 0m1.678s
sys 0m0.349s
[notzed@unknown001fe11d1e42 MapViewer]$
What? What? Huh?
Oh, so it seems 'ant clean' cleans all related projects as well so it's rebuilding many more files needlessly. I thought one of the main points of having multiple sub-projects is to avoid this kind of thing ... but yeah, "whatever", ... in the parlance of our time.
So what about just changing one file ...
[notzed@unknown001fe11d1e42 MapViewer]$ touch src/mapviewer/MapViewer.java
[notzed@unknown001fe11d1e42 MapViewer]$ time ant jar
.. pages of crap again ...
BUILD SUCCESSFUL
Total time: 7 seconds
real 0m8.344s
user 0m9.161s
sys 0m1.038s
[notzed@unknown001fe11d1e42 MapViewer]$
Even what amounts to a simple batch script which just does everything from scratch is an order of magnitude faster than using ant - which only compiled one file. With JavaFX (as well as android), netbeans just keeps forgeting to pick up changes so I almost always have to use shift-f11 (complete clean and rebuild) every time I run whatever i'm working on otherwise I get either the old code or runtime failure.
I'm using javafxpackager to create the final jar, and the makefile is only 30 lines long, and you know, at least a bit readable.
I hate to think of the days I alone waste every year because of this completely incompetent and utterly shit tool.
Oh my god, it's full of boggles.
3rd time lucky
Instead of socialising with mates down at a local winery like I should have been, I was feeling too antisocial so I spent most of yesterday investigating using db-je for duskz ... and pretty much ended up rewriting the whole codebase; resulting in a 3rd totally incompatible game. And I still have about a days work to get back to where I was before ...
In the end the changes are more minor than I thought they would be:
- I simplified items to 3 classes (from 7) - general items, wearable items, and training items;
- All items are now read-only in terms of the game;
- Items in the inventory or on the map are stored via a holder object which tracks wear and usage;
- I moved the 'read only'/prototypical information from 'actives' to 'race';
- Mobiles have their own race subclass but otherwise there's one big race table (so no demon players anymore, at least not with that name);
- Moved things like name/description out of the base object, but provided abstract methods for them. This way a player can have a unique db constraint on the name, but nothing else needs to;
- I toyed with using interfaces (and infact did in the end) but the interface is so big and messy I don't think it's really worth it. However having done it I can use it as a tool for cleaning it up since every function that is necessary is easier to see. Thinking I maybe fucked up a little with the Battle rejig.
These aren't very big changes in reality and i just turned them into much more work than was required. However, along the way I cleaned up a few things:
- Pared down the interfaces a bit - removing helper functions where they weren't really necessary. e.g. getArmourMod() now takes an argument for including boosted attributes rather than a separate method. I wanted to do more but that will be harder;
- Store the passwords properly, e.g. only use bcrypt. Based on code from this nice howto for bcrypt;
- Moved more internal data to 'private' and provided helpers which force correct usage. e.g. a check password function rather than access to the crypted password;
- Got to ditch all the i/o code, although I still need tools which work in human formats. Currently I have some tab-separated-file format for loading old game data but it would be nice to automate it (or automatically generate tools for it).
But the big benefits of dumping into a db are ...
- I/O code is much simpler and more reliable;
- Automatic contstraint checks ensure the validity of all data in the database. e.g. you can't have an item on the map or inventory which doesn't exist, and you can't delete it if used. You can't create a user with the same name (and accidentally overwrite the old one), etc.;
- Transactions! Just simplifies a bunch of stuff;
- Indexed access to every object.
I still need to have my own in-memory indices for some objects because db-je is only an i/o layer and doesn't manage java object instances but it is only needed in some cases (e.g. in-game live objects) and is thin anyway. Actually I don't necessarily need these; it may be something i look into in the future although scalability isn't really an issue ...
But today i'm having a day off and will go read a book outside or something (and have an AFD at that).
Objects, they kind of suck.
I had a bit of a poke around the dusk code today, looking into the embedded db option.
It's not going to be as easy as I thought ... oh well.
The main trouble is that the objects used in the game are usually copies of some prototype object. So most of the data is copied but read-only - i.e. the sort of stuff that when you put it into a database you separate into a separate shared table. For Actives, I might be able to move this type of stuff into Races.
Another related issue is that the object heirarchy - whilst accurately representing every behaviour wanted in the game - is just a bit hassle for me to have to duplicate again to fix the database tables. I might simplify it.
It might even make sense to drop the common base class for everthing. One motivation for that was to save on (the considerable) i/o code, but all that can go away now. Another motivation was a single hash table for all live objects; but usually the code is only interested in a sub-set of classes anyway, and if it is backed by a database having seperate tables is more flexible.
I guess I still need to sit on this a bit more becaausei'm trying to be lazy and get away with a small amount of effort.
It worked again!
Just had my first success at launching a cooperative multi-core programme on the epiphany using my own loader.
... lots of spew ...
Loading workgroup
writing 'e-test-workgroup-b.elf' len 8208 to core 0, 1 0xb6f11000 <- 0x1d618
writing 'e-test-workgroup-b.elf' len 8208 to core 1, 1 0xb6e1a000 <- 0x1d618
writing 'e-test-workgroup-b.elf' len 8208 to core 2, 1 0xb6e08000 <- 0x1d618
writing 'e-test-workgroup-b.elf' len 8208 to core 3, 1 0xb6df6000 <- 0x1d618
writing 'e-test-workgroup-a.elf' len 2808 to core 0, 0 0xb6f19000 <- 0x154c8
writing 'e-test-workgroup-a.elf' len 2808 to core 1, 0 0xb6e23000 <- 0x154c8
writing 'e-test-workgroup-a.elf' len 2808 to core 2, 0 0xb6e11000 <- 0x154c8
writing 'e-test-workgroup-a.elf' len 2808 to core 3, 0 0xb6dff000 <- 0x154c8
find symbol _shared
section base = 8e000000 val=00000000
Global shared = 0xb4df5000
Reset cores
Start cores: 0,0 0,1 1,0 1,1 2,0 2,1 3,0 3,1
Waiting for results
result 0 = 000013ab
result 1 = 000130ab
result 2 = 001300ab
result 3 = 013000ab
I have two columns each with different programmes. The two cores in each row communicates individually on their problem and writes the result to shared memory. I came up with a queing primitive an 'eport' which handles arbitration on a 1:1 basis.
Although the per-core e_workgroup_config is in the elf file, it is uninitialised, so I had to set that up during the loading phase ... which took me an hour or so of faffing about to realise ...
The Code
So the whole point of this exercise is to write non-hetereogeneous multi-core programmes without having to hard-code addresses or manually extract symbols from elf files. The code below demonstrates that i've managed this to about as good a level as one can expect without having to customise any of the toolchain.
Program A defines the global shared resource (even though in this case it doesn't use it), a local eport endpoint, and a remote queue address (bbuffer).
struct interface shared __attribute__((section(".bss.shared")));
extern struct eport bport __attribute__((weak));
extern int bbuffer[4] __attribute__((weak));
struct eport aport = EPORT_INIT(4);
int main(void) {
int lid = e_group_config.core_row;
int *bbufferp;
bbufferp = e_get_global_address(lid, 1, bbuffer);
eport_setup(&aport, e_get_global_address(lid, 1, &bport), 4);
for (int i=0;i<20;i++) {
int wid = eport_reserve(&aport);
bbufferp[wid] = i == 19 ? -1 : (i + (1<<((4*lid)+8)));
eport_post(&aport);
}
}
It feeds out numbers to add one at a time to the ecore in the same row but in column 1. The 'eport' handles arbitration and blocking and so no 'critical section' arises at either end by passing ownership from the queue slot from one to the other (well it will when i fix a bug i just spotted) in an asynchronous manner; which is critical for performance.
Program B takes the values as they arrive adding them up - until a sentinal arrives. It then saves the result and pings the host.
extern struct interface shared __attribute__((weak));
extern struct eport aport __attribute__((weak));
struct eport bport = EPORT_INIT(4);
int bbuffer[4] __attribute__((section(".data.bank1")));
int main(void) {
int lid = e_group_config.core_row;
unsigned int qid;
int val;
int sum = 0;
eport_setup(&bport, e_get_global_address(lid, 0, &aport), 4);
do {
qid = eport_wait(&bport);
val = bbuffer[qid];
if (val != -1)
sum += val;
eport_done(&bport);
} while (val != -1);
shared.sum[lid] = sum;
shared.c[lid] = 1;
}
The only 'pain' is that each endpoint of the eport needs to be pointed to the other end explicitly - it can't be handled in the linker. Oh and symbols outside of the sub-workgroup must be accessed using weak references, which can be a bit easy to mess up (I think i can use void *, which helps protect against errors). These ecore programmes must be linked with '-r' to create relocatable elf files but otherwise do not need a linker script.
The host code is fairly straightforward too although I haven't yet got anything tidy for the return communications (actually eport would work too but you'd need one pair for each result core).
struct interface *shared;
e_init(NULL);
e_reset_system();
wg = ez_open(0, 0, 4, 2);
ez_bind(wg, "e-test-workgroup-a.elf", 0, 0, 4, 1);
ez_bind(wg, "e-test-workgroup-b.elf", 0, 1, 4, 1);
ez_load(wg);
shared = ez_addr(wg, 0, 0, "_shared");
ez_reset(wg);
for (int i=0;i<4;i++)
shared->c[i] = 0;
ez_start(wg);
for (int r=0;r<4;r++) {
while (shared->c[r] == 0)
usleep(100);
printf("result %d = %08x\n", r, shared->sum[r]);
}
Still a few bugs and things to finish off but it's a solid foundation.
Unfortunately ... it's nowhere near as trivial as loading a demand-paged elf file. The code has to do some of the linking and a few other bits and pieces - it's about 1 000 lines at the moment.
The e-zed runtime ...
I thought i'd have a quick look at hacking on parallella today - I thought about trying a multi-core algorithm again but in the end I decided I didn't want to code up all that boilerplate and worked on the elf-loader code again.
The last time I looked at it I had tenatively started hacking up an api to support multi-core loading but it was pretty pants and so I left it there.
This morning i started afresh, and it worked out much simpler than I thought.
This is the API I am currently working towards:
ez_workgroup_t *ez_open(int row, int col, int nrows, int ncols);
void ez_close(ez_workgroup_t *wg);
int ez_load(ez_workgroup_t *wg, const char *path, int row, int col, int nrows, int ncols);
void *ez_addr(ez_workgroup_t *wg, int row, int col, const char *name);
void ez_start(ez_workgroup_t *wg);
void ez_reset(ez_workgroup_t *wg);
(I called it ez_ to avoid namespace clashes and I use z a lot in software, not to make it sound like easy; although it turned out that way - remember, it's e-zed, not e-zee!)
At present ez_workgroup_t is a subclass of e_dev_t so they can just be cast as well, although i'm not sure how long adapteva will keep the api the same such that this works.
The idea here is that a workgroup represents a rectangular group of cores which will be cooperating together to work on a job. It doesn't quite fit with the opencl workgroup topology of homogenous multi-core, nor particularly with the way i think the parallella sdk is heading; but it can be fine-tuned.
In the end it was more work thinking up the api than implementing it - I already have much of it working. Because I was too lazy I just tried out the single-core test code but one at a time on different cores. It worked.
Issues remaining
- The loader relocates each loaded code once and then splats it to each target core. This means they all share off-core addresses and there is no ability to create thread-local / private storage.
I will think about this, probably the easiest way is to implement support for thread-local storage sections. Even without compiler support this can (sort of) just go straight into the loader, it would require some more work since it would have to handle each target core separately. Otherwise it would need some runtime setup.
- There's still no easy way to create linkage between on-core code.
e-lib has some support for relocating a known address to a different core - but that only works automatically if you're running the same code on that core. In a non-homogenous workgroup scenario you have to find this information externally.
Oh hang on, actually I can do this ... nice.
Code for each core can define weak references to code in other cores. Once all the code has been loaded into the workgroup it could just resolve these references. The code would still need to use the e-lib functions (or equivalent) for turning a core-relative-address into a grid-relative one, but this is not particularly onerous compared with having to manually extract symbol values from linker files at link or run-time ...
- But if i do that ... what happens with .shared blocks? Are they really shared globally amongst all grids in the workgroup, or are they local to each grid? Hmm ...
Doable technically, once I decide on an acceptable solution. Probably a new section name is needed.
- The newly published workgroup hardware support stuff should map nicely to this api. e.g. blatting on the code and starting the workgroup.
- It would be nice to have a way to manage multiple programmes at once in some sort of efficient manner. e.g. being able to change the set of programmes on-core without having to relocate them again and re-set the shared data space. Because LDS is so small real applications will need to swap code in and out repeatedly.
- I'm not aiming for nor interested in creating an environment for loading general purpose code which wasn't written for the parallella. This is for loading small kernels which will have all code on-core and only use external memory for communicatons.
I guess once I get the globally weak reference stuff sorted out I can finally tackle some multi-core algorithms and go back to the face recognition stuff. But today is too nice to spend inside and so it waits.
Update: I had another short hacking session this morning and came up with a simple solution that handles most problems without too much effort.
First, I changed the load api call to 'bind' instead, and added a separate load call.
int ez_bind(ez_workgroup_t *wg, const char *path, int row, int col, int nrows, int ncols);
int ez_load(ez_workgroup_t *wg);
Internally things are a bit different:
- Bind opens the elf file and lays out the sections - but does no reloc processing nor does it write to the target cores.
- A separate link is performed which processes all the reloc sections, and resolves symbols across programs. Again this is all implemented off-core.
- The load stage just copies the core binaries to the cores. This is literally just a bunch of single memcpy's per core, so it should be possible to switch between programs relatively quickly.
At the moment the linking/reloc is done automatically when needed - e.g. if you call ez_addr, but it might make sense to have it explicit.
When working on the external-elf linking I realised I didn't need to implement anything special for globally-shared resources, they can just be weak references as with any other run-time linked resources.
e.g. program a, which defines a work-group shared block and references a buffer local to another core:
struct interface shared __attribute__((section(".bss.shared")));
extern void *bufferb __attribute__((weak));
int main(void) {
// needs to map to global core-specific address
int *p = e_get_global_address(1, 0, bufferb);
p[0] = 10;
shared.a = shared.b;
}
And program b which references the shared block from program a, and defines a core-local buffer (in bank 1):
extern struct interface shared __attribute__((weak));
int bufferb[4] __attribute__ ((section(".bss.bank1")));
int main(void) {
// can use shared or bufferb directly
}
One of the other issues I was worried about was allocating thread-private storage. But that can just be done manually by reserving specifics slots in shared resources in a more explicit manner.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!