About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

microsoft's ex-box one more WTF?
So microsoft's xbox-one-again is out and a few weird things have come to light.
Batshit Insanity
Firstly it's obvious that still just don't get it. The general pupulous 'mass market' do not want a PC under their TV, they want an appliance. But they've gone and dropped a full-blown 'metro' interface - which looks confusing as hell to start with, and looks like a total headfuck on a tv with a controller. That's completely apart from the decidedly non-mass-market price.
Nobody's PAL
And then there's the whole tv integration ... no 50hz mode? What?
I'm pretty down on the 'tech press' already, but them claiming that somehow that is 'impossible to fix' is pretty laughable. Every PS2 or PS3 game in PAL regions also support direct 50Hz output because they supported composite out. Given that most of a game is being rendered in real-time it's a trivial run-time alteration (literally a couple of numbers) to change either rendering resolution or framerate output. A bonus here is that you have considerably more frame-time as well so games always run smoother at 50/25 compared to 60/30 too. The only stuff that can't be easily fixed for 50Hz output is pre-rendered video (aka 'FMV') - and that CAN be fixed by just recording two versions at the different frame-rates - which is what the high budget games have usually done. And even then it isn't really that important for lower budget games; a few judders during non-interactive game play is no big deal.
Apart from that, 50Hz is better for ALL video content apart from native NTSC recordings anyway - which is a legacy from electronic pre-history. So for a so-called 'all in one media solution' to force a shitty PC-compatible-60hz is utterly nonsensical. If you're used to watching youtube or videos on your pc you probably wouldn't notice but it just totally shits up the picture.
Is it gaming, or is it gaming?
The other big thing to come to light is the attempt to push the revenue model up significantly higher than the selling-disks model will ever be able to provide.
Here in Australia 'gaming' generally refers not to computer games, but to the computerised gambling industry. An awful lot about the intended revenue models (and mobile/tablet 'free to play games' in general) share a lot with this despicable industry which prays on people psychologically to fleece them of their cash. Even the words being thrown around like 'whales' come from directly that industry.
And gaming is big money compared to the computer game industry.
Unfortunately it seems 'computer games' are going to be headed at least in some part toward this gambling revenue model; anywhere there is this much money to be had it will be sought out actively. Companies that don't embrace it will be fighting for the scraps but hopefully they'll be able to survive and hopefully this is just a passing fad (or gets regulated out of the market).
If one looks at a graph of revenue from microsoft's entertainment division vs the other business units (i think there's a plot from semiaccurate or somewhere that shows this) something jumps right out at you: one has been bumbling on at insignificant profits or losses for a decade whereas the other units generate obscene profits. microsoft will not be in this business much longer if they cannot find a way to bridge that gap and this gambling based user-fleecing revenue model is just one of the despicable anti-customer ways they will attempt it. It will be interesting to see if they can manage it ...
Bundling with Video Services
This is another strange idea coming out of some of the analyst houses and tech press; some weird notion that entertainment providing companies will 'partner' with microsoft to deliver content through their hardware.
Now there's an idea which is bat-shit insane.
The thought that any company would willing GIVE AWAY it's entire family jewels to a DIRECT COMPETITOR is just embarassing. The only way it might happen is if entryism takes over the board as it did with nokia, and destroys the company from the inside.
And it's pretty much an obvious conclusion from applying a bit of common sense - if this was going to happen they'd never have bothered with the dumb out-dated idea of a video pass-through in the first place. That just seeems a decade late ... at best.
Automagic cross-core symbol linking.
So one of the problems with the loader/linker code i've been working on is that you still need to manually link symbols on other cores ... which is rather error prone and frankly a bit of a pain. I was looking at how to wrap some of that pain in macros and had another thought.
It relies on the fact that as is usually the case; relocs can have an additional fixed pointer-sized offset added to them.
Basically the idea is that when you reference an external core, you define a work-group relative address by providing an addend which defines the group-relative core address in the upper 12 bits as normal. At load time this external-core link is detected and offset by the workgroup base (which can be dynamic). It should still work cleanly for all the normal cases like referencing a member of a struct and so on which is what these relative addends are for.
A few simple macros should make it trivial to use but in raw code to define a reference to 'bufferx' in a core which is in column 1:
extern void *bufferx __attribute__ ((weak));
void *refx = (1<<20) + (void *)&bufferx;
Each case would need special handling in the link-loader for the core-address bits (row=31-26, col=25-20, iirc, or vice-versa; it isn't important here):
- row == 0, col == 0
- Left alone - remains a local address. Allows for programmatic resolution as i'm currently using via elib.
- row == 0 col != 0
- Resolves to this.row,
group.col + col this.col +- col.
- row != 0 col == 0
- Resolves to
group.row + row this.row +- row, this.col.
- row != 0 col != 0
- Resolves to
group.row+row, group.col+col this.row +- row, this.col +- col.
- Outside of workgroup or chip?
- Undefined behaviour? Leave it as is? Clamp? Let it resolve as above?
- Matches dram "window" address.
- Leave it alone.
Where group is the group root, and this is the core on which the code resides. I thought of using the non-zero values as 'this relative', but there aren't enough bits for a signed offset (actually, there is if I use wrap-around ... hmm, interesting thought, actually the more i think about it I think it's the better solution, otherwise you can't reference 0,x or x,0 ). Given that a 64x64 core w/ 1MB LDS each might be some time away I could always abuse some of the addressing bits for extra information anyway, but that's probably not a wise idea for the little benefit it might provide.
This will cover most of the common and useful cases and one can always just fall back to using e_get_global_address() for more complex data-flow topologies.
Unfortunately it requires more processing because each programme must be (re)linked for each target core rather than being able to broadcast the code to all common cores and these extra overheads might make it less attractive. OTOH it allows for load-time initialisation of data structures and less on-core code.
Hmm, how did it get to midnight. Blah.
A bit of S-FX fun
Last couple of days i've been poking around a bit with audio - trying to learn a bit more about how to process it digitally.
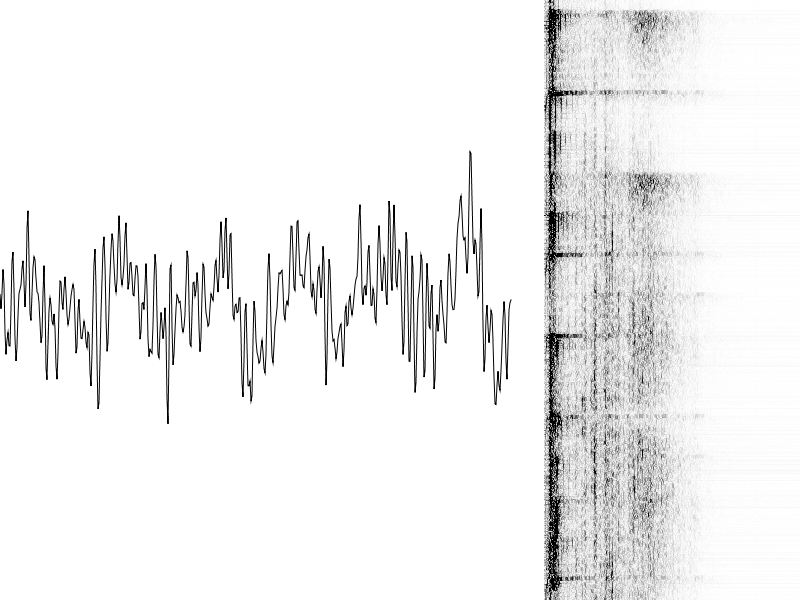
To start with I just wanted to get some visualisation up to see what sort of stuff you get out of a fourier transform.
I started in Swing but then re-started in JavaFX and came up with this little tool. A signal plot on the left and a scrolling spectrogram on the right.
I use an old trick from Amiga days to simplify the spectrogram display updates. I create a WritableImage which is twice the visibile size. When a new row of spectrogram data arrives I write it twice, at the current output row and at the current output row + visible size. This just keeps repeating forever, rolling back to the start when it overflows. Then I adjust the viewport on the ImageView to show the correct section - which is just the total output count modulo the visible row count. This creates a smooth scroll without having to write the whole display every time (let the GPU do that since it will anyway) or the need for an extra block of processing once every n frames.
So e.g. for a 256-wide spectrogram on a 600-high display:
WritableImage spectrogram = new WritableImage(256, 1200);
ImageView spec = new ImageView(spectrogram);
int spectrogramRow = 0;
void addRows(int[] srow, int rows) {
PixelFormat fmt = PixelFormat.getIntArgbPreInstance();
spectrogram.getPixelWriter().setPixels(0, spectrogramRow, 256, rows, fmt, srow, 0, 256);
spectrogram.getPixelWriter().setPixels(0, spectrogramRow + 600, 256, rows, fmt, srow, 0, 256);
spectrogramRow = (spectrogramRow + rows) % 600;
spec.setViewport(new Rectangle2D(0, spectrogramRow, 256, 600));
}
Unfortunately it's just running on the CPU (some ancient piece of shit intel graphics on this laptop) so the output isn't really very smooth at all, nor can up the spectrogram rate too high. Not that it's fast enough anyway but I don't think it helps that my laptop outputs 50Hz to it's screen and the external second screen is 60Hz, I think JavaFX uses 60Hz NTSC timing too, bletch.
Actually I dunno, it's only using 30% cpu. Must try it on my workstation.
Anyway, nothing special but it's still hypnotic enough I forgot why I started writing it.
The joy of segfaults
I had another look at some parallella code today but I didn't get as far as i'd hoped. Being a bit tired and not really into it didn't really help I guess.
First major problem I hit was that the linker doesn't allocate bss blocks for relocatable files by default, which I only discovered after a lot of faffing about. This and a few other issues made me decide to create a simpler linker script which I was trying to avoid. Since I have it now I'm using the linker script to merge some of the c-runtime support sections and epiphany sections with the base sections, and rename some of the epiphany sections to something i can use more readily in the loader (e.g. IVT_RESET to .ivt0).
It still didn't work. Which took a lot of tracking down ... and turned out to be an annoying bug with the way I was resolving the address of a remote-core array. I had defined the weak external reference as a pointer type and was just passing it to e_get_global_address - I should have passed the address of the variable instead. Live and learn I suppose, or maybe not. This is the second time I've wasted a good chunk of time on something like this so it's probably something I need to macro/functionise if I can.
But once I worked that out it suddenly started working.
Single-pass resampler
I'm working on a single-pass image resampler. It's something I need for the FD code, and a nice parallel problem which should fit a grid of EPUs nicely to boot. It's also a good test case for the relocating elf loader code i have.
input rows
|
+-------------+-------------+-------------+
| | | |
+-----------+ +-----------+ +-----------+ +-----------+
| scale x 0 | | scale x 1 | | scale x 2 | | scale x 3 |
+-----------+ +-----------+ +-----------+ +-----------+
| | | |
+-----------+ +-----------+ +-----------+ +-----------+
| scale y 0 | | scale y 1 | | scale y 2 | | scale y 3 |
+-----------+ +-----------+ +-----------+ +-----------+
| | | |
+-------------+-------------+-------------+
|
output rows
Workgroup topology' (transposed)
The input stage comprises of 4 cores in a column which load in 1/4 of a row of the input stream at a time and scale it in X - the results are written directly to the next stage in the pipeline.
The y scalers then perform y scaling on the input rows, and output directly to the target.
Because there are a lot of fiddly edge cases I just started with the data-flow code with an X-only scaling case to nearest neighbour (simplifies the y-scaling logic), but the intention is to end up with (at least) bi-cubic resampling. For this reason the Y scalers contain 'some' number of rows which will be greater than one organised in a cyclic buffer - so they can double-buffer with the X scaler and support higher-order resampling. I'm only using 4+4 cores mostly for simplicity but I may also have a use for the other 8. I don't know yet if the workload will balance well with a 1:1 mapping like this - in any event it will be dynamic based on the problem (e.g. x scaler always runs on each input row, by the y scaler only needs to run on each output row), and even if it isn't 100% efficient it should be goodly-efficient[sic].
So as of now I have the basic data-flow working. I'm using an 'eport' for the throttling/arbitration of the Y buffers and by organising the input stage in a column the DMA reads are fair without further work. This also gives me a simple platform to determine how important write DMA arbitration is, although I haven't included it yet.
As the Y stage can have multiple rows of storage (memory permitting) the same structure can be used for separable convolution, wavelets, etc. I can also be extended to high quality rotation and even to general purpose affine resampling - which I may look at eventually.
PicFX out
I did a bit of a clean, a README, some (not very good) tweaks to the layout files for a high dpi phone vs 7" tablet, and just checked in the code into:
I haven't cross-checked by building from a clean checkout from scratch so there could be some missing bits: i'll check when I can. I've also only built it on Fedora with some slightly older-than-current version(s) of the android ndk/sdk.
My previous post has some screenshots which are representative of the state of the code.
I did have grander plans but between my main work and it being a bit of a weird-arsed year and they didn't make it. However apart from some minor layout issues on small screens and the lack of capabilities, the basic operation and backend design i'm fairly pleased with for a couple of weeks work spread over 5 months.
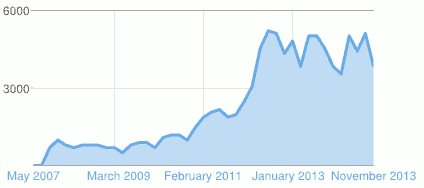
100K
In the next hour or so or whilst i'm wrting this (under 15 to go), this blog will hit 100K pageviews over it's lifetime; since early 2007.
So seems like a good time for another update - the last 50K certainly happened a lot faster than the first.
It bumbled along till about this time of the year in 2011 and then bumbled along at a higher level ever since. The big leap was from being added to the JavaFX feed surreptitiously IIRC, and it's been propped up lately from the occasional twat from the parallella devs.
I'm pretty sure a good proportion of it is just search engines and web crawlers, and lately a sharp rise in link spammers. I'm not sure why as the number of pages grows the page hits don't. Maybe it's because of these automaton views, or just because the web itself grows at a similar rate. I'm still occasionally dissapointed to see my blog show up too near the front when I try to whittle down a search on a topic (i.e. am i the only person in the whole world looking at that problem?), although that hasn't happened much lately.
I don't have the data to show it (maybe i can get it off analytics, but that doesn't cover the whole range and i'm not that narcissistic), but the general ebb and flow i've seen over a week suggests most human readers are reading the blog during the work-week and not on the weekends. Which is a bit of a bummer since almost the whole blog is about a hobby. If i were to guess: students appropriating work as their own, programmers looking for free code, and probably a good bit of general skiving.
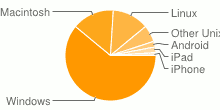
Just looking into some of the stats is a bit weird to be honest. The operating system skew for instance. I absolutely detest Apple Macintosh computers, yet that seems to have led to a pretty significant proportion. I think there might be some scientific Java and OpenCL programmers lending their weight to that stat. Good to see a decent 17% or so on some sort of Unix at least.
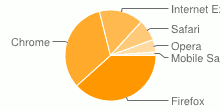
The browser share is also likewise atypical of the internet as a whole. Although personally I don't find the appeal of Google Chrome - not that Mozilla Firefox isn't without it's considerable problems mind you. Poor little IE, sucked in you pile of shit.
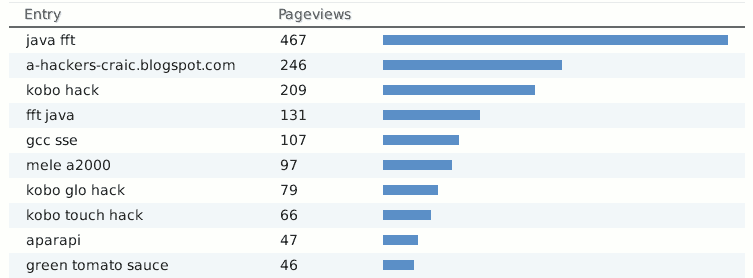
Because the search terms list has such a long tail it's hard to really tell what is bringing people here - but "java fft" continues to be the clear leader. The second is no doubt just an automatic browser resolving an invalid url (hint: url's start with the protocol ...), and kobo seems popular (is, below). Nice to see at least one other type of open sauce made the list too. Unfortunately spikes in the stats tend to hang around forever.
All I can think of is that there's a lot of people with kobo's that don't want adverts or to pay for books. Which is an attitude i can fully agree with, they just wont get anything to help them with that here. The OpenCL post in there is also not particularly useful, but who can tell what people find interesting.
I think the main reason I continue to blog is simply for the cartharsis of it. I don't care if people think i'm a bit nutty, a total cunt and a boorish prick, or if i'm really just talking to a wall. I'm not terribly interested in using this format for holding a conversation with peers and even less so with freeloaders; which is just as well as I haven't had much of that - I just got my 200th comment this minute infact.
Well, on to the future I guess.
lambdas to the slaughter ...
Had a look at a couple of the videos from the AMD developer summit going on at the moment. One was about how Java is a pretty good fit with the heterogeneous (i'm a bit sick of typing that word already) world. A short demo by Gary Frost of aparapi fame got me to finally pull my finger out and finally have a look at lambdas and how they work. Half an hour of hacking later and I think i've pretty much sussed them out for what i'm interested in!
As i've mentioned several times on the blog and elsewhere i'm pretty excited about the possibilities HSA provide, and i'm still surprised at how good a fit Java is for it - all because of the JVM and that 'pesky' bytecode and a few -very well thought out- language extensions. Until now I just haven't really had the time to look into them and have been limited by using JDK 7 as well. I'm also worried that once I use it I wont want to go back to the old way of doing things ...
I'm still using netbeans 7.3 so the lambda support is shit (totally nonexistant) but I played a little bit with a few things ...
Took me a while to realise when you iterate an array you don't iterate the items but the indices, but once that was out of the way it was plain sailing. Also had a look at 2d iteration as well. Some surprising results.
So a simple loop:
for (int i=0;i<a.length;i++) {
a[i] = sqrt(a[i] * b[i]);
}
Can become:
IntStream.range(0, a.length).forEach(i -> a[i] = sqrt(a[i] * b[i]));
(I'm not really a big fan of the syntax which hides so many details, but whatever).
Knowing that the lambda expression is converted to a private function suggests it should run slower, but thanks to the jvm ... it runs just about as fast as the simple array - infact with some tests it was slightly faster (oddly). Which is nice - because simple arrays are fast.
However the real benefit comes when you can then utilise all cores on your cpu ... (or eventually ... gpu) ...
IntStream.range(0, a.length).parallel().forEach(i -> a[i] = sqrt(a[i] * b[i]));
Now it uses all CPU cores available on the machine and executes appropriately faster. Well that was hard?
So what about 2D loops? The supplied streams only create 1D sequences.
A typical 2D processing loop:
float[] values;
int width;
int height;
for (int y=0;y<height;y++) {
for (int x=0;x<width;x++) {
float v = values[x+y*width];
.. do something ..
}
}
Which is simple enough but if you type it several times a day for weeks it gets a bit tiring (i'm pretty fucking tired of it). And I rarely even bother to parallelise these things because it's just too much work and I keep writing new code too rapidly. I suppose I could come up with some class to encapsulate that and use a callback, but then it becomes a bit of a pain to use due to finals or an explosion in one-off worker classes.
In a lot of cases 1D operations as above on 2D arrays suffice (when the coordinates don't matter) but sometimes one needs the coordinates too. So my first-cut-worked-first-time approach was just to create a '2D' consumer interface and map the 1D index to 2D using the obvious maths:
public interface Consumer2D {
void accept(int x, int y);
}
public class Array2D {
float[] values;
int width;
int height;
public void parallelForeach(Consumer2D ic) {
IntStream.range(0, width*height).parallel().forEach(i -> {
int x = i % width;
int y = i / width;
ic.accept(x, y);
});
}
public float get(int x, int y) {
return values[x+y*width];
}
}
...
a.parallelForeach((x, y) -> {
float v = a.get(x,y);
... do something ...
});
Now one would think all that extra maths would make it "a bit slow", but at least for my simple tests the JVM must be optimising it to pretty much the same code as it executes at the same speed ... as the straight 1D version!
Nice.
One still has to be somewhat cognent of the pitfalls of concurrent processing so it doesn't really make the solutions any easier to come up with, but at least it throws out a pile ... a big big pile ... of boilerplate ... which means you don't even have to think about the mechanics anymore and can focus on the maths. And that's only talking about CPU resources, trying to leverage a GPU is even worse (well in some respects it's easier because the job concurrency is automatic, but in other's it's much more painful do the native api's and data conversion). I still think there will be applications where OpenCL is useful (all that LDS bandwidth) - hopefully HSA will make that work nicer with Java as well in the future.
Damn, once I get used to this, Android and it's fucked up ancient shitty version of Java-esque is going to suck even more than it does already.
The other thing I still have to wait for is that HSA capable hardware, hopefully a decent minipc / laptop is available in Australia when they finally arrive early next year. And that it all works properly in Linux.
There's also an effort to port the same stuff to the parallella board, and it will be interesting to see how well that works in practice. I'm keeping an eye on it but it's a bit out of my area of expertise/current interests to help more than that right now.
Who'd have thunk Java being completely in it's own league when it came to support for massive parallelism and the high performance it can provide?
PS on another note it's interesting to see the latest GPUs are becoming completely bounded by both power and heat requirements - given the designs are now quite mature and advanced and there isn't much scope for performance increases due to architectural improvements as there has been in the past. Has a practical total-flop ceiling been hit outside of process changes (and how much can they even provide with the head dissipation issue)? The move to trying to improve utilisation via software improvements - HSA, Mantle, and so on - will only help so far - the more efficiently you utilise these chips the hotter they get too. Food for thought.
Little tool things & anim stuff
I was poking around at making a simple map viewer in a way that works directly with tiled output mainly as a way to see the animation stuff in motion. But I looked a bit further at using it for some other map related things.
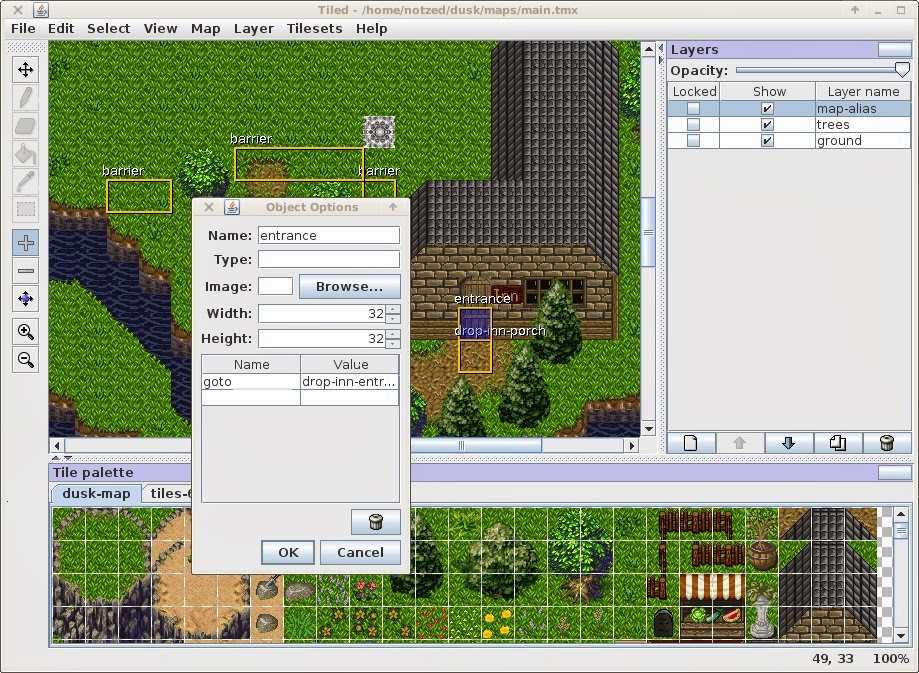
I store everything in a jar file - from a set of pngs for the tilesets, to the multi-layered map, the tile 'script' information, and I just had a quick 15 minute poke to see how to add the location based script information shown here as well. This allows one to define some basic behaviour like impassable barriers, doors/portals, and calls out to scripts directly in the tiled.
per-tile properties allow one to define impassable/un"stand"able objects, or calls to scripts, and the animation sequences - i'm still coming up with a simple enough design for the last point, but it will probably be something like:
anim=group,step[,duration]
Where group is symbolic, step is a sequence number, and the duration is the number of milliseconds per step taken from the tile with a step of 0. To make a tile animatable, one draws using the tile with step 0. This allows the same tiles to be used in different animation sequences so long as step 0 is unique. I'm still debating whether i have an extra layer of indirection and define animation sets which operate together to ensure they are always in sync. However i'm not sure it's worth the complication as I think the lower level animation system can ensure that anyway.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!