About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Saturday arvo elf-loader hack-a-thon
So I hacked a bit more of the elf loader today. Initially it was just documenting where I got to so I could work out where to go next. I wrote up a bit more background and detail on how it works. Then I cleared out the out of date experimental stuff and focussed on the ez_ interfaces.
But then I got a bit side-tracked ...
Compact startup
First I thought i'd see if i could replace crt0 with my own. Apart from an initialisation issue with bss and data there isn't really anything wrong with the bundled one ... apart from it dragging in a bunch of C support stuff which isn't necessary if writing small kernel code that doesn't need the full libc.
So I took the crt0.s and stripped out a bunch of stuff. The trampoline to a potentially off-core start routine (it's going to be on-core). The atexit init (not necessary). The constructors init (hopefully not necessary). The .bss clearing (it's problematic when you have possibly more than one block of bss such as shared and given that .data isn't re-initialised anyway the C language behaviour is already broken). And the argument setting (three zero's isn't useful for anything and isn't even correct).
I toyed with the idea of passing arguments to kernel but decided to just have a void main instead.
I just pass -nostartfiles e-crt0minimal.o to the link line to replace the standard start-up code.
e-gcc -Wl,-r -o e-test-reloc.elf -nostartfiles e-crt0minimal.o e-test-reloc.o -le-lib
Worth it? Probably ...
Minimal crt0:
$ e-size e-test-workgroup-a.elf
text data bss dec hex filename
548 64 120 732 2dc e-test-workgroup-a.elf
Standard crt0:
$ e-size e-test-workgroup-a.elf
text data bss dec hex filename
1418 1196 128 2742 ab6 e-test-workgroup-a.elf
When you've only got 32K to play with saving 2K isn't to be sniffed at.
Matching addresses (aka fake hsa)
Next I looked at just using mmap to map the shared memory so pointers can be shared between the epiphany and the host arm directly. I tried to use e_get_platform_info() to get the list of memory blocks but for some odd reason that zeros out the memory array pointer? Odd. So ... I just access the struct directly via an extern instead.
This is just an implementation of stuff from a previous post but using the platform_info to find the addresses.
I have no idea whether this will work on a multi-epiphany setup but since I don't have one it's not something i'll lose sleep over :)
*COM* symbols
About this point I noticed that some symbols weren't being allocated any location in the output file and thus could not be resolved during the loader-linker execution. These were symbols marked with the section id of COMMON. I had hit this before but I had forgotten all about it. Last time I solved it using a linker script but I found I can just pass '-d' to the linker to achieve the same result which puts any such values into bss.
Automatic remote-core on-chip symbol resolution
Then I had a look into implementing fully automatic resolution of remote but on-chip symbols. The options are limited but the desired target core can be indicated by the symbol name.
For example:
program a:
extern int buffer[12];
program b:
// current cell relative +0, +1
extern int buffer_0_1[12];
// group relative 0,1
extern int buffer$0$1[12];
Or some variation thereof. This is easy enough to parse and implement, and not too ugly to use.
But it would mean that the binary for every core would need to be linked individually and thus it wouldn't be possible to just copy the same code across to multiple cores when they share the implementation. For this reason I've dropped the idea for now. Having to use e_get_global_address() on a weak symbol isn't too difficult.
'easy' elf loader for parallella
I prettied up some of the stuff I did a few months ago on the parallella code loader and uploaded it to the home page.
It is still very much work in progress (just a bunch of experiments) but it is currently able to take several distinct epiphany-core programs and relocate and cross-link them to any on-core topology - at runtime. Remote addresses in other cores can be partially resolved automatically (to the local core address offset - suitable for e_get_global_address()) by using weak symbols and the host can resolve symbols by name. By default sections go on-core but .section directives can redirect individual records to specific banks or to global memory. bss/text/data are all supported for any such section using standard names (no 'code' sections!).
Linker scripts are not needed for any of this and the only 'special sauce' is that the epiphany binaries be linked with -r. I mention this because this was the primary driving factor for me to write any of this. I would probably like to replace crt0 as well but that is something for the future (basically remove the bss init stuff).
When I next poke at it I want to work toward wrapping it in an accessible Java API. There is a bit to be done before that though (I think - it's been a while since I looked at it).
thoughts on opencl + array methods
I was going to have a quick look at removing the erroneous asynchronous Get/SetPrimitiveArrayCritical() stuff from zcl this morning but I've hit a complication too far for my tired brain.
I changed to just allocating a staging buffer and using Get/Set*ArrayRegion() for the read/writeBuffer commands. I only allocate enough memory for the transfer and copy the transfer size around and so on. It's a bit bulky but it's fairly straightforward.
Then I started looking at the image interfaces and realised doing the same thing is somewhat more complex - either I have to copy the whole array to/from the staging buffer to/from each time (if the get/set updates on a portion of the image for example) or I have to flatten the transfer myself. The former pretty much makes the function pointless and the latter bulks out the binding and may require lots of jvm calls.
So now i'm deciding whether I just force synchronous transfers for all array interfaces because they probably have some use despite synchronisation being the mind-killer, or just deleting them altogether to drop a ton of code. Since i've already got all the code the former will probably be the approach I take. The event callback stuff i'm using to finish up the transaction seems pretty expensive anyway so there may not be much net difference (against a net use count of zero for the library, at that - it's just something to pass the time).
On another note I decided to use cvs as my local repository backend to store this stuff. I think the all-day-never-finished checkout of gcc finally tipped me over but I never liked subversion because it's too slow and is just shit at merging. I was surprised netbeans detected it and offered to install the cvs plugin automatically (and i was a little surprised it was already installed too). I don't need or want to use tools that weren't designed for my use-case.
Ho hum, back to work Tuesday. My boss actually apologised for taking so long to get the contract sorted but yeah, i'm not complaining! Looks like it'll mostly be a continuation of one of the projects i'm not terribly keen on too. Bummer I guess. All I really care about right now is sleep though.
Update: (I kept poking) I just removed the async handling code and force a blocking call. Get/SetPrimitiveArrayCritical() is used to access the arrays directly. I'll do a release another day though.
sumatra, graal, etc.
I didn't really wanna get stuck building stuff all day but that seems to have happened.
Sumatra uses auto* so it built easily no problem. Bummer there's no javafx but hopefully that isn't far off.
graal is a bit of a pain because it uses a completely custom build/update/everything mega-tool written in a single 4KLOC piece of python. Ok when it works but a meaningless backtrace if it doesn't. Well it is early alpha software I guess. Still ... why?
Anyway ... I tried building against 'make install' from sumatra but that doesn't work, you need to point your JAVA_HOME at the Sumatra tree as the docs tell you to. My mistake there.
So it turns out getting the hsail tools to build had some point after-all. The hsailasm downloaded by the "build" tool (in lib/okra-1.8-with-sim.jar) wont work against the libelf 0.x included in slackware (might be easier just building libelf 1.x). So I added the path to the hsailasm I built myself ... and ...
export PATH=/home/notzed/hsa/HSAIL-Instruction-Set-Simulator/build/HSAIL-Tools:$PATH
./mx.sh --vm server unittest -XX:+TraceGPUInteraction \
-XX:+GPUOffload -G:Log=CodeGen hsail.test.IntAddTest
[HSAIL] library is libokra_x86_64.so
[HSAIL] using _OKRA_SIM_LIB_PATH_=/tmp/okraresource.dir_7081062365578722856/libokra_x86_64.so
[GPU] registered initialization of Okra (total initialized: 1)
JUnit version 4.8
.[thread:1] scope:
[thread:1] scope: GraalCompiler
[thread:1] scope: GraalCompiler.CodeGen
Nothing to do here
Nothing to do here
Nothing to do here
version 0:95: $full : $large;
// static method HotSpotMethod
kernel &run (
align 8 kernarg_u64 %_arg0,
align 8 kernarg_u64 %_arg1,
align 8 kernarg_u64 %_arg2
) {
ld_kernarg_u64 $d0, [%_arg0];
ld_kernarg_u64 $d1, [%_arg1];
ld_kernarg_u64 $d2, [%_arg2];
workitemabsid_u32 $s0, 0;
@L0:
cmp_eq_b1_u64 $c0, $d0, 0; // null test
cbr $c0, @L1;
@L2:
ld_global_s32 $s1, [$d0 + 12];
cmp_ge_b1_u32 $c0, $s0, $s1;
cbr $c0, @L12;
@L3:
cmp_eq_b1_u64 $c0, $d2, 0; // null test
cbr $c0, @L4;
@L5:
ld_global_s32 $s1, [$d2 + 12];
cmp_ge_b1_u32 $c0, $s0, $s1;
cbr $c0, @L11;
@L6:
cmp_eq_b1_u64 $c0, $d1, 0; // null test
cbr $c0, @L7;
@L8:
ld_global_s32 $s1, [$d1 + 12];
cmp_ge_b1_u32 $c0, $s0, $s1;
cbr $c0, @L10;
@L9:
cvt_s64_s32 $d3, $s0;
mul_s64 $d3, $d3, 4;
add_u64 $d1, $d1, $d3;
ld_global_s32 $s1, [$d1 + 16];
cvt_s64_s32 $d1, $s0;
mul_s64 $d1, $d1, 4;
add_u64 $d2, $d2, $d1;
ld_global_s32 $s2, [$d2 + 16];
add_s32 $s2, $s2, $s1;
cvt_s64_s32 $d1, $s0;
mul_s64 $d1, $d1, 4;
add_u64 $d0, $d0, $d1;
st_global_s32 $s2, [$d0 + 16];
ret;
@L1:
mov_b32 $s0, -7691;
@L13:
ret;
@L4:
mov_b32 $s0, -6411;
brn @L13;
@L10:
mov_b32 $s0, -5403;
brn @L13;
@L7:
mov_b32 $s0, -4875;
brn @L13;
@L12:
mov_b32 $s0, -8219;
brn @L13;
@L11:
mov_b32 $s0, -6939;
brn @L13;
};
[HSAIL] heap=0x00007f47a8017a40
[HSAIL] base=0x95400000, capacity=108527616
External method:com.oracle.graal.compiler.hsail.test.IntAddTest.run([I[I[II)V
installCode0: ExternalCompilationResult
[HSAIL] sig:([I[I[II)V args length=3, _parameter_count=4
[HSAIL] static method
[HSAIL] HSAILKernelArguments::do_array, _index=0, 0xdd563828, is a [I
[HSAIL] HSAILKernelArguments::do_array, _index=1, 0xdd581718, is a [I
[HSAIL] HSAILKernelArguments::do_array, _index=2, 0xdd581778, is a [I
[HSAIL] HSAILKernelArguments::not pushing trailing int
Time: 0.213
OK (1 test)
Yay? I think?
Maybe not ... it seems that it's only using the simulator. I tried using LD_LIBRARY_PATH and -Djava.library.path to redirect to the libokra from the Okra-Interface-to-HSA-Device library but that just hangs after the "base=0x95..." line after dumping the hsail. strace isn't showing anything obvious so i'm not sure what's going on. Might've hit some ubuntu compatibility issue at last or just a mismatch in versions of libokra.
On the other hand ... it was noticeable that something was happening with the gpu as the mouse started to judder, yet a simple ctrl-c killed it cleanly. Just that alone once it makes it into OpenCL will be worth it's weight in cocky shit rather than just hard locking X as is does with catalyst.
Having just typed that ... one test too many and it decides to crash into an unkillable process and do weird stuff (and not long after I had to reboot the system). But at least that is to be expected for alpha software and i've been pretty surprised by the overall system stability all things considered.
I think next time I'll just have a closer look at aparapi because at least I have that working with the APU and i'm a bit sick of compiling other peoples code and their strange build systems. Sumatra and graal are very large and complex projects and a bit more involved than I'm really interested in right now. I haven't used aparapi before anyway so I should have a look.
If the slackware vs ubuntu thing becomes too much of a hassle I might just go and buy another hdd and dual-boot; I already have to multi-boot to switch between opencl+accelerated javafx vs apu.
Update: Actually there may be something more to it. I just tried creating my own aparapi thing and it crashed in the same way so maybe i was missing some env variable or it was due to a suspend/resume cycle.
So I just had another go at getting the graal test running on hsail and I think it worked:
export JAVA_HOME=/home/notzed/hsa/sumatra-dev/build/linux-x86_64-normal-server-release/images/j2sdk-image
export PATH=${JAVA_HOME}/bin:${PATH}
export LD_LIBRARY_PATH=/home/notzed/hsa/Okra-Interface-to-HSA-Device/okra/dist/bin
./mx.sh --vm server unittest -XX:+TraceGPUInteraction -XX:+GPUOffload -G:Log=CodeGen hsail.test.IntAddTest
[HSAIL] library is libokra_x86_64.so
[GPU] registered initialization of Okra (total initialized: 1)
JUnit version 4.8
...
Time: 0.198
OK (1 test)
Still, i'm not sure what to do with it yet ...
I was going to have a play today but I just got the word on work starting again (I can probably push it out to Monday) so I might just go to the pub or just for a ride - way too nice to be inside getting monitor burn. I foolishly decided to walk into the city yesterday for lunch with a mate I haven't seen for years (and did a few pubs on the way home - i was in no rush!) but just ended up with a nice big blister and sore feet for my troubles. It's about a 45 minute walk into the city but I don't do much walking.
I want see if anything interesting comes out of the Sony's GDC talk first though (the vr one? - yes the VR one, it's just started).
And ... done. Interesting, but still early days. Even if they release a model for the public at a mass-market price it's still going to have to be a long term project. Likely the first 5-10 years will just be experimentation and getting the technology the point where it is good and cheap enough.
Update: Yep, i'm pretty sure it's just a problem with suspend/resume. I just tried running it after a resume and it panicked the kernel.
Building the hsail tools.
I had a lot more trouble than this post suggests getting this stuff to compile which is probably why i sound pissed off (hint: i am, actually pro tip: i often am), but this summarises the results.
I started with the instructions in README.hsa from the hsa branch of gcc. See the patches below though.
I installed libelf from slackware 14.1 but had to build libdwarf manually. I got libdwarf-20140208 from the libdwarf home page. I actually created a SlackBuild for it but i'm uncertain about providing it to slackbuilds.org right now (mostly because it seems a bit too niche).
Then this should probably work:
mkdir hsa
cd hsa
git clone --depth 1 https://github.com/HSAFoundation/HSAIL-Instruction-Set-Simulator.git
git clone --depth 1 https://github.com/HSAFoundation/HSAIL-Tools
cd HSAIL-Instruction-Set-Simulator/src/
ln -s ../../HSAIL-Tools
cd ..
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Debug ..
make -j3 _DBG=1 VERBOSE=1
Actually I originally built it from the Okra-Interface-to-HSAIL-Simulator thing, but that checks out both of these tools as part of it's android build process together with the llvm compiler this does. Ugh. And then proceeds to compile whilst hiding the details of what it's actually doing and simultaneously ignoring-all-fatal-errors-along-the-way through the wonders of an ant script. Actually I could add more but I might offend for no purpose - afterall I did get it compiled in the end. I'm just a bit more impatient than I once was :)
Patches
It doesn't look for libelf.h anywhere other than /usr/include so I had to add this to HSAIL-Instruction-Set-Simulator. Of course if you have lib* in /usr/local you have to change it to that instead. Sigh. I thought this sort of auto-discovery was a solved problem.
diff --git a/CMakeLists.txt b/CMakeLists.txt
index 083e9c6..c86192c 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -25,8 +25,9 @@ set(CMAKE_CXX_FLAGS "-DTEST_PATH=${PROJECT_SOURCE_DIR}/test ${CMAKE_CXX_FLAGS}")
set(CMAKE_CXX_FLAGS "-DBIN_PATH=${PROJECT_BINARY_DIR}/HSAIL-Tools ${CMAKE_CXX_FLAGS}")
set(CMAKE_CXX_FLAGS "-DOBJ_PATH=${PROJECT_BINARY_DIR}/test ${CMAKE_CXX_FLAGS}")
set(CMAKE_CXX_FLAGS "-I/usr/include/libdwarf ${CMAKE_CXX_FLAGS}")
+set(CMAKE_CXX_FLAGS "-I/usr/include/libelf ${CMAKE_CXX_FLAGS}")
-set(CMAKE_CXX_FLAGS_RELEASE "-O3 -UNDEBUG")
+set(CMAKE_CXX_FLAGS_RELEASE "-O2 -UNDEBUG")
# add a target to generate API documentation with Doxygen
find_package(Doxygen)
And because I used a newer version of libdwarf than ubuntu uses it has a world-shattering fatal error causing difference in one of the apis.
Apply this to HSAIL-Tools.
diff --git a/libHSAIL/libBRIGdwarf/BrigDwarfGenerator.cpp b/libHSAIL/libBRIGdwarf/BrigDwarfGenerator.cpp
index 7e2d28d..fe2bc51 100644
--- a/libHSAIL/libBRIGdwarf/BrigDwarfGenerator.cpp
+++ b/libHSAIL/libBRIGdwarf/BrigDwarfGenerator.cpp
@@ -261,7 +261,7 @@ public:
//
bool storeInBrig( HSAIL_ASM::BrigContainer & c ) const;
- int DwarfProducerCallback2( char * name,
+ int DwarfProducerCallback2( const char * name,
int size,
Dwarf_Unsigned type,
Dwarf_Unsigned flags,
@@ -459,7 +459,7 @@ bool BrigDwarfGenerator_impl::generate( HSAIL_ASM::BrigContainer & c )
// *sec_name_index is an OUT parameter, a pointer to the shared string table
// (.shrstrtab) offset for thte name of the section
//
-static int DwarfProducerCallbackFunc( char * name,
+static int DwarfProducerCallbackFunc( const char * name,
int size,
Dwarf_Unsigned type,
Dwarf_Unsigned flags,
@@ -476,7 +476,7 @@ static int DwarfProducerCallbackFunc( char * name,
}
int
-BrigDwarfGenerator_impl::DwarfProducerCallback2( char * name,
+BrigDwarfGenerator_impl::DwarfProducerCallback2( const char * name,
int size,
Dwarf_Unsigned type,
Dwarf_Unsigned flags,
I had to use the 'git registry' to disable coloured diffs so I could just see what I was even doing here.
git config --global color.ui false
Whomever thought that sort of bloat was a good idea in such a tool ... well I would only offend if i called him or her a fuckwit wouldn't i?
hsa, gcc hsail + brig
I didn't spend much time on it yesterday but most of it was just reading up on hsa. There's only a few slides plus a so-shittily-typeset-is-has-to-be-microsoft-word reference manual on hsail and brig. As a bonus it includes some rather poor typeface choices (too stout - the trifecta of short, thick, and fat), colours, and tables to complement the word-wrap that all say to me 'not for printing' (not that I was going to). The link to the amd IOMMUv2 spec is broken - not that i'm likely to need that. Bit of a bummer as amd docs are usually formatted pretty well and they seem to be the primary driver at this point. In general the documentation 'needs work' (seems to be my catchphrase of 2014 so far) although new docs and tools seem to be appearing in drips and drops over time.
I'd already skimmed some of it and had a general understanding but I picked up a few more details.
The queuing mechanism looks pretty nice - very simple yet able to do everything one needs in a multi-core system. I had been under the impression that the queue system had / needed some hardware support on the CPU too but looking at it but it doesn't look necessary so was just a misunderstanding. Or ... maybe it's not since any work signalling mechanism would ideally avoid kernel interactions and/or busy waiting - either or both of which would be required for a purely software implementation. But maybe it's simpler than that
To be honest i would have preferred that hsail was a proper assembly language rather than wrapping the meta-data in a pseudo-C++ syntax. And brig seems a bit unnecessarily on the bulky side for what is essentially a machine code encoding. At the end of the day neither are deal breakers.
The language itself is kind of interesting. Again I thought it was a slightly higher level virtual-processor that it is, something like llvm's intermediate representation or PTX. But it has a fixed maximum number of registers and the register assignment and optimisation occurs at the compiler stage and not in the finaliser - looks a lot more like say DEX than IR or Java bytecode. This makes a lot of sense unless you have a wildly different programming model. Seems a pretty reasonable and pragmatic approach to a universal machine code for modern processors.
The programming and queuing model looks like something that should fit into Epiphany reasonably well. And something that can be used to implement OpenCL with little work (beyond the compiler, but there's few of those already).
GCC
I managed to get gcc checked out to build. The hsa tools page just points to the subversion branch with no context at all ... but after literally 8 hours trying to check it out and only being part-way through the fucking C++ standard library test suite, I gave up (I detest git but I'm no fan of subversion by any stretch of the imagination). I had to resort to the git mirror. Unfortunately gcc takes a lot longer to build than last time I had to despite having faster hardware, but that's 'progress' for you (no it's not).
I'm not sure how useful it is to me as it just generates brig directly (actually a mash up of elf with amd64 + brig) and there's no binutils to play with hsail that I can tell. But i'll document the steps I used here.
git clone --depth 1 -b hsa git://gcc.gnu.org/git/gcc.git
mkdir build
cd build
../gcc/configure --disable-bootstrap --enable-languages=c,c++ --disable-multilib
make
Slackware 64 is only 64-bit so I had to disable multilib support.
The example from gcc/README.hsa can then be compiled using:
cd ..
mkdir demo
cd demo
cat > hsakernel.c
extern void square (int *ip, int *rp) __attribute__((hsa, noinline));
void __attribute__((hsa, noinline)) square (int *in, int *out)
{
int i = *in;
*out = i * i;
}
CTRL-D
../build/gcc/xgcc -m32 -B../build/gcc -c hsakernel.c -save-temps -fdump-tree-hsagen
Using -fdump-tree-hsagen outputs a dump of the raw HSAIL instructions generated.
[...]
------- After register allocation: -------
HSAIL IL for square
BB 0:
ld_kernarg_u32 $s0, [%ip]
ld_kernarg_u32 $s1, [%rp]
Fall-through to BB 1
BB 1:
ld_s32 $s2, [$s0]
mul_s32 $s3, $s2, $s2
st_s32 $s3, [$s1]
ret_none
[...]
Went through the gcc source and found a couple of useful bits. To get the global work-id I found you can use: __builtin_omp_get_thread_num() which compiles into workitemabsid_u32 ret,0. And __builtin_omp_get_num_threads() which compiles into gridsize_u32 ret,0. Both only work on dimension 0. And that seems to be about it for work-group functions.
I'm not really sure how useful it is and unless the git mirror is out of sync there hasn't been a commit for a few months so it's hard to know it's future - but it's there anyway.
My understanding is that a reference implementation of a finaliser will be released at some point which will make BRIG a bit more interesting (writing one myself, e.g. for epiphany, is a bigger task than i'm interested in right now). I'm probably going to have more of a look at aparapi and the other java stuff for the time being but eventually get the llvm based tools built as well. But ugh ... CMake.
Aparapi on HSA on Slackware on Kavaeri on ASROCK
Although i've been waiting with bated breath for HSA to arrive ... the last I heard about a month ago via the aparapi mailing list was that the drivers weren't quite ready yet. So I was content to wait patiently a bit longer. Then somehow the first I heard that the alpha became available from one of the few comments on this blog and apparently it's been out for a few weeks. I couldn't find any announcement about it?
So yesterday before I went out and this morning I followed Linux-HSA-Drivers-And-Images-AMD and SettingUpLinuxHSAMachineForAparapi trying to get something working. As i'm using a different motherboard and OS it was a little more involved although I made it more involved than it should've been by making a complete pigs breakfast out of every step along the way due to being a bit out of practice.
But after getting a working kernel built and X sorted I just ran the test example a few seconds ago:
$ ./runSquares.sh
using source from Squares.hsail
0->0, 1->1, 2->4, 3->9, 4->16, 5->25, 6->36,
;7->49, 8->64, 9->81, 10->100, 11->121,
;12->144, 13->169, 14->196, 15->225, 16->256,
;17->289, 18->324, 19->361, 20->400, 21->441,
;22->484, 23->529, 24->576, 25->625, 26->676,
;27->729, 28->784, 29->841, 30->900, 31->961,
;32->1024, 33->1089, 34->1156, 35->1225, 36->1296,
;37->1369, 38->1444, 39->1521,
PASSED
$
I'm presuming 'PASSED' means it worked.
I'm not sure how much i'll do today but i'll next look at the hsa branch of aparapi, sumatra?, and then I want to look a bit closer. I haven't been able find much detailed technical documentation yet but there is the kernel driver at least now and hopefully it's coming soon.
On Slackware
I'm using the ASROCK FM2A88X-ITX+ motherboard with Slackware64 14.1 and using the DVI and HDMI outputs in a dual-head configuration. Just getting Slackware 14.1 working on it reliably required a BIOS upgrade but i'm not sure what version it is right now.
To compile a fresh checkout of the correct kernel I tried the supplied kernel config file 3.13.0-config at first but that didn't work it just hung on the loading kernel line from elilo. After a couple of aborted attempts I managed to get a working kernel by starting with /boot/config-generic-3.10.17 as the .config file, running make oldconfig and holding down return until it finished to accept all the defaults, then using make xconfig to make sure my filesystem driver wasn't a module (which i of course forgot the first time).
Getting dual-screen X was a bit confusing - searches for xorg.conf configuration is pretty much a waste of time I think mostly because every config file is filled with non-important junk. But I finally managed to get it going even if for whatever reason it comes up in cloned mode but I can fix it manually running xrandr after i login. Because I'm not ready to make this permanent is good enough for me. As I was previously using the fglrx driver I had initially forgotten to de-blacklist the radeon kernel module but that was an easy fix.
This is how I set up the screen config.
$ xrandr --output HDMI-0 --right-of DVI-0
I'm not ready to make this my system yet because afaik OpenCL isn't available for this driver interface yet. Although the Okra stuff includes libamdhsacl64.so so presumably it isn't too far away.
Aparapi
I got aparapi going quite easily.
But beware, don't run '. ./env.sh' directly to start with - any error and it just closes your shell window! So test with 'sh ./env.sh' until it passes it's checks.
I used the ant that comes with netbeans and I already had AMD APP SDK 2.9 and Java 8 installed.
Not sure if it's needed but I noticed a couple of variables were blank so I set them in env.sh.
export APARAPI_JNI_HOME=${APARAPI_HOME}/com.amd.aparapi.jni
export APARAPI_JAR_HOME=${APARAPI_HOME}/com.amd.aparapi
Once env.sh was sorted it built in a few seconds and the mandelbrot demo ran in suitably impressive fashion.
Well this should all keep me busy for a while ...
JNI, memory, etc.
So a never-ending hobby has been to investigate micro-optimisations for dealing with JNI memory transfer. I think this is at least the 4th post dedicated soley to the topic.
I spent most of the day just experimenting and kinda realised it wasn't much point but I do have some nice plots to look at.
This is testing 10M calls to a JNI function which takes an array - either byte[] or a ByteBuffer. In the first case these are pre-allocated outside of the loop.
The following tests are performed:
- Elements
-
Uses Get/SetArrayElements, which on hotspot always copies the memory to a newly allocated block.
- Range alloc
-
Uses Get/SetArrayRegion, and inside the JNI code always allocates a new block to store the transferred data and frees it on exit.
- Critical
-
Uses Get/ReleasePrimitiveArrayCritical to access the JVM memory directly.
- ByteBuffer
-
Uses the JNIEnv entry points to retrieve the memory base location and size.
- Range
-
Uses Get/SetArrayRegion but uses a pre-allocated (bss) buffer.
- ByteBuffer field
-
Uses GetLongField and GetIntField to retrieve the package/private address and size values directly from the Buffer object. This makes it non portable.
I'm running it on a Kaveri APU with JDK 1.8.0-b129 with default options. All plots are generated using gnuplot.
Update: I came across this more descriptive summary of the problem at the time, and think it's worth a read if you're ended up here somehow.
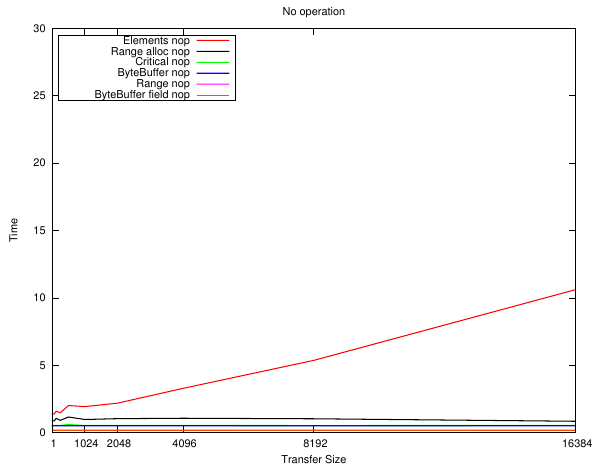
Small arrays
The first plot shows a 'no operation' JNI call - the pointer to the memory and the size is retrieved but it is not accessed. For the Range cases only the length is retrieved.
What can be seen is that the "ByteBuffer field" implementation has the least overhead - by quite a bit compared to using the JNIEnv entry points. From the hotspot source it looks like they perform type checks which are adding to the cost.
Also of interest is the "Range alloc" plot which only differs from the "Range" operation by a malloc()/free() pair. i.e. the JNI call invocation overhead is pretty much insignificant compared to how willy-nilly C programmers throw these around. This is also timing the Java loop as well of course. The "Range" call only retrieves the array size in this case although interestingly that is slower than retrieving the two fields.
The next series of plots are for implementing a dummy 'load'. The read load is to add up every byte in the array, and the write load is to write the array index to the array. It's not particularly important just that it accesses the memory.
Well, they're all pretty close and follow the overhead plot as you would expect them to. The only real difference is between the implementations that need to allocate the memory first - but small arrays can be stored on the stack 'for free'.
The only real conclusion is: don't use GetArrayElements() or malloc space for short arrays!
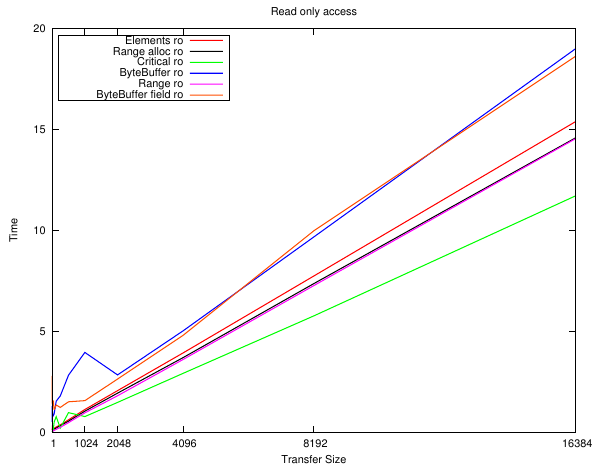
Larger arrays
This is the upper area of the same plots above.
Here we see that by 8K the overhead of the malloc() is so insignificant to the small amount of work being performed that it vanishes from the time - although GetArrayElements() is still a bit slower. The Critical and field-peeking ByteBuffer edge out the rest.
And now some strange things start to happen which don't seem to have an obvious reason. Writing the data to bss and then copying it using SetArrayRegion() has become the slowest ... yet if the memory is allocated first it is nearly the fastest?
And even though the only difference between the ByteBuffer variants is how it resolves Buffer.address and Buffer.capacity ... there is a wildly different performance profile.
And now even more weirdness. Performing a read and then a write ... results in by far the worst performance from accessing a ByteBuffer using direct field access, yet just about the best when going through the JNIEnv methods. BTW the implementation rules out most cache effects - this is exactly the same memory block at exactly the same location in each case, and the linearity of the plot shows it isn't size related either.
And now GetArrayElements() beats GetArrayRetion() ...
I have no idea on this one. I re-ran it a couple of times and checked the code but perhaps I missed something.
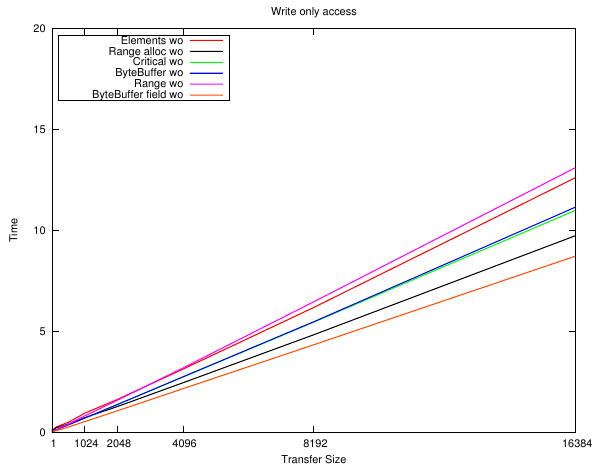
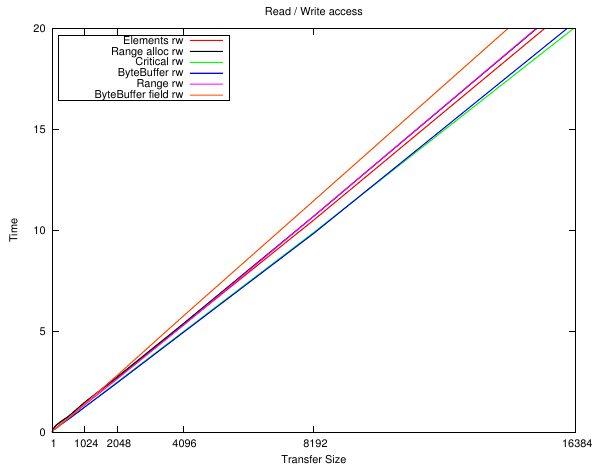
Dynamic memory
Perhaps it's just not a very good benchmark. I also tried an extreme case of allocating the Java memory inside the loop - which is another extreme case. At least these should give some bracket.
Here we see Critical running away with it, except for the very small sizes which will be due to cache effects. The ByteBuffer results show "common knowledge" these things are expensive to allocate (much more so than malloc) so are only suitable for long-lived buffers.
Again with the SetArrayRegion + malloc stealing the show. Who knows.
It only gets worse for the ByteBuffer the more work that gets done.
The zoomed plots look a bit noisy so i'm not sure they're particularly valid. They are similar to the pre-allocated version except the ByteBuffer versions are well off the scale at that size.
After all this i'm not sure what conclusions to draw. Well for one OpenCL has so many other overheads I don't think any of these won't even be a rounding error ...
Invocation
I also did some playing around with native method invocation. The goal is just to get a 'pointer' to a native resource in the JNI and just to compare the relative overheads. The calls just return it so it isn't optimised out. Each case is executed for 100M times and this is the result of a fourth run.
- call
-
This is what I used in zcl. An object method is invoked and the instance method retrieves the pointer from 'this.p'.
- calle
-
The same but the call is wrapped in a try { } catch { } with in the loop and the method declares it throws an exception.
- callp
-
An instance method where an anonymous pointer is passed to the JNI.
- calls
-
A static method which takes the object as a parameter. The JNI retrieves 'this.p'.
- callsp
-
This is the commonly used approach whereby an anonymous pointer is passed as a parameter to a static method.
The three types are the type of pointer. I was going to test this on a 32-bit platform but ran out of steam so the integers don't make much difference here. int and long are just a simple type and buffer stores a 'struct' as a ByteBuffer. This latter is how I originally implemented jjmpeg but clearly that was a mistake.
Results
type call calle callp calls callsp
int 1.062 1.124 0.883 1.100 0.935
long 1.105 1.124 0.883 1.101 0.936
buffer 5.410 5.401 2.639 5.365 2.631
The results seemed pretty sensitive to compilation - each function is so small so there may be some margin of error.
Anyway the upshot is that there's no practical performance difference across all implementations and so the decision on which to use can be based on other factors. e.g. just pass objects to the JNI rather than the mess that passing opaque pointers create.
And ... I think that it might be time for me to leave this stuff behind for good.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!