About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

roadblocks
I've hit a roadblock for the moment in parallella hacking. It could just be a bug but I seem to be hitting a design fault when input to the epiphany is loaded - write transactions from the host cpu are getting lost or corrupted.
It happens when I try to communicate with the epu cores by writing directly to their memory like this:
struct job *jobqueue = @some pointer on-core@
int qid = ez_port_reserve(1)
memcpy(jobqueue[qid], job, sizeof(job);
ez_port_post(1);
And when the core is busy reading from shared memory:
struct job jobqueue[2];
ez_port_t port;
main() {
while (1) {
int qid = ez_port_await(1);
ez_dma_memcpy(buffer, jobqueue[qid].input, jobqueue[qid].N);
ez_port_complete(1);
}
}
It's ok with one core but once I have multiple cores running concurrently it starts to fail - at 16 it fails fairly often. It often works once too but putting the requests in a loop causes failures.
If I change the memcpy of the job details to the core into a series of writes with long delays in between them (more than 1ms) it reduces the problem to a rarity but doesn't totally fix it.
I spent a few hours trying everything I could think of but that was the closest to success and still not good enough.
I'll have to wait to see if there is a newer fpga image which is compatible with my rev0 board, or perhaps it's time to finally start poking with the fpga tools myself, if they run on my box anyway.
fft
I was playing with an fft routine. Although you can just fit a 128x128 2D fft all on-core I was focusing on a length of up to 1024.
I did an enhancement to the loader so I can now specify the stack start location which lets me get access to 3 full banks of memory for data - which is just enough for 3x 1024 element complex float buffers to store the sin/cos tables and two work buffers for double-buffering. This lets me put the code, control data, and stack into the first 8k and leave the remaining 24k free for signal.
I also had to try to make an in-place fft routine - my previous one needed a single out-of-place pass to perform the bit reversal following which all operations are streamed in memory order (in two streams). I managed to include the in-place bit reversal with the first radix-2 kernel so execution time is nearly as good as the out of place version. However although it works on the arm it isn't working on the epiphany but I haven't worked out why yet. At worst I can use the out-of-place one and just shift the asynchronous dma of the next row of data to after the first pass of calculation.
Although i'm starting with radix-2 kernels i'm hoping I have enough code memory to include up to radix-8 kernels which can make a good deal of difference to performance. I might have to resort to assembly too, whilst the compiler is doing a pretty good job of the arithmetic all memory loads are just word loads rather than double-word. I think I can do a better job of the addressing and loop arithmetic, and probably even try out the hardware loop feature.
parallella ezesdk 0.2
Just uploaded version 0.2 of the ezesdk stuff to the ezesdk homepage.
This includes everything i've been working on of late including the mandelbrot demo.
atomic counters
Yesterday I tried a mutex based implementation of an atomic counter to see how it compares.
My first test was to read the atomic counter 2^20 (1024x1024) from each core in a tight loop. Times are wall-clock on the host.
RxC Interrupt Mutex
---- ---------- ------
1x1 0.193488s 0.114833s
1x2 0.317739s 0.122575s
2x1 0.317739s 0.121737s
4x1 0.393244s 0.298871s
1x4 0.393244s 0.361574s
4x2 0.542462s 1.122173s
2x4 0.543283s 0.903163s
4x4 0.849627s 3.493985s
Interesting to note that orientation of a single line of cores makes a difference. May have something to do with using core 0,0 as the location of the mutex. Also of interest is that the 4x4 case is accessing the atomic counter 16x as many times as the 1x1 case - here the low-bandwidth requirements of the interrupt implementation is scaling better than linear compared to the mutex implementation - because the requesting core is effectively batching up multiple requests if they come too fast, rather than having to serialise everything remotely.
But as can be seen - once more than 4x cores are in play the interrupt driven routine starts to win out comfortably. This is despite effectively blocking the host core while the others are running.
But this isn't a very useful test because no practical software simply increments a remote counter. So for something more realistic I added a delay to the loop using one of the ctimers.
So looking at the most congested case of all cores busy:
4x4
Delay Interrupt Mutex
------ ---------- ------
10 0.965649s 3.138225s
100 1.083733s 3.919083s
200 1.630165s 3.693539s
300 1.780689s 3.792168s
400 2.297966s 3.666745s
500 2.448892s 3.563474s
1000 3.840059s 1.851269s
2000 4.923238s 3.402963s
So the cross-over point is around 1000 cycles worth of work, at least on a 16 core machine. 1000 cycles isn't much.
Given this data, it's probably better to go with a mutex implementation after-all. It requires about 1/3 of the code and doesn't load the servicing core nearly as much. Oh well, worth a try. (hang on, this doesn't let the host participate ... argh).
I have no direct data on the mesh load or the fairness of the count distribution. Intuitively the mutex based implementation wont be as fair due to the way the routing works, but once you have enough work to do the network shouldn't be particularly busy.
I'm hoping a future hardware revision may include an option on the ctimer to count reads of the ctimer register - which would effectively be a 2xatomic counters per core in hardware. In the meantime there's always that FPGA (maybe that's something I will look at, just no experience there).
note to self ...
Remember you need to save the status register before you execute an add.
I went about coding up that atomic counter idea from the previous post but had a hard time getting it to work. After giving up for a bit I had another go (couldn't let it rest as it was so close) and I discovered the register-saving preamble i'd copied from the async dma isr was simply broken.
_some_isr:
sub sp,sp,#24
strd r0,[sp]
strd r2,[sp,#1]
strd r4,[sp,#2]
movfs r5,status
... routine
movts status,r5
ldrd r4,[sp,#2]
ldrd r2,[sp,#1]
ldrd r0,[sp],#3
rti
Well it certainly looked the part, but it clobbers the status register in the first instruction. Oops.
strd r4,[sp,#-1]
movfs r5,status
sub sp,sp,#24
strd r0,[sp]
strd r2,[sp,#1]
There goes the symmetry. Actually it could probably just leave the stack pointer where it is because the routine isn't allowing other interrupts to run at the same time.
Fixed, the atomic counter worked ok. It shows some ... interesting ... behaviour when things get busy. It's quite good at being fair to all the cores except the core on which the atomic counter resides. Actually it gets so busy that the core has no time left to run any other code. The interrupt routine is around 200 cycles for 16 possible clients.
So ... I might have to try a mutex implementation and do some profiling. Under a lot of contention it may still be better due to the fixed bandwidth requirements but it's probably worth finding out where the crossover point is and how each scales. A mutex implementation wont support host access either ... always trade-offs. Definitely a candidate for FPGA I guess.
ipc primitive ideas
Had a couple of ideas for parallella IPC mechanisms whilst in the shower this morning. I guess i'm not out of ideas yet then.
atomic counter
These are really useful for writing non-blocking algorithms ... and would best be implemented in hardware. But since they aren't (yet - it could go into fpga too) here's one idea for a possible solution.
The idea is to implement it as an interrupt routine on each core - each core provides a single atomic counter. This avoids the problem of having special code on some cores and could be integrated into the runtime since it would need so little code.
Each core maintains a list of atomic counter requests and the counter itself.
unsigned int *atomic_counter_requests[MAX_CORES];
unsigned int atomic_counter;
To request an atomic number:
unsigned int local_counter;
local_counter = ~0;
remote atomic_counter = &local_counter;
remote ILATST = set interrupt bit;
while local_counter = ~0
// nop
wend
The ISR is straightforward:
atomic_isr:
counter = atomic_counter;
for i [get_group_size()]
if (atomic_counter_requests[i])
*atomic_counter_requests[i] = counter++;
atomic_counter_requests[i] = NULL;
fi
done
atomic_counter = counter;
Why not just use a mutex? Under high contention - which is possible with many cores - they cause a lot of blockage and flood the mesh with useless traffic of retries. Looking at the mesh traffic required:
do {
-> mutex write request
<- mutex read request return
} while (!locked)
-> counter read request
<- counter read request return
-> counter write request
-> mutex write request
Even in the best-case scenario of no contention there is two round trips and then two writes which don't block the callee.
In comparison the mesh traffic for the interrupt based routine is:
-> counter location write request
-> ILATST write request
<- counter result write request
So even if the interrupt takes a while to scan the list of requests the mesh traffic is much lower and more importantly - fixed and bounded. There is also only a single data round-trip to offset the loop iteration time.
By having just one counter on each core the overhead is minimal on a given core but it still allows for lots of counters and for load balancing ideas (e.g. on a 4x4 grid, use one of the central cores if they all need to use it). Atomic counters let you implement a myriad of (basically) non-blocking multi-core primitives such as multi reader/multi-writer queues.
This is something i'll definitely look at adding to the ezecore runtime. Actually if it's embedded into the runtime it can size the request array to suit the workgroup or hardware size and it can include one or more slots for external requests (e.g. allow the host to participate).
Broadcast port
Another idea was for a broadcast 'port'. The current port implementation only works with a single reader / single writer at a time. Whilst this can be used to implement all sorts of variations by polling one idea might be to combine them into another structure to allow broadcasts - i.e. single producer and multiple readers which read the same entries.
If the assumption is that every receiver is at the same memory location then the port only needs to track the offset into the LDS for the port. The sender then has to write the head updates to every receiver and the receivers have to have their own tail slots. The sender still has to poll multiple results but they could for example be stored as bytes for greater efficiency.
This idea might need some more cooking - is it really useful enough or significantly more efficient enough compared to just having a port-pair for each receiver?
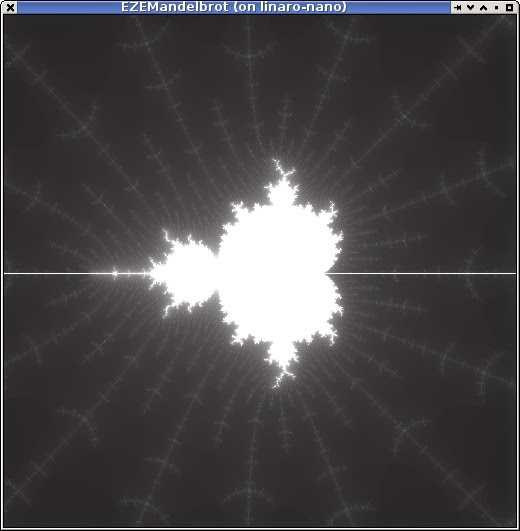
that 'graphical' demo
Ended up coding that 'graphical' demo. Just another mandelbrot thingo ... not big on the imagination right now and I suppose it demonstrates flops performance.
This is using JavaFX as the frontend - using the monocle driver as mentioned on a previous post. I'm still running it via remote X11 over ssh.
I have each EPU core calculating interleaved lines which works quite well at balancing the scheduling - at first i tried breaking the output into bands but that worked very poorly. The start position (not shown, but is (-1.5,-1.0) to (0.5,+1.0) and 256 maximum iterations) with 16 cores takes 0.100 seconds. A single-threaded implementation in Java using Oracle JDK 1.8 on the ARM takes 1.500 seconds, i'm using the performance mode. A single EPU core takes a little longer at 1.589s - obviously showing near-perfect scaling of the trivially paralellisable problem here even with the simple static scheduling i'm using.
For comparison my kaveri workstation using the single-core Java takes 0.120 seconds. Using Java8 parallel foreach takes that down to 0.036 seconds (didn't have this available when I timed the ARM version).
Details
The IPC mechanism i'm using is an 'ez_port' with a on-core queue. The host uses the port to calculate an index into the queue and writes to it's reserved slot directly, and so then the on-core code can just use it when the job is posted to the port.
The main loop on the core-code is about as simple as one can expect considering the runtime isn't doing anything here.
struct job {
float sx, sy, dx, dy;
int *dst;
int dstride, w, h;
};
ez_port_t local;
struct job queue[QSIZE];
int main(void) {
while (1) {
unsigned int wi = ez_port_await(&local, 1);
if (!queue[wi].dst) {
ez_port_complete(&local, 1);
break;
}
calculate(&queue[wi]);
ez_port_complete(&local, 1);
}
return 0;
}
This is the totality of code which communicates with the host. calculate() does the work according to the received job details. By placing the port_complete after the work is done rather than after the work has been copied locally allows it to be used as an implicit completion flag as well.
The Java side is a bit more involved but that's just because the host code has to be. After the cores are loaded but before they are started the communication values need to be resolved in the host code. This is done symbolically:
for (int r = 0; r < rows; r++) {
for (int c = 0; c < cols; c++) {
int i = r * cols + c;
cores[i] = wg.createPort(r, c, 2, "_local");
queues[i] = wg.mapSymbol(r, c, "_queue");
}
}
Then once the cores are started the calculation code just has to poke the result into the processing queue on each core. It has to duplicate the struct layout using a ByteBuffer - it's a bit clumsy but it's just what you do on Java (well, unless you do some much more complicated things).
int N = rows * cols;
// Send job to queue on each core directly
for (int i = 0; i < N; i++) {
int qi = cores[i].reserve(1);
// struct job {
// float sx, sy, dx, dy;
// int *dst;
// int dstride, w, h;
//};
ByteBuffer bb = queues[i];
bb.position(qi * 32);
// Each core calculates interleaved rows
bb.putFloat(sx);
bb.putFloat(sy + dy * i);
bb.putFloat(dx);
bb.putFloat(dy * N);
// dst (in bytes), dstride (in ints)
bb.putInt(dst.getEPUAddress() + i * w * 4);
bb.putInt(w * N);
// w,h
bb.putInt(w);
bb.putInt(h - i);
bb.rewind();
cores[i].post(1);
}
The post() call will trigger the calculation in the target core from the loop above.
Then it can just wait for it to finish by checking when the work queue is empty. A current hardware limitation requires busy wait loops.
// Wait for them all to finish
for (int i = 0; i < N; i++) {
while (cores[i].depth() != 0) {
try {
Thread.sleep(1);
} catch (InterruptedException ex) {
}
}
}
These two loops can then be called repeatedly to calculate new locations.
The pixels as RGBA are then copied to the WritableImage and JavaFX displays that at some point. It's a little slow via remote X but it works and is just a bit better than writing to a pnm file from C ;-)
I've exhausted my current ideas for the moment so I might drop out another release. At some point. There are still quite a lot of issues to resolve in the library but it's more than enough for experimentation although i'm not sure if anyone but me seems remotely interested in that.
minimal memory allocator n stuff
Over the last couple of days i've been hacking on the ezesdk code - original aim was to get a graphical Java app up which uses epiphany compute. But as i'm just about there i'm done for a bit.
Along the way I realised I pretty much needed a memory allocator for the shared memory block because I can't use static allocations or fixed addresses from Java. So I implemented a very minimal memory allocator for this purpose. It's small it enough it could potentially be used on-core for on-core memory allocations but i'm not look at using it there at this point.
It uses first-fit which I surprisingly found (some profiling a few years ago) was one of the better algorithms in terms of utilisation when memory is tight. The lowest level part of the allocator requires no overheads for memory allocations apart from those required for maintaining alignment. So for example 2 32xbyte allocations will consume 64-byte of memory exactly. Since this isn't enough to store the size of the allocation it must be passed in to the free function. I have a higher level malloc like entry point also which has an 8-byte overhead for each allocation and saves the size for the free call.
The only real drawback is that it isn't really very fast - it does a memory-order scan for both allocations and de-allocations. But as it is basically the algorithm AmigaOS used for years for it's system allocator it has been proven to work well enough.
So once I had that working I moved all the loader code to use it and implemented some higher level primitives which make communicating with cores a bit easier from host code.
I just ran some trivial tests with the JNI code and I have enough working to load some code and communicate with it - but i'll come up with that graphical demo another day. A rather crappy cold/wet weekend though so it might be sooner rather than later.
parallella ezesdk 0.1
As seems to be the habit lately I had a bunch of code sitting around on the hard drive for too long doing nothing so i packaged it up incase someone else finds it interesting. I should have some free time throughout June so doing this might also be a kick to restart development but I wouldn't be holding my breath on that one.
It's over on the ezesdk homepage I just whipped up.
It's all pretty much still subject to change but I think i've nailed down a pretty nice and compact core-side library api and the low-level host library as well. I had intended to include proper documentation and Java bindings by this point but ... well I didn't get to it.
Features of note is that it includes a functional printf, on-core barrier, async (interrupt-driven) dma routines, and 2d dma entry points; some of which has been discussed in more detail on a hacker's craic.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!