About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

kettle + bucket
Hmm, no wonder my gas bill has always been high, and rising to stupid levels. Big gas leak :-/ Well plumber came, checked, turned it off. Given the volume of the leak i'm surprised I couldn't smell it more but it's underground in a steel pipe.
I've been thinking of getting solar hot water so maybe it's time to finally do that but I just don't want to have to sort anything out right now (i.e. my life; the story so far).
Perhaps cold showers will get me thinking faster. Although it's not bloody likely i'll have any of those; middle of winter and just washing your hands in cold water is ... well cold. Last time I had a hot-water problem was also in the middle of winter and it was an electric kettle and a bucket for a while (I was just about to sell the house and it needed a lot of renovation so getting it replaced wasn't worth it).
just bit of a tool
Weather turned south so I ended up hacking all afternoon again.
After posting the last article I went and had a look at the instruction decoder I was working on. First I was hand-coding it all but then I realised how silly it was so I put it into a simple table. I was going to make a code-generator from that but it's really not necessary.
Here's a tiny bit of the table (it's only 84 lines long anyway). It has 3 fields, instruction name, addressing mode, bit format.
; branches
b 7 i{7-0},c{3-0},v{0000}
b 7 i{23-0},c{3-0},v{1000}
; load/store
ldr 8 d{2-0},n{2-0},i{2-0},b{1-0},v{00100}
str 8 d{2-0},n{2-0},i{2-0},b{1-0},v{10100}
; alu
add 3 d{5-3},n{5-3},m{5-3},x{000},v{1010},d{2-0},n{2-0},m{2-0},v{0011111}
; etc.
The bit format just defines the bits in order as they are displayed in the instruction decode table, so were easy enough to enter.
From this table it's only about 10 lines of code to decode an instruction and not much more to display it - most of it is just handling the different addressing modes (ok it's a lot more but it's all a simple switch statement). It just searches for the instruction that matches all bits in the v{} sections; first in 16-bit instructions and if none are found then reads another 16 bits and looks in the 32-bit instructions. I still have some sign extension stuff to handle properly but here's some example output.
09: 1 SHT_PROGBITS .text.2
strd.l r4,[r13],#-2
strd.l r6,[r13,#+1]
strd.l r8,[r13,#+0]
mov.l r12,#0x0000
ldrd.l r44,[r12,#+0]
mov.s r4,#0x0001
ldrd.l r46,[r12,#+1]
lsl.l r17,r4,r2
ldrd.l r48,[r12,#+2]
sub.s r5,r1,r3
ldrd.l r50,[r12,#+3]
sub.s r6,r5,#0x0002
ldrd.l r52,[r12,#+4]
lsl.s r7,r4,r6
Here's the output from objdump for comparison.
Disassembly of section .text.2:
00000000 <_e_build_wtable2>:
0: 957c 0700 strd r4,[sp],-0x2
4: d4fc 0400 strd r6,[sp,+0x1]
8: 147c 2400 strd r8,[sp]
c: 800b 2002 mov r12,0x0
10: 906c a400 ldrd r44,[r12,+0x0]
14: 8023 mov r4,0x1
16: d0ec a400 ldrd r46,[r12,+0x1]
1a: 312f 400a lsl r17,r4,r2
1e: 116c c400 ldrd r48,[r12,+0x2]
22: a5ba sub r5,r1,r3
24: 51ec c400 ldrd r50,[r12,+0x3]
28: d533 sub r6,r5,2
2a: 926c c400 ldrd r52,[r12,+0x4]
2e: f32a lsl r7,r4,r6
Because I wrote this in Java, before I could even test it ... I had to write an elf library as well. But elf is simple so it was just a few 'struct' accessors for a memory mapped Java ByteBuffer and only took half an hour via some referencing of the code in ezesdk and elf.h.
A simple static analysis tool should be relatively straightforward at this point although to be useful it needs to do some more complicated things like determine dual-issue and so on. For that my guess is that i'll need a relatively complete pipeline simulator - it doesn't need to simulate the cpu instructions, just the register dependencies. A more dynamic analysis tool would require a simulator but I guess that's possible since the cpu is so simple (performance might be a factor at that point though).
But I don't really know and i'm just piss farting about - I haven't written tools like this for ... forever. Last time was probably a dissasembler I wrote in assembly language for the Commodore 64 about 25 years ago so I could dump the roms. Ahh those were the days. Actually these days aren't much different for me apart from different shit to be anxious about.
Productive enough afternoon anyway, I suppose i'd better go find some food and decide if i'm going to stay up to watch the soccer after watching some local footy and maybe the tour. 5am is a bit too late, or early, and tbh i don't really care too much who wins.
Update: Hacked a bit more last night, came up with a really shitty pipeline simulator.
From this code:
fmadd.l r0,r0,r0
fmadd.l r0,r0,r0
add r17,r16,r16
add r17,r16,r16
add r17,r16,r16
add r17,r16,r16
add r17,r16,r16
add r17,r16,r16
fmadd.l r0,r0,r0
rts
Assembled, then loaded from the elf:
de ra e1 de ra e1 e2 e3 e4
alu: - - - fpu: 0 fmadd - - - - -
alu: 1 add - - fpu: 1 fmadd 0 fmadd - - - -
alu: 2 add 1 add - fpu: 1 fmadd - 0 fmadd - - -
alu: 3 add 2 add 1 add fpu: 1 fmadd - - 0 fmadd - -
alu: 4 add 3 add 2 add fpu: 1 fmadd - - - 0 fmadd -
alu: 5 add 4 add 3 add fpu: 1 fmadd - - - - 0 fmadd
alu: 6 add 5 add 4 add fpu: 6 fmadd 1 fmadd - - - -
alu: 7 jr 6 add 5 add fpu: 6 fmadd - 1 fmadd - - -
alu: - 7 jr 6 add fpu: 6 fmadd - - 1 fmadd - -
alu: - - 7 jr fpu: 6 fmadd - - - 1 fmadd -
alu: - - - fpu: 6 fmadd - - - - 1 fmadd
alu: - - - fpu: - 6 fmadd - - - -
alu: - - - fpu: - - 6 fmadd - - -
alu: - - - fpu: - - - 6 fmadd - -
alu: - - - fpu: - - - - 6 fmadd -
alu: - - - fpu: - - - - - 6 fmadd
alu: - - - fpu: - - - - - -
The number infront of the instruction is when it entered the pipeline.
Oops, so bit of a bug there, once it dual-issues the first add/fmadd pair it just keeps issuing the ialu ops, which shouldn't happen. I've go the register dependency test in the wrong spot. I can fiddle with the code to fix that up but I need to find out a bit more about how the pipeline works because there some other details the documentation doesn't really cover in enough detail.
Update: After a bit of work on the house I had another look at the pipeline and did some hardware tests. So it looks like as soon as an instruction sequence arrives which might dual-issue, it gets locked into a 'dual issue' pair which will stall both instructions until both are ready to proceed - regardless of the order of the instructions and whether the first could advance on it's own anyway.
So for example, these sequences all execute as dual-issue pairs (all else being equal, there are other alignment related things but I haven't worked them out yet).
fmadd.l r0,r0,r0 fmadd.l r0,r0,r0 mov r16,r16 fmadd.l r0,r0,r0
mov r16,r16 mov r16,r16 fmadd.l r0,r0,r0 mov r16,r16
fmadd.l r0,r0,r0 mov r16,r16 mov r16,r16 mov r16,r16
mov r16,r16 fmadd.l r0,r0,r0 fmadd.l r0,r0,r0 fmadd.l r0,r0,r0
Anyway, so re-running the timing tool with these new changes give a better result:
alu: - - - fpu: 0 fmadd - - - - -
alu: 1 add - - fpu: 1 fmadd 0 fmadd - - - -
alu: 1 add - - fpu: 1 fmadd - 0 fmadd - - -
alu: 1 add - - fpu: 1 fmadd - - 0 fmadd - -
alu: 1 add - - fpu: 1 fmadd - - - 0 fmadd -
alu: 1 add - - fpu: 1 fmadd - - - - 0 fmadd
alu: 6 add 1 add - fpu: - 1 fmadd - - - -
alu: 7 add 6 add 1 add fpu: - - 1 fmadd - - -
alu: 8 add 7 add 6 add fpu: - - - 1 fmadd - -
alu: 9 add 8 add 7 add fpu: - - - - 1 fmadd -
alu: 10 add 9 add 8 add fpu: 10 fmadd - - - - 1 fmadd
alu: 11 jr 10 add 9 add fpu: - 10 fmadd - - - -
alu: - 11 jr 10 add fpu: - - 10 fmadd - - -
alu: - - 11 jr fpu: - - - 10 fmadd - -
alu: - - - fpu: - - - - 10 fmadd -
alu: - - - fpu: - - - - - 10 fmadd
alu: - - - fpu: - - - - - -
I also have another output format which is like the spu timing tool which shows each instruction in sequence with time horizontal. I don't have the correct labels yet but it shows the dual issue pairs more clearly. The register checking/writing might be in the wrong spot too but the delays look right.
fmadd dr1234
fmadd dr1234
add dr1
add dr1
add dr1
add dr1
add dr1
add dr1
fmadd dr1234
jr dr1
Still a few other details which can wait for another day.
Optimising
I spent a good chunk of yesterday trying to optimise the cexpi implementation to get of as many register access penalties as possible and dual-issue as many instructions as possible. There still seems to be a bit of magic there but i'm getting there.
what clock ialu fpu dual e1 st ra st loc fe ex ld
e_build_wtable 29637 21347 9548 8866 24 7563 21 36
e_build_wtable2 20149 17656 8184 6138 24 402 28 36
build_wtable_2 is based on the 5+4 term sincos from the previous post so requires fewer flops to start with but the main point of interest is the greatly reduced register stalls.
Primarily I just wasn't putting enough code between the flop instructions, but that can be easier said than done.
I used a technique I've talked about previously to be able to add more ialu instructions within the flops. Basically the loop is unrolled "in-place", whereby some results required for the next loop are calculated in the current one and otherwise the loop conditions remain the same.
A fairly detailed summation of the steps follows. This calculates two tables of sin/cos pairs together. The polynomial approximation is only valid over (0..pi/4) and so to calculate sin(pi/4+i) it calcualtes cos(pi/4-i) and so on.
build_wtable(complex float *wtable, int logN, int logStride, int logStep, int w0)
load constants
calculate loop count
loop:
all integer ops:
// 1: calculate frequency of this coefficient
f1 = w0 << shift
f0 = f1 * 2
// 2: calculate octant
j0 = f0 >> shift2
j1 = f1 >> shift2
// 3: calculate fractional part of frequency and mirror if required
x0 = f0 & mask;
x0 = j0 & 1 ? (scale - x0) ? x0;
x1 = f1 & mask;
x1 = j1 & 1 ? (scale - x1) ? x1;
// 4: calculate sign of result
negcos0 = ((j0+2) >> 2) << 31;
negsin0 = ((j0) >> 2) << 31;
negcos1 = ((j1+2) >> 2) << 31;
negsin1 = ((j1) >> 2) << 31;
// 5: determine if cos/sine needs swapping
swap0 = (j0+1) & 2;
swap1 = (j1+1) & 2;
All float ops:
// 6: scale input
a0 = to_float(x0) * 1.0 / scale;
a1 = to_float(x1) * 1.0 / scale;
// 7: calculate sin/cos over pi/4
b0 = a0 * a0;
b1 = a1 * a1;
... calculate sin'(a0/a1) and cos'(a0/a1) using fmadd+fmul
// 8: swap if necessary
cos0 = swap0 ? sin'0 : cos'0;
sin0 = swap0 ? cos'0 : sin'0;
cos1 = swap1 ? sin'0 : cos'0;
sin1 = swap1 ? cos'0 : sin'0;
// 9: fix sign
All Integer ops:
// twiddles bit-31 of ieee float
as_int(cos0) ^= negcos0;
as_int(sin0) ^= negsin0;
as_int(cos1) ^= negcos1;
as_int(sin1) ^= negsin1;
// a: output
*wtable++ = cos0 + I * sin0;
*wtable++ = cos1 + I * sin1;
// b: next step
w0 += wstep;
endloop
I wont show the detail of the calculation itself but I tried using Estrin's Algorithm for the polynomial expansion to try to reduce the latency involved. Actually it ended up a bit interesting because it shifted where the constants needed to be loaded for the 3-register fmadd (since it modifies it's first result, the constants need loading there) - and meant there were fewer ways to dual-issue instructions, more below. I might end up trying the other way too - but this stuff just sucks so much time it's crazy.
So basically there are a bunch of integer ops followed by float ops followed by a few int ops to finish off. Now comes the tricky bit where 'optimisation' comes into play. Firstly, float operations all have a latency which means that if you just use them in the order shown you wont get good performance.
Even just listing it the way I have is a simple optimisation.
For example:
a0 = to_float(x0) * 1.0 / scale;
b0 = a0 * a0;
a1 = to_float(x1) * 1.1 / scale;
b1 = a1 * a1;
Would take approximately 2x longer than:
a0 = to_float(x0) * 1.0 / scale;
a1 = to_float(x1) * 1.1 / scale;
b0 = a0 * a0;
b1 = a1 * a1;
If one looks at the basic instructions annotated with the delay slots it's pretty obvious which is better (i might be a off with the delay slots)
inline interleaved
float r8,r0 float r8,r0
- float r10,r1
- -
- -
- -
fmul r8,r8,r32 fmul r8,r8,r32
- fmul r10,r10,r32
- -
- -
- -
fmul r9,r8,r8 fmul r9,r8,r8
float r10,r1 fmul r11,r10,r10
-
-
-
-
fmul r10,r10,r32
-
-
-
-
fmul r11,r10,r10
But one can only do this optimisation if you have enough registers to fully calculate each separately (this is an important point, and why the cpu has so many registers).
The other factor is that the epiphany cpu can dual-issue certain sets of instructions in certain circumstances. Fortunately the circumstances are fairly simple (for the most part, some details still elude me) and it's basically a float + ialu or load op. The precise behaviour seems to depend on instruction order/alignment but i'm not really sure on all the details yet.
So this means for example that any of the integer operations can be interleaved with the float operations and effectively become 'zero cost' - assuming there is some 'fixed cost' based on the number of float ops and their scheduling requirements. Cool but it complicates things and dual-issuing instructions means you don't fill any of those latency slots so need to find more instructions!
Examining the algorithm there are some hard dependencies which force a particular calculation order but a bunch of the integer calculations aren't needed till the end.
- Steps 1-3
- These are required before any float ops can be performed. These cannot be dual-issued obviously.
- Steps 4-5
- These can be performed anywhere and they are not needed until the end. These are prime candidates for dual issue.
- Steps 6-7
- These are hard orderings that add float latencies which cannot be avoided. They also require some register moves to setup the 3-register fmadd instructions which can make use of some of those slots and dual-issue.
- Steps 8-a
- These are pretty much hard-dependencies on the output. Fortunately there are no ra penalties for integer operations but it does mean there is an integer/fpu op mismatch; as odd as it sounds it may actually help to convert these operations into floating point ops.
- Step b
- Can be put almost anywhere.
Actually ... I lied. All of those steps can be interleaved with others ... by calculating the value you will need for the next loop (or next next) instead. This requires a ton of registers - I used every 'free' register up and had to save a few to the stack besides. I think the epiphany ABI could use some tuning for size/performance but I don't have enough data to back up any changes; and it isn't simple because any change has side effects.
The algorithm then becomes changed to:
setup first loop
loop:
calculate result interleaved with setup next loop
The tricky bit comes in tracking the state of all the registers across the algorithm and ensuring the right value is calculated and in the correct register when it is needed. The simplest way to do this is to basically use a new register for every calculation that might be needed later and then bits of code can basically be re-arranged 'at will' without becoming too much of a complicated mess for a head to manage. And hope you don't run out of registers.
Still it's a little hard on the head and eyes so I'm thinking of writing a tool which can help with some of the work. I started with a tool that parsed the assembly and dumped a table of register liveliness; but then i realised to go any further with that i'd basically need to write a whole assembler so I started work on an instruction decoder that can pass over the compiled binary which should be easier. Epiphany's instruction set is fairly tiny so at least that shouldn't be too much work. Well i'll see on that one, ... it's still a lot of work.
Estrin's Method and 3-register FMA
So whilst doing a pass over this post I noticed the anomaly with the greatly reduced ialu count of the new implementation. I did notice when I wrote the initial implementation it seemed rather small compared to the previous one - I put it down to the reduced term count but on reflection is is more than that.
So the basic polynomial expansion using Horner's Rule for sin+cos() in terms of 3-register fmadd instructions becomes:
; sin
; a (A + a^2 (B + a^2 (C + a^2 D)
; r0 = a
; r1 = a^2
mov r2,rC ; t0 = C
1 fmadd r2,r1,rD ; t0 += a^2 D
mov r3,rB ; t1 = B
2 fmadd r3,r2,r1 ; t1 += a^2 (C + a^2 D)
mov r2,rA ; t0 = A
3 fmadd r2,r3,r1 ; t0 += a^2 (B + a^2 (C + a^2 D))
4 fmul r2,r2,r0 ; t0 *= a
; cos
; A + a^2 (B + a^2 (C + a^2 (D + a^2 E)
; r0 = a
; r1 = a^2
mov r2,rD ; t0 = D
1 fmadd r2,r1,rE ; t0 += a^2 D
mov r3,rC ; t1 = C
2 fmadd r3,r2,r1 ; t1 += a^2 (D + a^2 E)
mov r2,rB ; t0 = B
3 fmadd r2,r3,r1 ; t0 += a^2 (C + a^2 (D + a^2 E))
mov r3,rB ; t1 = A
4 fmadd r3,r2,r1 ; t1 += a^2 (B + (C + a^2 (D + a^2 E)))
Note that the cos 'A' is not the same as the sin 'A'. The digit infront of the fpu ops is the 'stage' of the calculation in terms of register dependencies.
The same using Estrin's Aglorithm:
; sin
; a ((A + a^2 B) + a^4 (C + a^2 D))
; r0 = a
; r1 = a^2
1 fmul r2,r1,r1 ; a^4 = a^2 . a^2
mov r3,rA ; t0 = A
mov r4,rC ; t1 = C
1 fmadd r3,r1,rB ; t0 = A + a^2 B
1 fmadd r4,r1,rD ; t1 = C + a^2 D
2 fmadd r3,r2,r4 ; sin'= (A + a^2 B) + a^4 (C + a^2 D)
3 fmul r3,r3,r0 ; sin = a sin'
; cos
; A + a^2 ((B + a^2 C) + a^4 (D + a^2 E))
; r0 = a
; r1 = a^2
1 fmul r2,r1,r1 ; a^4 = a^2 . a^2
mov r3,rB ; t0 = B
mov r4,rD ; t1 = D
1 fmadd r3,r1,rB ; t0 = B + a^2 C
1 fmadd r4,r1,rD ; t1 = D + a^2 E
2 fmadd r3,r2,r4 ; sin'= (A + a^2 B) + a^4 (C + a^2 D)
mov r4,rA ; t1 = A
3 fmadd r4,r3,r1 ; sin = A + a^2 ((A + a^2 B) + a^4 (C + a^2 D))
So 15 instructions vs 15 instructions, but 7 constant loads vs 5. Well that's interesting. With dual issue with this snippet the cost is hidden but if a routine has more ialu ops than flops then the latter leave more opportunities for scheduling.
Even if the instruction set had a 4-register fma instruction the second might be better due to needing one less stage of calculation.
ABI?
I wish the abi was tad bit more asm-hacker friendly. A compiler doesn't care where the spare registers are but keep track of the sparse ranges is a pain. I think it would benefit from having all 8 'zero page' registers available as scratch anyway.
I wouldn't mind something closer to this:
r0-r3 argument / saved by caller
r4-r7 gp / saved by caller
r8-r23 saved by callee / hardware (lr only) / constants
r24-r63 gp / saved by caller
Rather than this:
r0-r3 argument / saved by caller
r8-r11 saved by callee
r12 scratch / saved by caller
r13-r15 saved by callee / hardware
r16-r27 gp /saved by caller
r28-r31 constants
r32-r43 saved by callee
r44-r63 gp / saved by caller
I don't really see the need for any of the arm-legacy register assignments such as r12 == ip. This would leave 48 registers free for leaf functions (rather than the current 37) to use without having to resort to saving registers and importantly leave 0-7 which can have a huge impact on code-size. And it would still leave enough registers for outer loops and so on. The abi is designed to work with a cut-down cpu which i think has 16 registers: but the proposed would work there as well.
But yeah, who knows, any change isn't cost-free and if your code is calling lots of small functions rather than calling big processing leaf functions then it might not work so well (but yeah, it wont anyway). I previously tried patching gcc to modify the abi but I didn't fully complete it.
A better, faster sincos/cexpi
After posting about the fft implementation i've been working on to the parallella forums one kind fellow-hacker directed me to a tool which can be used to improve the error of polynomial estimates to functions. Basically to get the same or better result in fewer terms.
This gave me something to poke at for a couple of evenings but to be honest my maths skills are up shit creek these days and I had trouble working out a good approximation to cosine() or properly forming the expressions to take account of floating point precision limits.
So armed with knowledge of this new technique I did further searching and came across a few interesting papers/presentaitons from the PS2 era about function optimisation and floating point errors and then came across exactly the tool I was after sollya. So I compiled that up and had a bit of a play.
Once I worked out how it worked I did some analysis on the functions I created using lolremez, the ones I had, and some others I found on the net.
First, the 6-term expression I started with. SG(x) here casts the value to a float (C type).
> Z6=x*(SG(3.1415926535897931159979634685441851615906e+00)
+ x^2 * (SG(-5.1677127800499702559022807690780609846115e+00)
+ x^2 * (SG(2.5501640398773455231662410369608551263809e+00)
+ x^2 * (SG(-5.9926452932079210533800051052821800112724e-01)
+ x^2 * (SG( 8.2145886611128232646095170821354258805513e-02)
+ x^2 * SG(-7.3704309457143504444309733969475928461179e-03))))));
Warning: Rounding occurred when converting the constant "3.1415926535...
Warning: Rounding occurred when converting the constant "5.1677127800...
Warning: Rounding occurred when converting the constant "2.5501640398...
Warning: Rounding occurred when converting the constant "5.9926452932...
Warning: Rounding occurred when converting the constant "8.2145886611...
Warning: Rounding occurred when converting the constant "7.3704309457...
> dirtyinfnorm(sin(x * pi)-Z6, [0;1/4]);
2.32274301387587407010080506217793120115302759634118e-8
Firstly - those float values can't even be represented in single precision float - this is despite attempting to do just that. Given the number of terms, the error rate just isn't very good either.
I used lolremez to calculate a sinf() function with 4 terms, and then analysed it in terms of using float calculations.
> RS = x * ( SG(9.999999861793420056608460221757732708227e-1)
+ x^2 * (SG(-1.666663675429951309567308244260188890284e-1)
+ x^2 * (SG(8.331584606487845846198712890758361670071e-3)
+ x^2 * SG(-1.946211699827310148058364912231798523048e-4))));
Warning: Rounding occurred when converting the constant "9.9999998617...
Warning: Rounding occurred when converting the constant "1.6666636754...
Warning: Rounding occurred when converting the constant "8.3315846064...
Warning: Rounding occurred when converting the constant "1.9462116998...
> dirtyinfnorm(sin(x)-RS, [0;pi/4]);
9.0021097355521826457692679614674224316870784965529e-9
This is roughly 8x the error rate reported by lolremez or sollya with extended precision, but obviously an improvement over the taylor series despite using only 4 terms.
So using sollya to calculate an expression with the same terms whilst forcing the values to be representable in float is very simple.
> LS4 = fpminimax(sin(x), [|1,3,7,5|], [|single...|],[0x1p-16000;pi/4]);
> LS4;
x * (1
+ x^2 * (-0.1666665375232696533203125
+ x^2 * (8.332121185958385467529296875e-3
+ x^2 * (-1.951101585291326045989990234375e-4))))
> dirtyinfnorm(sin(x)-LS4, [0;pi/4]);
2.48825949986510374795541070830762114197913817795157e-9
So ... yep that's better. (0x1p-16000 is just a very small number since the calculation fails for 0.0).
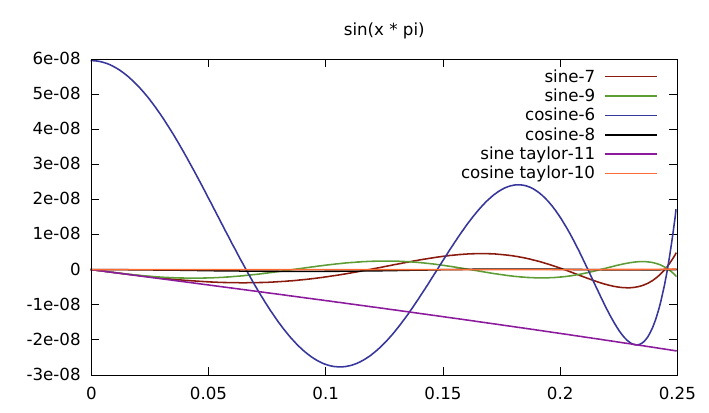
One of the most accurate other implementations I found for sin() was from an article "Faster Math Functions" by Robin Green of Sony (cira ps2 era). The first term of this function is exactly representable in float and the constants calculated using remez. I analysed this in sollya.
> RGS = x * (1 + x^2 * (SG(-0.166666567325592041015625) + x^2 * (SG(0.00833220803) + x^2 * SG(-0.000195168955))));
Warning: Rounding occurred when converting the constant "0.0083322080...
Warning: Rounding occurred when converting the constant "0.0001951689...
> dirtyinfnorm(sin(x)-RGS, [0;pi/4]);
3.40294295123115698469497312067470829353049357459609e-9
Note that the first term is represented in floating point exactly.
Plot time.
The lolremez version is faltering here because the first term is actually 1 in float, yet the optimisation process is assuming it has much higher accuracy and adjusting the other polynomial exponents appropriately.
> SG(9.999999861793420056608460221757732708227e-1);
1
I did some further mucking about with the tutorial which explained how to fix the first-term into one representable by floats (i.e. 1.0) but I wont include it here since it was superseded by the results from sollya with much less work (i.e. the result above). The one from the Robin Green article should be much the same anyway as it was derived in a similar manner.
cexpi()
So applying the problem to the one I was interested in - sin/cos with an integer argument, leads to the following solutions. By scaling the input value by pi, the full range is normalised to a 1.0, and powers-of-two fractions of one (as required by an fft) can be represented in float with perfect accuracy which removes some of the error during calculation.
> S4 = fpminimax(sin(x * pi), [|1,3,7,5|], [|24...|],[0x1p-16000;1/4]);
> S4;
x * (3.1415927410125732421875
+ x^2 * (-5.16771984100341796875
+ x^2 * (2.550144195556640625
+ x^2 * (-0.592480242252349853515625))))
> C5 = fpminimax(cos(x * pi), [|0,2,4,6,8|], [|24...|],[0;1/4]);
> C5;
1 + x^2 * (-4.93480205535888671875
+ x^2 * (4.0586986541748046875
+ x^2 * (-1.33483588695526123046875
+ x^2 * 0.22974522411823272705078125)))
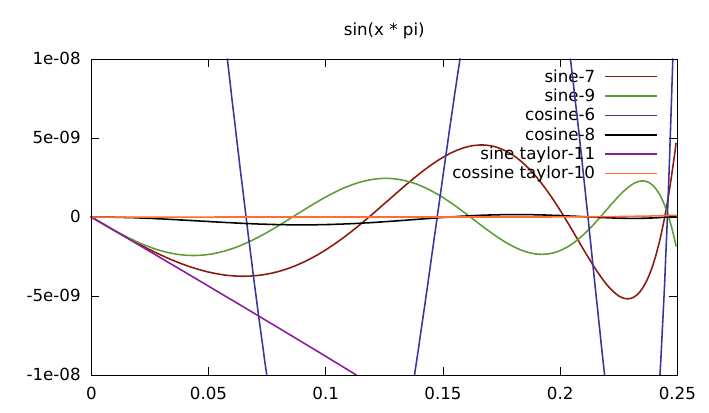
The reason for using 4 terms for sine and 5 for cosine is because at least 5 are needed for cosine for similar accuracy and it also creates a matching number of instructions since sine() needs the extra multiply by x - this also improves the instruction scheduling. Using more terms for sine only increases the accuracy by a small bit because this is hitting the limits of floating point accuracy so isn't worth it.
A closer view:
The taylor series for cosine is much better than the one for sine.
fmadd, fmul, etc
Most of the function can be implemented using multiply+add instructions if it is represented in the obvious 'Horner' form.
s = a A + a^3 B + a^5 C + a^7 D
= a (A + a^2 (B + a^2 (C + a^2 D)
c = 1 + a^2 A + a^4 B + a^6 C + a^8 D
= 1 + a^2 (A + a^2 (B + a^2 (C + a^2 D)
seq caclulation
0 a2 = a * a
1 s = 2.550144195556640625 + a2 * -0.592480242252349853515625
1 c = -1.33483588695526123046875 + a2 * 0.22974522411823272705078125
2 s = -5.16771984100341796875 + a2 * s
2 c = 4.0586986541748046875 + a2 * c
3 s = 3.1415927410125732421875 + a2 * s
3 c = -4.93480205535888671875 + a2 * c
4 s = a * s
4 c = 1.0 + a2 * c
Another way to represent the expression is using Estrin's method. I found this mentioned in the stuff by R.Green and he references Knuth.
This breaks the expression into independent sub-trees which can be calculated concurrently. This is obviously quite useful for SIMD calculations but can also be useful on a serial processor with a deep pipeline as it reduces the number of stages with serial dependencies.
s = a A + a^3 B + a^5 C + a^7 D
= a ( (A + a^2B) + a^4 (C + a^2 D) )
c = 1 + a^2 A + a^4 B + a^6 C + a^8 D
= 1 + a^2 ( (A + a^2 B) + a^4 (C + a^2 D) )
seq calculation
0 a2 = a * a
1 a4 = a2 * a2
1 s0 = A + a2 * B
1 s1 = C + a2 * D
1 c0 = A + a2 * B
1 c1 = C + a2 * D
2 s3 = s0 + a4 * s2
2 c3 = c0 + a4 * c2
3 s = a * s3
3 c = 1 + a2 * c3
This requires 1 more floating point instruction: but it executes in 3 stages of dependent results rather than 4. If latency of the calculation is important or if there are no other instructions that can be scheduled to fill the latency slots of the fpu instructions this would execute faster.
Exact floats: Hex Float Notation
Whilst looking through some code I came across the hexadecimal float notation which I hadn't seen before. I've been wondering how to correctly encode floating point values with exact values so this I guess is the way.
Sollya can output this directly which is nice, so the above expressions can also be represented (in C) as:
> display = hexadecimal;
Display mode is hexadecimal numbers.
> S4;
x * (0x3.243f6cp0
+ x^0x2.p0 * (-0x5.2aefbp0
+ x^0x2.p0 * (0x2.8cd64p0
+ x^0x2.p0 * (-0x9.7acc9p-4))))
> C5;
0x1.p0
+ x^0x2.p0 * (-0x4.ef4f3p0
+ x^0x2.p0 * (0x4.0f06ep0
+ x^0x2.p0 * (-0x1.55b7cep0
+ x^0x2.p0 * 0x3.ad0954p-4)))
So the hex number is the mantissa, and the exponent is relative to the decimal point in bits. It wont output expressions in IEE754 encoded values directly but they can be printed (useful for assembly).
> printsingle( 0x3.243f6cp0);
0x40490fdb
> printsingle(3.1415927410125732421875);
0x40490fdb
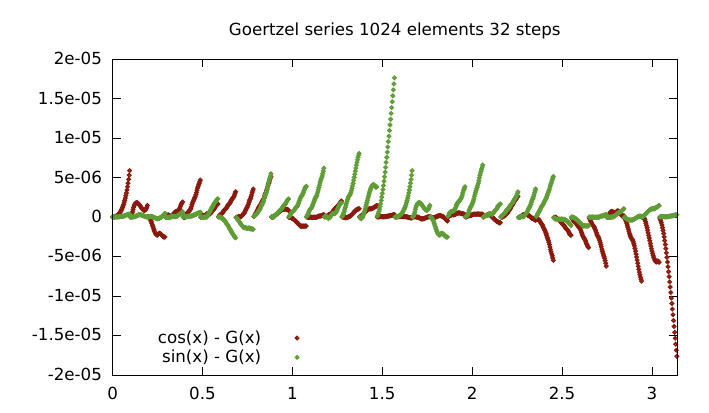
Goertzel's Algorithm
There are other ways to calculate series of sincos values quickly. One is Goertzel's Algorithm. It can calculate a series of sin/cos values of the form sincos(a + i*b), which is exactly what is required.
An example implementation:
float cb = 2 * cos(b);
// offset by 3 terms back
float ag = a - 3 * b;
// can be calculated using summation rule
float s1 = sin(ga+b);
float s0 = sin(ga+2*b);
float c1 = cos(ga+b);
float c0 = cos(ga+2*b);
// unroll the inner loop once to simplify register usage/reusage
for (int i=0;i<N;i+=2) {
s1 = cb * s0 - s1;
c1 = cb * c0 - c1;
s0 = cb * s1 - s0;
c0 = cb * c1 - c0;
out[i+0] = c1 + s1 * I;
out[i+1] = c0 + s0 * I;
}
Unfortunately, floating point addition pretty much sucks so this will drift very quickly if cb*X is appreciably different in scale to Y in the cb*x-Y expressions. So error depend on both b and a, which leads to a funky looking error plot.
Where a = j*32*PI/1024 | j= (0 ... 31), b = PI/1024.
Was worth a try I guess.
asm v c
For a bit of 'fun' i thought i'd see how translating some of the fft code to assembly would fare.
I started with this:
void
build_wtable(complex float *wtable, int logN, int logStride, int logStep, int w0) {
int wcount = 1<<(logN - logStep - 2);
int wshift = logStride;
for (int i=0;i<wcount;i++) {
int j0 = w0 + (i<<wshift);
int f2 = j0 << (CEXPI_LOG2_PI - logN + logStep - logStride + 1);
int f0 = f2 * 2;
wtable[i*2+0] = ez_cexpii(f0);
wtable[i*2+1] = ez_cexpii(f2);
}
}
It generates the twiddle factors required for a given fft size relative to the size of the data. ez_cexpii(x) calculates e^(I * x * PI / (2^20)), as previously discussed.
This is called for each radix-4 pass - 5 times per 1024 elements, and generates 1, 4, 16, 64, or 256 complex value pairs per call. I'm timing all of these together below so this is the total time required for twiddle factor calculation for a 1024-element FFT in terms of the timer counter register.
The results:
what clock ialu fpu dual e1 st ra st loc fe ex ld size
noop 23 4 0 0 9 16 8 6
build_wtable 55109 36990 9548 6478 9 7858 1 6 372
build_wtable_il 62057 25332 9548 4092 9 27977 8 6 618
e_build_wtable 31252 21999 9548 8866 9 7518 13 6 464
e_build_wtable_hw 29627 21337 9548 8866 24 7563 16 36 472
1 * e_build_wtable 148 99 28 26 9 38 1 6
$ e-gcc --version
e-gcc (Epiphany toolchain (built 20130910)) 4.8.2 20130729 (prerelease)
(30 000 cycles is 50uS for a clock of 600Mhz)
- noop
- This just calls ez_timer0_start(timerid, ~0); ez_ctimer0_stop(); and then tallies up the counters showing a baseline for a single time operation.
- build_wtable
- This is the code as in the fft sample.
- build_wtable_il
- This is the same as above but the ez_cexpii() call has been inlined by the compiler.
- e_build_wtable
- The assembly version. This is after a few hours of poking at the code trying to optimise it further.
- e_build_wtable_hw
- The same, but utilising the hardware loop function of the epiphany.
Discussion
Well what can i say, compiler loses again.
I'm mostly surprised that inlining the cexpii() function doesn't help at all - it just hinders. I confirmed the code is being inlined from the assembler listing but it just seems to be more or less copying the code in-lined twice rather than trying to interleave the functions to provide additional scheduling opportunities. As can be seen the ialu ops are significantly reduced because the constant loads are being taken outside of the loop but that is offset by a decrease in dual-issue and a big jump in register stalls.
Whilst the compiler generated a branch in the cexpii function I managed to go branchless in assembly by using movCC a couple of times. I am loading all the constants from a memory table using ldr which reduces the ialu op count a good bit, although that is outside the inner loop.
The hardware loop feature knocks a little bit off the time but the loop is fairly large so it isn't really much. I had to tweak the code a little to ensure the code lined up correctly in memory otherwise the loop got slower. i.e. such that .balignw 8,0x01a2 did nothing although it is still present to ensure correct operation.
Try as I might I was unable to get every flop to dual issue with an in ialu op. Although I got 26 out of 28 to dual-issue which seems ok(?). I don't fully understand the interaction of the dual-issue with things like instruction order and alignment so it was mostly just trial and error. Sometimes moving an instruction which had no other dependency could change the timing by a bigger jump than it should have, or e.g. add one ialu instruction and now the total clock time is 3 clock cycles longer?
I'm not sure I understand the register stall column completely either. For example calling the function such that a single result pair is calculated results in the last row of the table above. 38 stalls, where? The noop case is easier to analyse in detail: where do those 16 stalls come from? AFAICT the instruction sequence executed is literally:
32: 3feb 0ff2 mov r1,0xffff
36: 3feb 1ff2 movt r1,0xffff
3a: 10e2 mov r0,r4
3c: 1d5f 0402 jalr r15
-> calls 00000908 <_ez_ctimer0_start>:
908: 6112 movfs r3,config
90a: 41eb 0ff2 mov r2,0xff0f
90e: 5feb 1ff2 movt r2,0xffff
912: 4d5a and r2,r3,r2
914: 4102 movts config,r2
916: 390f 0402 movts ctimer0,r1
91a: 0096 lsl r0,r0,0x4
91c: 487a orr r2,r2,r0
91e: 4102 movts config,r2
-> clock starts counting NOW!
920: 194f 0402 rts
-> returns to timing loop:
40: 0112 movfs r0,config
42: 02da and r0,r0,r5
44: 0102 movts config,r0
-> clock stops counting NOW!
46: 391f 0402 movfs r1,ctimer0
4a: 1113 add r0,r4,2
4c: 270a eor r1,r1,r6
4e: 0056 lsl r0,r0,0x2
etc.
Attempting to analyse this:
- 4 ialu - integer alu operations
- Yep, 4 instructions are executed.
- 6 ex ld - external load stalls
- This is from reading the config register.
- 8 loc fe - local fetch stalls
- From the rts switching control flow back to the caller?
- 16 ra st - register dependency stalls
- Considering no registers are being directly accessed in this section it's a little weird. rts will access lr (link register) but that shouldn't stall. The instruction fetch will access the PC, not sure why this would stall.
Still puzzled. 23 clock cycles for { rts, movfs, and, movts }, apparently.
parallella ezesdk 0.3(.1)
Just uploaded another ezesdk snapshot as ezesdk 0.3 to it's home page.
Didn't do much checking but it has all the recent stuff i've been playing with from auto-resource referencing to the fft code.
Update: Obviously didn't do enough checking, the fft sample was broken. I just uploaded 0.3.1 to replace it.
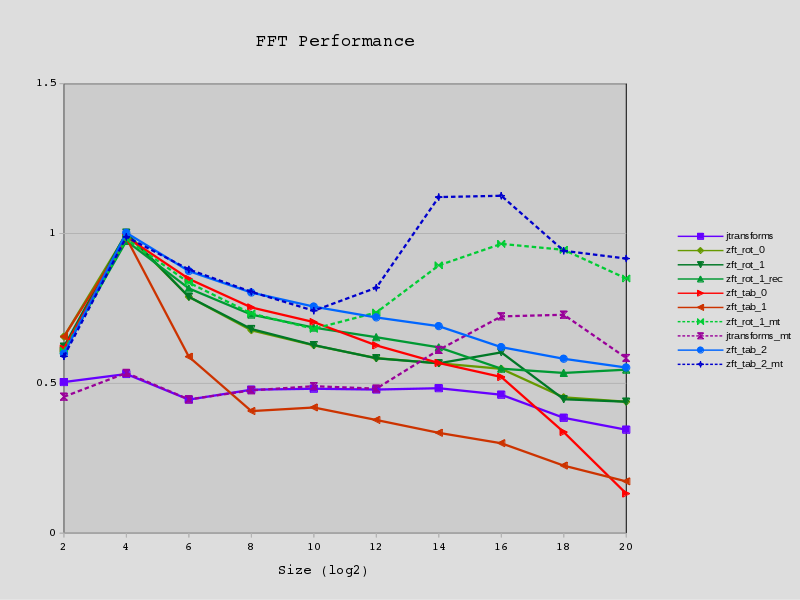
FFT(N=2^20) parallella/epiphany, preliminary results
I finally (finally) got the fft routine running on the epiphany. It's been a bit of a journey mostly because each time I made a change I broke something and some of the logarithmic maths is a bit fiddly and I kept trying to do it in my head. And then of course was the days-long sojourn into calculating sine and cosine and other low-level issues. I just hope the base implementation I started with (radix-2) was correct.
At this point i'm doing synchronous DMA for the transfers and I think the memory performance is perhaps a little bit better than I thought from a previous post about bandwidth. But the numbers still suggest the epiphany is a bit of an fpu monster which has an impedance mismatch to the memory subsystem.
The code is under 2.5K in total and i've placed the code and stack into the first bank with 3 banks remaining for data and twiddle factors.
First the timing results (all times in seconds):
rows columns noop fft ffts radix-2
1 1 0.234 0.600
2 1 0.379
1 2 0.353
4 1 0.195 0.302
1 4 0.233 0.276
2 2 0.189 0.246
4 4 0.188 0.214
arm - 1.32 0.293 2.17
The test is a single out-of-place FFT of 2^20 elements of complex float values. The arm results are for a single core.
- noop
- This just performs the memory transfers but does no work on the data.
- fft
- The fft is performed on the data using two passes of a radix-1024 step. The radix-1024 step is implemented as 5 passes of radix-4 calculations. Twiddle factors are calculated on-core for each radix-4 pass.
The first outer pass takes every 1024th element of input, performs a 1024 element FFT on it, and then writes it back sequentially to memory (out-of-place).
The second outer pass takes every 1024th element, performs a 1024 element FFT on it but with a phase shift of 1/(2^20), and then writes it back to the same memory location they came from (in-place).
- ffts
- Using the Fastest Fourier Transform in the South on an ARM core. This is a code-generator that generates a NEON optimised plan.
- radix-2
- A out-of-place radix-2 implementation which uses a pre-calculated lookup-table for the sin/cos tables. The lookup-table calculation is not included but it takes longer than the FFT itself.
Discussion
Firstly, it's a bit quicker than I thought it would be. I guess my previous DMA timing tests were out a little bit last time I looked or were broken in some way. The arm results (outside of ffts) are for implementations which have particularly poor memory access patterns which explains the low performance - they are pretty close to worst-case for the ARM data cache.
However as expected the limiting factor is memory bandwidth. Even with simple synchronous DMA transfers diminishing returns are apparent after 2 active cores and beyond 4 cores is pointless. Without the memory transfers the calculation is around 10x faster in the 16-core case which shows how much memory speed is limiting performance.
Compared to complexity of ffts (it was the work of a PhD) the performance isn't too bad. It is executing a good few more flops too because it is calculating the twiddle factors on the fly. 1 396 736 sin/cos pairs are calculated in total.
Further stuff
I've yet to try asynchronous DMA for interleaving flops and mops. Although this would just allow even fewer cores to saturate the memory bus.
Currently it runs out-of-place, which requires 2x8MB buffers for operation. I can't see a way to re-arrange this to become in-place because of the butterfly of the data required between the two outer passes.
The memory transfers aren't ideal for the parallella. Only the write from the first pass is a sequential DMA which increases the write bandwidth. The only thing I can think of here is to group the writes across the epiphany chip so at least some of the writes can be in sequential blocks but this would add complication and overheads.
The inner loops could be optimised further. Unrolling to help with scheduling, assembly versions with hardware loops, or using higher radix steps.
The output of the last stage is written to a buffer which is then written using DMA, it also requires a new pair of twiddle factors calculated for each step of the calculation which passes through an auxiliary table. These calculations could be in-lined and the output written directly to the external memory (although the C compiler only uses 32-bit writes so it would require assembly language).
The code is hard-coded to this size but could be made general purpose.
The implementation is small enough it leaves room for further on-core processing which could help alleviate the bandwidth issue (e.g. convolution).
It should be possible to perform a radix-2048 step with the available memory on-core which would raise the upper limit of a two-pass solution to 2^22 elements, but this would not allow the use of double-buffering.
I haven't implemented an inverse transform.
static resource init
I noticed some activity on a thread in the parallella forum and whilst following that up I had another look at how to get the file loader to automgically map symbols across multiple cores.
Right now the loader will simply resolve the address to a core-local address and the on-core code needs to manually do any resolution to remote cores using ez_global_address() and related functions.
First I tried creating runtime meta-data for symbols which let the loader know how the address should be mapped on a given core. Once I settled on some basic requirements I started coding something up but quickly realised that it was going to take quite a bit of work. The first approach was to use address matching so that for example any address which matched a remapped address could be rewritten as necessary. But this wont work because in-struct addresses could fall through. So then I thought about using the reloc record symbol index. This could work fine if the address is in the same program on a different core, but it falls over if the label is in a different program; which is the primary case i'm interested in. Then I looked into just including a symbolic name but this is a bit of a pain because the loader then needs to link the string pointers before it can be used. So I just copied the symbol name into a fixed sized buffer. But after all that I threw it away as there were still a couple of fiddly cases to handle and it just seemed like too much effort.
So then I investigated an earlier idea I had which was to include some meta-data in a mangled symbol name. One reason I never followed it up was it seemed too inconvenient but then I realised I could use some macros to do some of the work:
#define REF(var, row, col) _$_ ## row ## $_ ## col ## $_ ## var
// define variable a stored on core 0,0
extern int REF(a, 0, 0);
// access variable a on core 0,0
int b = REF(a, 0, 0);
This just creates a variable named "_$_0$_0$_a" and when the loader goes to resolve this symbol it can be mapped to the variable 'a' on the specific core as requested (i'm using _N to map group-relative, or N to map this-core-relative). The same mechanism just works directly for symbols defined in the same program as well since the linker doesn't know of any relation between the symbols.
So although this looked relatively straightforward and would probably work ... it would mean that the loader would need to explicitly relink (at least some of) the code for each core at load-time rather than just linking each program once and copying it over as a block; adding a lot of on-host overheads which can't be discounted. It didn't really seem to make much difference to code size in some simple tests either.
So that idea went out the window as well. I think i'll just stick to hand coding this stuff for now.
resources
However I thought i would revisit the meta-data section idea but use it in a higher level way: to define resources which need to be initialised before the code executes - e.g. to avoid race conditions or other messy setup issues.
I coded something up and it seems to be fairly clean and lean; I might keep this in. It still needs a bit of manipulation of the core image before it gets copied to each core but the processing is easier to separate and shouldn't have much overhead.
An example is initialising a port pair as used in the workgroup-test sample. There is actually no race condition here because each end only needs to initialise itself but needing two separate steps is error prone.
First the local endpoint is defined with a static initialiser and then it's reference to the remote port is setup at the beginning of main.
extern ez_port_t portb EZ_REMOTE;
ez_port_t porta = {
.mask = 4-1
};
main() {
int lid = ez_get_core_row();
ez_port_setup(&aport, ez_global_core(&bport, lid, 0));
... can now use the port
}
This sets up one end of a port-pair between two columns of cores. Each column is loading a different program which communicates with the other via a port and some variables.
Using a resource record, this can be rewritten as:
extern ez_port_t bport EZ_REMOTE;
// includes the remote port which the loader/linker will resolve to the
// lower 15 bits of the address
ez_port_t aport = {
.other = &bport,
.mask = 4-1
};
// resource record goes into .eze.restab section which is used but not loaded
// the row coordinate is relative, i.e. 'this.row + 0',
// and the column of the target is absolute '1'.
static const struct ez_restab __r_aport
__attribute__((used,section(".eze.restab,\"\",@progbits ;"))) = {
.flags = EZ_RES_REL_ROW | EZ_RES_PORT,
.row = 0,
.col = 1,
.target= &aport
};
main() {
... can now use the port
}
It looks a bit bulky but it can be hidden in a single macro. I guess it could also update an arbitrary pointer too and this isn't far off what I started with - but it can only update data pointers not in-code immediate pointer loads that elf reloc records allow for.
Not sure what other resources I might want to add though and it's probably not worth it for this alone.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!