
A better, faster sincos/cexpi
After posting about the fft implementation i've been working on to the parallella forums one kind fellow-hacker directed me to a tool which can be used to improve the error of polynomial estimates to functions. Basically to get the same or better result in fewer terms.
This gave me something to poke at for a couple of evenings but to be honest my maths skills are up shit creek these days and I had trouble working out a good approximation to cosine() or properly forming the expressions to take account of floating point precision limits.
So armed with knowledge of this new technique I did further searching and came across a few interesting papers/presentaitons from the PS2 era about function optimisation and floating point errors and then came across exactly the tool I was after sollya. So I compiled that up and had a bit of a play.
Once I worked out how it worked I did some analysis on the functions I created using lolremez, the ones I had, and some others I found on the net.
First, the 6-term expression I started with. SG(x) here casts the value to a float (C type).
> Z6=x*(SG(3.1415926535897931159979634685441851615906e+00)
+ x^2 * (SG(-5.1677127800499702559022807690780609846115e+00)
+ x^2 * (SG(2.5501640398773455231662410369608551263809e+00)
+ x^2 * (SG(-5.9926452932079210533800051052821800112724e-01)
+ x^2 * (SG( 8.2145886611128232646095170821354258805513e-02)
+ x^2 * SG(-7.3704309457143504444309733969475928461179e-03))))));
Warning: Rounding occurred when converting the constant "3.1415926535...
Warning: Rounding occurred when converting the constant "5.1677127800...
Warning: Rounding occurred when converting the constant "2.5501640398...
Warning: Rounding occurred when converting the constant "5.9926452932...
Warning: Rounding occurred when converting the constant "8.2145886611...
Warning: Rounding occurred when converting the constant "7.3704309457...
> dirtyinfnorm(sin(x * pi)-Z6, [0;1/4]);
2.32274301387587407010080506217793120115302759634118e-8
Firstly - those float values can't even be represented in single precision float - this is despite attempting to do just that. Given the number of terms, the error rate just isn't very good either.
I used lolremez to calculate a sinf() function with 4 terms, and then analysed it in terms of using float calculations.
> RS = x * ( SG(9.999999861793420056608460221757732708227e-1)
+ x^2 * (SG(-1.666663675429951309567308244260188890284e-1)
+ x^2 * (SG(8.331584606487845846198712890758361670071e-3)
+ x^2 * SG(-1.946211699827310148058364912231798523048e-4))));
Warning: Rounding occurred when converting the constant "9.9999998617...
Warning: Rounding occurred when converting the constant "1.6666636754...
Warning: Rounding occurred when converting the constant "8.3315846064...
Warning: Rounding occurred when converting the constant "1.9462116998...
> dirtyinfnorm(sin(x)-RS, [0;pi/4]);
9.0021097355521826457692679614674224316870784965529e-9
This is roughly 8x the error rate reported by lolremez or sollya with extended precision, but obviously an improvement over the taylor series despite using only 4 terms.
So using sollya to calculate an expression with the same terms whilst forcing the values to be representable in float is very simple.
> LS4 = fpminimax(sin(x), [|1,3,7,5|], [|single...|],[0x1p-16000;pi/4]);
> LS4;
x * (1
+ x^2 * (-0.1666665375232696533203125
+ x^2 * (8.332121185958385467529296875e-3
+ x^2 * (-1.951101585291326045989990234375e-4))))
> dirtyinfnorm(sin(x)-LS4, [0;pi/4]);
2.48825949986510374795541070830762114197913817795157e-9
So ... yep that's better. (0x1p-16000 is just a very small number since the calculation fails for 0.0).
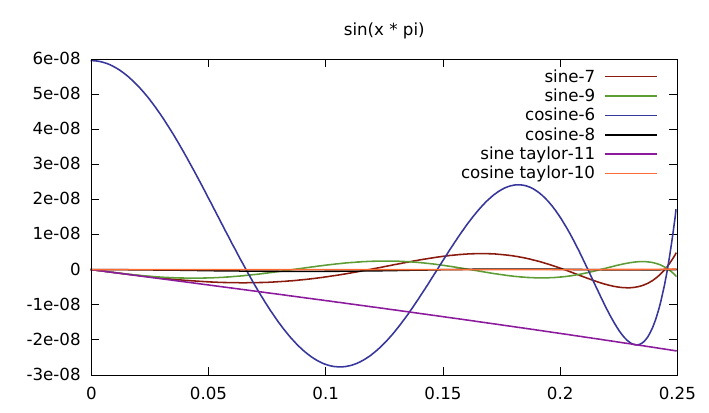
One of the most accurate other implementations I found for sin() was from an article "Faster Math Functions" by Robin Green of Sony (cira ps2 era). The first term of this function is exactly representable in float and the constants calculated using remez. I analysed this in sollya.
> RGS = x * (1 + x^2 * (SG(-0.166666567325592041015625) + x^2 * (SG(0.00833220803) + x^2 * SG(-0.000195168955)))); Warning: Rounding occurred when converting the constant "0.0083322080... Warning: Rounding occurred when converting the constant "0.0001951689... > dirtyinfnorm(sin(x)-RGS, [0;pi/4]); 3.40294295123115698469497312067470829353049357459609e-9
Note that the first term is represented in floating point exactly.
Plot time.
The lolremez version is faltering here because the first term is actually 1 in float, yet the optimisation process is assuming it has much higher accuracy and adjusting the other polynomial exponents appropriately.
> SG(9.999999861793420056608460221757732708227e-1); 1
I did some further mucking about with the tutorial which explained how to fix the first-term into one representable by floats (i.e. 1.0) but I wont include it here since it was superseded by the results from sollya with much less work (i.e. the result above). The one from the Robin Green article should be much the same anyway as it was derived in a similar manner.
cexpi()
So applying the problem to the one I was interested in - sin/cos with an integer argument, leads to the following solutions. By scaling the input value by pi, the full range is normalised to a 1.0, and powers-of-two fractions of one (as required by an fft) can be represented in float with perfect accuracy which removes some of the error during calculation.
> S4 = fpminimax(sin(x * pi), [|1,3,7,5|], [|24...|],[0x1p-16000;1/4]); > S4; x * (3.1415927410125732421875 + x^2 * (-5.16771984100341796875 + x^2 * (2.550144195556640625 + x^2 * (-0.592480242252349853515625)))) > C5 = fpminimax(cos(x * pi), [|0,2,4,6,8|], [|24...|],[0;1/4]); > C5; 1 + x^2 * (-4.93480205535888671875 + x^2 * (4.0586986541748046875 + x^2 * (-1.33483588695526123046875 + x^2 * 0.22974522411823272705078125)))
The reason for using 4 terms for sine and 5 for cosine is because at least 5 are needed for cosine for similar accuracy and it also creates a matching number of instructions since sine() needs the extra multiply by x - this also improves the instruction scheduling. Using more terms for sine only increases the accuracy by a small bit because this is hitting the limits of floating point accuracy so isn't worth it.
A closer view:
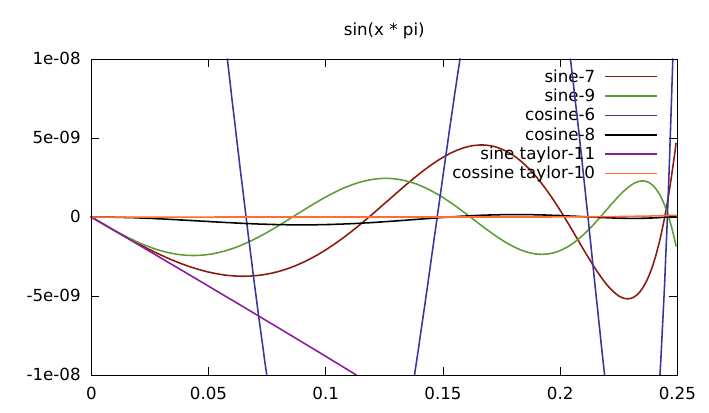
The taylor series for cosine is much better than the one for sine.
fmadd, fmul, etc
Most of the function can be implemented using multiply+add instructions if it is represented in the obvious 'Horner' form.
s = a A + a^3 B + a^5 C + a^7 D = a (A + a^2 (B + a^2 (C + a^2 D) c = 1 + a^2 A + a^4 B + a^6 C + a^8 D = 1 + a^2 (A + a^2 (B + a^2 (C + a^2 D) seq caclulation 0 a2 = a * a 1 s = 2.550144195556640625 + a2 * -0.592480242252349853515625 1 c = -1.33483588695526123046875 + a2 * 0.22974522411823272705078125 2 s = -5.16771984100341796875 + a2 * s 2 c = 4.0586986541748046875 + a2 * c 3 s = 3.1415927410125732421875 + a2 * s 3 c = -4.93480205535888671875 + a2 * c 4 s = a * s 4 c = 1.0 + a2 * c
Another way to represent the expression is using Estrin's method. I found this mentioned in the stuff by R.Green and he references Knuth.
This breaks the expression into independent sub-trees which can be calculated concurrently. This is obviously quite useful for SIMD calculations but can also be useful on a serial processor with a deep pipeline as it reduces the number of stages with serial dependencies.
s = a A + a^3 B + a^5 C + a^7 D = a ( (A + a^2B) + a^4 (C + a^2 D) ) c = 1 + a^2 A + a^4 B + a^6 C + a^8 D = 1 + a^2 ( (A + a^2 B) + a^4 (C + a^2 D) ) seq calculation 0 a2 = a * a 1 a4 = a2 * a2 1 s0 = A + a2 * B 1 s1 = C + a2 * D 1 c0 = A + a2 * B 1 c1 = C + a2 * D 2 s3 = s0 + a4 * s2 2 c3 = c0 + a4 * c2 3 s = a * s3 3 c = 1 + a2 * c3
This requires 1 more floating point instruction: but it executes in 3 stages of dependent results rather than 4. If latency of the calculation is important or if there are no other instructions that can be scheduled to fill the latency slots of the fpu instructions this would execute faster.
Exact floats: Hex Float Notation
Whilst looking through some code I came across the hexadecimal float notation which I hadn't seen before. I've been wondering how to correctly encode floating point values with exact values so this I guess is the way.
Sollya can output this directly which is nice, so the above expressions can also be represented (in C) as:
> display = hexadecimal; Display mode is hexadecimal numbers. > S4; x * (0x3.243f6cp0 + x^0x2.p0 * (-0x5.2aefbp0 + x^0x2.p0 * (0x2.8cd64p0 + x^0x2.p0 * (-0x9.7acc9p-4)))) > C5; 0x1.p0 + x^0x2.p0 * (-0x4.ef4f3p0 + x^0x2.p0 * (0x4.0f06ep0 + x^0x2.p0 * (-0x1.55b7cep0 + x^0x2.p0 * 0x3.ad0954p-4)))
So the hex number is the mantissa, and the exponent is relative to the decimal point in bits. It wont output expressions in IEE754 encoded values directly but they can be printed (useful for assembly).
> printsingle( 0x3.243f6cp0); 0x40490fdb > printsingle(3.1415927410125732421875); 0x40490fdb
Goertzel's Algorithm
There are other ways to calculate series of sincos values quickly. One is Goertzel's Algorithm. It can calculate a series of sin/cos values of the form sincos(a + i*b), which is exactly what is required.
An example implementation:
float cb = 2 * cos(b);
// offset by 3 terms back
float ag = a - 3 * b;
// can be calculated using summation rule
float s1 = sin(ga+b);
float s0 = sin(ga+2*b);
float c1 = cos(ga+b);
float c0 = cos(ga+2*b);
// unroll the inner loop once to simplify register usage/reusage
for (int i=0;i<N;i+=2) {
s1 = cb * s0 - s1;
c1 = cb * c0 - c1;
s0 = cb * s1 - s0;
c0 = cb * c1 - c0;
out[i+0] = c1 + s1 * I;
out[i+1] = c0 + s0 * I;
}
Unfortunately, floating point addition pretty much sucks so this will drift very quickly if cb*X is appreciably different in scale to Y in the cb*x-Y expressions. So error depend on both b and a, which leads to a funky looking error plot.
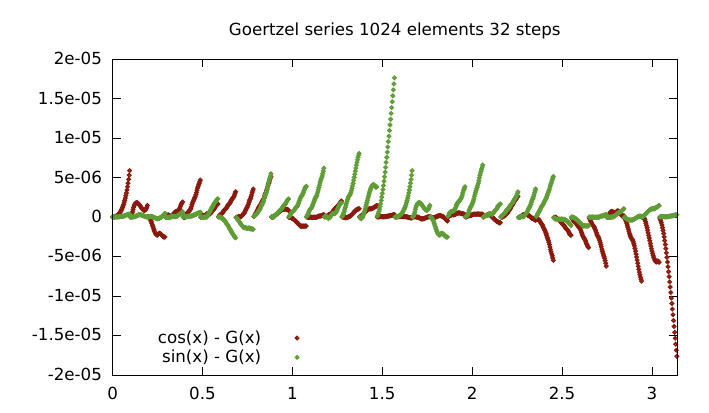
Where a = j*32*PI/1024 | j= (0 ... 31), b = PI/1024.
Was worth a try I guess.