
PDFZ searching
So after finding and fixing the bug in my outline binding - a very stupid paste-o - I added a table of content navigator to PDFReader, and then I had a look at search.
Which ... I managed to get working, at least as a start:
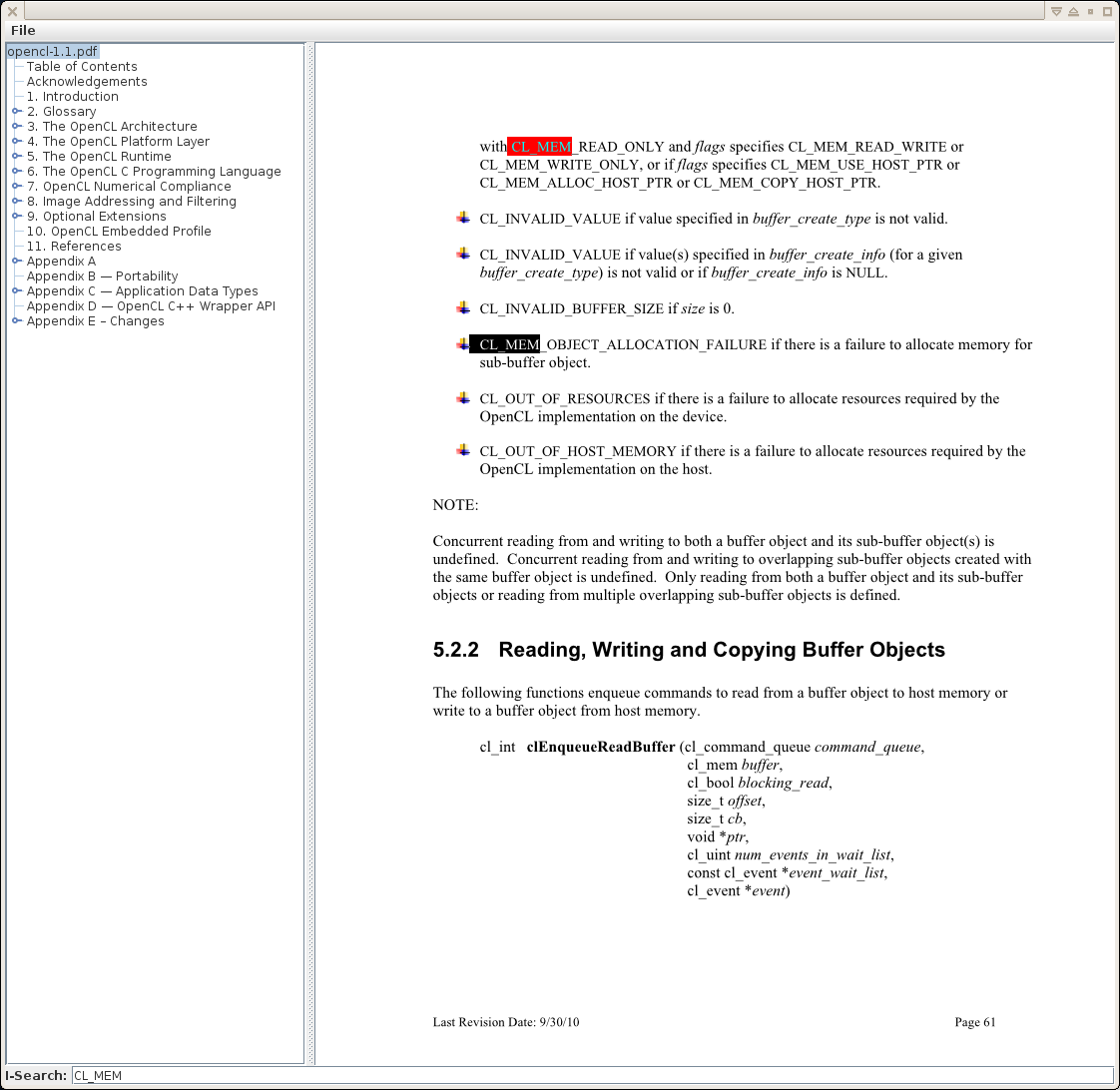
As can be seen, it's a little flaky - mupdf is adding spaces here and there in the recovered text, and i'm not sure i'm processing the EOL marker properly (and possibly I have a bug in the search trie code too). But as I said - it's a start.
I decided to use a Trie for the search (Aho-Corasick algorithm) - because I know it's an efficient algorithm, and because I know there was a good implementation in evolution. So I grabbed an old copy from the GPL sources and modified it to work on the mupdf fz_text_span code. Thanks Jeff ;-) Basically it's a state machine that can match multiple (possibly overlapping) words whilst only ever advancing the search stream one character at a time.
I tried to copy the emacs mode of searching to some extent:
- / or ctrl-s starts a search
- The search updates immediately for the current page as characters are typed.
- The next search on the current page is highlighted when ctrl-s is pressed again.
- If there are no more results on the current page, the search starts scanning the document if ctrl-s is pressed again.
- ESC closes the command prompt.
I put some code in there to abort the search if the page is changed while it's still searching (because I hooked the search into the page loader/renderer), but on the documents i've tried it on it's been so fast I haven't been able to test it ...
This is one of the first times I used JNI to create complex Java objects from C - the array of results for a given page. It turns out it's fairly clean and simple to do.
I guess the next thing is to see if i can integrate the search functionality into ReaderZ. Time to write one of those horrible on-screen keyboards I guess ...
But for now ... the weather's way too nice to be inside, so I think it's off to the garden, beer in hand ...