
LBP face cascades, scaling, etc.
So whilst converting the LBP cascade stuff from OpenCV 2.4 to my code, I noticed that the cascade code in general had changed the way it worked. Now rather than scaling the features, it only ever scales the images.
Netbeans' profiler was reporting the scaling operation in my code (I wrote a mip-map based scaler) was taking a good chunk of the processing time (however, subsequently I can't get reasonable results out of the profiler at all, so I think something is quite broken there), so I thought i'd see if i could scale the features for the LBP algorithm, rather than scale the source image.
I only scale the features by integer amounts - this makes the feature testing much simpler (and more reliable?), and should work ok so long as the faces are big enough relative to the training size.
My initial results had me worried - it was running 10x slower. But then I realised it is detecting many more hits, and now I see it's simple testing many more locations at each scale.

This is using the same algorithm as in OpenCV, showing the raw hits before they are grouped and averaged. I think the sparsity of results is because the step size is fixed relative to the scaled image, so it just does far fewer probes to start with.
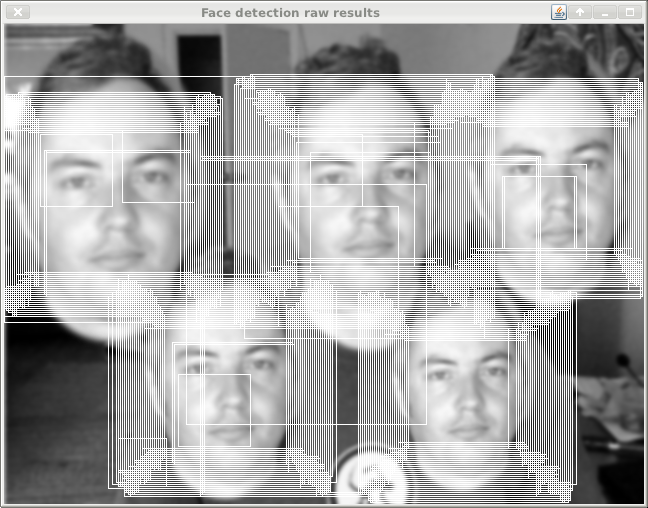
This is the raw hit result from scaling the feature tests instead, using parameters that result in a similar number of scales tested (but many more locations as they are global-size relative).
If I tweak the probe factors so that a similar number of probes execute, then the feature-scaled version executes slightly faster, which is what I was trying to determine in the first place.
Given that the feature tests are more or less an LBP 8,1, perhaps using the summed area table to do the averaging is producing a more reliable result, but I think the different results are just from the probe differences.
Update: I think the sparse/aliased results are just from poor resampling.
Update 2: Regarding the LBP cascades supplied by OpenCV as asked by Div below ... unfortunately the OpenCV code is pretty difficult to read. It was pretty bad as C, but the C++ has made it worse as code is spread over multiple places now.
Luckily it's fairly straightforward though: the rectangles describe a region over which a "regional" LBP code is created. The rectangle encoded is the top-left "pixel" for a 3x3 LBP code.
So for example if the rectangle was (5,6,1,2) the 9 values required to calculate the LBP code (i.e. centre pixel and surrounding 8) are taken as the average of the pixel values over the following regions:
(5,6) +-+-+-+
| | | |
|7|6|5| The cell number is the bit number of the LBP code
+-+-+-+ Each "cell" is 1x2 pixels in size
| | | | This template is applied relative to the
|0|C|4| current scanning window.
+-+-+-+ A summed area table is used to calculate
| | | | the average "efficiently"
|1|2|3|
+-+-+-+ (8, 12)
These coordinates are either scaled, or the input image is scaled before generating the summed area tables.
The rest of the record for each region is a bit table (stored as signed integers). The region is used to calculate an LBP code, and it is looked up in the bit table. If the bit is set you use one weight, otherwise you use the other and just sum them up for the stage.
BTW I gave up on using the LBP cascades - the supplied ones weren't good enough, and I couldn't get the training to work to any useful extent. I wrote a C version of the Haar cascade code and got pretty comparable run-time performance anyway so the last reason to use the LBP version evaporated.
Update 3: Further response to David below ...
The 46 is just the index of which <rect> to get from the <features> array.
Rather than store it like that in memory it should be more efficient to pack the rectangles together with the stage data rather than just store indices. This structure is walked very very often. OpenCV stores the rectangles as offsets relative to the size of the image as well, which is another optimisation worth doing.