About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

LBP face cascades, scaling, etc.
So whilst converting the LBP cascade stuff from OpenCV 2.4 to my code, I noticed that the cascade code in general had changed the way it worked. Now rather than scaling the features, it only ever scales the images.
Netbeans' profiler was reporting the scaling operation in my code (I wrote a mip-map based scaler) was taking a good chunk of the processing time (however, subsequently I can't get reasonable results out of the profiler at all, so I think something is quite broken there), so I thought i'd see if i could scale the features for the LBP algorithm, rather than scale the source image.
I only scale the features by integer amounts - this makes the feature testing much simpler (and more reliable?), and should work ok so long as the faces are big enough relative to the training size.
My initial results had me worried - it was running 10x slower. But then I realised it is detecting many more hits, and now I see it's simple testing many more locations at each scale.
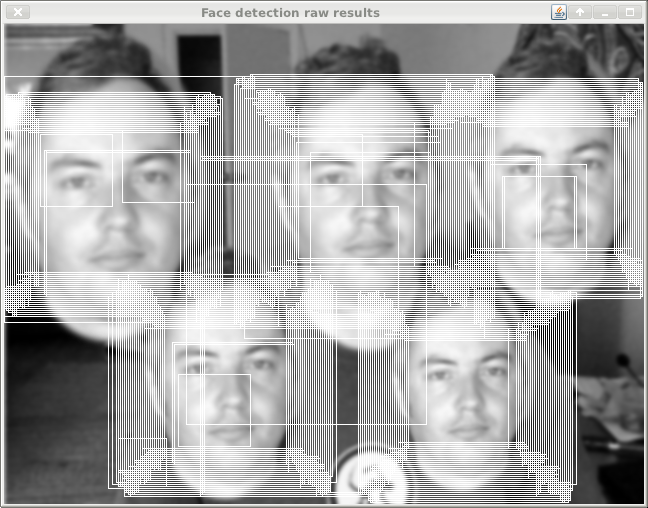
This is using the same algorithm as in OpenCV, showing the raw hits before they are grouped and averaged. I think the sparsity of results is because the step size is fixed relative to the scaled image, so it just does far fewer probes to start with.
This is the raw hit result from scaling the feature tests instead, using parameters that result in a similar number of scales tested (but many more locations as they are global-size relative).
If I tweak the probe factors so that a similar number of probes execute, then the feature-scaled version executes slightly faster, which is what I was trying to determine in the first place.
Given that the feature tests are more or less an LBP 8,1, perhaps using the summed area table to do the averaging is producing a more reliable result, but I think the different results are just from the probe differences.
Update: I think the sparse/aliased results are just from poor resampling.
Update 2: Regarding the LBP cascades supplied by OpenCV as asked by Div below ... unfortunately the OpenCV code is pretty difficult to read. It was pretty bad as C, but the C++ has made it worse as code is spread over multiple places now.
Luckily it's fairly straightforward though: the rectangles describe a region over which a "regional" LBP code is created. The rectangle encoded is the top-left "pixel" for a 3x3 LBP code.
So for example if the rectangle was (5,6,1,2) the 9 values required to calculate the LBP code (i.e. centre pixel and surrounding 8) are taken as the average of the pixel values over the following regions:
(5,6) +-+-+-+
| | | |
|7|6|5| The cell number is the bit number of the LBP code
+-+-+-+ Each "cell" is 1x2 pixels in size
| | | | This template is applied relative to the
|0|C|4| current scanning window.
+-+-+-+ A summed area table is used to calculate
| | | | the average "efficiently"
|1|2|3|
+-+-+-+ (8, 12)
These coordinates are either scaled, or the input image is scaled before generating the summed area tables.
The rest of the record for each region is a bit table (stored as signed integers). The region is used to calculate an LBP code, and it is looked up in the bit table. If the bit is set you use one weight, otherwise you use the other and just sum them up for the stage.
BTW I gave up on using the LBP cascades - the supplied ones weren't good enough, and I couldn't get the training to work to any useful extent. I wrote a C version of the Haar cascade code and got pretty comparable run-time performance anyway so the last reason to use the LBP version evaporated.
Update 3: Further response to David below ...
The 46 is just the index of which <rect> to get from the <features> array.
Rather than store it like that in memory it should be more efficient to pack the rectangles together with the stage data rather than just store indices. This structure is walked very very often. OpenCV stores the rectangles as offsets relative to the size of the image as well, which is another optimisation worth doing.
OpenCV, android, java, C++, suckage
So I needed to code up a prototype and I thought it was probably time to use OpenCV rather than write it all from scratch again, since I didn't need OpenCL at this time. I've always avoided OpenCV because the code within it is horrid, the API a bit ugly, and it's almost impossible to build it without the right version of GNU/linux (let alone for another platform).
I think I probably made a mistake here ... because I'm not sure much has changed, or if it has it's only for the worse.
First I was just using the android api - i thought that the same api was available to java generally, but it's pretty hard to find out if that's true. The only README just points to a generic web page, and who knows what cmake is doing to decide it wont build anything Java. Although I have some stuff working on android I wanted to drop back to the desktop to ease some experimentation I need to do.
cmake - boy that sucks total arse. When it does work there is no information on how to control it (e.g. why does it say Unavailable: java), and it's just a shitty piece of crap anyway.
And so does C++. C++ is such a shit language.
OpenCV on android is just slow as fuck anyway. Just a simple live webcam can barely hit 10fps without even doing anything. Changing the camera resolution barely makes much difference, so there's something funky going on. There's so much debug snot in `logcat' that you can't even tell what you're own application is doing let alone OpenCV.
The Java API is really pretty horrible anyway. Everything seems to go through an opaque type 'Mat', but then you still need to know what's in it. It seems to be because the C++ API is also horrible. It's kind of like they're trying to make it "matlab for C++", which probably makes sense for their target audience of non-programmers, but otherwise it totally sucks.
I would have been better off just coding up the routines I need from scratch (I already had to do one of them as it was a contrib api which isn't exposed, and I couldn't get custom jni to work to bind it), as they're fairly simple and easy to use once you give them a decent api.
(Yes I could use JavaCV but it still brings along with it a lot of the hassles, and the library it uses is still the same).
Thunderbird deprecation
So apparently Mozilla have announced that Thunderbird will no longer get active development, and merely security updates.
Well you could have fooled me - I gotta say it's a pretty uninspiring bit of software, and from the way it works I could have sworn they stopped developing it a decade ago.
It's like a reasonably competent email client from the 90s. Sure it does the job, but there's certainly no flair there and it's really just a bit clumsy at doing everything.
I've been using it for about a year since gmail became too slow in firefox and loaded my laptop too much. But for all it's faults it's still better than gmail, and I don't have to put up with adverts either. I still can't look at evolution after 7 years ...
Zed's Red Fermented Weird Sour Chilli Sauce
Well i'm back to work next week so i've been taking a break from hacking before getting back into it. Brewed some beer (second wart going now), cleaned the windows (i'm still surprised how much difference it makes), did some more preserving and cooking ...
Many moons ago - last year some time - I fermented some red chillies with the goal of making some tobasco style sauce. I did the same from some green chillies and I just ran out of that (or just can't find it in the cupboard), so I thought it was about time I did something with the red ones before the mould ate it all ...
So I scraped off the white mould, added some vinegar (1/2 a cup or so, didn't measure), lime and lemon juice (4 of each), blended it, sterilised it and bottled it. No sugar or anything else.
If nothing else it has an absolutely amazing colour ...
Flavour is interesting - quite sour. Definitely nothing like tabasco (unlike the green one I made which was much more vinegary and fairly close to green tobasco sauce), but it does emphasise the sour note from the fermentation which is what I wanted - the green version masked it too much in the vinegar. Given it was from Cayesan chillies it isn't too spicy either. House-mate thought it was reminiscent of green mango.
I have a small jar of habaneros i fermented too, originally I was intending to make a `super' tabasco sauce with that, but I think I will just leave those as sliced pickled chillies. Damn damn hot too - can't really add more than about 1/2 teaspoon to a bowl of food without suffering too much ...
Oh I tried the salted kumquats i made a few weeks ago. Well, they taste like salty kumquats in lemon juice and a little like lime pickles. Not sure what i'll do with them ...
It's almost time to look at getting some seedlings going again this year.
Update: I really like this sauce, very nice as a dipping sauce for pork or chicken. Very moreish, and not too overpowering in heat. I also found a use for the kumquats - works pretty well in a bean dish i've been making (bacon, beans, green tomatoes, herbs, stir fry, not stewed) to add some depth - although it's easy to over-do the salt.
Your browser is not supported ...
Great, now i get a fucking advert for some shit browser I don't want to use every time i do anything in blogger.
Lime marmalade Incinerade
Still have more fruit than I can use, so I made some lime marmalade. Added a pile of Habanero chillies as well, so it's pretty hot. Not sure what i'll use it for ... it's more like a lime + chillie jelly with a bit of bitterness.
Got of the infernal machines yesterday and got a bit productive in general, also did 3 loads of washing, mowed the lawn, started brewing some beer ...
Ingredients
| 500g |
Finely sliced ripe limes (mine are yellow on the outside with a very thin skin, lime-green on the inside, and very juicy). |
| 40g |
Finely sliced Habanero chillies (this is a TON of heat) |
| 60g |
Grated ginger |
| 600ml |
Water (i.e. equal weight to fruit) |
| 600g |
Sugar (i.e. equal weight to fruit) |
|
Pips from some other pippy citrus. I used half a dozen kumquats which are loaded with large seeds. |
Method
- Place the lime, chillies, ginger and water in a pot and soak overnight.
- Wrap the pips in some chux and tie up, place in the pot and bring to the boil.
- Simmer for at least 30 minutes.
- Pour in the sugar and stiry until dissolved (I initially removed the pips at this point, but as it took forever to set I put them back).
- Simmer until it sets on a plate in the freezer, 30 minutes plus. It's supposed to skin when pushed.
- Pour into sterlised jars and seal while still hot. Makes about 4.5 250ml jars.
I had trouble geting the 'plate set test' to work - and ended up simmering it for a bit over an hour. But when I went to bottle it it started to stick in my funnel after the first jar and it turned solid enough to turn upside-down as soon as it cooled off a bit. In short I think I cooked it a bit longer than I needed to, but not enough to hurt it (made it a bit more orange coloured than it would otherwise have been).
Initially I only put 40g of habaneros, but I thought I may as well make it worth the effort and grabbed a few more from the freezer as I was cooking it.
Results
Has a nice sweet and intensely lime flavour with a generous hint of marmalade bitterness. It set solid - like jelly - although it is cloudy (mostly from the ginger pulp I guess).
The habanero chillies add a big kick - that gets more intense with each drop as they usually do. I had some tiny amount with kabana and cheese on crackers and it worked pretty well. Yet to try it on toast with coffee ..
It looks and smells like a nice sweet marmalade, but a corn-kernel sized piece is enough to set your whole mouth afire.
arm, tegra3, neon vfp, ffmpeg and crashes
So I just did a release of jjmpeg including the android player ... and then a few hours later finally discovered the cause of crashes I've been having ...
Either FFmpeg, the android sdk compiler or the Tegra 3 processor (or the way i'm using any of them) has some sort of issue which causes bus errors fairly regularly but never repeatably. Possibly because of mis-aligned accesses. Unfortunately when I compile without optimisations on - the build fails, which makes it a bit hard to debug ... i got gdb to run (once only though, subsequent runs fail), and got a half-decent backtrace, but optimistions obscured important details.
Anyway i noticed that 0.11.1 has a bunch of ARM work, so I upgraded the FFmpeg build, and mucked about with the build options for an hour trying to suss out the right ones and to see how various ones worked.
Short story is that using armeabi-7a causes the crash to appear (with any sort of float, vfp, neon, or soft), and dropping back to armeabi fixes everything.
Unless I can get better debugging results I think i'll just stick with armeabi for the foreseeable future. I can't find anything recent about these types of problems, so perhaps it's just my configuration but I really just don't know enough about the ARM specifics at this point to tell either way.
Well, that's enough for today.
Update: I spent another day or so on this and finally nutted it out. It was due to alignment problems - but it was odd that it happened so rarely.
As best I could work out, ARMV6+ allows non-aligned memory accesses, but the standard ARM system control module can be programmed to cause faults. And just to complicate matters the ARM linux kernel has the ability to handle the faults and implement the mis-aligned access manually, and this the behaviour can be configured at run-time via proc. It seems the kernel on my tablet is configured to cause faults, and not having administrative access I am unable to change it ...
So the problem is that FFmpeg's configure script assumes mis-aligned memory accesses are safe if you're using armv6 or higher. Anyway I filed a bug although so far indications are that the bug triager doesn't know what I filed (see update 2) - i'm not fussed as I have a work-around that doesn't require any patch.
I had wasted a lot of time based on thinking it was neon or optimisation related, whereas it was just ARMv5 vs anything else behaviour. When i finally did get it to compile without optimisation turned on, the backtrace I got was still identical and so worrying about getting a good backtrace was pointless. I had wrongly assumed that a modern cpu would handle mis-aligned accesses ok, not working at the assembly language level for a while gets you rusty ...
I suppose the main upshot of posting on the libav-user list ... that mostly just resulted in me wasting a full day of fucking about ... is that I realised my configure invocation was still broken (more problems one got from copying some random configure script from the net) and so I managed to clean it up further.
Bit over it all now.
Update: So the actual fix was to run this sed command over config.h after configure is executed:
sed -i -e 's/ HAVE_FAST_UNALIGNED 1/ HAVE_FAST_UNALIGNED 0/' $buildir/config.h
Update 2: Good-o, they've just added a configure option to override it.
Update 3: Can anyone tell me why this post is getting so many hits over the last month or so (June '14) It's showing up in the access stats but there's no info on why.
"Fuck you Nvidia" (and other news of the day)
So apparently Linus blew his top a bit and gave the bird to Nvidia with a pretty clear verbal message to match. Well if nothing else that'll be a keeper of a picture that will bounce around the internet for years to come ...
Of course, he has only got himself to blame here - if he didn't allow binary blobs to link into the kernel in the first place (choosing to discard rights that copyright gives him) then he wouldn't be in this situation would he? After-all, it was his decision alone - he could have gone either way and the rest would follow.
So much for pragmatism ...
So I guess we'll see where it goes in a few years when UEFI tivo-ises every hardware platform you buy, and you can no longer compile your own kernel or write your own operating system on your own computer, even if it is running a 'free' operating system.
Of course industry consortia such as Linaro are right behind UEFI - anyone who sells appliances would love to lock them down giving them forced obsolescence - when in reality hardware is approaching the point where software is taking over many of the functions, and is capable of much more than it's original firmware allows it. I find it pretty offensive that the guy in the linked video regards anyone who doesn't like UEFI as a pirate ...
Microsoft laptop and/or tablet
Well things must be in dire straits in microsoft's windows-rt land. One can only guess that the OEMs simply aren't embracing the platform with enough zeal - there seems no other sane reason that they would want to create their own tablet (and/or laptop, or whatever it is).
Unless it's just pure greed - which of course isn't something that can be discounted entirely. At least in part they probably think they can recreate the xbox success story - which given how much it cost, clearly wasn't anywhere near as successful as the internets would have you believe.
I bet the few OEMs even looking at microsoft windows-rt are going to be given some moment for pause with this announcement.
Nokia
The only `OEM' to embrace microsoft will probably be nokia.
But they're totally fucked and who knows if they'll even see out the calendar year. They only ever made good phones, and now they don't even do that - who is going to buy a PC from them, even if the form-factor is a tablet.
But what has happened to nokia is a rant for another person - I've had a couple of old nokia phones over the years and I thought they were fine, but I don't have any connection to them other than a shared sense of disappointment in what has become of a great company in such an astoundingly short period of time.
Transformer prime
Finally got a firmware upgrade to the transformer prime last week. TBH I can't tell any difference - if anything the browser hangs more with 'application not responding' (or whatever it says) than it did before. Not that i've been using it a great deal - it's a pretty clumsy way to do anything.
I hurt my foot again (well, this time it was my other foot - my guess is my overly sedentary work-at-home lifestyle for the last few years is catching up with me and I have to at least start taking regular walks to repair my feet - even when i venture out it's mostly cycling) so I was pretty much immobile for a few days. So I dragged out the tablet and used it for some web reading and even tried a few games.
Even the touchy feely games (I downloaded some 'bridge builder' and 'physics challenge' games) which seem well suited to the tablet are a bit of a pain to control with a fat imprecise finger which obscures what you're doing. Trying to use it in bed is annoying as you need two hands to hold it - the auto-rotate stuff is a pain in the arse too - so that gets turned off anyway. As a web browser it is just ok - portable - but again you need to prop it up to use it, or bend over it, and the fat-finger-mouse can make using any web page frustrating. Not to mention all the annoying adverts I haven't seen for years (well at least the flash stops when you're not looking at it - something i never understood about firefox after it had tabs).
About the only good thing about it is it still has a battery that works - so I can use it without a tether - unlike my laptops whose batteries are all dead now. Those batteries are too expensive to make them worth replacing. But other than the battery having died so it is tethered to my desk, my X61 thinkpad is a much easier to use and much more useful device: I use it for email and forums, and most of my browsing.
Once the tablet battery dies it'll be pretty shit as the connector is in an inconvenient place.
I'm still working on the android jjmpeg stuff though - mostly just for my own entertainment. I have the code back ported to amd64 now, but I haven't seen any crashes - valgrind gives a bunch of hits but it's always hard to tell if that's just the JVM doing funky shit or real problems (none of the stack traces show anything useful, even with a debug build).
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!