
eye detector again
I was playing around with generating ROC curves for various algorithms - first I was trying to determine whether some new LBP codes I came up with worked better in certain cases (not yet, but they have promise, ok i kept playing as below: maybe they do already). For this purpose I implemented a basic LBP histogram matching algorithm, as I figured having baseline would provide a decent comparison.
This just took all eye images as one class and all non-eye images as another and then measured the distance of them all to the classifier. I'm using 20x20 images and the classfier creates 16 histograms from 8x8 tiles overlapping by half in each direction. It isn't terribly valid as a measure because it is using the same set for training and for testing but i'm only after the relative results. There are 10560 positive training examples and 9940 negative examples in the data set, all taken (and synthesised) from Color FERET fa partition. I'm only using abs difference as the distance measure which isn't ideal, and perhaps the 8x8 tile area isn't a large enough sample to build a decent histogram - in short, these histogram results are not tuned for performance.
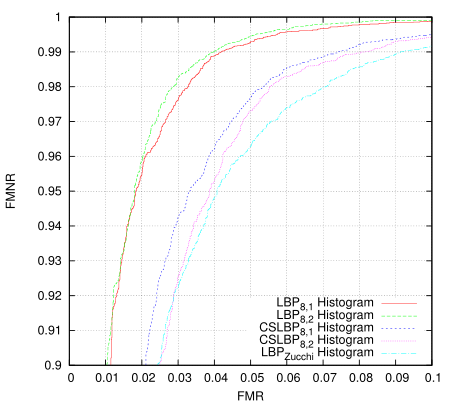
The Zucchi LBP is using some directional differential filters in order to build the LBP code bit-planes. The idea is that they're tunable to the problem, should be more robust to noise, and generally produce a more noise-free and accurate LBP code. They are much more expensive to calculate however. This tunability offers another possibility for GA optimisation. I guess this is something else I should really write up properly.
Then I revisited the classifier I came up with late 2012 (the one I put into a small android app). Here the data and LBP transform are the same, only the algorithm has changed.
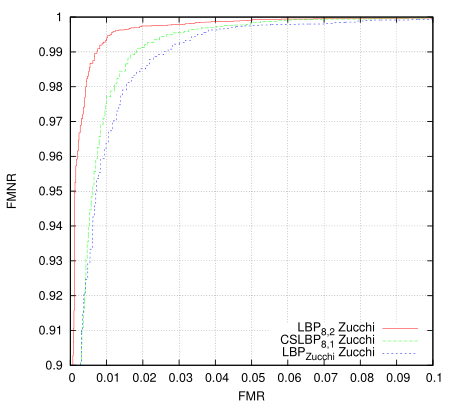
Blew me away a bit, I really didn't expect that much of an improvement. The 'Zucchi' algorithm requires a tiny fraction of the storage and fewer cpu instructions to process. Training takes more memory but fewer instructions per pixel. The original goals in designing it were for it to be SIMD parallelisable (at execution time) so it optimises very well. The first algorithm should be more robust to registration errors, but on this test the differences are remarkable and in many cases you don't want/need such robustness.
Then I wondered if this classifier could be trained using GA instead. Here I truncated the training set to 8192+8192 images to match the OpenCL GA algorithm, so the results are slightly more valid.
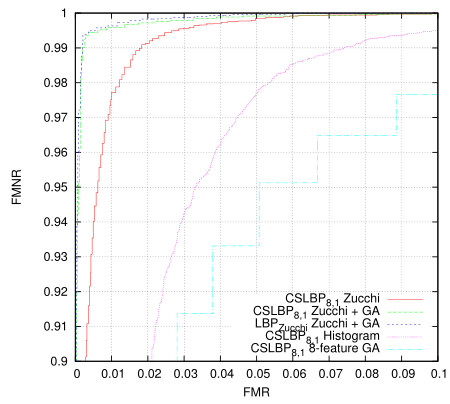
Somewhat surprisingly given the size of the problem (each individual is ~6K bits) it works extremely well and attains a result in only 300 generations. Actually the problem I have is that it is almost too good(tm) - before doing much of a search of the problem space the utility of the fitness measure has been exhausted and the population no longer evolves. One might also note that this result is for the relatively information poor 4-bit LBP codes, and in all cases is only a single-stage classifier.
Given the results I should probably look at the data that isn't classifying properly at each end, some of it may just be poor / incorrectly labelled data. Update: I had a look - the false negatives at the upper end are from synthesised images some of which are over-rotated or rotated off-centre. A couple of the false positives are samples taken a bit too close to the eye although most are legitimate and from around under the nose to under the mouth.
The 8-feature test as described in the previous post doesn't fare so well here - even though it is an effective eye detector in practice and requires about 1/3 of the processing.
Here the differential LBP code is working very well too. And it works extremely well as an eye detector in practice.

For this post I wasn't going to run the differential LBP codes through the GA algorithm based on the first plot - it didn't seem that good. But the final plot and this eye detector heat map somewhat validates the initial reasoning behind the algorithm - reduced noise. See the previous post.
Looking closer at the LBP code image I now see there isn't enough similarity between the left and the right eye regions in the LBP domain to try to create a classifier which resolves both at the same time. What I might do instead is create separate classifiers but not include the other eye in the negative training set - this should improve the results of both. I guess i'm near the point where spectacles should be added to the mix.
I've started writing some of this up but i'm a bit lazy to put the effort in required to do a good job. Apart from the fact that i'm only doing this for self education and entertainment purposes in my spare time right now, i've little experience writing papers. I'm purportedly on holidays for that matter - technically i'm even unemployed but literally i'm just between contracts.
Update: Oops, looks like I made a bit of a mistake. I thought I was using a decent resampler whilst generating the scaled training data, but it wasn't - so aliasing was creating noise in the small-scale images and thus in the LBP codes. This is probably why the derivative LBP code managed to win out in the end. This mistake will lead to the plots showing poorer performance than they should be - but i'm not going to re-run the plots right now.
Seeing that the classifier was doing such a good job, I thought i'd push it a bit harder. I have a couple of other ideas too but the first one I tried was to create a classifier for a very small region. This has very large implications on execution time. So whilst working on an 8x8 classifier I noticed the aliasing and realised the scaling problem. I still have an issue with pixel-boundary sampling when extracting the normalised eye so the data is of a lower quality - but it has to deal with these problems in the input data too.
An 8x8 detector is absurdly small. Here's an example of a decent training image from the training set:

Testing on Lenna's photograph gives quite a few false positives - but out of 181 244 tests, 30 or even 100 false positives isn't too bad for a single-stage classifier. An 8x8 classifier requires 16x less total processing from the inner loop vs a 16x16 classifier to detect the same sized features at the same input scale - so even a modest true negative rate could be a big win if it is reliable. And this doesn't count the image scaling and LBP operator both of which also scale at an N*N rate.

This is just one run of a single-pass 8x8 detector generated via a GA using left and right eye images as the positive set. The threshold was chosen roughly. There are a total of 43 hits out of a total of 181 244 probes, with a false acceptance rate of 0.022%. It took about an hour to generate this detector via pure-Java code on a 6-core intel machine.

This is one run of a single-pass 20x20 detector generated via GA using left-eye images as the positive set. It is being executed over a wide range of scales from 0.2x to 1.5x of the original (512x512) source. There are a total of 22 hits out of a 5 507 592 probes, with a false acceptance rate of 0.00016%. It took about 3 minutes to generate the classifier using the same pure-Java code on the 6-core intel at which point evolution stopped due to having a perfect classifier on the training data set. It took under 200 generations on the improved input data vs the numbers in the top-half of this post.
Update 2: I wasn't going to, but I compared it to the raw results from the left-eye cascade from OpenCV - i remembered it not being particularly good but wanted to quantify it. This is showing the raw hits as exit the cascade and do not include grouping which would remove most of the false positives. There are 313 total hits.

For comparison purposes I re-ran the 20x20 classfier with settings that result in about the same number of scans at roughly the same scales. Here there are 64 total hits, although I just chose an arbitrary threshold value (a fairly loose one however). Haar cascades only provide a binary true/false result and have no threshold that can be adjusted - they also provide no quality indicator so there is no way to choose a peak match and one must resort to error prone averaging and merging.

This code executes about 30% faster than the haar cascade although perhaps the looseness of the haar detector would allow it to be run on fewer locations at the cost of accuracy. However; accuracy is often important if not critical. It should be possible to train a better haar-cascade but I haven't had any luck geting even close to the ones supplied in OpenCV. Likewise this is still only a single-stage classifier and can still be improved (I think) quite easily.
One last data point - the 8x8 classifier over similar scales executes 10-20x faster. These classifiers also scale much much better on parallel hardware - all the way from SIMD to multi-stream GPUs, so this 30% figure is a little misleading. It would also take only a tiny bit of FPGA logic ...