
better edges
Been poking more at the renderer. I have a fairly clean set of routines now that can be used to implement most of what I need: generating fragments, interpolating arbitrary parameters, handling a depth test.
And well, just running it and looking at the pretty pictures ...
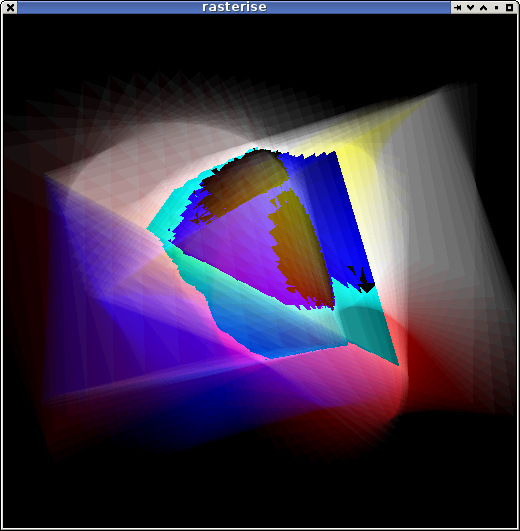
The Z/W buffer stretched to 8-bit:

Add a few more, use a different 'fragment shader', ... polygonal shade-bobs.
I'm still just running stuff in Java on my workstation but i've been doing a lot of experimenting with micro-optimisations an trying to work out how i'm going to split the work up.
My current idea is to process the scene by complete scan-lines rather than tiles. This greatly simplifies the looping and address arithmetic but would not be very efficient for texture lookups. I'm basing the following on a loose understanding of a gpu pipeline but erring on the side of epu-efficiency.
- The first pass would basically just find out which triangles are live on the current line and determine the triangle leading edge. Walking the triangle edges is surprisingly involved.
- The second pass converts this span into fragments, interpolating z/w, 1/w ,and the triangle parameters/w and performing z-buffer tests. The result of this pass will be sent to an epu for processing. Each parameter requires a single addition per pixel. The data sent to the epu will be the pixel location, each interpolated parameter, and the interpolated 1/w.
- The fragment processor will perform the reciprocal calculation (1/1/w) and convert the parameter/w values to parameter values and invoke the fragment shader. The reciprocal calculation is relatively expensive but by batching up several the cost can be reduced significantly - I have some C code that takes about 12 cycles/reciprocal if 6 care calculated concurrently. Because the fragment processor doesn't have to perform a per-pixel to test so see if the pixel is live it can more efficiently batch this calculation up compared to performing it in the second pass.
- Each fragment processor will process a whole line or some significant portion thereof depending on memory requirements. I'm hoping to use a floating point format which will make blending and a lot of operations essentially time-free but at a cost of 4x the memory. A 1024 element RGBA buffer will require 16K for a forward renderer although i'm going to look into deferred rendering too. It might be possible to defer the texture lookups for example.
I'm not sure where the first and second passes will reside, and for small triangles they will possibly run in the same loop. It may make sense to place some of the decision work on the arm so as to reduce the need for multiple passes over the triangles for each 'run'. In any event several rows will be processed at once since there will be several epus dedicated as fragment/row processors.
It's interesting that due to the FPU and branch latency you're forced to consider SIMD style algorithms for efficiency in a lot of cases. i.e. unrolling loops, branchless logic, re-arranging processing so decisions are taken elsewhere. I'm still juggling the code around to find out what works best on-paper although I should start poking on-board soon.
That better edge test
I'm also surprised at just how little code is required for the inner loop. Only 3 flops and 4 ialu ops (+branch) are required to implement a length-bounded 'inside triangle run' test.
This is an example of scanning right looking for the first set pixel in the triangle.
; v0, v1, v2 = edge equation value (already calculated) ; e0, e1, e1 = edge equation x coefficient ; i = length left 1: and code,v0,v1 ; negative test for v0 & v1 fadd v0,v0,e0 and code,code,v2 ; negative test for v0 & v1 & v2 fadd v1,v1,e1 sub i,i,#1 fadd v2,v2,e2 orr code,code,i ; negative test for i bgte 1b
5 cycles + branch = 8. Can be unrolled.
This is the equivalent of:
do {
code = (v0 < 0 && v1 < 0 && v2 < 0) || (i < 0));
v0 += e0;
v1 += e1;
v2 += e2;
i -= 1;
} while (code == 0);
Rather than move the negative bit somewhere else as in the previous post I found just leaving them in-place reduces the instruction count. This also lets me combine float and integer comparisons in the same way.
A similar calculation can be used as the exit condition for the fragment generating loop. As each parameter is interpolated using a single addition within the loop it makes for a very simple loop. The only "problem" is that the calculations are so simple that branches become more expensive.