
opencl termz
I was just going to "try something out" while I waited for the washing to finish ...
... so after a long and full day of hacking ...
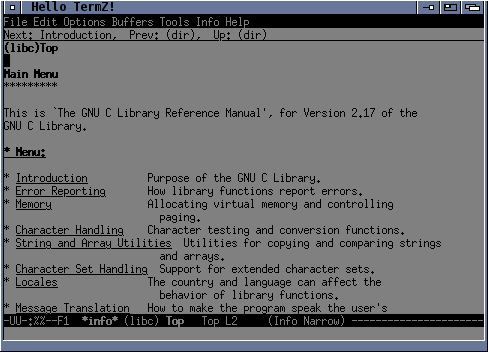
The screenshot is from an OpenCL renderer. Each work item processes one output pixel and adds any attributes on the fly, somewhat similar in effect to how hardcoded hardware might have done it. I implemented a 'fancy' underline that leaves a space around descenders. The font is a 16x16 glyph texture of iso-8859-1 characters. I haven't implemented colour but there's room for 16.
On this kaveri machine with only one DIMM (== miserable memory bandwidth) the OpenCL routine renders this buffer in about 35-40uS. This doesn't sound too bad but it takes 3uS to "upload" the cell table input, and 60uS to "download" the raster output (and this is an indexed-mode 8-bit rather than RGBA which is ~2x slower again), but somehow by the time it's all gone through OpenCL that's grown to 300-500uS from first enqueue to final dequeue. Then add on writing to JavaFX (which converts it to BGRA) and it ends up ~1200uS.
I'm using some synchronous transfers and just using buffer read/write so there could be some improvements but the vast majority of the overheads are due to the toolkit.
So I guess that's "a bit crap" but it would still be "fast enough". For comparison a basic java renderer that only implements inverse is about 1.5x slower overall.
But for whatever reason the app still uses ~8% cpu even when not doing anything; and that definitely isn't ok at all. I couldn't identify the cause. Another toolkit looks like a necessity if it ever went beyond play-thing-toy.
I got bored doing the escape codes around "^[ [ ? Ps p" so it's broken aplenty beyond the bits I simply implemented incorrectly. But it's only a couple days' poking and just 1K3LOC. While there is ample documentation on the codes some of the important detail is lacking and since i'm not looking at any other implementation (not even zvt) i have to try/test/compare bits to xterm and/or remember the fiddly bits from 15 years ago (like the way the cursor wrapping is handled). I also have most of the slave process setup sorted beyond just the pty i/o - session leaders, controlling terminals, signal masks and signal actions, the environment. It might not be correct but I think all the scaffolding is now in place (albeit only for Linux).
FWIW a test i've been using is "time find ~/src" to measure elapsed time on my system - after a couple of runs to load everything into the buffer cache this is a consistent test with a lot of spew. If I run it in an xterm of the same size this takes ~25s to execute and grinds big parts of the desktop to a near halt while it's active. It really is abysmal behaviour given the modern hardware it's on (however "underpowered" it's supposed to be; and it's considerably worse on a much much faster machine). The same test in 'termz' takes about 4.5s and you'd barely know it was running. Adding a scrollback buffer would increase this (well probably, and not by much) however this goes through a fairly complete UTF-8 code-path otherwise.
The renderer has no effect on the runtime as it is polled on another thread (in this instance via the animation pulse on javafx). I don't use locks but rely on 'eventual consistency'. Some details must be taken atomically as part of the snapshot and these are handled appropriately.
Right now I feel like i've had my fill for now with this. I'm kinda interested, but i'm not sure if i'm interested enough to finish it sufficiently to use it - like pretty much all my hacking hacked up hacks. Time will be the teller.