
twiddle dweeb twiddle dumb
I started writing a decent post with some detail but i'll just post this plot for now.
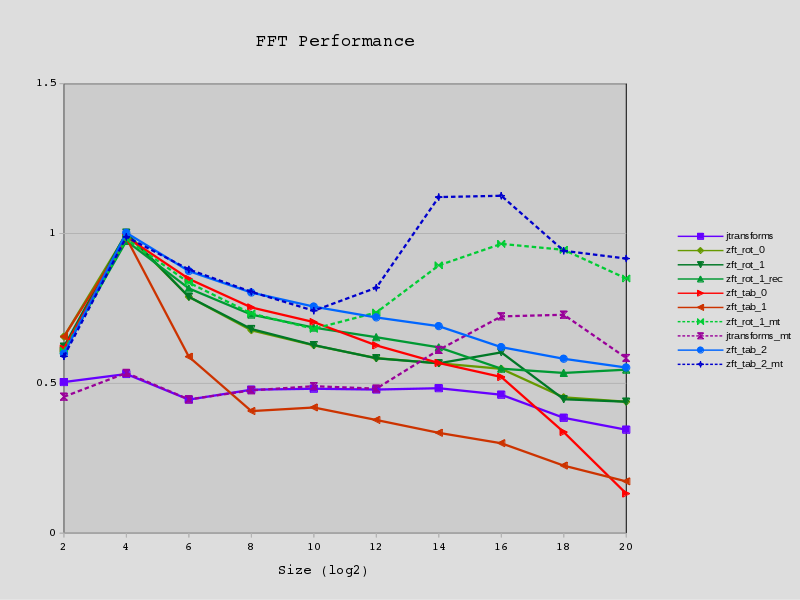
Ok, some explanation.
I tried to scale the performance by dividing the execution time per transform by N log2 N. I then normalised using a fudge factor so the fastest N=16 is about 1.0.
My first attempt just plotted the relative ratio to jtransforms but that wasn't very useful. It did look a whole lot better though because I used gnuplot, but this time i was lazy and just used openoffice. Pretty terrible tool though, it feels as clumsy as using microsoft junk on microsoft windows 95. Although I had enough pain getting good output from gnuplot via postscript too, but nothing a few calls to netpbm couldn't fix (albeit with it's completely pointless and useless "manual" pages which just redirect you to a web page).
Well, some more on the actual information in the picture:
- As stated above, the execution time of a single whole transform is scaled by N log_2 N and scaled to look about right.
- I run lots of iterations (2^(25 - log N)) in a tight loop and take the best of 3 runs.
- All of mine use the same last two passes, so N=2^2 and N=2^4 are "identical". They are all DIF in-place, out-of-order.
- The '_mt' variants with dashed lines are for multi-threaded transforms; which are obviously at a distinct advantage when measuring executiong time.
- My multi-threading code only kicks in at N > 2^10 ('tab_2' above has a bug and kicks in too early).
- The 'rot' variants don't use any twiddle factor tables - they calculate them on the fly using rotations.
-
'rot_0' is just of academic interest as repeated rotations cause error accumulation for large N.Wrong again! I haven't done exhaustive tests but an impulse response and linearity test puts it equivalent or very close to every other implementation up to 2^24 - 'rot_1*' compensates with regular resynchronisation with no measurable runtime cost. ^^^ But why bother eh?
-
- The 'tab' variants use a more 'traditional' lookup table.
-
'tab_0' uses a single table of N/2+N/4 complex numbers.See update below. - 'tab_1' uses a single compressed table of N/2+1 real numbers.
int l1 = i << logStep; int l2 = i << logStep + 1; int l3 = l1 + l2; int mw = w.length - 2; int nw = w.length - 1; float w1r = w[l1]; float w1i = -w[nw - l1]; float w2ra = w[l2 & mw]; float w2ia = w[nw - (l2 & mw)]; int cs2 = (l2 >> logN - 1) * 4; int cs3 = (l3 >> logN - 1) * 4; float w2r = cosmap[cs2 + 0] * w2ra + cosmap[cs2 + 1] * w2ia; float w2i = cosmap[cs2 + 2] * w2ra + cosmap[cs2 + 3] * w2ia; float w3ra = w[l3 & mw]; float w3ia = w[nw - (l3 & mw)]; float w3r = cosmap[cs3 + 0] * w3ra + cosmap[cs3 + 1] * w3ia; float w3i = cosmap[cs3 + 2] * w3ra + cosmap[cs3 + 3] * w3ia;And this . - 'tab_2' uses multiple tables, of well, somewhat more than N complex numbers. But not too excessive, 2^20 requires 1 048 320, which is around double the size of a single full table.
-
- The 'rec' variant (and 'tab_2', 'tab_2_mt', and 'rot_1_mt') use a combined breadth-first/depth-first approach. It's a lot simpler than it sounds.
- I only just wrote 'tab_2' a couple of hours ago so it includes all the knowledge i've gained but hasn't been tuned much.
So it turned out and turns out that the twiddle factors are the primary performance problem and not the data cache. At least up to N=2^20. I should have known this as this was what ffts was addressing (if i recall correctly).
Whilst a single table allows for quick lookup "on paper", in reality it quickly becomes a wildly sparse lookup which murders the data cache. Even attempting to reduce its size has little benefit and too much cost; however 'tab_1' does beat 'tab_0' at the end. While fully pre-calculating the tables looks rather poor "on paper" in practice it leads to the fastest implementation and although it uses more memory it's only about twice a simple table, and around the same size as the data it is processing.
In contrast, the semi-recursive implementation only have a relatively weak bearing on the execution time. This could be due to poor tuning of course.
The rotation implementation adds an extra 18 flops to a calculation of 34 but only has a modest impact on performance so it is presumably offset by a combination of reduced address arithmetic, fewer loads, and otherwise unused flop cycles.
The code is surprisingly simple, I think? There is one very ugly routine for the 2nd to lass pass but even that is merely mandrualic-inlining and not complicated.
Well that's forward, I suppose I have to do inverse now. It's mostly just the same in reverse so the same architecture should work. I already wrote a bunch of DIT code anyway.
And i have some 2D stuff. It runs quite a bit faster than 1D for the same number of numbers (all else being equal) - in contrast to jtransforms. It's not a small amount either, it's like 30% faster. I even tried using it to implement a 1D transform - actually got it working - but even with the same memory access pattern as the 2D code it wasn't as fast as the 1D. Big bummer for a lot of effort.
It was those bloody twiddle factors again.
Update: I just realised that i made a bit of a mistake with the way i've encoded the tables for 'tab0' which has propagated from my first early attempts at writing an fft routine.
Because i started with a simple direct sine+cosine table I just appended extra items to cover the required range when i moved from radix-2 to radix-4. But all this has meant is i have a table which is 3x longer than it needs to be for W^1 and that W^2 and W^3 are sparsely located through it. So apart from adding complexity to the address calculation it leads to poor locality of reference in the inner loop.
It still drops off quite a bit after 2^16 though to just under jtransforms at 2^20.