About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

jjmpeg - why java?
As a follow-up to the post about using Java and JNI to access ffmpeg, perhaps the more fundamental query is - why use Java in the first place? After all, Java is slow and crappy and nobody uses it anyway and isn't .NET the way to go and all that?
I used to write Amiga BOOPSI classes in assembler for fuck's sake, so why am I now using Java?
For starters Java is not slow - although as with any language you can (un)intentionally make it slower than necessary. Compared to similar systems with the same application support it isn't bulky; at run-time or on disk. The JVM is mature and stable and the garbage collection is reliable and fast.
Machines are also not slow these days - in-fact they are so fast most of the processing power is wasted much of the time. Likewise for memory. Wasted processing cycles and wasted memory bytes are actually an inefficiency, not necessarily something to chime about. I am no longer developing applications for a 1MB system running a multitasking GUI. Nobody is.
I still enjoy writing C, and I am still concerned with performance and efficiency, but I have been using Java for a few years now and am very happy with it - and I continue to be further pleasantly surprised from time to time. I find it puzzling that far more desktop software isn't written using Java - in my experience it compares well in all the important categories and is generally easier to develop for.
For example, performance is usually within a few % of C for normal scalar, single-threaded C. Most programmers don't seem capable of going beyond that type of code anyway - and those that are will find JNI a piece of piss. It will probably require twice as much memory - but this is simply an artefact of the use of a decently fast garbage collector - nothing comes completely free, but with memory expanding so much in recent years this is about the cheapest cost you could imagine for the huge benefit it provides. And I don't just mean no longer needing to track which pointers to free - I never found that particularly onerous although many people are unable to grok it - the GC is also a very fast memory allocator as well. No need for pool or slice allocators and the whatnot.
By the time you add all of the features of a basic JVM runtime to C (or anything else), you have something like GNOME or KDE which are not very small at all, have large memory footprints themselves, and are still not as easy to work with (speaking of GNOME as of some time ago at least, I haven't tried KDE and in any event loathe C++ so am not about to).
Of course, python (or ruby) seem to be the flavour of the month at the moment, but they have their own issues. Usually they are just ugly front-ends to some C libraries or commands and they have the same problems that tcl/tk scripts had - a specific version dependency, ugly gui's, and meaningless error messages from their inevitable crashes. And for all that they're not particularly robust, nor provide a particularly compact memory footprint.
seek to frame
Seeking to a frame using ffmpeg ...
I knew this was a bit of a pain since I'd tried it before, but oh boy - there went my weekend. And i still don't have a 100% reliable solution. Ho hum.
Some of the issues I found with only a handful of videos I have at hand:
- An mpeg ts which will wont seek via timestamp. Only byte seeking works.
- An avi in which byte seeking never works. Only timestamp seeking does.
- An avi in which the DTS increments forever - so although you can seek by timestamp to a keyframe, you cannot use it to identify specific frames thereafter.
- A mov file in which byte seeking never works.
- A mov file which ends with an EPIPE error rather than end of file. It must be closed and re-opened to perform any further operations.
I have something which mostly works now, but I suspect it will never be reliable enough.
jjmpeg - why jni?
I started writing a reply to Michael's comment on the last entry but because I tend to ramble, it ended up so long I thought I'd promote it to a post.
have you considered using JNA? ...... otherwise gluegen if you want to stay on the JNI road.
I looked at JNA previously some time ago, and found some problems with using it. I can't remember what they were at the moment but I was so displeased with it I know it ruled me out ever bothering with it again. It looks really good on paper but as I chose to write JNI directly at the time (for cross platform code too) there must have been a good reason. FWIW I didn't look into SWIG or any other option either.
For ffmpeg specifically, you need to access random fields of big structures and it would be impractical (or impossible) to map them using jna - many of the fields are private and the public ones are spread out through the structure. So i'd be forced to write a library to define accessors anyway, and then the jna objects to call those, so in the end i'd have to write something twice whereas now i don't even need to write it once (just a simple config file entry, assuming i didn't write a generator for jna - but then there would be no reason to use it).
I tried gluegen because it looks pretty nice and i've had nothing but positive experiences with jocl and jogl, but it's preprocessor and parser just weren't up to the task - the ffmpeg headers are mostly internal headers which have become public, they are not a cleaned-up public/standard api. They contain a ton of cruft that isn't public as well as public stuff that is behind conditional compilation (using expressions) and the like. I tried pre-processing it using cpp -dD (iirc) which preserves the #defines but then the inline code or other stuff threw it and i couldn't even work out which bit of code was the problem from the terse error messages. After giving up on it i found some other tools that might generate a simple/clean enough file to process (e.g. cproto can dump cleaned up types as well as clean prototypes) - but by then i'd moved on.
The perl script is a bit of a mess but most of the binding is automatic. At minimum i only have to write a constructor method for the public class. Accessors and most methods are automatic (once defined in the config file). I only need 2 classes for every wrapped 'object', one auto-generated.
There are a few special cases, but I find JNI pretty easy to use for those - given what it does it's about as simple as could be expected. And having attempted or worked with interfaces for similar purposes in the past I think JNI is actually quite nice. For example .NET's native binding looks really nice on paper too (it's more like a 'built-in' JNA) but there are actually more gotchas because it's trying to automate more - it's good most of the time but can be a real pain when things get complicated.
I'm already spending more time trying to work out how to use the libraries, the binding itself is mostly looking after itself, even if it is still incomplete.
Having said all that .... I realise that I may have made a mistake and there will be outstanding issues yet to resolve. But at least i'm fighting with my own mistakes and not finding the hidden limitations of tools i know little about - which simply makes it a lot more fun for a spare-time project.
jjmpeg rethink
So I had a bit of a rethink about how jjmpeg does things and in short rewrote it from scratch over the last couple of days/nights:
- OBAWO (one big-arse-write-once) Perl script generates bindings for field accessors as well as many methods based on a configuration file.
- Use dlopen() to bind to libavformat, libavcodec, libswscale at run-time, in order to avoid linking to an impossibly specific version of libavcodec at compile-time.
- Write accessors in C. This will necessarily be a bit slower, but it avoids having to have different Java classes for each case. It also means only the 'c' files need to be recompiled for a different platform.
- The C member functions do their own 'this' lookups, thus allowing them to be called directly as public interfaces (although right now they're not for various reasons).
I've now enough of the libraries bound to allow creating of video files:
It scrolls! (not shown)
So with this and with a bit of Java2D it's pretty easy to start compositing and generating simple video sequences, if one should so desire.
I'm pretty sure I have the lifecycle and memory management sorted, although there may still be bugs there. The AVFrame to AVPlane interface is a bit crappy though.
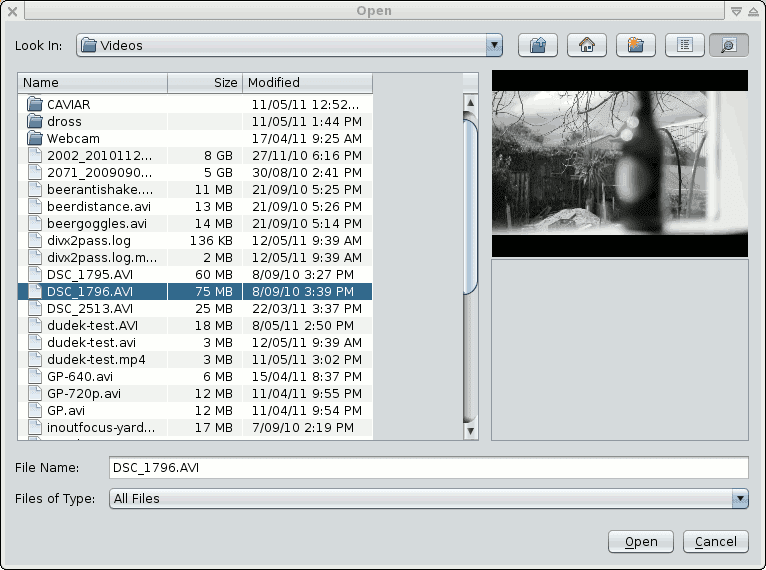
VideoFileChooser
Just a simple little utility class i'm working on at the moment.
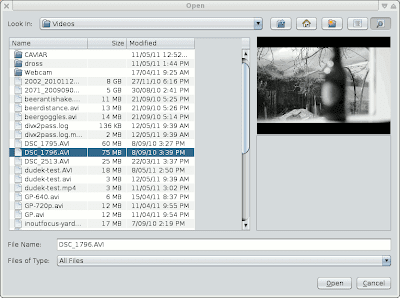
A basic file chooser with a greyscale video preview of selected-format video files. Seems like it could be nice to have; even if it is only black and white, mute and with (possibly) incorrect aspect ratio and frame-rate. I just hacked up the image-preview file requester I made for ImageZ and in-fact it took fewer lines of code.
I also had a go at supporting 32 bit systems with jjmpeg, although I haven't tested it at all yet. However I noticed that the .so file links with a huge pile of stuff from ffmpeg depending on the build options it was created with. So it probably will not be possible to make a generic package for it - fortunately the native library is only a single small c file so it probably doesn't need one. Assuming I don't go and dlopen the libraries manually at least ... which is always an option I suppose.
jjmpeg
I've started another new project on google code: jjmpeg. It's a simple binding to ffmpeg for java, where possible mirroring the API directly. e.g. compare Main.java with avcodec_sample.0.5.0.c.
It uses NIO direct ByteBuffers to allow some of the binding to be done in managed code, and the rest is done with custom callbacks.
I only need it for reading video, so that's all i've implemented; and even then only a tiny subset thereof. I don't know if it will get any further than that.
I did look into using gluegen to do the binding but I couldn't get it to work - for starters the ffmpeg headers are too complex for it's limited parser. Even stripping out the conditionals and the inline code didn't help (using cpp -dD and some editing). So I just manually select which fields to bind and I have some C which works out the offsets (and auto-generates some classes) from some embedded tables (why write a config parser when the c compiler has one?), and hand-code the function calls.
I use 3 classes per 'class' to allow me to get away with binding generated code with hand-written code, as well as supporting 32 or 64 bit (perhaps, eventually - only 64 bit done so far). Base abstract class is auto-generated and sets up the interface for the auto-generated field accessors. The middle abstract class is the public api and includes the hand-written bindings and factory methods (where appropriate). The final concrete class implements the accessors for each processor size.
Up until now i've been using Xuggler ... which I probably will keep using for some software, particularly cross platform stuff. But I don't really like the callback api it uses and for the most part the ffmpeg library api's are fairly simple on their own (despite a bit of bitrot).
Viola & Jones Detector OpenCL
After being a bit distracted yesterday evening by my co-dwellers, I got stuck into a problem I've been wanting to look at for a while - running a Viola & Jones cascade detector on the GPU using OpenCL. I'd just got an integral image calculator done so was eager to use it.I've had a few goes in the past but always seemed to mess up some of the weighting calculations, so I started with the code from OpenClooVision which is a bit easier to follow than the OpenCV implementation, although could certainly use some work.
So, by about 6am I had a working implementation ... but it was really very slow. Far too slow to even consider for what I need, and worse, it doesn't scale at all well - running it on smaller problem sizes just makes it even less efficient.

Who is that fat bastard?
I went to bed shivering cold but mostly wondering just what I could do to speed it up. I have previously done some work with integral images, and I found they do not work particularly well on GPUs - even calculating them aside (which I managed to solve with an acceptable solution although it took many many dead-ends and grey hairs). Although on paper they look like an efficient solution - a handful of array lookups to calculate an area sum - in use they seem to interact poorly with texture cache.
It was taking in excess of 30 000uS to perform 14 passes on a 640x480 test image in steps of 5 with a scale of 1.25.
The OpenCV and faint implementations both pre-scale the features and feature-weights. I never quite understood why until I had a working implementation, and the OpenClooVision version was calculating them on the fly. So the first stop was to try this. Pre-calculating the weights is extremely cheap, and this lead to around a 50% performance boost.
I still had a problem with the GPU hardly being utilised, particularly at the larger scales (fewer tasks/call) or with smaller images. And because each thread was working on a separate probe, there was very little coherency in processing or data.
However, I noticed that for the cascade I was using (the default one from OpenCV) it was running many feature tests for each stage - 25-200; and that calculating the feature value was unconditional - something ripe for parallelisation.
So I tried launching 64 threads for each probe location, and they work together on the list of features in blocks of 64, and then tally them up at the end using thread 0. This was the biggest improvement and I managed to get it down to around 12 000uS.
I then tried a parallel prefix sum - which got it down to about 11 000uS, although then I tried a sqrt(N) sum (split the summation into 2 passes, first 16 threads produce 16 partial sums, then 1 thread adds those up) and got it down to about 10 500uS. Parallel prefix sum loses again.
And then to cut a long story short I tried a whole bunch of variations, such as storing the regions in integer format - this made it faster, but only because it wasn't calculating the same results. And different work-sizes - 64 worked the best. And different packing formats for the feature descriptors. But no matter what I tried, about 10 500 uS was about the best I could manage with the test image.
I also tried a slightly modified version (no thread dependencies) running on the AMD CPU driver, on the 6 core+HT machine I have. That managed 90mS. So the GPU is only 10x faster, which although nothing to sneeze at is still a bit disappointing.
To me this is still a little on the slow side, but I'm pretty much out of ideas for now. It might just be a problem that defies any particularly efficient mapping to GPU hardware.
Actually one thing I haven't tried is scaling the images instead of the features ... but I think that's something that can wait for another day.
OpenCL Kanade Lucas Tomasi feature tracking
I've added a couple of things to socles, the main being an implementation of Kanade Lucas Tomasi feature tracking. It's just a fairly simple translation of the public domain version here (site seems down at time of writing), with a few tweaks for good GPU performance. Ok it looks nothing like it, but all i did was remove the need for 3 temporary images and the loops to create and use them by noting that each element was independent of the other and so they could all be moved inside of a single loop.
I've only implemented the translation-only version of the tracker, with the lighting-sensitive matching algorithm. The affine version shouldn't be terribly difficult - it's mostly just re-arranging the code in a similar fashion (although the 6x6 matrix solver might benefit from more thorough work).
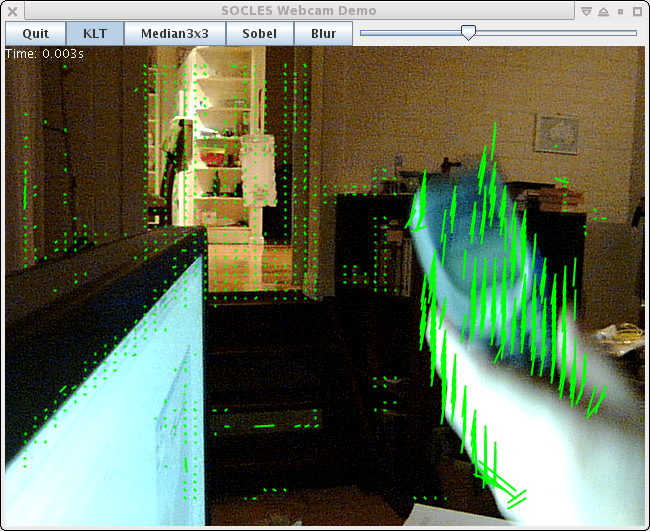
Really awful screenshot of it in action ... (it's very late again)
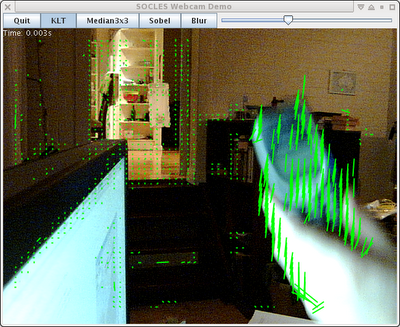
The 3300 regularly spaced feature points above take about 1.5ms to track in GPU time (480 GTX), including all of the image pyramid and gradient image set-up for the incoming frame. It uses 3 levels of pyramid with each 1/4 the size in each dimension of the one below. Most of the points lose track because there isn't enough detail to meet the quality settings, hence the areas with no green dots.
With a CPU implementation the majority of the time is taken in the convolutions necessary to setup the image pyramid - although eventually with enough features one reaches a break-even point. In this case it's about 500uS for the image setup for 640x480 image (3 convolutions at full res, 2 at each subsampling and one resample), and 1ms for the 3300 tracks (i.e. 0.3 microsecond per additional 16x16 feature tracked). Well that's quick enough to keep me happy anyway. At least for now!
I implemented this using a pattern which I've found after much (much) trial and error to be reliably efficient for mapping many types of rectilinear problems to GPU processes, which i'll just call an NxM execution pattern. For a feature-size of 'NxM', the code assigns 'N' threads to each feature, each which works on a column of 'M' rows of data, with the first thread in the sub-group used to tally results and make decisions. A small amount of local memory is used for the partial sums and to share the decisions amongst the threads. These are mapped to a flat work size which is independent of the local workgroup size, which allows for easy tuning adjustments. So a feature size of 9 would be mapped using 7 features if the local work-size is 64, with 15 threads idle (i.e. choose factors of the worksize for best efficiency, but it can still work well with any size). 100 such features would need 15 work groups (ceil(100/7)). The address arithmetic is a bit messy but it only needs to be calculated once on entry, after that it is simple fixed indexing. And since you can reference any memory/local memory by local id 0 you don't have to worry about memory bank conflicts.
I tried many other variations of mapping the work to the GPU and this was by far the best (and not far off the simplest once the fiddly address calculations are out of the way). For example, using a parallel prefix some across all elements with a 3d work size (i.e. 16x16xnfeatures) was about 1/2 the speed IIRC - the increased parallelism was a hindrance because of both the IPC required and the over-utilisation of resources (more local memory and threads).
Update Ok I found a pretty major problem with this mapping of the jobs - early exit of some sub-workgroups messes up the barrier usage which upsets at least the AMD cpu driver. So all threads need to keep executing until they are all finished and then mask the result appropriately, which will complicate matters but hopefully not by much.Update 2 I think I managed to solve it, although I had some trouble with the code behaving as I expected, and got misled by bugs in other kernels.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!