About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

ARM, NEON, etc
After a good few hours of experimentation I had some NEON code running. With all the OpenCL i've been doing for a while I kind of forgot some of the ways one writes SIMD code, and for a "RISC" cpu, a modern ARM has a large set of instructions to learn.
For example, whilst trying to build the 8 bits of the LBP code my first approach was to try to perform the 8 comparisons to form the bits in the code using a single instruction. The problem with this is that it takes a lot of fuffing about just to get the bytes in the right spot (vtbl helps a lot here), and even more fuffing about trying to turn those 8 results into 1x8 bit number. And even when you've done that you need to get 8 results before you write something out and it all just gets messy. Thinking about that jogged my memory on how one can stream data through a SIMD processor and instead produce 'n' independent results concurrently.
Which makes the whole thing a lot simpler - and allows one to re-use memory accesses as well without having to write custom extraction code for every position in the vector. For 6x64-bit memory accesses I can produce 8 output codes, and the code itself is fairly simple ...
Unfortunately, this only produces the 8 bit LBP codes, and I really want the u2 variant ... which requires a 256-byte lookup table. (you can't really do the lookup using NEON, and have to resort to ARM, and it's too slow moving the registers back, so it has to go through memory).
The obvious approach is to just run the whole lot twice, but it turns out that's pretty slow because of the slow memory on the beagleboard. e.g. my best LBP algorithm (which does 8 columns and 4 rows per inner loop) takes about 2.6ms to process a 512x512 image (simple C is about 12ms). And my best LBP to LBPu2 conversion routine takes about 2.5ms ... and together they end up 5.1ms.
So I took a slightly simpler LBP routine (does 8x1 results per loop, about 2.9ms) and tacked on the ARM code which processes the previous row's result after en-queuing all the NEON instructions (i.e. it does 8 lookups for the row above, whilst the current row calculates 8 results). This showed some promise, so I then took the ARM instructions and sprinkled them throughout the NEON ones so it spreads out the calculation a bit more/improves parallelism. Not bad - best effort is down to 3.9ms total. I only have a rough idea on the scheduling rules, I wish I had the static analysis tool for the SPU which showed dual-issue and delay slots.
I guess it's worth it - the C code that does the U2 lookup is about 13ms - but it didn't take a good few days to write and it's only 10 lines of code.
I also looked at a 'SIMD' like ARM version - it turns out you can do 4x 8-bit unsigned comparisons with a single instruction (uhsub8) - I got stuck working on that till late into the night one night (instead of watching tv), but then I figured it wasn't going to beat the NEON, so I couldn't be bothered debugging it. OTOH it would allow one to hook in the U2 lookup more easily, so it might actually be a win and worth looking into. The ARM code is very tight on registers though so i'm not sure it will fit.
I've done some testing with the classifier code as well - at first I thought I'd just wasted 10 hours on the NEON code because it was taking the same time as some simple C (the classifier is literally a 5 line double-loop). But then I realised I was running it 8x as many times as i should have. At least an 8x speedup is definitely not something to sniff at. And I still have the outer loop in C and with all the redundant function invocation overheads so there might be a bit more left to get. I haven't debugged it yet so i'm not sure it's working, but a 17x17 template on a 512x512 image is about 0.6s - this seems slow but this is much smaller than one would normally look for objects in such a source image, and at a more-realistic 4x this size it takes about 30ms.
There's still a lot of scaffolding before I can find out how it will actually run in practice, but it's looking ok so far. I kind of forgot how long it takes to write assembly code (at least, when one is learning the instruction set), but now I remember why I wasted so much of my youth on it - it is rather fun.
Mele A2000
So I finally got a Mele A2000 I ordered from deal-extreme. Took about 3 weeks from ordering. The cardboard boxes were a bit crushed but nothing was broken.
Actually seems like quite a nice little unit - much better than that crap digital tv tuner/recorder I got from Kogan (which even if it didn't have issues like rebooting and not responding to the remote if the weather isn't just so, runs totally shithouse software anyway and is just a real fucking pain to use). In short, at least it isn't total junk ...
Android seems to run fine on it, and the video player seems ok although it doesn't really do 'pal' properly. The HDMI output didn't seem too compatible with my old DVI monitor (output was purplish) but I didn't try the different video modes on it either. Had a US plug on the plug-pack, but it was robust enough that a pair of pliers fixed that without too much work (i've had other plug-packs break apart when trying to bend the pins). There's something going funky with the network though - videos off my lan play fine, but although the google shop worked once doesn't seem to want to connect any more, neither does the browser. I guess it's lost the default route somehow (maybe playing with both) Hah, funny, it was a DHCP server running on the ADSL router i used as a switch .... Looks like i can't turn the damn thing off either so I guess i'll have to find another box to do that.
Oh yeah, when i first plugged it in I used my pc mouse. And here's a fucking idea - the mouse wasn't over-accelerated to the point of total unusability like every X11 based desktop always is these days ...
OTOH, a dark blue and black mouse pointer on a black background is hardly a fucking sterling idea though.
Performance seems ok - not quite as snappy as the transformer prime (not surprising), but visually fine (better than the benchmarks would suggest). The browser is a truck load faster than the ps3 that's for sure, even running firefox.
I also got one of the wand remote things - it isn't fantastic but works ok (better than the original wii imo) without requiring any adjustment (one re-centres by just pushing off the edge and when you move back it starts from there). What is odd about it is design of the case. It has some strange sharp edges and a clip-together type look. It also has holes for a microphone and ear-piece, but it doesn't appear to be hooked into anything (could be neat if it was). It's actually kind of cool and works as a keyboard mouse on any machine you plug the small dongle into. Rather missing is a tab key however ...
Not sure what I'll do with it yet, I might just use it on a tv - one reason I went with the mele rather than the other smaller things is the CVBS output, and the SATA (and to be honest - it has a friggan case). But work is using the tablet for a demo so it's also the only android device i have handy at the moment too. I'm not sure whether I want to muck about with linux on it although that's originally got me interested in it.
I was originally going to get 2, one to hack, one to use as an appliance/android thing, and ordered them from Tom's shop on aliexpress. Unfortunately they have some fucked up credit card verification thing which wouldn't work with mine (even rang the bank), and although Tom mentioned pay pal never gave me his details (if it was supposed to be on the shop front, it definitely wasn't). I did get 2 this time but one was for a friend to look at, although if it doesn't suit his purposes I guess I may end up with it too.
There goes the weekend anyway, as if the NEON hacking wasn't enough ...
Update: Apart from 1/2 of Saturday i didn't get much time to play, but since then ...
- I downloaded the new firmware which just came out and installed that. Needs a microsoft windows peecee to create the SD card :-( I did mine via a USB stick first, and then dd'd that over the sd-card, as my windows peecee has no card reader. It still worked even though the USB stick was 8GB and the SD 4GB.
- The update made some strange changes, such as changing the device id in the shop, removing their custom ugly launcher, and replacing the default five-pane one with a single-pane version. But on the positive side the mouse pointer is a lot easier to see (although it just wasn't well drawn, and additionally goes beyond the hardware sprite bounds when playing video), and videos play full-screen properly. I didn't use it enough to know if its fixed any other issues.
- I found Skifta - it seems a simple no-nonsense upnp client for browsing mediatomb & mythtv shares, without adverts and other crap. I was using avia (or something like that) on the tablet but then I noticed it wants a DNA sample and urine sample to install ...
- I tried the alpha XBMC port from the nightly builds (on xda forums): in short, just don't bother yet on this machine. It uses software decoding, and even without that it runs like a total pig and is a huge install (~50MB). To be honest I find it a pretty confusing and difficult to use bit of software anyway, and it would have to have something else to make me put up with it's weird interface.
- On the dev side, I found ADB Konnect as a simple tool to enable adb over the network. It's about 2x faster than a beagleboard XM in raw cpu power + memory speed. And JJPlayer is totally shit on it ...!
Stop #*@^$&@ "innovating"!
So in my morning 'paper read' of BN I came across this opinion piece about desktop 'domination'.
What I don't get is, why is it so important to "innovate" in such a basic and to be honest - downright fucking boring - area of a `computer desktop'?
Last I looked, my computer workbench is pretty much the same it was on AmigaDOS 1.2 (apart from a proper top-menu, but it's half there) ... I have a first-class CLI, overlapping graphical application windows, removable media is mounted automatically, and a file browser from which I can launch applications or delete files. The big things are the same, only the details have changed. Even Apple's Macintosh (apparently 'the' example of innovation) is basically the same design as it's first iteration; top-menu, full-screen "windowed" applications, and so on.
Some things just don't need innovating after the basic functionality is in place.
Take doors for instance. I'm no door expert but the last innovation in doors I see was the sliding glass door from the 80s or so and even then they only work in very limited situations (but there they do work well). Other than that, the basic design of a large flat rectilinear with a turning latch on one side hasn't changed - in hundreds of years. I really don't want anyone to 'innovate' in such a basic user interface since it simply works.
One can take any number of other household or day-to-day items, from car steering wheels to cups and saucers, frying pans to mirrors. One can innovate in the details as much as one likes - using new materials, finishes, colours, or designs - but a frying pan is most definitely identifiable as a frying pan whether it's made of steel, aluminium, glass, ceramic, coloured red, black, or blue.
And like doors, in some cases there is scope for radical differences in very different situations. An appliance (like a tv, phone, etc) is a very different computer from one used as a general re-usable `workbench', trying to make a universal GUI solution here is about as stupid (and it is mind-numbingly stupid) as making a universal door.
All a computer desktop has to do is get out of the fucking way whilst I get real work done - and that problem was long solved ago. Once it becomes the end in itself we end up with disasters like GNOME 3 or "Metro", and really they deserve all they get. I'm sure wood-workers and other craftsmen are very proud of their workbench (especially if they made it themselves), but I doubt they consider the workbench itself the pinnacle of their craft or anything other than a dependable rock-solid tool that shouldn't be trying to get in their way at every opportunity.
On ARM, NEON, et al.
So for a bit of a diversion I finally found a decent use for my beagleboard-xm ... i can use it to write and debug ARM assembly and NEON ...
To that end I 'upgraded' the sd-card to the latest available image of angstrom - for no particular reason I went with the GNOME build. Which is course was a big mistake since it uses that systemd shit (which sent me out on a google-search-of-rage looking for like-minded individuals of which there are plenty), notworkmanager and all sorts of crap. And X is still un-accelerated so it's pretty much pointless anyway.
So I went back to the other angstrom build, which at least starts the network up from boot and has gcc and gdb. But no opkg for emacs? Ugh ... so I just had to compile that myself. A bit over an hour, but I just watching tv by then and by now I was just happy I had a system which worked, and I already knew it wasn't a super-computer.
I dragged out the 2nd hand monitor I had for playing with the beagle, remembered where I had put my old ADSL router which I set up as a switch (seriously, i'd 'lost' it for about a year), and Bob's James' dad, I have a development environment up. I should really go out and get a faster SD card though, since the one it came with is slow ... (i presume that's the issue).
It's been a while since I looked much at ARM. I remember VFP being a bit weird, but NEON is nice and more like SPU. It's really missing pack-bits instruction though (take MSB of each element and pack to a scalar bitmap), at least for what I was looking at.
To start with I was looking at using it to build LBP codes - if i had a pack bits it would only be 4 instructions instead of 7. Pity I still need to use a lookup table to get the LBP u2 code though (there is a definite pattern to the table, so there might be some bit-manipulation tricks to do it too). It's been really crappy and cold, and I've been too exhausted from work, so I haven' felt like doing much yet.
Before I set the beagle up I also poked around just cross compiling stuff and seeing how it went. I came up with a builder in ARM code which was at least all in registers if not particularly compact - and what should have been an equivalent implementation in C didn't compile very well. But I guess we know that.
I spent another hour or so last night just fiddling with another version of the ARM code - it was actually quite enjoyable to play with something just for fun. It doesn't matter if i finish it, or if i ever get it to work but trying to hand-optimise one screen-full worth of code to solve an interesting problem is quite a puzzling challenge. It's nice to work on something fairly simple for a change ...
Efficient local binary pattern multi-class classifier
So given that the feature tests with the classifier i've been working with are independent ... it offers a fairly interesting possibility: that of using sub-regions of a single trained classifier to detect corresponding sub-regions of the image with a higher resolving power.
This isn't a very good picture, but it demonstrates what's going on (it's from the same source image as the previous posts).
Here I am using a single trained classifier for faces, but from that classifier detecting 4 classes of subregions - the full face, each eye separately (9x9 corners), and the eye pair (17x9 top region). In the picture I am showing green for the face, red for left eye, and blue for right eye (as the RGB intensities as well as the detection boxes). This is the raw detections at a single scale with no grouping, and I haven't determined if the threshold can be tweaked to improve the false positives. The RGB image shows the RGB components overlayed with respect to the top-left of the detection box, not the centre of each feature (so a white dot means everything aligns). I'm drawing a 21x21 green box just to make it easier to see.
It's not perfect, but it is detecting localised eye positions within the faces.
So even using the same trained classifier it allows a finer resolution of the eye locations, and a further test to remove false positives. The fact there are a lot of false positives for the eyes is not very important as only those in the green boxes (and in the correct quadrant) are of interest. The main downside is such a small feature test means low accuracy for larger images (as they are downscaled more to start with).
The kicker: in opencl this executes at the same speed as the single classifier as most of the work is shared. A fixed set of additional separately trained classifiers can also be added very cheaply as the classifier runs in LDS to reduce the bandwidth needs.
Update: So i've been trying to utilise this, and although it kind of works it doesn't kind of work well enough to be that useful, at least with the classifier I have.
However, on the base LBP detector, with a bit of tweaking to the training data I have been able to get fairly decent performance. For some sequences it is clearly outperforming the haar cascades from OpenCV, whilst retaining the braind-dead fast training algorithm. The fact that it gives a score allows for more post-processing options as well.
Actually anything I try to do to 'improve it', e.g. by weighting some regions, just breaks it's resolving power. I seem to have much more luck by adjusting the training images. For example I revisited the eye detector based on the data used for the haar data. I noticed there was a bit too much variation in scale and variety of the eye images being used. So I tried instead creating a subset of images which were closer to a hand-picked candidate - this made a much better eye detector, even for eye shapes which weren't included in the training set. Although left eyes (right from the front) are always a problem - they have a less consistent and distinctive 'eye shape' than right eyes which gives classifiers trouble.
I find this machine learning stuff pretty frustrating as it just seems to involve a bit too much magic, and my mathematics skills just aren't up to the task of delving further.
More on the LBP detector
I've been a bit busy with work doing another prototype but I had a small play with my object detector last night. I wanted to see how it would work with online training for parts of a scene.
In a word: excellent.
Training on as little as a single instance of an image even works. It yields a detector with an obviously very specific discriminative selection power (scale/orientation), but it still works for that case.
With a modest number (16, 256, or 1024) of randomly synthesized training images (scale/rotation), the discriminative power still remains to pick out the object of interest, but it works over a larger range of scales and orientations. When I tried translation the classifier started generating much less distinct results but I think that might have been a bug in my synthesising code.
The only problem is that the scale of the detector output changes depending on the range of orientations (not so much the number of training images). Although even with a poorly specified classifier (very many high values in the output), the global peak value is still a reliable indicator of a single instance of the object (which is the most important thing, so long as it is present).
I have only been trying it with still images so far, the next thing to try will be with video. And with other objects than a face (faces are particularly 'interesting' in the LBP space, so it might not work on general objects).
Simple LBP Object Detector
After mucking about getting nowhere with a simple local binary pattern (LBP) object detector algorithm I finally had a bit of a breakthrough. Rather than getting dozens of false positives, i'm finally getting a concise enough answer to be useful for further processing.
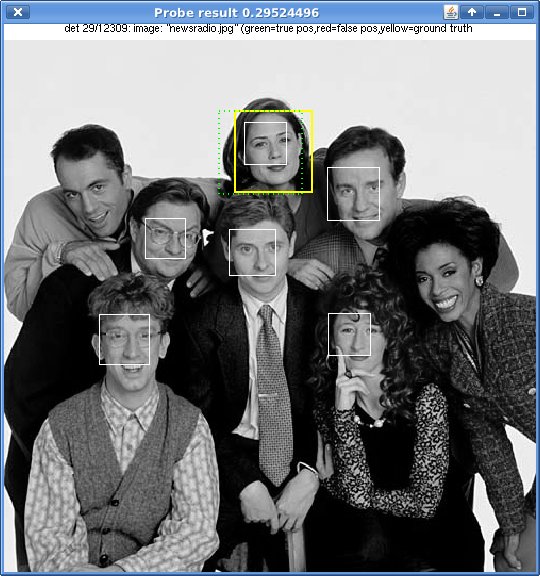
Here is an example based on a photo I found on the net with a few faces in it (it's from here - i only found this using an image search, that page is just where i found it but I haven't otherwise read it). The yellow box is their result, the white boxes are mine (i'm not quite centring/scaling it properly yet).
The only tuning is a threshold and the grouping limit.
I'm actually quite surprised some of those faces are even found because this is one of the first tests i've done on more than a couple of images - and it has trouble with Lenna for example (but i suspect that is some aliasing issues with downsampling the larger countenance). I originally started with the eye set (from the OpenCV eye cascade), but was having trouble with false positives - e.g. eyebrows, mouth, dark spots. It seems to work much better with the face data. But most eye detectors on their own seem a bit noisy anyway so perhaps I was expecting too much.
I gave up on the cascade idea and this simply tests every position using the LBP u2 8,1 code (only 59 values) against a binary lookup table, and then each position votes on the outcome - once I get enough positive votes, it's considered a hit. This is similar to the LBP feature test in the OpenCV LBP detector, except that one uses the full 8 bits of LBP code, and of course the code is calculated on regions, not pixels.
I am only using the face and non-face images from the CBCL face dataset available here, which isn't a particularly good quality set of images. The only pre-processing i'm doing is mirroring the faces to double the training set. Training is very fast - after the images are loaded and converted to LBP, it's only taking 0.038s on my machine to `train' the 4858 positive and 4548 negative images (very plain single-threaded Java).
On the CPU the lookup isn't particularly fast (0.4s for the test image above) but I will look at porting it to OpenCL - it should be a very good fit for a GPU. If weighting isn't required, the feature description itself can be made very compact as it only requires 2 integers (64 bits) for each x,y location in the pattern - i.e. under 2K5b for a 17x17 test pattern (e.g. 19x19 training set, as the the LBP requires a 1 pixel border) which can easily fit in the constant cache.
There are still some tuning issues such as that a given threshold doesn't work equally well on all images, but it is still a promising result and there are still plenty of ideas to try.
Update (ok not really an update i hadn't published this yet ...) ... I coded something up in OpenCL and the performance is really very good - kernel time for the scaling (using a mip-map like thing), lbp building, and running the detector is around 2ms (same scales at the cpu example above). But this time doesn't include peak detection, thresholding and grouping. Still, this is pretty favourable compared to the VJ cascade as that does far fewer probes in it's 10ms runtime (and takes a week to train - if you can get that to work). Here i'm doing over 200 000 17x17 probes through 5 scales ...
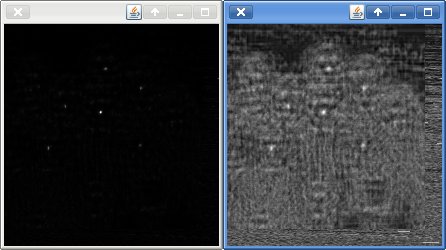
I also played with a more statistically valid accumulation mechanism (as each test is independent): multiplication rather than addition (statistics isn't my strength by any stretch ... sigh). This leads to much more specific peaks as can be seen by the following picture, although i'm not sure if it leads to a more consistent threshold value (I think it does, and if that's true, I probably don't even need to do peak detection ...).
Both images are normalised.
Update 2: Had a bit more of a play this morning, tried a couple of different kernel topologies and using LDS to reduce memory bandwidth requirements. Got the kernel time of my test case down to 1.3ms, vs the 2.1ms yesterday (on a Radeon HD 7970). I also found the new combination metric is working well - I can use a specific value as the threshold and remove the peak detection stage entirely. It doesn't work too well with the eye data (way too many false positives), but it's pretty good with faces, so far.
android object detection, threads, haar, lbp
So post my previous post I kept hacking away at writing java equivalents of some of the OpenCV code I was using.
I already had the MB-LBP detector but I got the Viola Jones detector working after I realised the weighting factors needed scaling ... (seems to catch me out every time!).
In the mean-time I've also been trying to understand the adaboost machine learning process for some time, and had another look at that. First I tried writing my own detector/learning algorithm using simple LBP codes. Each feature test is a bitmap of LBP codes which are present at a given location. Training is very fast as many iterations can be executed quickly, but I just haven't been able to get a satisfactory result - it kind of works, but just isn't good enough to be useful. I'm also trying to create a detector which would suit GPU execution, as each test is a simple lookup of a pre-calculated LBP table. I think it can probably be done, but it would help if I understood adaboost. Last week I also looked at average of synthetic exact filters as well (it's used in pyvision, although that isn't where I heard of it first), but like most FFT based algorithms although it is neat and academically interesting, in practical use it has some issues.
So I thought i'd try opencv_traincascade instead and generate a MP-LBP detector. I ran many different options, but it was hard to tell if it had gone into a loop or was just taking a long time. But in the end I just couldn't get it to create a deep enough cascade - it kept hitting "Required leaf false alarm rate achieved", so I gave up. Oh opencv_traincascade loads every negative image EVERY time, so once I made it cache all the images in ram instead (a miniscule 100mb or so) I sped it up a good 10x. Still, not much use if it doesn't work. Frustrating at best. I kind of got a result out of it with a depth 10 cascade (mostly of 2 tests each), but it's not much better than my own attempt and it shows there is a bit more magic involved than i'd hoped (I also have a feeling that as MB-LBP features are so descriptive, it's causing problems with the training process). I'm using the data for the eye detector in opencv (the url is in the eye cascade).
So whilst that was running I neatened up the detector code I had, converted a couple more cascades to the simple text format I use in socles, and started on an android application to use it. I wrote a trivial XML loader using JAXB to load in the cascades from OpenCV - I gotta say, when it works JAXB almost makes XML tolerable. I also noticed my custom text-format loader was pretty slow on android too, turns out creating a String from a byte array using the default (UTF8?) charset is slow as shit - forcing US-ASCII sped it up about 3x (or more, a good few seconds to barely noticeable now), although I should really just use a binary format anyway.
Performance at base is on par with the OpenCV code, however when I use a smaller camera preview image the performance increases dramatically as you'd expect (with OpenCV it only made a minor difference for some reason). Together with some muli-threading, I can get face detection running about 10fps on a 640x480 image even with the haar cascade (MB-LBP is about twice as fast as that, but just isn't as solid). And interactively it looks a bit better as the video preview is rendered asynchronously to the processing (that the detection regions lag isn't important in my application). This is using plain old java, so i'm not sure what some jni would accomplish.
Although i'm using summed area tables the implementations are scaling the images rather than using the tables to do the averaging (it's meant to be a big part of using them ...). Fortunately summed area tables are pretty cheap and simple to generate on a CPU but the scaling can be expensive once you get below 1/2 (nearest neighbour isn't good enough). So i'm using a simple mip-map with bi-linear interpolation for the scaling. With plain Java that's a one-off 8ms per frame for the mipmap load, and then a total of 14ms for the scale + SAT generation for all scales. 20% of the time for a haar cascade is a bit steep, but short of using the GPU or JNI is unavoidable.
Actually I was only getting pretty average performance until I removed all the dynamic allocation per-frame. It was hitting GC very hard and that was taking a lot of time - I got about a 3x speedup when I changed the allocation to 'big enough to fit' rather than 'exact every time'. Because i'm parsing a simple cascade, start-up time is much reduced compared to opencv as well. This startup time and GC overhead were the two biggest problems with OpenCV in terms of user experience, and together with the other issues of trying to make a funky API fit within an Android application, and the installation complexity, make it pretty unappealing.
Update: Today I converted the code to C and hooked it up using JNI. It still does a redundant copy or two, but this sped everything up by 2-4x. And that is over the Java which I sped up a bit more than yesterday by pre-calculating the SAT table offsets for each feature as OpenCV does. The detection itself is around 30-40ms per 640x480 frame on the tablet (searching scale factor 1.2, minimum size 64x64, maximum 320x320, search step size 2, using the frontalface_alt haar cascade - the minimum size has the biggest impact on performance as smaller windows mean many more probes).
Bit over it all now ... but I suppose I will eventually try this method with socles since it should be a big improvement for cache coherency - which I think is what is dogging the current implementation. And now I know why I couldn't get it to work last time i tried.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!