About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

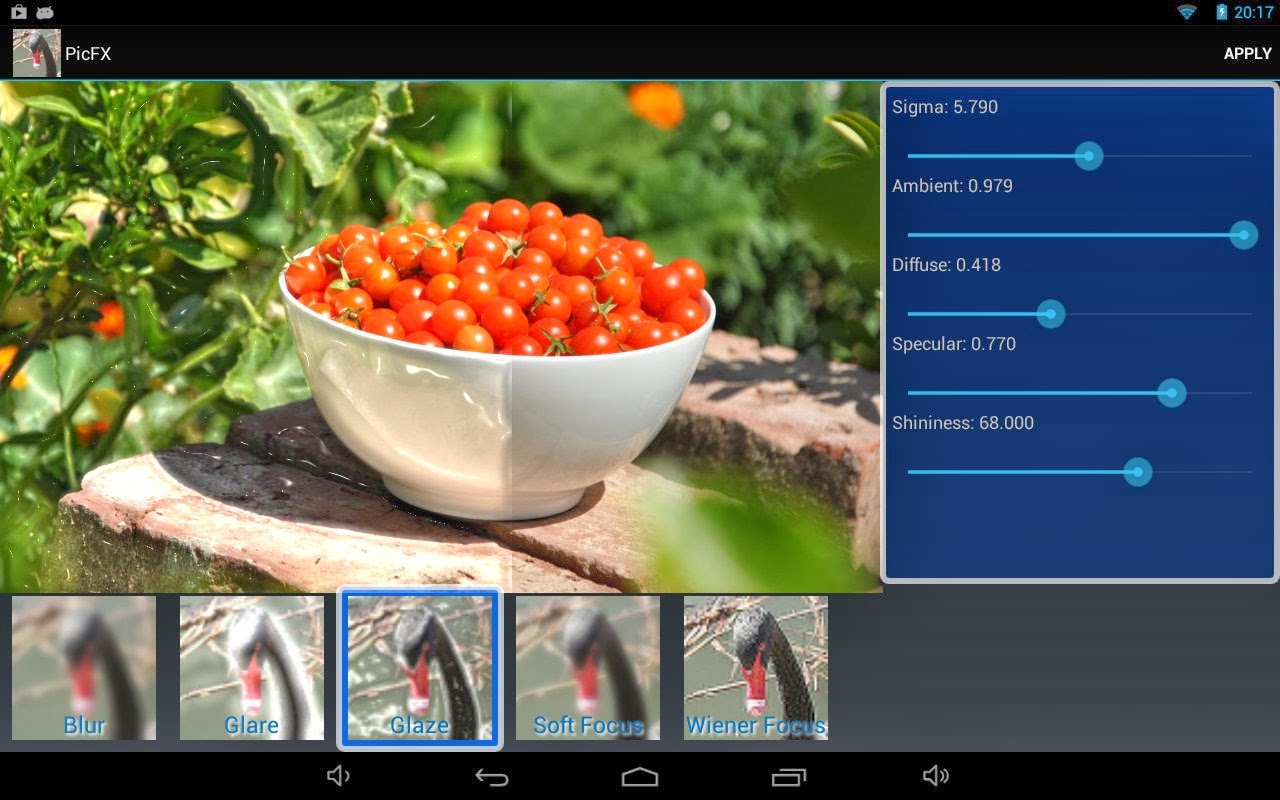
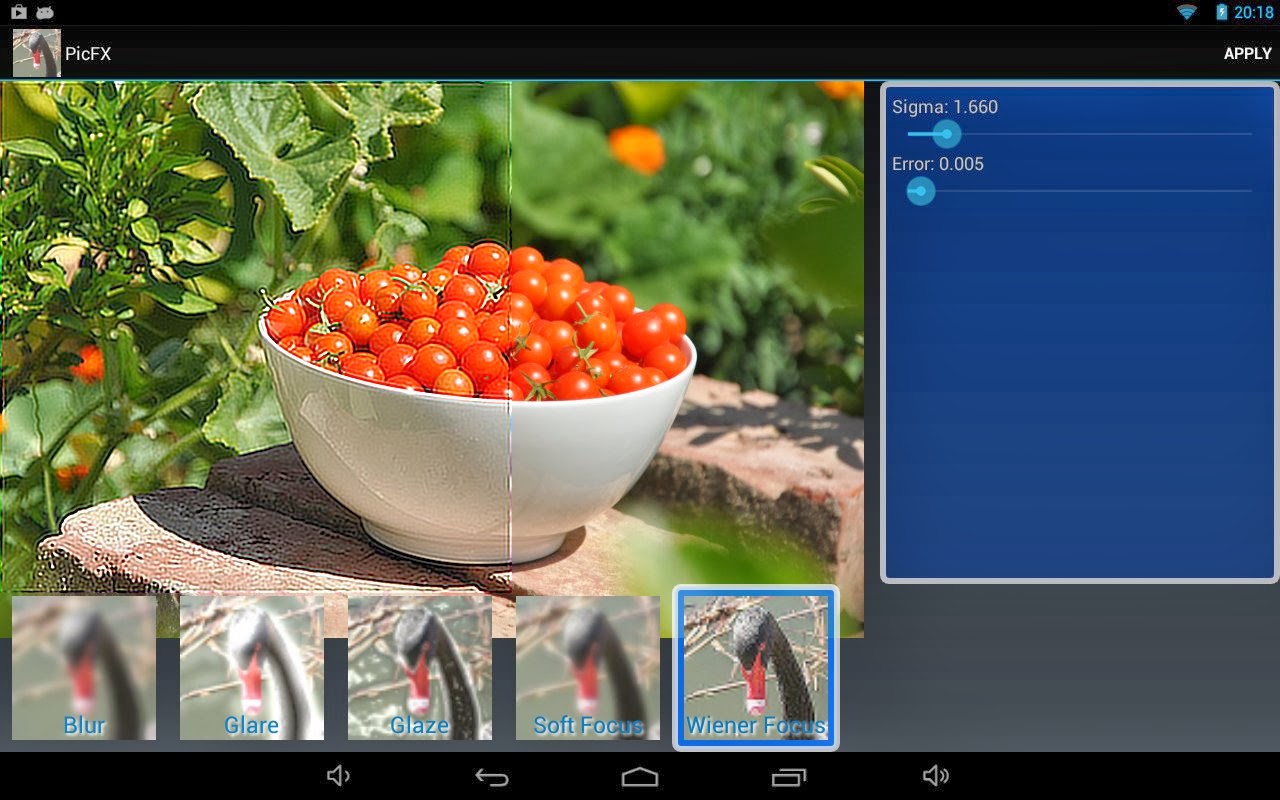
PicFX
I haven't been working on this nearly as regularly as I should've been but here's a bit of an update on the demo android app I was doing for ffts (an fft library).
It was looking a bit bare so I added in the effects I came up with on the weekend. This pretty much forced me to revamp the whole backend again ... but after a few hours work it's all roses. Or tomatoes.
Because I was aiming for some performance the code isn't the best 'example' code, but what can you do eh. Some of the design made code re-use difficult so there's a bit of copy/paste. Even with straight C the interactive performance is very good - over 10fps during a basic convolution of 4 channels. Of course it's only updating a 512x512 tile to help with this interactive speed, but i'm using multiple threads for most of the work. I took the NEON code out for now so there's a little more to be gained although most of the time is spent within the fourier transforms.
Today I added a bit of branding and cleaned up the GUI a bit and so (finally!) it's almost to a releasable state.
Gradients, lights, FFTs, &c
I've been playing with some gradient based "visual effects" and finally have a couple that look interesting.
This i'm calling glare, it's just an additive solid colour being modulated by the magnitude of the gradient. I guess it's a sort of HDR bloom effect.
This is a fancy emboss using a phong shading model for lighting with a small ambient source. I'm using the opportunity to learn a bit about lighting models - the last time I did anything related to lighting was on an Amiga and that amounted to little more than a dot product of the normal for 'light sourced vectors'. I finally get to use my Foley & van Dam!
This is the same algorithm with different parameters - upped the ambient, reduced the diffuse and specular and with a slightly smaller gaussin filter. Gives more detail to the surface as well as showing the original image (which could also work in colour).
I'm using a differential of Gaussian to calculate the gradients in each direction. This is basically a tunable sobel filter.
From these gradients I just directly create a surface normal which feeds into the phong calculations.
3 pass affine fourier resample
Just an example from the resample stuff I was looking at recently.
Source input - Lenna scaled by 1/8 using imagemagic with a Lanczos filter:
I'm applying an affine matrix with a 7° rotation and a 8x scale in each dimension. Apart from the test algorithm the rest are just using Java2D for the resampling on 8-bit images.
Just to see how little information is present i'll start with the nearest-neighbour version. The ringing at the top of the hat suggests artefacts have been added by the downsampling process.
Now for bilinear, which makes a right pigs breakfast of things:
Then comes bicubic. Which really isn't much better than bilinear once you get to this kind of scale. It's still making a mess of things:
And finally the one which is based on a three-pass shear and/or scale algorithm. It comprises three separate stages.
- Horizontal shear and scale;
- Vertical shear and scale;
- Horizontal shear.
Each operates only in a single dimension which greatly simplifies the resampling required - one only needs to be able to resample and scale in one dimension.
I'm using a trick to avoid the typical sinc filter ringing along the edges of the image itself, and i'm not cropping the result properly yet.
Unfortunately due to using a Fourier Transform for scaling I end up with a bit of ringing primarily due to the Gibbs Phenomenon. How much of this is present depends on the source image too, and even the nearest-neighbour result shows that the Lanczos downsampling has added some ringing to start with.
Even with the ringing certain features are significantly smoother - such as the brim of her hat, top of her shoulder, or the frame of the mirror.
Most of the design including using the Fourier Transform for arbitrary shift/scaling is from the paper Methods for Efficient, High Quality Volume Resampling in the Frequency Domain; Aili Li , Klaus Mueller. But i'm using the affine matrix decomposition in ``Bottleneck-free separable affine image warping''; Owen, C.B. ; Makedon, F. Image Processing, 1997. Proceedings., International Conference on (Volume:1 ). A related paper which just covers rotation is High Quality Alias Free Image Rotation; Charles B. Owen, Fillia Makedon.
Spectral Analysis
Visual appearnce is one thing, but how true to the desired signal is each result mathematically? Taking a log power spectrum of a portion of the image (without edges) allows me to look a bit deeper.
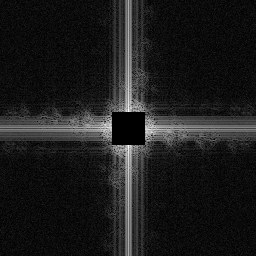
Since i've upscaled by 8x in each dimension an ideal (i.e. sinc filter) resampling will contain no higher frequencies than were originally present - i.e. for a 64x64 image upscaled by any amount, only the lowest 64x64 frequencies should contain any information at all (it will be rotated along with the signal however). To emphasise this I've zeroed out the signal-bearing frequencies in the following spectrograms so that only the distortion added by each algorithm is displayed.
To be "farier" on the 8-bit resampling i've also taken the power spectrum of the quantised 8-bit result of the Fourier based algorithm as used to generate the PNG. This quantisation mostly shows up (?) as noise along the axes.
Note that each spectrum is auto-scaled so the brightness levels do not necessarily represent equivalent amounts of distortion.
To the spectrums ... first the nearest-neighbour. This basically leaks a copy of the original signal as a grid across the whole spectrum.
Bilinear reduces these signal copies significantly apart from along the axes.
Bicubic reduces them further but there is still significant signal leaking out to the adjacent frequencies. Approximately 1.5x along each axis.
And finally the result from the Fourier based method. Apart from the axes which are primarily due to the quantisation to 8-bit (i think), most of the signal is just noise plus a little from the rotation leaking past the mask.
Hardware scheduling & stuff
Came across an interesting article on the hardware scheduling stuff AMD is finally getting together.
One of the more interesting aspects of the hardware and their HSA efforts. I'm surprised it took so long to finally realise something like this. But when I think about it, it CAN only work if the GPU goes through the same memory protection mechanisms as the CPU, and they've only just done that.
This should mean much faster graphics drivers as well as significnatly reduced OpenCL job dispatch overheads. I've had issues with large job dispatch overheads on AMD before so i'm interested in seeing what difference it makes.
I wonder how the job queues for CPU jobs are handled by the operating system and it's scheduler? Can they replace the run-queue entirely?
On a side note I haven't been doing a lot of hacking outside of work lately. Too many family related distractions, a wedding, and other stuff. Just don't have the energy at the moment.
At work i've been playing with some interesting resampling techniques using fourier transforms, I might post a bit about it later.
It works!
Just managed to get the relocating loader run it's first bit of code successfully:
~/src/elf-loader-1.0# ./reloc-test
elf_reloc_core `e-test-reloc.elf' to core 0,0 at 0x18000-0x1ffff
dump of section headers
Type name addr offset size entsz link info addralign flags
00: 0 SHT_NULL 00000000 00000000 00000000 0 0 0 0000000
01: 1 SHT_PROGBITS .init 00000000 00000034 00000024 0 0 0 0000002 SHF_ALLOC SHF_EXECINSTR
02: 4 SHT_RELA .rela.init 00000000 000047dc 00000030 12 36 1 0000004
03: 1 SHT_PROGBITS .text 00000000 00000060 00000398 0 0 0 0000016 SHF_ALLOC SHF_EXECINSTR
04: 4 SHT_RELA .rela.text 00000000 0000480c 00000324 12 36 3 0000004
05: 1 SHT_PROGBITS .fini 00000000 000003f8 0000001a 0 0 0 0000002 SHF_ALLOC SHF_EXECINSTR
06: 4 SHT_RELA .rela.fini 00000000 00004b30 00000018 12 36 5 0000004
07: 1 SHT_PROGBITS .jcr 00000000 00000414 00000004 0 0 0 0000004 SHF_WRITE SHF_ALLOC
08: 1 SHT_PROGBITS .data 00000000 00000418 00000458 0 0 0 0000008 SHF_WRITE SHF_ALLOC
09: 4 SHT_RELA .rela.data 00000000 00004b48 0000003c 12 36 8 0000004
10: 1 SHT_PROGBITS .ctors 00000000 00000870 00000008 0 0 0 0000004 SHF_WRITE SHF_ALLOC
11: 1 SHT_PROGBITS .dtors 00000000 00000878 00000008 0 0 0 0000004 SHF_WRITE SHF_ALLOC
12: 1 SHT_PROGBITS .tm_clone_table 00000000 00000880 00000000 0 0 0 0000004 SHF_WRITE SHF_ALLOC
13: 1 SHT_PROGBITS .rodata 00000000 00000880 00000004 0 0 0 0000004 SHF_ALLOC
... etc ...
actual loading of sections
1: load .init on-core @ 00058 host 0x18058 36
3: load .text on-core @ 00080 host 0x18080 920
5: load .fini on-core @ 00418 host 0x18418 26
7: load .jcr on-core @ 00434 host 0x18434 4
8: load .data on-core @ 00438 host 0x18438 1112
10: load .ctors on-core @ 00890 host 0x18890 8
11: load .dtors on-core @ 00898 host 0x18898 8
12: load .tm_clone_table on-core @ 008a0 host 0x188a0 0
13: load .rodata on-core @ 008a0 host 0x188a0 4
15: load IVT_RESET isr @ 00000
17: load RESERVED_CRT0 on-core @ 008a4 host 0x188a4 12
19: load .rodata.str1.8 on-core @ 008b0 host 0x188b0 8
20: load .bss on-core @ 008b8 host 0x188b8 8
core bss start = 008b8
21: load .bss.shared xshared @ 8e000000 host 0xb4e3e000 8
processing reloc hunks
offset symid addend type section symval symsize result name
1: 00000004 000002 0000015c R_EPIPHANY_LOW 3 00000000 0 [fffe805c / 0000005c <= 000001dc]
LOW p = 0x1805c <= low(000001dc) *p=0002000b <- 00121b8b
1: 00000008 000002 0000015c R_EPIPHANY_HIGH 3 00000000 0 [fffe8060 / 00000060 <= 000001dc]
HI p = 0x18060 <= hi(000001dc) *p=1002000b <- 1002000b
1: 0000000e 000002 0000035c R_EPIPHANY_LOW 3 00000000 0 [fffe8066 / 00000066 <= 000003dc]
LOW p = 0x18066 <= low(000003dc) *p=0002000b <- 00321b8b
1: 00000012 000002 0000035c R_EPIPHANY_HIGH 3 00000000 0 [fffe806a / 0000006a <= 000003dc]
HI p = 0x1806a <= hi(000003dc) *p=1002000b <- 1002000b
3: 00000090 000008 00000000 R_EPIPHANY_LOW 12 00000000 0 [fffe8110 / 00000110 <= 000008a0]
LOW p = 0x18110 <= low(000008a0) *p=0002000b <- 0082140b
3: 00000094 0001af 00000003 R_EPIPHANY_LOW 12 00000000 0 [fffe8114 / 00000114 <= 000008a3] ___TMC_END__
LOW p = 0x18114 <= low(000008a3) *p=0002200b <- 0082346b
... etc ...
15: 00000000 0001a4 00000000 R_EPIPHANY_SIMM24 17 00000000 10 [fffe8000 / 00000000 <= 000008a4] .normal_start
SIMM24 reloc 00000000 000000e8 <- 000452e8
17: 00000000 0001a5 00000000 R_EPIPHANY_LOW 3 00000000 132 [fffe88a4 / 000008a4 <= 00000080] _epiphany_start
LOW p = 0x188a4 <= low(00000080) *p=0002600b <- 0002700b
17: 00000004 0001a5 00000000 R_EPIPHANY_HIGH 3 00000000 132 [fffe88a8 / 000008a8 <= 00000080] _epiphany_start
HI p = 0x188a8 <= hi(00000080) *p=1002600b <- 1002600b
running test code
find symbol _shared
section base = 8e000000
shared address = 0xb4e3e000
before 0,0 after 0,0
before 0,1 after 1,1
before 1,2 after 2,2
before 2,3 after 3,3
before 3,4 after 4,4
Not much to look at it but it shows it's relocating and linking properly and communicating between the host and the epu.
So that's only for a single core, now I have to go away and think about multi-core programmes.
Loading bits and pieces
Bit of a combination of work, life, weather, drink (hmm i think i damaged my speakers again oops), hayfever, and sleep has kept me from being able to concentrate enough to get much done but I have made some progress. I managed to get a little bit done tonight but i'm pretty much stuffed and need a break.
But what I do have working is most of a relocating loader which can take a file linked with -r and splat it anywhere in a given memory space and resolve all the references to create a runnable programme. I worked out the epiphany reloc types I required for a small test code and verified them with the disassembler.
I ran in to some strange problems with writing directly to epu and the shared memory block but now I look at the code it seems I forgot to reset/halt the epu first. So hopefully it was just the epu running random junk and crashing the computer and not something funny about the writes.
To work around that (before i spotted the error above) I just wrote to a separate 32k block in memory and then dump it to an assembly file (as .bytes) i can then compile to a binary ... on which i can run a disassembler (e-objdump) to verify that the reloc has been spliced into the code properly. And what I have working looks all pretty hunky dory. About the only thing missing are some of the c-runtime support variables and constants like the stack location. Oh and resolving the weak symbols but that's straightforward. Hmm, and the code support stuff like symbol resolution. So plenty left.
Runtime linking
Moving the architecture details from the linker to the loader provides some interesting possibilities although it also presents some problems.
As outlined last post the intention is to use the section names to assign data+code to different regions such as specific data banks, or shared or private external memory. But this can quickly turn into a non-trivial optimisation problem if any of the fixed regions start to overflow and you try to fit them in anyway. i.e. if you assign to bank1 and subsequently bank0 overflows, what then? It might still be possible to honour the bank targets by shifting things around, although all the linker does currently is fill from the start and just borks if anything overlaps. Right now i'm just processing sections as they arrive (which is fairly random straight from the compiler) but they can be processed in any order and/or a linker script used to clean it up.
Having it in the loader also means I run up against some of the C runtime support stuff which is hardcoded into the current linker scripts and runtime. e.g. the bss range and stack pointer. The current crt0 (bootstrap) code only initialises a single bss section although I intend to have many and the bootstrap code still needs to be be the one initialising it. So i'll probably need my own crt0/bootstrap stuff and work out how to get gcc to use it (gcc 'specs' files have always been an indecipherable and opaque mess to me, but i think i can just do it with a command line). But because everything is relocated dynamically the loader can initialise dynamic/complex structures and link them into the bootstrap code if necessary.
Linker scripts are still needed for some purposes but they can be far simpler. e.g. to put libc into external memory it's easiest just to use a linker script to rewrite the target sections appropriately. It's probably worth using it to order the sections a bit more sanely and strip out some of the weird section names.
GDB
The real bummer about all this is that gdb wont work as is on any binary loaded in this manner - there are no programe headers and the load addresses of every section are dynamically assigned at runtime (although this doesn't necessarily need to hold for the on-core code, it's necessary for any external code).
TBH I don't like the idea of trying to run gdb on a 64-core chip anyway and i've managed with printf's (or raster bars!) and hard system resets ever since I started coding so I can probably deal with it personally.
My intention isn't to create an alternative sdk anyway just to experiment with some low-level code for a change.
Updated handbook
After too many probing questions on the parallella forums Andreas of Adapteva has released an early draft of an updated epiphany handbook which has some pretty interesting newly documented stuff in it. Some of the cooler features include a separate oob signal bus capable of work-group-wide signalling and synchronisation, and a broadcast write feature. The latter is will be very useful for loading the same code on multiple cores for instance, and the former for some multi-core primitives like barrier.
Looking forward to exploring that stuff ... when i finally get to it.
More ELF n stuff
Elf loader
I posted a simple elf loader for the parallella to the boards, but here's another link to it: elf-loader-0.0.tar.gz
This just handles the single-core case with nothing 'extra', it still requires special linker scripts and other foo.
It was really just a test to check some assumptions and fortunately they checked out.
A multi-loader?
I spent a few hours the night before trying to nut out a multi-core relocating loader but although I think I can pull it off it's kind of messy and it can't be made to do what I want it to.
The problem is that the linker will pull in all the library functions as static and although i can relocate per-core code to the per-cores, I need to copy all the static library functions used across all cores; and that just isn't going to be good enough given the tight memory.
What I really want is to have the linker create a specific binary for each core, ... but somehow handle multple cores too. But the problem is the linker will either whine or create redundant copies of any shared data structures.
So this morning I had a bit of an epiphany (pun intended) with the idea of using weak symbols. I can then define 'undefined' labels and just resolve them at load time. It does force me to use relocable code, but I need to anyway. Resolving and relocating a few undefined labels isn't that difficult and it's easy to tell if you failed.
That got me thinking a bit further and the way the linker is currently used isn't really that useful on the epiphany because it doesn't have an MMU. You can write code that sits on one core, or the same code that runs on multiple cores, but if you want to have multiple codes running on multiple cores each using private global memory - you're stuck with a huge headache of having to manually assign private memory ranges in the linker script! Might be acceptable for embedded programmers, but yeah, way too Commodore 64 for me these days.
But AmigaOS never had a problem running multiple code blocks it just relocated everything, even sparsely if that so happened. Simply ignoring all the elf-features designed for MMU capability makes a lot more sense than trying to shoe-horn them to fit. So does finding a better approach than using compile-time-fixed linker-defined memory map.
The solution
This is my first thoughts on how to solve this problem. I drop the notion of being able to target multiple cores within the one file but I get a pile of benefits.
- A single executable will map to a single core.
- The same executable can be loaded onto multiple cores.
- Multiple executables can be defined for loading a whole work-group.
- Code is linked using -r to create a relocatable object. This is the only tool-chain specific option required.
- Any code can reference code or data in other cores using weak references.
- Platform specifics like the stack base or end of the bss section are also weak references.
- The loader relocates the on-core data onto the core directly.
- The loader could potentially automatically spill sections to external memory if they don't fit.
- The loader resolves all weak references at the workgroup level.
- Specific section names are used for global or private external mememory.
- Platform specifics like the ISR table offset and the total on-core ram can be handled in the loader.
I still have to nut out some C runtime issues and where the weak reference's concrete instantiations are defined, but I'm pretty confident this will work and moreover that it is a good solution.
Since all the code is relocable there's no reason to use position independent code (which the compiler doesn't support yet) and there's no reason to include platform-specific details inside the linker script. The linker script can be very simple and is just used to partition external sections between on-core and off-core memory.
Note that even though the code is statically linked this will allow multiple separate instances of the the c (or other) library to be loaded across multiple cores. This might waste a bit of space but is much easier than dynamic linking and solves all the concurrency issues.
Relocating is more work than not having to, but it's not much work. And if a 7mhz 68000 can do it fast enough to be practical, surely a 1Ghz ARM can too.
Update: Moved the location of the elf-loader distribution.
EPU elf loader, reloc, etc.
I've come to the point where I need to start looking at placing different code on different epu's and having them talk to each other via on-chip writes ...
But the current SDK is a bit clunky here. One basically has to write custom linker scripts, custom loader calls, and then manually link various bits together either with custom compile-time steps or manual linking (or even hardcoded absolute addresses).
So ... i've been looking into writing my own loader which will take care of some of the issues:
- Allow symbolic lookup from host code, a-la OpenGLES;
- Allow standard C resolution of symbols across cores;
- Allow multi-core code to be loaded into different topologies/different hardware setups automatically.
Symbolic lookup
This is relatively straightforward and just involves a bit of poking around the ELF file. It's pretty straightforward and since ELF is designed for this kind of thing it takes very little code in the simple case.
Cross-core symbols
Fortunately the linker can do most of this, I just need a linker script but one that can be shared across multiple implementations.
My idea is to have the linker work against "virtual" cores which are simply 1MB apart in the address space. Section attributes can place code or data blocks into individual cores or shared memory or tls blocks.
Relocating loader
Because the cores are "virtual" the loader can then re-arrange them to suit the target topology and/or work-group. I'm going to rely on the linker creating relocatable code so i'm able to do this - basically it retains the reloc hunks in the final binary.
I'm not relying on position independent code for this - and actually that would just make life harder.
Linker too?
The problem is that the linker is going to spew if i try to put the same code into local blocks on different cores ... you know simple things like maths routines that really need to be local to the core. The alternative is to build a different complete binary for each core ... but then you're stuck with no way to automatically resolve addresses across cores and you're back where you started.
So it's going to have to get a lot more involved than just a simple load and reloc.
I'm just hoping i can somehow leverage/trick the linker into creating a single executable that has most of the linking work done, and then I'm able to finish it off at runtime without having to do everthing. Perhaps just duplicate all the sections common to all cores and then relocate and link in the per-core blocks.
Hmm, i think i need to think about this a bit more first.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!