About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

dead miele washing machine
Blah, washing machine blew up this morning. Novotronic W310, cost $1 900, bought Feb 2004.
During a spin cycle it started making very loud grinding noise and after turning it off and opening it up the drum had a really hot spot near the rim and a bit of a burnt rubber smell. Lucky I was home and it didn't catch fire. I was only washing a few t-shirts, shorts, undies, and my cycling shit.
Despite stating that the drum wont turn freely and that it rotates off-centre the service centre claims they can't tell if it will require major repair (it could only be a bearing, and that is a major repair) and still wants $200 for someone to come and have a look at it. Redeemable if i buy another one. I guess I got 5 weeks shy of 10 years out of it so I can't complain too much - then again being a male living alone for most of that time it hardly got much of a work-out either, so i'm not terribly inclined to buy another miele at the premium they charge here.
I guess i'll think about it over the weekend.
Washing machines aren't exactly a high priority item for a single male, but I don't want to have to deal with replacing broken shit either.
Road Kill
Finally got out on the roadie today and went for a 30km blat down to the beach and back. I haven't gone for a recreational cycle in nearly a year - had to give it a good wipe down to remove the dust and reinflate the tyres after taking it off the wall. I wasn't going to lycra it up but the shy-shorts I have these days come down to my fucking knees (longs?) and it was way too hot to wear those. Ran like new though, it's an awesome bike to ride.
Overall I can't say the experience was particularly enjoyable however - several cars cut me off and a pair of fuckwits (having a race?) nearly took me out through a roundabout on seaview road next to the grange hotel. I always hate that stretch and the fuckwit grange council obviously just hates bikes - they haven't changed it in years so I think i'll just avoid going down that way ever again - grange and henly are nice beaches but all the facilities and vendors are completely anti-cyclist so they can all just go and get fucked. I had to cut it short anyway due to a "natural break" required from a bit too much home-made hot-sauce on my dinner last night which was getting a bit painful. And somehow the racing saddle manages to find the only boney bits of my arse as well so 1.5 hours in 34 degree heat was enough of a re-intro trip after such a long break from it.
At least as a bonus I chanced on a homebrew shop that had a capping bell for champagne bottles - something i've been looking for for a while (not that i really need it, i have a ton of glass longnecks, but champagne bottles are much stronger). Yesterday I finally bottled off the last brew (nearly 2 weeks late - but it was still good, i ended up drinking over 4 litres straight out of the wart - it's quite decent but too warm) and started another one. Unfortunately all I have left from last year is 1 super-hot chilli beer (actually i had a half-bottle of one of those last night, maybe that was the cause of the natural break requirement) and a few stout/porter-like things which are a bit heavy for this weather - so after i finish this lime cordial and soda I'm going to have to find something else to drink today.
I really need to get back into regular cycling but it's not going to happen unless I can find some route that is safe and enjoyable and not too boring to do it on. That's a big part of why I've been so slack at it since coming back from Perth (and all my cycling mates moved interstate or os). Chances are this is the just another last ride for another 6 months, but time will tell ...
Update: Sunday I went to see a friend at Taperoo and he took his young family down to the beach. Apart from a couple of spots that isn't such a bad ride so maybe I can do the Outer Harbour loop - it's about 90 minutes on a good day. Even though one road is a bit truck laden there's plenty of room. Given the weather this week I had thought of hitting the beach a couple of times but today it was already 41 by 10:30 - and a burning northerly wind - so I might not be going anywhere after the washing machine is delivered. Monday I went for a loop through the city and around about to buy a washing machine and do a bit of shopping and that was pretty much the limit - I seemed to catch every red light and waiting in the full sun on newly laid ashphalt on a still day really takes it out of you. The LCD panel on my speedo even started to turn black so hell only knows how hot it was out on the road. And it's warming up tomorrow ;-)
Update: Well this has now become very strange weather. 40+ in summer is as common as sheep shit around here but it ended up hitting 45.1 at 2pm which is a bit on the extreme side even for here (i believe it may be a record for Kent Town). And now thunderstorms are coming? They are looking to miss me, but if they hit it'll turn the place into a sauna. Just saw a nice fork of lightning about 18 seconds away (~6km). Time for beer and a light-show?
Update:
Only 4th hottest day on record after all.
Fast Face Detection in One Line of Code
**** **** ****
* * * * * *
**** **** ****
**** **** ****
* * * * * *
**** **** ****
**** **** ****
* * * * * *
**** **** ****
(blogger is broken: this is supposed to be a pic)
Based on the work of the last couple of weeks I've written up a short article / paper about the algorithm and created a really basic android demo. I think it's something novel and potentially useful but i'm not sure if i'm just suffering from an island effect and it's already been tried and failed. I tried to find similar research but once outside of the software engineering realm the language changes too much to even know if you're looking at the same thing when you are. Statistics gives me the willies.
Since I did this at home and am not aquianted with the academic process I didn't know what else to do. None of my peers, aquaintances or contacts do similar work for a hobby.
I have created a basic 1990s style `home' page on my ISPs web server to store the paper and application and anything else I may want to put there. This may move in the future (and perhaps this blog will too).
And yes, it really does detect faces in a single line of code (well, significant code) - and we're talking C here, not apl - and on SIMD or GPU hardware it is super duper fast. I haven't even looked at optimising the OpenCL code properly yet.
I wasn't going to but I ended up creating an optimised NEON implementation; I kinda needed something to fill the timing table out a bit in the article (at the time; it filled out afterwards) but I guess it was worth it. I also wrote up a NEON implementation of the LBP code i'm using this afternoon and because it is only 4 bits it is quite a bit faster than the LBP8,1u2 code I used last time, although in total it's a pretty insignificant part of the processing pie.
Now perhaps it is time for summer holidays.
And just to help searchers: This is an impossibly simple algorithm for a very fast image classifier and face detector which uses local binary patterns (LBP) and can be implemented directly using single instruction multiple data (SIMD) processors such as ARM/NEON and scales very well to massively multi-core parallel processors including graphics processing units (GPU) and application processing units (APU). OpenCL, CUDA, AMD, NVidia.
Further beyond the ROC - training a better than perfect classifier.
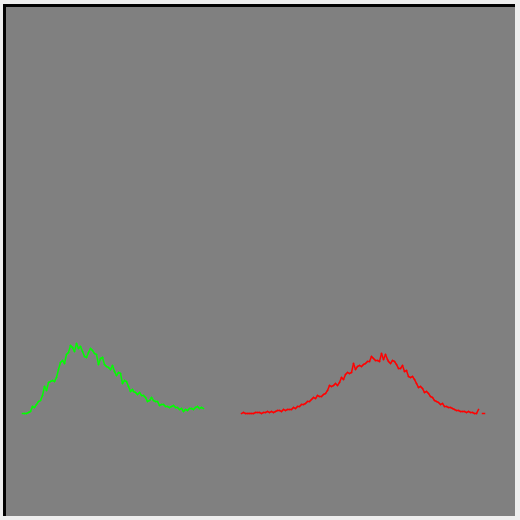
I added a realtime plot of the population distribution to my training code, and noticed something a little odd. Although the two peaks worked themselves apart they always stayed joined at the midpoint. This is not really strange I guess - the optimiser isn't going to waste any effort trying to do something I didn't tell it to.
So with a bit of experimentation I tweaked the fitness sorting to produce a more desriable result. This allows training to keep improving the classifier even though the training data tells it it is 'perfect'. It was a little tricky to get right because incorrect sorting could lead to the evolution getting stuck in a local minimum but I have something now that seems to work quite well. I did a little tuning of the GA parameters to speed things up a bit and added a bit more randomisation to the mutation step.
The black line is the ROC curve (i.e. it's perfect), green is the positive training set, red is the negative. For the population distrtribution the horizontal range is the full possible range of the classifier score, and vertically it's just scaled to be useful. The score is inverted as part of the ROC curve generation so a high score is on the left.
The new fitness collator helps push the peaks of the bell curves outwards too moving the score distribution that bit closer to the ideal for a classifier.
The above is for a face detector - although I had great success with the eyes I wanted to confirm with another type of data. Eyes are actually a harder problem because of scale and distinguishing signal. Late yesterday I experimented with creating a face classifier using the CBCL data-set but I think either the quality of the images is too low or I broke something as it was abysmal and had me thinking I had hit a dead-end.
One reason I didn't try using the Color FERET data directly is I didn't want to try to create a negative training set to match it. But I figured that since the eye detector seemed to work ok with limited negative samples, so should a face detector so I had a go today. It works amazingly well considering the negative training set contains nothing outside of the Color FERET portraits.
Yes, it is Fantastic.
I suspect the reason the Color FERET data worked better is that due to the image sizes they are being downsampled - with the same algorithm as the probe calculation. So both the training data and test data is being run through the same image scaling algorithms. In effect the scaling is part of the LBP transform on which the processing runs.
This is using a 16x16 classifier with a custom 5-bit LBP code (mostly just LBP 8,1).
The classifier response is strong and location specific as can be seen here for a single scale. This detector here is very size specific but i've had almost as good results from one that synthesized some scaling variation.
I couldn't get the young klingon chick to detect no matter what I tried - it may just be her pose but her prosthetics do make her fall outside of the positive training set so perhaps it's just doing it's job.
Beyond the ROC
I mentioned a couple of posts ago that i was hitting a wall trying to improve the classifier using a genetic algorithm because the fitness measure i'm using reached 'perfect' ... well I just worked out how to go further.
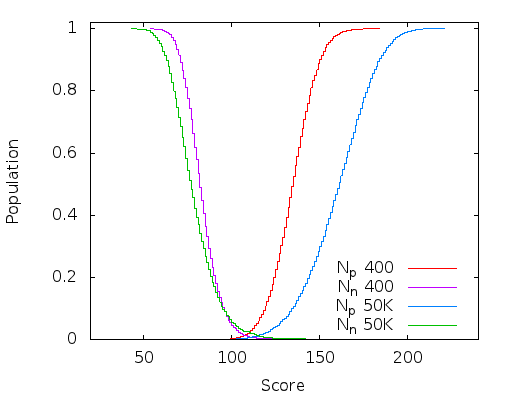
Here is a plot of the integral of the population density curve (it's just the way it comes out of the code, the reader will have to differentiate this in their head) after 400 and 50K generations of a 16x16 classifier. I now have the full-window classifier working mostly in OpenCL so this only took about 20 minutes.
Although a perfect classifier just has a dividing line separating the two populations, it is clear that these two (near) perfect classifiers are not equal (the above plot was generated from a super-set of the training data, so are not perfect - there should be no overlap at the base of the curves). The wider and deeper the chasm between the positive and negative population, the more robust the classifier is to noise and harder to classify images.
400 generations is the first time it reached a perfect ROC curve on the training data. I just let it run to 50K generations to see how far it would get and although most of the improvement had been reached by about 10K generations it didn't appear to encounter an upper bound by the time I stopped it. Progress is quite slow though and there is probably cause to revisit the genetic algorithm i'm using (might be time to read some books).
This is a very significant improvement and creates much more robust detectors.
Because the genetic algorithm is doing the heavy lifting all I had to do was change the sorting criteria for ranking the population. If the area under the ROC curve is the same for each individual then the distance between the mean positive and mean negative score is used as the sort key instead.
The Work
So i'm kind of not sure where to go with this work. A short search didn't turn up anything on the internets and recent papers are still mucking about with MP-LBP and integral images on GPUs which I found 2 years ago are definitely not a marriage made in heaven. The eye detector result seems remarkable but quite a bit of work is required to create another detector to cross-check the results.
The code is so simple that it's effectiveness defies explanation - until the hidden maths is exposed.
I started writing it up and I've worked out where most of the mathematics behind it come from and it does have a sound basis. Actually I realised the algorithm is just an exisiting common algorithm but with a single specific decision causing almost all of the mathematics to vanish through simplification. I first looked at this about 18 months ago but despite showing some promise it's just been pretty much sitting idle since.
tablet firmware
I had my occasional look for updated firmware for my tablet yesterday - an Onda V712 Quad - and was pleased to find one came out late November. All firmwares, I guess.
For whatever reason this particular tablet seems to be remarkably uncommon on the internet. Apart from the piss-poor battery life it's pretty nice for it's price - although that is a fairly big issue I guess.
I apparently bricked it running the firmware updater via microsoft. Nothing seemed to be happening/it said the device was unplugged, so after a few minutes I unplugged it. Don't really know what happened but the list of instructions that then popped up in a requester managed to get it back on track. Not that I needed it this time, but every time I go into the recovery boot menu I forget which button is 'next' - the machine only has power and home - and always seem to press the wrong one, but luckily I didn't really need it. I know from previous readings that the allwinner SOCs are completely unbrickable anyway, so i wasn't terribly concerned about it.
After a bit of confusion with the - i presume - ipad like launcher they decided to change to, I got it back to where it was before. I didn't even need to reinstall any apps.
So although it's still android 4.2 (4.4 is out for some of their tablets but not this one, not sure if it will get it, Update 11/1/14: 4.4 is now up for my tablet but i haven't tried it yet) they fixed a few things.
The main one for me is that media player service plays streaming mp3 properly now: previously my internoderadioplayer app wouldn't play anything onitdidn't work. I might be motivated to fix a couple of things and do another release sometime soonish.
Other than that it just feels a bit snappier - although I really wouldn't mind if you could set the display to update at some low frame-rate like 12-15fps to save power. That full-screen render can't be cheap on battery and most of the animations just give me the shits to start with.
I'm still a bit annoyed how they changed the order of the software buttons along the bottom - having back in the corner followed by the rest made much more physical sense with all the varying screen sizes out there. Having them centred is a pain in the arse, and I keep accidentally activating that 'google' thing on that bizarre circular menu thing off the home button when trying to scroll scroll scroll through long web pages because there's no fucking scrollbar on anything anymore. I don't even know what that google thing is for (read: i have no interest in finding out) but I sure wish I could disable it from ever showing up.
Pretty much only use it as a web browser for the couch anyway - the screen is too shiny to use outside (despite a very high brightness). Typing on a touch screen is utterly deplorable, and playing games on one isn't much better. It's just passable as a PDF reader, although I wish mupdf handled off-set zoom with page-flipping better (it's a hard thing to get right though). I'm finding the over-bright black-on-white becoming somewhat irritating to read for very long so i might have to patch it for a grey background anyway. Actually it's quite useful for finding papers - for some reason Google search from my desktop has decided to keep returning stuff it thinks I want to read, rather than what I'm searching for. So that just means I keep finding the same fucking papers and articles i've already read - which isn't much use to me. Fortunately for whatever reason the tablet doesn't have this problem, ... yet.
I had to turn off javascript in firefox because it kept sucking battery (and generally just kept sucking full stop), any websites or features that rely on it just wont work - if that breaks a web site then I just dont bother returning. I've no interest in commenting on blogs or forums from it so it doesn't break much for me. Amazing how much smoother the internet is without all that crap. Everything has layout problems too because I force a typeface and font size that's big enough to read; but I have that problem on every browser. Dickhead web designers.
eye detector again
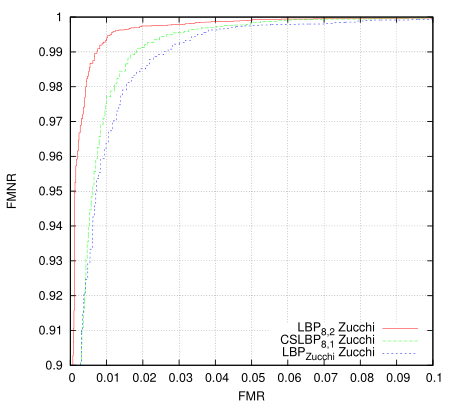
I was playing around with generating ROC curves for various algorithms - first I was trying to determine whether some new LBP codes I came up with worked better in certain cases (not yet, but they have promise, ok i kept playing as below: maybe they do already). For this purpose I implemented a basic LBP histogram matching algorithm, as I figured having baseline would provide a decent comparison.
This just took all eye images as one class and all non-eye images as another and then measured the distance of them all to the classifier. I'm using 20x20 images and the classfier creates 16 histograms from 8x8 tiles overlapping by half in each direction. It isn't terribly valid as a measure because it is using the same set for training and for testing but i'm only after the relative results. There are 10560 positive training examples and 9940 negative examples in the data set, all taken (and synthesised) from Color FERET fa partition. I'm only using abs difference as the distance measure which isn't ideal, and perhaps the 8x8 tile area isn't a large enough sample to build a decent histogram - in short, these histogram results are not tuned for performance.
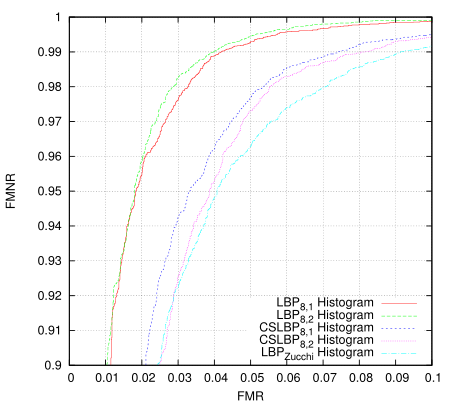
The Zucchi LBP is using some directional differential filters in order to build the LBP code bit-planes. The idea is that they're tunable to the problem, should be more robust to noise, and generally produce a more noise-free and accurate LBP code. They are much more expensive to calculate however. This tunability offers another possibility for GA optimisation. I guess this is something else I should really write up properly.
Then I revisited the classifier I came up with late 2012 (the one I put into a small android app). Here the data and LBP transform are the same, only the algorithm has changed.
Blew me away a bit, I really didn't expect that much of an improvement. The 'Zucchi' algorithm requires a tiny fraction of the storage and fewer cpu instructions to process. Training takes more memory but fewer instructions per pixel. The original goals in designing it were for it to be SIMD parallelisable (at execution time) so it optimises very well. The first algorithm should be more robust to registration errors, but on this test the differences are remarkable and in many cases you don't want/need such robustness.
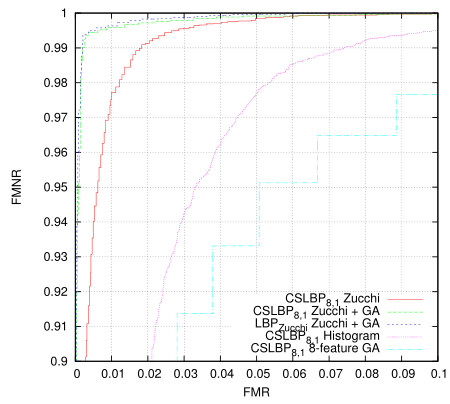
Then I wondered if this classifier could be trained using GA instead. Here I truncated the training set to 8192+8192 images to match the OpenCL GA algorithm, so the results are slightly more valid.
Somewhat surprisingly given the size of the problem (each individual is ~6K bits) it works extremely well and attains a result in only 300 generations. Actually the problem I have is that it is almost too good(tm) - before doing much of a search of the problem space the utility of the fitness measure has been exhausted and the population no longer evolves. One might also note that this result is for the relatively information poor 4-bit LBP codes, and in all cases is only a single-stage classifier.
Given the results I should probably look at the data that isn't classifying properly at each end, some of it may just be poor / incorrectly labelled data. Update: I had a look - the false negatives at the upper end are from synthesised images some of which are over-rotated or rotated off-centre. A couple of the false positives are samples taken a bit too close to the eye although most are legitimate and from around under the nose to under the mouth.
The 8-feature test as described in the previous post doesn't fare so well here - even though it is an effective eye detector in practice and requires about 1/3 of the processing.
Here the differential LBP code is working very well too. And it works extremely well as an eye detector in practice.
For this post I wasn't going to run the differential LBP codes through the GA algorithm based on the first plot - it didn't seem that good. But the final plot and this eye detector heat map somewhat validates the initial reasoning behind the algorithm - reduced noise. See the previous post.
Looking closer at the LBP code image I now see there isn't enough similarity between the left and the right eye regions in the LBP domain to try to create a classifier which resolves both at the same time. What I might do instead is create separate classifiers but not include the other eye in the negative training set - this should improve the results of both. I guess i'm near the point where spectacles should be added to the mix.
I've started writing some of this up but i'm a bit lazy to put the effort in required to do a good job. Apart from the fact that i'm only doing this for self education and entertainment purposes in my spare time right now, i've little experience writing papers. I'm purportedly on holidays for that matter - technically i'm even unemployed but literally i'm just between contracts.
Update: Oops, looks like I made a bit of a mistake. I thought I was using a decent resampler whilst generating the scaled training data, but it wasn't - so aliasing was creating noise in the small-scale images and thus in the LBP codes. This is probably why the derivative LBP code managed to win out in the end. This mistake will lead to the plots showing poorer performance than they should be - but i'm not going to re-run the plots right now.
Seeing that the classifier was doing such a good job, I thought i'd push it a bit harder. I have a couple of other ideas too but the first one I tried was to create a classifier for a very small region. This has very large implications on execution time. So whilst working on an 8x8 classifier I noticed the aliasing and realised the scaling problem. I still have an issue with pixel-boundary sampling when extracting the normalised eye so the data is of a lower quality - but it has to deal with these problems in the input data too.
An 8x8 detector is absurdly small. Here's an example of a decent training image from the training set:
Testing on Lenna's photograph gives quite a few false positives - but out of 181 244 tests, 30 or even 100 false positives isn't too bad for a single-stage classifier. An 8x8 classifier requires 16x less total processing from the inner loop vs a 16x16 classifier to detect the same sized features at the same input scale - so even a modest true negative rate could be a big win if it is reliable. And this doesn't count the image scaling and LBP operator both of which also scale at an N*N rate.
This is just one run of a single-pass 8x8 detector generated via a GA using left and right eye images as the positive set. The threshold was chosen roughly. There are a total of 43 hits out of a total of 181 244 probes, with a false acceptance rate of 0.022%. It took about an hour to generate this detector via pure-Java code on a 6-core intel machine.
This is one run of a single-pass 20x20 detector generated via GA using left-eye images as the positive set. It is being executed over a wide range of scales from 0.2x to 1.5x of the original (512x512) source. There are a total of 22 hits out of a 5 507 592 probes, with a false acceptance rate of 0.00016%. It took about 3 minutes to generate the classifier using the same pure-Java code on the 6-core intel at which point evolution stopped due to having a perfect classifier on the training data set. It took under 200 generations on the improved input data vs the numbers in the top-half of this post.
Update 2: I wasn't going to, but I compared it to the raw results from the left-eye cascade from OpenCV - i remembered it not being particularly good but wanted to quantify it. This is showing the raw hits as exit the cascade and do not include grouping which would remove most of the false positives. There are 313 total hits.
For comparison purposes I re-ran the 20x20 classfier with settings that result in about the same number of scans at roughly the same scales. Here there are 64 total hits, although I just chose an arbitrary threshold value (a fairly loose one however). Haar cascades only provide a binary true/false result and have no threshold that can be adjusted - they also provide no quality indicator so there is no way to choose a peak match and one must resort to error prone averaging and merging.
This code executes about 30% faster than the haar cascade although perhaps the looseness of the haar detector would allow it to be run on fewer locations at the cost of accuracy. However; accuracy is often important if not critical. It should be possible to train a better haar-cascade but I haven't had any luck geting even close to the ones supplied in OpenCV. Likewise this is still only a single-stage classifier and can still be improved (I think) quite easily.
One last data point - the 8x8 classifier over similar scales executes 10-20x faster. These classifiers also scale much much better on parallel hardware - all the way from SIMD to multi-stream GPUs, so this 30% figure is a little misleading. It would also take only a tiny bit of FPGA logic ...
eye detector
I thought i'd see how well the detector works on more general data so first I cleaned up the data a bit and ran against a test image. I cleaned out some closed eyes and excessive squint, mis-alignment, and fiddled a bit with the ratio of eye-size to region. I ended up going with a 20x20 region because adding a bit more height to the classifier seems to help with nose and mouth false-positives. I synthesised a number of rotated images but kept the scale fixed, and included both left and right eyes in the positive training set.
In short, I trained a classifier for open and straight-on eyes only, with a small amount of head tilt (+- 15 degrees) and only misalignment variation to the scale. No spectacles.
This is the raw results after running the detector over 19 scales from 0.2 to 0.5 of the original Lenna image. The scale range isn't chosen arbitrarily obviously. Whilst the threshold can be adjusted to remove the false positive I left it in to demonstrate some remaining issues. Although blank areas aren't that big of a problem as they can be detected via other means such as variance.
This was the single highest response from all scales tested. The heat map is rendering exp(score), and the result is normalised to highlight the peaks more clearly. The signal being processed is the local binary pattern (LBP) image in the centre, which is a 4-bit CS-LBP 8,1 operator with pixel centered sampling.
As can be seen, It's very good at picking out Lenna's right eye ... her left eye is a bit obscured and off-angle and generally gives the detectors i've tried a bit of grief. It doesn't work well with outside images due to squint, or portraits against a blank background (blank areas score well). But given all of the negative training data come from only face images, it's working quite well as suppressing non-eyes. It has some problems with scale - once the face is about 2x the size the detector expects it starts to pick up eyebrows/noses/mouths/under-eyes but again given the training data this is to be expected - and generally the eye detector is only run after you have face candidates.
This is just with a single 8-feature (4x4) classifier which processes a 20x20 region. I had intended to create a multi-stage classifier but I got side-tracked.
This is the regions used by the classifier created in this example, overlayed with one of the positive training images. The data comes from Color FERET. Any significant overlap is essentially wasted processing (apart from a weighting factor of the overlapped region), so in this case the ga may not have chosen the best solution. It may be worth investigating whether I can get better results by pre-locking the regions and just letting the genetic algorithm choose the other classifier parameters instead.
It took a few runs of the classifier to get a this good result - although the ROC curve fitness measure works well, each run tends to 'lock on' to specific feature points and so that limits the performance to a local peak. If a random bit-flip hits the coordinates it just creates a poorer classifier and it dies immediately.
Some earlier trials had greater problems with background but this particular one was looking very good after about 1K generations so I just kept letting it run for much longer to see if it would get better - it did slightly and the first individual reached 'perfection' on the training set after about 55K generations (around 40 minutes, 8K of each class). Although that wasn't necessarily the best classifier in practice.
Experiments on-going ...
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!