About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Starting JavaFX from random Java code
I write a lot of prototype routines - too many to keep track of in separate projects so I end up with a ton of mains(). Best practice? Who gives a shit: its a prototype, played with for a day or a week and then forgotten.
So far for graphical output i've just been using Swing: actually there's probably not much reason not to use it for that because it does the job but once you need to add some interactivity it becomes a bit of a pain if you've been playing with JavaFX. I might add a 'display intermediate image' anywhere in the code and up it comes.
But JavaFX doesn't let you just call Platform.runLater() or new Stage() from anywhere as with Swing: the system needs initialising within an Application context.
Here's a solution. I have no claims it's a good one but it works for me so far.
// This code is placed in the public domain
public class FXUtils {
static FXApplication app;
static Semaphore sem = new Semaphore(0);
public static void startFX(Runnable r) {
if (app == null) {
try {
Thread t = new Thread(() -> {
FXApplication.start(r);
});
t.start();
sem.acquire();
} catch (InterruptedException ex) {
}
} else {
Platform.runLater(r);
}
}
public static class FXApplication extends Application {
WritableImage image;
static Runnable run;
public FXApplication() {
}
@Override
public void start(Stage stage) throws Exception {
app = this;
run.run();
sem.release();
}
public static void start(Runnable r) {
run = r;
// Application.launch() can only be called from a static
// method from a class that extends Application
Application.launch();
// no windows - no app!
System.exit(0);
}
}
}
Whether start() calls System.exit() or not is up to you - personally when I close a window i'm prototyping stuff on I want everything else to fuck off for good.
And this is how to use it:
public static void main(String[] args) {
FXApplication.start(() -> {
// Now on javafx thread
Stage s = new Stage();
s.setScene(new Scene(new VBox(new Label("foobar!"))));
s.show();
});
// Will wait for javafx to start, but then continue here
// exiting will leave the windows open, till they're closed
}
This uses a thread to launch javafx so that the original main thread can continue; Application.launch() doesn't return until the last window is closed so would otherwise block. The thread could be made a daemon too for some different behaviours.
If you just want to launch a full JavaFX application from multiple mains then none of this is required, just create a static start() method which calls Application.launch().
lambdas & streams
As part of the experiment with the histogram equalisation stuff I started writing a utility library for playing with images for prototyping code.
One thing I was curious about was whether I could use streams to simplify the prototyping by saving having to type and retype the typical processing loop:
for (int y = 0; y < image.height; y++) {
for (int x = 0; x < image.width; x++) {
do something;
}
}
When i'm prototyping stuff I type this in ... a lot.
I had mixed results.
Because I wanted to support arbitrary 2d subregions of an image which might be a mapping of an arbitrary 2d subregion I had to create my own 'spliterator' to do the work. After a couple of aborted attempts I came up with one that just turns the widthxheight range into a linear stream and then maps that to the local (x,y) when retrieving the pixel values (i tried to avoid the divide first, but made a pigs breakfast of the maths).
It lets me write something like this to calculate the histogram over a sub-range of an image:
Image2D img;
byte[] hist = new byte[256];
img.bytes(0, 0, 16, 16).forEach((v) -> > {
hist[v] += 1;
});
Ok, so far so good. It's not necessarily the best way to do it - it can't be parallelised for instance, but this is fine, it saves a few keystrokes and it lets one access a whole bunch of stream functionality "for free".
The problem is with images you normally want to write to them or modify them. So you're back to just using a loop, or maybe a custom foreach which supplies coordinates to a lambda function: again this is fine but then you don't get any of the stream functionality for free here (although as in the next section: it's good enough?). You could just use an IntStream, ... but that doesn't really save any typing over a for loop.
Staying within the confines of the existing IntStream type for the sake of argument, the solution is a little clumsy. One first has to create a class which implements the functions required to be used as a collector.
static class ByteArray {
byte[] data;
public void add(int b);
public void addAll(ByteArray b);
}
With that in place it can be used to collect the results of the calculation. In this case performing the pixel mapping from one set of intensity values to another.
byte[] pixels = img.bytes()
.map((int v) -> map[operand])
.collect(ByteArray::new, ByteArray::add, ByteArray::addAll)
.data;
Image2D dst = new ByteImage(src.width, src.height, pixels);
This can run in parallel: the downside is that each stage needs to allocate its own buffers and then allocate copies of these up to the final result. Probably works but yeah, it's not that pretty or efficient.
Indexed Stream
So I thought about it a little and perhaps a solution is to create another type of stream which indexes over the values. Some of the api usage gets a bit fatter if you want to use some of the basic stream facilities like sums and so on: but that's what .map() is for. I think it can get away without having to allocate the indexing object for each iteration: it is only needed when the stream range is split.
class IndexedInt {
int value;
int x;
int y;
}
dst = new ByteImage(src.width, src.height);
img.bytes().forEach((ii) -> {
dst.set(ii.x, ii.y, ii.value);
});
I dunno, I suppose that's better than a double-for-loop, once the not-insignificant scaffolding is in place.
Actually; why bother even passing the value in this case, it may as well just be calculating indices. It doesn't really make any difference to the code and having a general purpose 2D indexer is somewhat useful.
class Index2D {
int x;
int y;
}
dst = new ByteImage(src.width, src.height);
Index2D.range(0, 0, src.width, src.height)
.forEach((ii) -> {
dst.set(ii.x, ii.y, src.get(ii.x, ii.y));
});
Some of the functionality is a little less concise but the simplicity of the above is probably worth it.
double average = Index2D.range(0, 0, src.width, src.height)
.mapToInt((ii) -> img.get(ii.x, ii.y))
.average()
.getAsDouble();
Much of that could be hidden in helper functions and the external interface could remain an IntStream, for cases where the pixel locations are not required.
Seems like a lot of work just to get a free parallelisable 'sum' function though? The implementing classes still need a bunch of boilerplate/helpers and they could have just implemented most of that themselves. I don't find the forkJoin() approach to paralellisation (which is used by the streams code) to be very efficient either.
But this is my first real look at it : experiments ongoing.
Parallel histogram
I mentioned earlier that the histogram calculation using a forEach isn't paralleisable as is (one could add a synchronized block inside the loop but one would have to be both naive and stupid to do so).
It can be parallelised using a collector. TBH it's a lot of boilerplate for such a simple function but the algorithm is identical to the one you would use in OpenCL even if it doesn't look the same.
First, one needs the class to hold the results and intermediate results.
class Histogram {
int[] hist;
public Histogram() {
hist = new int[256];
}
public void add(int value) {
hist[value] += 1;
}
public void addHistogram(Histogram o) {
for (int i = 0; i < hist.length; i++)
hist[i] += o.hist[i];
}
}
And then the code:
int[] hist;
Image2D img;
hist = img.bytes().parallel()
.collect(Histogram::new, Histogram::add, Histogram::addHistogram)
.hist;
*shrug*. I guess it saves some typing?
tunable histogram equalisation
So this is a rather simple but quite effective improvement to the basic histogram equalisation operation for automatic image correction.
I got the main idea from a paper: ``A Modified Histogram Equalization for Contrast Enhancement Preserving the Small Parts in Images''. Bit of a mouthful for what is just a bounded histogram.
I also made made another small modification which makes it tunable. Allowing for a fairly smooth range from what should be the same as 'normalise' in paint programs, up to the fully sun-seared over-exposed normal result from histogram equalisation.
Here's an example of the range of output.
The value is the proportion of the mean to which the histogram input is limited: a value of 0.0 should be equivalent to a contrast stretch or normalise operation, 1.0 matches the paper, and some large number (depending on the input, but approximately greater than 2) will be the same as a basic histogram equalisation.
One has to look closely with this particular image because they are already fairly balanced but a smooth range of 'enhancement' should be apparent.
I also played with a colour version which applies the histogram to the Y channel of a YUV image.
As of now it does tend to upset the colour balance a little bit and tends toward a metallic effect; but it's arguable better than what the gimp's equalise does to colour images.
Yikes. Although the image on the right is arguably more agreeable - the colour is very different from the source. Histogram equalising each component separately is effectively applying a white-balance correction where the colour temperature is some sort of flat grey: this sometimes works ok but it messes with the colour balance by definition.
I have some thoughts on applying the algorithm to floating point values using polynomial curve fitting, but I haven't tried them out yet. This would be to prevent binning from quantising the output.
For such a simple adjustment to the algorithm it's quite a good result - histogram equalisation is usually too harsh to use for much on it's own.
On my god, it's full of local binary patterns!
I recently had need to look into feature descriptors. I've previously played with SURF and looked into others but I wasn't really happy with the complexity of the generator and needed something Java anyway.
A small search turned up FREAK (why the silly 'catchy' acronym names? Maybe it started with S-USANs?) which looked doable so I had a bit of a play. There is code available but it's OpenCV and C++ and the version I saw just wasn't very good code. I wrote up my own because I had some different needs for what I was looking at and porting the C++/OpenCV was going to be a pain.
I guess they work as advertised but i'm not sure they're what I want right now. I tried porting the AGAST detector as well but it wasn't really getting what I was after - i'm after specific features not just 'good features'.
The paper does include this interesting diagram though:
Although the paper doesn't reference them this diagram is pretty much a description of local binary patterns. The FREAK descriptor itself is just a very long local binary pattern with optional orientation normalisation.
Perhaps more interestingly is that this specific diagram could just as well be a description for how my fast object detector works. It is effectively a direct implementation of this diagram.
Assuming the above diagram is representative of human vision I guess one could say that the whole of visual reality is made of local binary patterns.
bummer, that bandwidth thing again
I did some profiling by clearing the framebuffer directly from the epiphany.
Short summary:
- Using dma takes about 20% longer than using the cpu (this is useful though because it can run asynchronously to the cpu).
- Using int writes is 1/2 the speed of long writes (but this is a known feature of the design).
- Writing sequential addresses is about 2x faster than not (again: known).
- Writing with one core is 2x faster than with 1 cores (due to last point, known again).
- Trying to get the compiler to do a long write is a pain. volatile seems to do it for this case.
- Using hardware loops was nearly 10% faster than not, but you need to do 16 instructions (for easier loop count setup) in the loop which makes it too bulky. I don't understand why this is because I can add a couple of nops before it makes any difference to the execution time; must be something to do with the write-to-mesh pipeline mechanism.
- A simple C loop on the ARM writing to the memory-mapped framebuffer using int is about 5x faster than the epiphany.
My screen is 1280x1024, 24-bit - don't know if that can be configured to fewer bits as i have no serial console and that's just how it starts up (at least it's not widescreen).
I know it's not the case but it appears as if the memory transfers are somehow synchronised with the framebuffer DMA. It's only getting about 60 fps. At any rate, they're running at the same speed.
that sucked a bit
I guess i should've known when i woke up feeling underslept with a headache. It was a dreadfully cold and stormy day so I ... well hacked again.
I had intended to just get a triangle out of an epiphany core, but it just didn't end up happening. I had to muck around getting the rev1 to a 'working' state which took surprisingly long. There are a lot of weird shitty changes to ubuntu (i mean, runlevels, why the fuck would anyone want those???) that took me a while to wade through. I did run the C code I have which outputs to the framebuffer, which worked but is a bit slow. I did seem to have weird issues with USB but a reboot more or less fixed that, with it running through a powered hub. nfs was super-slow till i set it to nfs3 mode. Apparently that's a thing that happens. I also ran one of the ezesdk tests and that worked ... i wasn't sure if that would.
And god, what the fuck have they done to the gtk+ version of emacs? It's like a really ugly version of notepad. I wish I had have found the emacs-lucid packages an hour earlier, would've saved my throat a good deal of violence. But I guess at some point the lucid version wont work anymore, I might have to find another editor (yeah it's that bad).
And what's with all the config/startup shit in debian and ubuntu? Run one tool and it gives a completely obtuse but apparently deep and meaningful message about using another tool, the other tool doesn't know what the fuck's going on and in the end you just edit a file by hand? Why is there even more than one? apt-get/dpkg/whatever else is bad enough. What sort of genious thought that "update-rc.d" was a nice name for a command anyone might ever want to run, ever? Trying to find solutions using a search engine is becoming pointless: it's the blind leading the blind and everything is years out of date. Try finding out how to disable screen blanking on the console for example?
This worked for me:
echo "setterm -blank 0 -powersave off -powerdown 0" >> /etc/rc.local
Net"work"Manager was still spewing pointless shit to the logs whilst trying to "dynamically manage" a fixed ethernet cable ... so fuck that right off. Although i wish more shit actually logged happenings: it seems almost nothing logs when anything goes wrong. I don't see how dedicating a whole virtual terminal to the almost completely information-free "boot.log" is of use to anyone. The packaging system seems to have turned into a sort of enterprise configuration management tool: and you know what, they suck. They're slow and cumbersome and buggy as all shit, and we know because it's linux some doe-eyed fool will come along in a year or two with a new and even more broken 'fix' for all the brokenness.
I can't believe after 20 years of this shit ... it's now way more broken than how it started. At least back then the problems were restricted to hardware support. Now that's fantastic the software has all been fucked up by people poking their noses into places they have no fucking business being.
And i'm still underslept with a headache, with added fun of cold and hungry.
Rasterisers
After the last post I kind of remembered one reason to split the work across cores: calculating the reciprocal of 1/w is somewhat expensive unless it can be batched up.
So I was up way too late last night just trying different snippets of code to address that. I think I will go the branchless loop thing that performs the z-buffer test and in-triangle tests separately and then outputs a compact set of coordinates. The compiler was doing some funky stuff but I got some hand-rolled code down to like 10 cycles per pixel (and that could include the 1/w interpolation too); the only real problem with that being the memory required for the output :-/
A separate loop can then just calculate 1/(1/w) to a table (at something like 16 cycles per pixel), and the final loop can then interpolate all the varying values without having to many any decisions about which are live pixels. Without this kind of split there isn't enough registers to keep everything in registers within the inner loops.
Because of the memory it may have to do all this in several batches - slivers of 64 pixels each or somesuch.
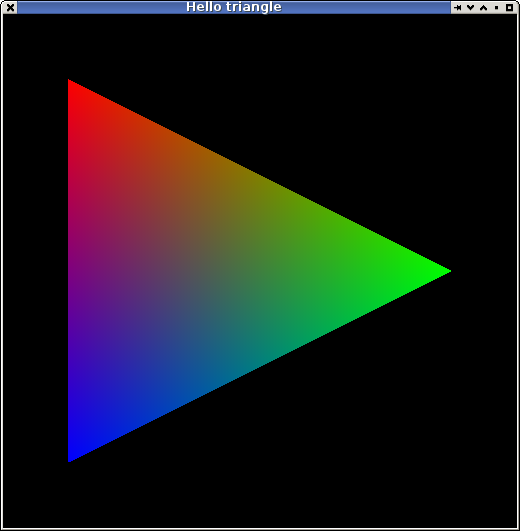
Hello Triangle
But I kinda gave up after today and just worked on a "simple as possible" Java "gpu" to try and have something positive to hang onto after a miserable day (and i started before I got nfs fixed). I needed something which is the distilled/captured knowledge of what I know "so far' as a training simulator. There's still some stuff I need to work out wrt the 3d maths and it's just easier playing with some simple code to do it.
This for example is the code which generates the typical hello world example from OpenGL:
float[] vertices = {
-0.75f, -0.75f, 0, 1,
0.75f, 0, 0, 1,
-0.75f, 0.75f, 0, 1,};
void helloTriangle() {
Viewport vp = new Viewport(0, 0, width, height);
PrimitiveTriangle tt = new PrimitiveTriangle();
tt.setup(vp, 0, vertices);
// red, green, blue
tt.setVarying(0, 1, 0, 0);
tt.setVarying(1, 0, 1, 0);
tt.setVarying(2, 0, 0, 1);
float uniformA = 1.0f;
tt.draw(pbuffer, zbuffer, width, (float[] varying, float[] pixels, int x) -> {
pixels[x + 0] = varying[0];
pixels[x + 1] = varying[1];
pixels[x + 2] = varying[2];
pixels[x + 3] = uniformA;
});
}
This is functionally equivalent to the low-level part of a gpu driver/hardware after the vertex shader (more or less).
Here the lambda expression is the fragment shader. The main problem with using Java as a fragment shader language is how ugly vector/matrix/complex maths ends up being when you need to use flat arrays for efficiency.
Right now this isn't really much more than a training tool and intellectual curiosity, but it's food for thought that computer systems (cpu+gpu+other) and compiler technology is explicitly working toward a point where code such as the above would be the way you "program" graphics drivers. And it would run just as fast as any other driver software. There will probably still be a need for some fixed-function units but these could also be encapsulated as co-processors. The reason this would be possible now when it wasn't previously is due to the technology that makes HSA possible.
A Saturday passes ...
I had a lot of trouble with the matrices and some with the triangle direction - as is usually the case with 3d maths. After playing with some opengl3 tutorials I got it enough worked out to get somewhere. I also played with framebuffer, javafx output, and parallel streams for the tile rendering. Oh and using fixed-point for the triangle edge calculations, which fix some rare edge cases with the edges and might be easier to optimise. And trying to optimise the reciprocal calculation and changing back to the fglrx driver as side-missions (so i could run the gl3 examples - for whatever reason mesa wasn't doing the job, except i forgot which kernel is the one I need to use and the one that mostly works causes some nasty bugs in X). Well you know, a ton of stuff - i lost track of time and suddenly it was 5am.
I should really add some lighting but it's quite mesmerising in full-frame-rate motion all the same. Ok result for a week of late nights piss-farting about.
Still no epiphany code; next perhaps?
lost in dots
Continued to play with software rendering. Ported the code to C and got it running on the framebuffer - still only on the workstation so I don't have any idea how it will run on the parallella.
The Java seems to be faster than the C TBH but that is probably rendering to X verses the framebuffer which is very slow. gcc isn't having the best time of the critical inner loop either. Currently i'm not running any fragment shaders and I have half an idea to just try creating a small soft-3d engine all in java since the jvm can handle some of that. Maybe not.
I thought i'd look at GLES2+ to see how it handles certain things, ... and decided to base some of the API on that because it dictates to a good degree the backend implementation and is based on 20+ years of industry experience. Apart from the shader compilers (which i'm going to side-step entirely) the core components are quite simple. The biggest one from my perspective is the one i've been focusing on so far - the rasteriser and varying interpolator.
I hadn't really thought about how many varyings there need to be, and 8x4 is a good amount. I hadn't got to thinking about uniforms yet either.
I played a bit with code to implement glDrawArrays() which is mostly just data conversion and flattening. My first obvious thought was to select elements from the arrays and turn them into rows (i.e. array of structures) and then batch-process them using the vertex shader. Locality of reference and all that. But after thinking about the inner loop of the rasteriser it will be more efficient to use a structure of arrays approach. It also makes it easier to SIMDise anything that needs to run on the ARM - quite likely the vertex shaders and primitive setup. It makes reading the vertex array data itself much more efficient anyway since each array type is an outer-loop decision rather than an inner-loop one although could have some poor cache behaviour if that isn't taken into consideration.
The potential size of the various data-structures has made me rethink the approach I was going to take. I was going to load as many triangles into the rasteriser as would fit in LDS and process them all at once. But that just wont be enough to be any use so it will have to cycle through them multiple times for different rendering bands. If I drop it down to just a pair of buffers it simplifies the i/o stuff and doesn't make any real difference to the number of times things are read from the external memory.
Due to memory constraints i'm going to have to split the rasteriser+zbuffer test to one or more cores and the fragment rendering to other cores. Each varying interpolator requires 3 floats per element, or 12 floats per 4-element vector. A simple gourad-shaded polygon will require at least 128 bytes to store everything needed (+some control stuff). I was going to pass the uniforms around with the triangle but they are too big so instead I will pass incremental updates to uniform elements in a processing stream, and the rasteriser will make sure the fragment shaders have the updates when necessary as well.
The queueing will be a bit of a pain to get right, but i'm ignoring it for now.
Rasteriser inner loop
Because of the number of varying elements I had to change the way I was thinking of writing the inner loop. I can't keep everything in registers and will need to load the interpolation addends as I go - this is why the data has to be stored as a structure of arrays because it always getting element 0 of a 3-element vector and that's more efficient to load using dword loads.
Also, since fadd is just as costly as fmadd I can remove the incremental update of the coefficients from always having to be executed - i.e. when a z-buffer test fails. It would also allow me to split the work into a couple of passes - one that generates live pixels, and another which turns them into interpolated fragments which could run branchless. I'm not sure if that is worth it yet though since it doesn't remove the branch.
So a single horizontal scan will be something like the following. This is the biggest case.
(v0,v1,v2) = edge equation results for start location
(zw, 1/w) = interpolants for z/w, 1/w
(p0-p31) = interpolants for varying values
(e0,e1,e2) = update values for edges
(ez, ew) = update values for z/w, 1/w
x = start;
lastx = start
start:
in = v0.sign | v1.sign | v2.sign;
if in
zt = load zw-buffer[x]
if (zw > zt) // i think some of my maths is flipped
store zw-buffer[x] = zw
// use delta of X so that 3-instruction fmadd can be used!
xdiff = x - lastx;
lastx = x;
; imagine this is all magically scheduled properly ...
1/w += xdiff * ew
dload ep0-ep1
p0 += xdiff * ep0
p1 += xdiff * ep1
dload ep2-ep3
p2 += xdiff * ep2
p3 += xdiff * ep3
.. etc
write target fragment record
write 1/w
write z/w
// (i don't think i need v0-v3)
write p0-p31
fi
fi
v0 += e0;
v1 += e1;
v2 += e2;
zw += ez;
while !done
I'm still experimenting with ways to work out how 'start' and '!done' are implemented. I've got a bunch of different algorithms although I need to get it on-hardware to get more accurate timing information. The stuff in ATTILA uses a sort of flood-fill algorithm but for various reasons I don't want to use that. I have a pretty reliable way to get both the start and end point of a line using a binary search, ... but its costly if run every line (it's still not perfect either but I think that's down to float being a shit :-/).
My current winner uses a 8x8 search every 8 lines and then uses that as the bounds. And that's even with a broken test which often over-runs (i've subsequently found the maths that work but haven't included it yet).
For small triangles just using the bounding box is pretty much as good as it gets, so may suffice.
Removing the loop branches
Actually it might be possible to have 2 branchless loops ...
(v0,v1,v2) = edge equation results for start location
(zw) = interpolant for z/w,
tmp = room for hit locations
loop1 (over bounds):
in = v0.sign | v1.sign | v2.sign;
zt = read zwbuffer[x]
in &= (zt - zw).sign
zt = cmove(in, zw)
write zwbuffer[x] = zt
tmp[0] = x
tmp = cmove(in, tmp+1)
All branch-free. At the end, tmp points to the end of an array which includes the X values of all visible pixels.
The second loop just interpolates everything for the x locations stored in the tmp array.
lastx = 0
loop2 (over tmp-tmp.start):
load x
increment everything by (x-lastx)
output
lastx = x
As with a previous post about getting good fmadd performance, it should be just about possible to dual-issue every fmadd and remove all stalls. All writes are written directly to the fragment shader core for that row?
Requires working memory for the X coordinates though; but that should be doable since this is all the core will be running.
However, having said all that; the fragment output from a single row can more than exceed the fragment processor memory so they need to be throttled. Back to loops and branches I guess but it was an interesting puzzle.
As one might tell i'm not really that concerned with getting a working solution, more in investigating the ways to fit the peculiarities of the hardware. There's just a lot to write even if i've got a fairly good idea of a workable solution and had all the components necessary :-/
Or maybe ...
Just do everything in a single-loop on the same core?
Yes maybe, hmm, dunno now. Really depends on if there's enough memory for it to fit and whether loading the triangle Nx times vs 1x times is slower than all the comms overheads. Unless the mesh is saturated; I would say no chance.
It's much easier and probably the first step to performance analysis anyway.
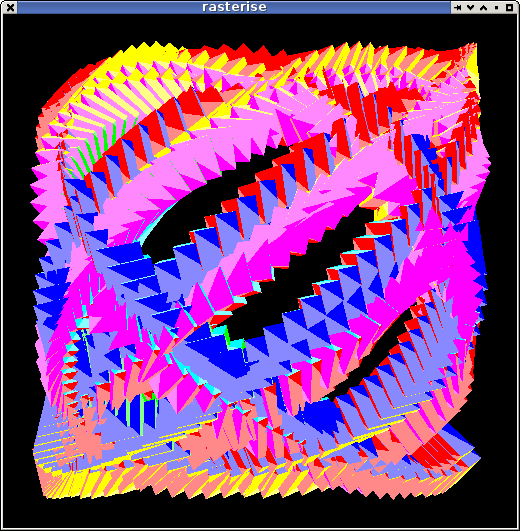
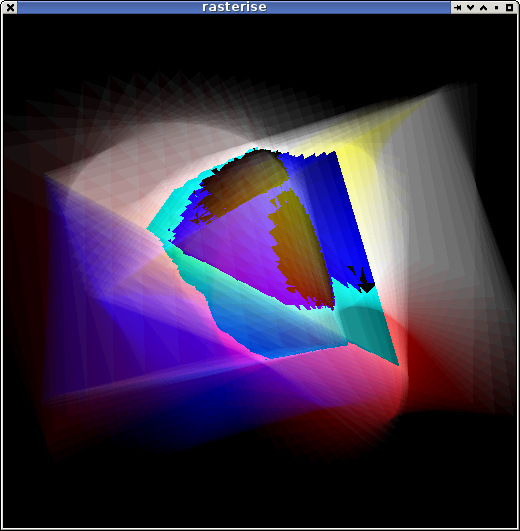
I guess I was more lost in dots than I realised when I made the subject (it was for the pic).
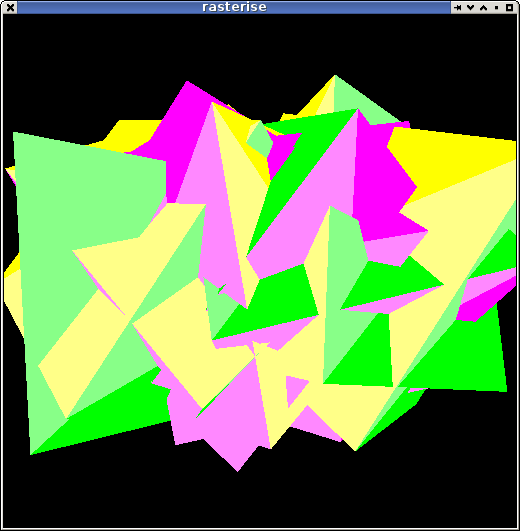
better edges
Been poking more at the renderer. I have a fairly clean set of routines now that can be used to implement most of what I need: generating fragments, interpolating arbitrary parameters, handling a depth test.
And well, just running it and looking at the pretty pictures ...
The Z/W buffer stretched to 8-bit:
Add a few more, use a different 'fragment shader', ... polygonal shade-bobs.
I'm still just running stuff in Java on my workstation but i've been doing a lot of experimenting with micro-optimisations an trying to work out how i'm going to split the work up.
My current idea is to process the scene by complete scan-lines rather than tiles. This greatly simplifies the looping and address arithmetic but would not be very efficient for texture lookups. I'm basing the following on a loose understanding of a gpu pipeline but erring on the side of epu-efficiency.
- The first pass would basically just find out which triangles are live on the current line and determine the triangle leading edge. Walking the triangle edges is surprisingly involved.
- The second pass converts this span into fragments, interpolating z/w, 1/w ,and the triangle parameters/w and performing z-buffer tests. The result of this pass will be sent to an epu for processing. Each parameter requires a single addition per pixel. The data sent to the epu will be the pixel location, each interpolated parameter, and the interpolated 1/w.
- The fragment processor will perform the reciprocal calculation (1/1/w) and convert the parameter/w values to parameter values and invoke the fragment shader. The reciprocal calculation is relatively expensive but by batching up several the cost can be reduced significantly - I have some C code that takes about 12 cycles/reciprocal if 6 care calculated concurrently. Because the fragment processor doesn't have to perform a per-pixel to test so see if the pixel is live it can more efficiently batch this calculation up compared to performing it in the second pass.
- Each fragment processor will process a whole line or some significant portion thereof depending on memory requirements. I'm hoping to use a floating point format which will make blending and a lot of operations essentially time-free but at a cost of 4x the memory. A 1024 element RGBA buffer will require 16K for a forward renderer although i'm going to look into deferred rendering too. It might be possible to defer the texture lookups for example.
I'm not sure where the first and second passes will reside, and for small triangles they will possibly run in the same loop. It may make sense to place some of the decision work on the arm so as to reduce the need for multiple passes over the triangles for each 'run'. In any event several rows will be processed at once since there will be several epus dedicated as fragment/row processors.
It's interesting that due to the FPU and branch latency you're forced to consider SIMD style algorithms for efficiency in a lot of cases. i.e. unrolling loops, branchless logic, re-arranging processing so decisions are taken elsewhere. I'm still juggling the code around to find out what works best on-paper although I should start poking on-board soon.
That better edge test
I'm also surprised at just how little code is required for the inner loop. Only 3 flops and 4 ialu ops (+branch) are required to implement a length-bounded 'inside triangle run' test.
This is an example of scanning right looking for the first set pixel in the triangle.
; v0, v1, v2 = edge equation value (already calculated)
; e0, e1, e1 = edge equation x coefficient
; i = length left
1: and code,v0,v1 ; negative test for v0 & v1
fadd v0,v0,e0
and code,code,v2 ; negative test for v0 & v1 & v2
fadd v1,v1,e1
sub i,i,#1
fadd v2,v2,e2
orr code,code,i ; negative test for i
bgte 1b
5 cycles + branch = 8. Can be unrolled.
This is the equivalent of:
do {
code = (v0 < 0 && v1 < 0 && v2 < 0) || (i < 0));
v0 += e0;
v1 += e1;
v2 += e2;
i -= 1;
} while (code == 0);
Rather than move the negative bit somewhere else as in the previous post I found just leaving them in-place reduces the instruction count. This also lets me combine float and integer comparisons in the same way.
A similar calculation can be used as the exit condition for the fragment generating loop. As each parameter is interpolated using a single addition within the loop it makes for a very simple loop. The only "problem" is that the calculations are so simple that branches become more expensive.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!