About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

Images, Pixels, Java Streams
This morning I wrote and published article about writing an image container class for Java which supports efficient use of Streams. It is on my local home page under Pixels - Java Images, Streams.
Although there is much said of it, there is still quite a bit unsaid about how many wrong-footed experiments it took to accomplish the seemingly obvious final result. The code itself is now (or will be) part of an unpublished library I apparently started writing just over 12 months ago for reasons I can no longer recall. It doesn't have enough guts to make publishing it worthwhile as yet.
I'm also still playing with fft code and toying with some human-computer-interaction ideas.
It was the best of times, it was the worst of times. More fft, more bang for your buck. Same old less bang for your buck.
After posting the result I kept experimenting with the code I `live blogged' about yesterday. I did some linlining but was primarily experimenting with multi-threading. I also looked at a decimation in time algorithm (which i kept fucking up until I got it working today), and a coupe of other things too, as will become apparent.
First a picture of a thousand words.
Now the words.
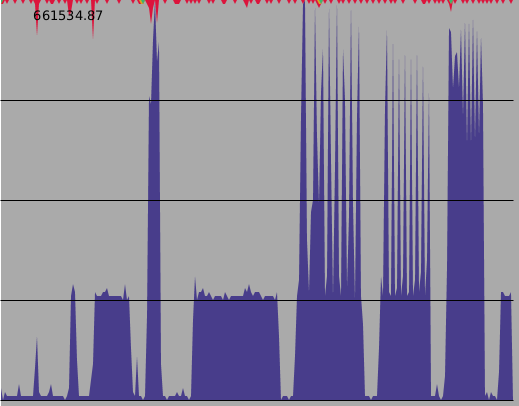
This picture shows the CPU load over time (i'm sure you all know what that is) as I ran a specific set of tests on a test against 8x runs of a 2^24 complex forward transform. The lines represent each core available on this computer. I put some 2s sleep calls between steps to make them distinguishable. Additionally each horizontal pixel represents 250ms which is is about the minimum sampling time which gives usable results.
Refer to earlier posts as to what the names mean.
- The first spike is starting the Java application. Oh boy, look at all that time and resources wasted! Java is the total suxors!!
- The next spike (about 10% utilisation) is initialising my "rot0" implementation. It uses 1 set of Wn exponents per log level of the calculation so has very little setup.
- The 1-load skinny spike is initialising jtransforms. I wonder how it's creating it's tables because it uses a lot of memory for them. It's clearly not using "[sic]Math".cos() for it.
- The 1-load long spike is initialising "table2". Lots of calls to "[sic]Math".sin(), and "[sic]Math".cos().
- The tall skinny spike is initialising the algorithm as discussed yesterday - I made some trivial alterations so it runs multi-threaded.
- There is now a 4 second pause because the next (newer but based on yesterday's code) implementation just uses the tables generated by the previous step and so doesn't register.
That's the setup out of the way, the first 3rd or so of the plot. It's important but not as important as the next bit.
- The long 1-load box is executing rot0 8 times over the data. As expected it takes the longest but fully occupies the CPU it is on while it's running.
- The next haircomb result is from jtransforms. Visually it's only using about 50% of the available cpu cycles above 1 core. The 8 separate transforms executed as part of this benchmark are clearly visible.
- Then comes my the (radix-4 only) implementation from yesterday. Despite it's somewhat trivial multi-threading code it's basically the same; but runs the fastest-so-far.
- Then comes the modified code. A nice solid block and a somewhat shorter execution time. In this case at least 4xthreads are used for all passes including the first. It's still wasting about a core, at least according to my monitor.
- The last spike is just the "rot0" algorithm starting again.
Well that's it I suppose. It utilises more of the available cpu resource and executes in a shorter time. But how was that achieved?
As Deane would say, ``Well Rob, i'm glad you asked''.
It only required a couple of quite simple steps. Firstly I copied the "radix4" routine into the inner loop of "radix4_pass". The jvm compiler wont do this itself without some options and it makes quite a difference of itself. Then I copied this to another "radix6_pass" which takes additional arguments that defines a sub-set of a full transform to calculate. I then just invoke this in parts from 4x separate threads, and keep doing that sort of thing until I hit the "logSplit" point and subsequently proceed as before. It was a quick-and-dirty and could be cleaned up but probably wont add much performance.
It was a bit of mucking about with the addressing logic but once done it's actually a fairly minor change: yet it results in the best performance by far.
At this point i've explored all the isssues and am working on a complete implementation which ties it all together. I think I will write two implementations: one using fully expanded tables for "ultimate performance" and another which calculates the Wn exponents on the fly for "ultimate size". Today I got a DIT algorithm working so I will fill out the API with forward/inverse, pairs-of-real, real-input, perhaps in-order results, and a couple of other useful things to aid convolution performance. Oh and 2D of all that.
But now for a little rant.
Why is software still so fucking shithouse?
So as part of this effort, I ended up having to write my own cpu load monitor. The only one I had available on slackware only has a tiny graph and is mostly just a GUI version of top. The dark slate blue is user time, the grey area is idle, crimson is cpu load, irq is medium sea green and the io wait is golden rod. The kernel doesn't report particularly accurate values in /proc/stat but it sufficed.
But I had intended to annotate this image with some nice 'callouts' and shadowed boxes and whatnot so i wouldn't have to write those 1000 words just to explain what it was showing. However ...
gimp has turned into a "professional photographer editing suite" - i.e. a totally useless piece of junk for most of the planet (and pro photographers wont use it anyway?). So the only other application i had handy was openoffice "dot org" (pretentious twats) draw. I even started to track down the dependencies of inkscape to build that but gtkmm? Yeah ok. But openoffce: Jesus H fucking-A-cunt-of-a-christ, what a load of shit that is. I can't imagine how may millions of dollars that piece of rubbish has cost in terms of developer hours and wasted customer time (aka luser `productivity') but i'm astounded by just how terrible it is. It runs very slow. Has some weird-arse modality/GUI update bullshit going on. Is a total pain to use (in terms of number of mouse clicks required to do the most trivial of operations). And above that it's just buggy as hell. I'd call up the voluminous settings "dialogue" to change a background colour and then it would decide to throw any changes i'd made if i didn't explicitly set it every time.
But it's in good company and about as shit as any `office' software has ever been since the inane marketroid idea to lock users into fucktastic `software ecosystems' was first conceived of. Fuck micro$oft and the fucking hor$e it fucking rode in on.
I was so pissed off I spent the next 4+ hours (till 5am) working on my own structured graphical editor. Ok maybe that's a bit manic and it'll probably go about as far as the last 4 times I did the same thing the last 4 times I also tried using a bit of similar software to accomplish a similar seemingly-simple goal ... but ``like seriously''?
To phrase it in the parlance of our time: what in the actual fuck?
Writing a FFT implementation for Java, in real-time
Just for something a bit different this morning I had an idea to do a record of developing software from the point of view of a "live blog". I was somewhat inspired by a recent video I saw of Media Molecules where they were editing shader routines for their outstandingly impressive new game "Dreams" on a live video stream.
Obviously I didn't quite do that but I did have a hypothesis to test and ended up with a working implementation to test that hypothesis, and recorded the details of the ups and downs as I went.
Did I get a positive or negative answer to my question?
To get the answer to that question and to get an insight into the daily life of one cranky developer, go have a read yourself.
twiddle dweeb twiddle dumb
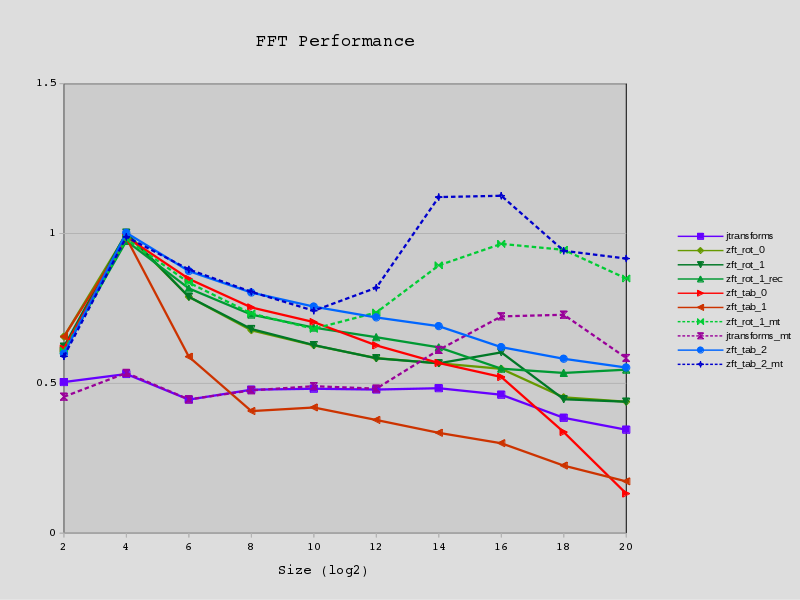
I started writing a decent post with some detail but i'll just post this plot for now.
Ok, some explanation.
I tried to scale the performance by dividing the execution time per transform by N log2 N. I then normalised using a fudge factor so the fastest N=16 is about 1.0.
My first attempt just plotted the relative ratio to jtransforms but that wasn't very useful. It did look a whole lot better though because I used gnuplot, but this time i was lazy and just used openoffice. Pretty terrible tool though, it feels as clumsy as using microsoft junk on microsoft windows 95. Although I had enough pain getting good output from gnuplot via postscript too, but nothing a few calls to netpbm couldn't fix (albeit with it's completely pointless and useless "manual" pages which just redirect you to a web page).
Well, some more on the actual information in the picture:
- As stated above, the execution time of a single whole transform is scaled by N log_2 N and scaled to look about right.
- I run lots of iterations (2^(25 - log N)) in a tight loop and take the best of 3 runs.
- All of mine use the same last two passes, so N=2^2 and N=2^4 are "identical". They are all DIF in-place, out-of-order.
- The '_mt' variants with dashed lines are for multi-threaded transforms; which are obviously at a distinct advantage when measuring executiong time.
- My multi-threading code only kicks in at N > 2^10 ('tab_2' above has a bug and kicks in too early).
- The 'rot' variants don't use any twiddle factor tables - they calculate them on the fly using rotations.
-
'rot_0' is just of academic interest as repeated rotations cause error accumulation for large N.
Wrong again! I haven't done exhaustive tests but an impulse response and linearity test puts it equivalent or very close to every other implementation up to 2^24
- 'rot_1*' compensates with regular resynchronisation with no measurable runtime cost. ^^^ But why bother eh?
- The 'tab' variants use a more 'traditional' lookup table.
- The 'rec' variant (and 'tab_2', 'tab_2_mt', and 'rot_1_mt') use a combined breadth-first/depth-first approach. It's a lot simpler than it sounds.
- I only just wrote 'tab_2' a couple of hours ago so it includes all the knowledge i've gained but hasn't been tuned much.
So it turned out and turns out that the twiddle factors are the primary performance problem and not the data cache. At least up to N=2^20. I should have known this as this was what ffts was addressing (if i recall correctly).
Whilst a single table allows for quick lookup "on paper", in reality it quickly becomes a wildly sparse lookup which murders the data cache. Even attempting to reduce its size has little benefit and too much cost; however 'tab_1' does beat 'tab_0' at the end. While fully pre-calculating the tables looks rather poor "on paper" in practice it leads to the fastest implementation and although it uses more memory it's only about twice a simple table, and around the same size as the data it is processing.
In contrast, the semi-recursive implementation only have a relatively weak bearing on the execution time. This could be due to poor tuning of course.
The rotation implementation adds an extra 18 flops to a calculation of 34 but only has a modest impact on performance so it is presumably offset by a combination of reduced address arithmetic, fewer loads, and otherwise unused flop cycles.
The code is surprisingly simple, I think? There is one very ugly routine for the 2nd to lass pass but even that is merely mandrualic-inlining and not complicated.
Well that's forward, I suppose I have to do inverse now. It's mostly just the same in reverse so the same architecture should work. I already wrote a bunch of DIT code anyway.
And i have some 2D stuff. It runs quite a bit faster than 1D for the same number of numbers (all else being equal) - in contrast to jtransforms. It's not a small amount either, it's like 30% faster. I even tried using it to implement a 1D transform - actually got it working - but even with the same memory access pattern as the 2D code it wasn't as fast as the 1D. Big bummer for a lot of effort.
It was those bloody twiddle factors again.
Update: I just realised that i made a bit of a mistake with the way i've encoded the tables for 'tab0' which has propagated from my first early attempts at writing an fft routine.
Because i started with a simple direct sine+cosine table I just appended extra items to cover the required range when i moved from radix-2 to radix-4. But all this has meant is i have a table which is 3x longer than it needs to be for W^1 and that W^2 and W^3 are sparsely located through it. So apart from adding complexity to the address calculation it leads to poor locality of reference in the inner loop.
It still drops off quite a bit after 2^16 though to just under jtransforms at 2^20.
radix-4 stuff
Well I did some more mucking about with the fft code. Here's some quick results for the radix-4 code.
First the runtime per-transform, in microseconds. I ran approximately 1s worth of a single transfer in a tight loop and took the last of 3 runs. All algorithms executed sequentially in the same run.
16 64 256 1024 4096 16384 65536 262144
jtransforms 0.156 1.146 6.058 27.832 135.844 511.098 3 037.140 14 802.328
dif4 0.160 0.980 5.632 27.503 138.077 681.006 3 759.005 20 044.719
dif4b 0.136 0.797 4.713 22.994 120.915 615.623 3 175.115 17 875.563
dif4b_col 0.143 0.797 4.454 21.835 117.659 593.314 3 020.144 22 341.453
dif4c 0.087 0.675 4.255 21.720 115.550 576.798 2 775.360 15 248.578
dif4bc 0.083 0.616 3.760 19.596 108.028 547.334 2 810.118 16 308.047
dif4bc_col 0.137 0.622 3.699 19.629 107.954 550.483 2 820.234 16 323.797
And the same information presented as a percentage of jtransforms' execution time with my best implementation highlighted.
16 64 256 1024 4096 16384 65536 262144
jtransforms 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0
dif4 102.4 85.5 93.0 98.8 101.6 133.2 123.8 135.4
dif4b 86.7 69.6 77.8 82.6 89.0 120.5 104.5 120.8
dif4b_col 91.3 69.6 73.5 78.5 86.6 116.1 99.4 150.9
dif4c 55.9 58.9 70.2 78.0 85.1 112.9 91.4 103.0
dif4bc 53.3 53.8 62.1 70.4 79.5 107.1 92.5 110.2
dif4bc_col 87.7 54.3 61.1 70.5 79.5 107.7 92.9 110.3
Executed with the default java options.
$ java -version
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build 1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
CPU is kaveri clocked at minimum (1.7Ghz) with only a single DIMM, it is quite slow as you can see.
A summary of the algorithms follow.
- jtransforms
- jtransforms 2.2, complexForward() routine.
- dif4
- A radix-4 implemented as two nested radix-2 operations. 42 flops.
- dif4b
- A radix-4 implemented directly with common subexpressions explicitly encoded. 36 flops.
- dif4b_col
- The first approximately half passes are the same as dif4b, but the second half swap the order of the loop in order to exploit locality of reference, a longer inner loop, and re-using of twiddle factors.
- difc
- The first N-2 passes attempt to re-use twiddle factors across pairs of results situated at (i,N-i). The N-1 pass is hand-coded for the 4 cases which only require 3 constants for the twiddle factors.
- dif4bc
- The first N-2 passes are the same as dif4b. The N-1 pass is hand coded (==dif4c).
- dif4bc_col
- A combination of dif4bc and dif4b_col.
The final (trivial) pass is hand-coded in all cases. dif4 requireds N/2 complex twiddle factors and the rest require N/2+N/4 due to the factorisation used.
In all cases only a forward complex transform which leaves the results unordered (bit-reversed indexed) is implemented.
Thoughts
-
All the implementations do full scans at each pass and so start to slow down above 2^12 elements due to cache thrashing (together with the twiddle table). Depth-first ordering should help in most cases.
-
Despite requiring fewer twiddle lookups in dif4c the extra complexity of the code leads to register spills and slower execution. That it takes a lead at very large numbers is also consistent with this and the point above.
-
Twiddle factor lookups are costly in general but become relatively costlier at larger sizes. This needs to be addressed separately to the general cache problem.
-
Whilst the re-ordering for the "col" variants was a cheap and very simple trick to gain some performance, it can't keep up with the hand-coded variants. Further tuning may help.
-
For addressing calculations sometimes it's better to fully spell out the calculation each time and let the compiler optimise it, but sometimes it isn't.
-
It is almost always a good idea to keep loops as simple as possible. I think this is one reason such a trivial / direct implementation of the FFT beats out a more sophisticated one.
-
There's a pretty clear winner here!
In most cases the calculations are expanded in full inside inner loops, apart from the W^0_N case. In all other cases the compiler generated slower execution if it was modularised, sometimes significantly slow (10%+). I suspect that even the radix-4 kernel is starting to exhaust available registers and scheduling slots together with the java memory model. The code also includes numerous possibly questionable and sometimes a little baffling micro-optimisations. I haven't validated the results yet apart from a test case which "looks wrong" when things go awry but i have reasonable confidence it is functioning correctly.
After I found a decent reference I did start on a radix-8 kernel but i realised why there is so little about writing software to do it; it just doesn't fit on the cpu in a high level language. Even the radix-4 kernel seems to be a very tight fit for java on this cpu.
Still playing ...
java, fft, and jvm
After quite a break i finally got stuck into a bit of hacking over the weekend. Actually i literally spent every waking hour of the weekend tinkering on the keyboard, about 25 hours or so. Yes my arse is a bit sore.
I will probably end up writing more about it but for now I'm just going to summarise some findings and results of some tinkering with FFT routines in Java. It may sound oxymoronic but i've been a bit under the weather so this was something "easy" to play with which doesn't require too much hard thought.
Initially i was working on an out-of-place in-order implementation but I hit some problems with 2D transforms so decided to settle on in-place out-of-order instead. Using a decimation in frequency (DIF) for the forward transform and a decimation in time (DIT) for the inverse allows the same routine to be used for all passes with no bit-reversal needed. I only implemented the basic Cooley-Tukey algorithm and only with radix-2 or radix-4 kernels and with special case code for the first (DIT) or last (DIF) pass. I'm only really interested in "video-image-sized" routines at this point.
I normally use jtransforms (2.4) for (java) fft's so i used that as a performance basis. Whilst the out-of-order results aren't identical they are just as useful for my needs so I think it's fair to compare them. In all cases i'm talking about single-threaded performance and complex input/output (jtransforms.complexForward/complexInverse), and i've only looked at single precision so far.
-
An all radix-2 implementation is about half the speed of jtransforms but takes very little code.
-
A naive radix-4 factorisation (40 flops) is roughly on-par with jtransforms depending on N.
-
A better radix-4 factoriation (34 flops) is 10-30% faster across many sizes of interest.
-
I can beat jtransforms quite handily at 2D transforms even using the naive radix-4 kernel. e.g. ~60% for 102x1024.
This only required creating a somewhat trivial implementation of a column-specific transform. More on this in another post. It will have some pretty pictures. I'm still working on code for it too.
The performance inflexion point (1D) is about 2^14 elements, beyond that jtransforms pulls (well) ahead. I suspect this is related to the cache size and such minutiae is something i just haven't explored.
Some other java/jvm related observations:
-
Single micro-optimisations can make significant (up to 20%) differences to total runtime. Such as:
- Addressing calculations;
- Floating point common subexpression elimination;
- Loop arithmetic;
-
Memory access ordering (due to java memory model and aliasing rules);
- Using final, or copying a field value to a local variable. Why? Maybe the compiler uses these as a registerisation hint?
- And more.
Memory access ordering is particularly difficult to overcome; there is no 'restrict' keyword or even possibility with the java language. Any changes one makes will be quite platform and compiler specific (although microoptimisations in general are to start with).
Nope! Seems i was just a victim of a skinner box. After a check I found there are no relevant rules here and changes i measured were for unrelated internal compiler reasons which are of no practical use. Should've checked before wasting my time.
Floating point arithmetic is also a bit-shit-by-design so expressions can't be freely re-arranged by the compiler for performance (well, depending on how reliable you expect the results to be, i think java aims to be strict). Java currently also has no fused-multiply-add although java-9 has added one. "complex float" would be nice. Although I didn't feel like digging out the disassembler to explore the generated code from hotspot so i'm only guessing as to how it's compiled the code.
- The jvm sometimes "over-optimises" resulting in slower code over time.
I suspect it inlines too much and causes register spills. In some cases I saw 20%+ performance hits although after upgrading to the latest jvm (from u40 to u92) they seem less severe although still present. I used "-XX:CompileCommand=dontinline,*.*" to compare to the default. It showed up as the first-of-3 runs being somewhat faster than subsequent ones, whereas normally it should improve as hotspots are identified. I just thought it was my cpu throttling at first but it continued after i'd locked it.
-
On a shithouse register starved architecture like x86 the jvm overheads limit the complexity of routines. e.g. a (naive) radix-8 kernel ran slower than a radix-4 one due to register spills (it wasn't very good either though).
-
It's very easy to take a "simple" routine and blow it out into a big library of special cases and experiments for that elusive extra single-digit% in performance gained. Actually i've done a lot of this work before but i didn't bother referencing much of it because there is no goal; only a journey.
Of course 'performance java' isn't exactly a hot topic anymore and i should be focusing on massively-parallel devices but I was only doing it to pass the time and I can tackle OpenCL another wet weekend. If I can identify isolated cases for the the optimiser-degredations I came across I will see what the java forums have to say about them.
I've nearly exhausted my interest for now but i still have a couple more things to try and also to identify what if any of it I want to keep. If I get really keen I will see about some sort of reusable library for special purpose fft use - one problem with jtransforms (and indeed other fft libraries) is that you need to marshal the data into/from the correct layout which can be quite costly and negate much of the performance they purport to provide. Big if on that though.
my lonesome easter
I made some chocolate cakes.
They have 2 fresh Habanero chillies in them, so they're quite potent. I also undercooked them a bit but they can be salvaged with a few minutes in a toaster oven. As I have no one to eat them with i did a half-batch and froze most of them.
I also had a 3k pork forequarter that had been in the freezer a bit too long so I took that out and spent a couple of days cooking different things with it.
Sliced some up with some skin on, marinated them in something jerk-ish, and put them in the vertical grill; basically spare ribs. I used the marinade again on a the hock overnight and then long-roasted that the next day. Got a few nice sandwiches out of that.
Baked some bread for said sandwiches; well bread-maker baked. I throw in some Bulgar wheat and linseed to make it a bit more interesting.
Diced a lean cut and made a masaman curry with it; I had intended to make a green curry but the shops were closed and that's all I had. I froze most of that because I had too much other food. It could've been better but it's ok.
Then I took the meaty bones and a bunch of other bones i'd been keeping for the purpose and pressure cooked the lot for 2.5 hours. I sloughed the meat off the bones, added lots of chillies, some tomatoes, garlic, spices, soup powders, stock powders, soy sauce, fish sauce, lemon basil; and made a super-spicy pork soup out of it.
It's super-hot! And very fatty so to be consumed in small amounts. I made the noodles for this bowl too of course. Because the mixer bowl was occupied I first tried making the noodles by hand but failed miserably; didn't add enough water, but then I freed up the mixer bowl and finished the job.
The mixer bowl was busy because I also made some hot-cross buns and the dough was still rising.
Without the xtian symbology of course. The recipe I had seemed to have far too little water so I added more but the resultant texture doesn't seem quite right. I think i overcooked them a bit and maybe let them rise a bit too long as it's a bit light and dry inside but the holes are small and evenly distributed. I also added much more spice, a little golden syrup and chocolate pieces as well.
I have these strange chilli plants I got seeds from mum and I was curious as to which variety they were. This morning I did some searching and found out; Aji Orchid, aka Peri Peri, Bishops Crown, or many other common names.
I've got quite a few of these growing and as they are cross pollinated seeds they are all a bit different - shapes vary quite a bit and so does their heat from almost nothing to enough to notice. They are tall thin plants. A couple of the bushes I have are over 6' high now and still seem to be growing upwards. But I've had a lot of problem with Eggfruit Caterpillars (my best guess) this year, so much so that i've not managed to get any ripe fruit yet; well and I keep eating them before they get that far.
Anyway I still had a day to burn through so I looked into pickling some. I found a reference on pickling brine concentrations (beyond 'add salt'), found a lid that fit a lidless jar I had and made an airlock out of an empty pill bottle I suddenly have lots of. Then picked some chillies and cut them up.
I waited to see how much water would come out on it's own - as I expected not much at all so I topped it up with 500ml of 7.5% brine and inserted a jar to keep them submerged, sealed it up and put it in the cupboard to be forgotten about for a while to let them ferment in peace.
I then got out in the garden and did a rush job setting up some furrows and seeding some wintery things in one garden bed. I planted some snow peas but the rest was a medley of seeds I just threw around; bugs always seem to eat my winter vegetables so it's not worth the effort but who knows it might work this time. I think I used broccoli, chinese cabbage, brussel sprouts, and lettuce.
And then I dug a big hole and moved a lime tree from a half-wine-barrel into the ground. I was surprised at how much the roots had filled the whole barrel but otoh it didn't seem root bound either. Once it was out of the pot I managed to lift the whole thing in and out of the hole so despite watering regularly the dirt wasn't holding any of it but I knew that anyway from the state of growth and lack of fruit. I'm sure my back will be a bit sore tomorrow.
Over the last 4 days I also played a good many hours of Bloodborne and other games. I'm stuck again in Bloodborne - Micolash, Martyr Logarius, or Lower Pthumeru Chalice (Rom again). I'm starting to get a bit sick of grinding (i'm level 105 or something) because i'm just too slow in reactions to be able to get through some parts without it. I'm about 100 hours in anyway which is pretty much my limit with any long game. Maybe i'll keep playing.
I also played some DRIVECLUB in memorial of Evolution Studios being shut down. Why a game of such high quality and depth didn't sell well is beyond me but it's a bit of a bummer and hopefully they can find a way to make more driving games in the future as they have always made really special games.
RIP Evolution, the next beer I have is for you guys.
I nipped out to the shops on Saturday morning but otherwise haven't seen another soul since Thursday evening. I had no visitors, nobody called, the friends I might visit are all away for the weekend. At least I got a couple of emails but none from 'regular' friends.
It's all just so pointless isn't it?
unkown unknowns
If I quit my job, what will I do instead?
Pity I can't afford to retire fully although given no male in my family has reached 60 yet that might not be true either! Probably should be though as two of those were somewhat self-inflicted and dad was cancer in the 80s.
But I can afford to quit this one if I choose to.
For a start it's been around 10 years which is much longer than i've had any other job for and whilst it's been often challenging and engaging there is always the fair share of frustration and baggage built up over such a span of time. For instance i've had years of work stuck in locked drawers unused. Stuff that should have been published, stuff that may even be published yet. It's even in an industry I don't particularly want to be a part of (not that I can think of any I do want to be part of!). On-top of all this there have been a good few years of very odd circumstances which only came to a head around xmas last year. Circumstances that while discussing with peers in hindsight appear to border on abuse. It was only though incidental rather than malicious intent but the cause doesn't affect the outcome. It's been raised and addressed but it feels too little too late since too much damage has been done that just can't be undone. Actually the initial reaction to the insight i've gained about the workplace itself in the last few weeks is that the whole joint is a complete fuckup and is a big reason i'm thinking of leaving sooner rather than later.
One other particular thing of note that crossed my mind over the last couple of days whilst reflecting on the whole period is that i've made absolutely no new friends during it - not a single one. And I don't just mean "real proper" friends you keep in touch with decades later which can be rare - I've had absolutely no social interaction with anybody outside of being at work itself (or lunch) or the annual xmas party. And the xmas party is mostly contractors i've never worked with. It's not entirely without reasons, to start with there just wasn't that many I did work with, and most people already have their lives done at this age. But it still does seem a little odd in hindsight given i've generally gotten on quite well with most of them and all the time involved.
Despite all this I've usually felt it was adequately compensated with lower and flexible work hours, an almost completely free reign in technology and implementation choices, and extended amounts of summer leave (even if it was usually due to funding shortages). But even these - as absolutely awesomely awesome as they are to me - have their limit of worth.
So I haven't decided yet.
One reason is of course what happens next. I don't really feel like i'm capable of much at all right now (look at the dearth of hacking on this blog for evidence) but that might be more perception than reality and it could change in the blink of an eye. I can however afford to take plenty of time to get my shit together if I need to (decades actually). Another is that I've never had to actually look for any job i've ever had and i'm generally pretty hung up about doing such things for the first time, yeah still. Due to working for Ximian/Novell and now these guys I don't have much of a local 'network', although it's not empty either. And my skills and interests are (probably?) not in much demand around this sleepy city outside of where I am now. Well obviously with my skills and experience I can code almost anything for almost anything (or quickly learn how to) but there's a lot of rather unappealing anythings out there that get coded and there's often some really poor technology taking up the flavour-of-the-month pedestal at any given time as icing on the cake.
If I decide in the positive will I manage to last out the remaining money for this year? Professionally one would think there is no question but personally once a decision like this has been made it will be hard to continue. I'm just a casual employee (no notice needed) and this is not an entirely professional matter I think. Another 3 months? Hmm.
I'll think about it some more I guess.
update: Told 'em. Well, we'll see. They don't want to let me go. I mean really not. I guess i'm worth something.
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!