About Me
Michael Zucchi
B.E. (Comp. Sys. Eng.)
also known as Zed
to his mates & enemies!
< notzed at gmail >
< fosstodon.org/@notzed >

lost in dots
Continued to play with software rendering. Ported the code to C and got it running on the framebuffer - still only on the workstation so I don't have any idea how it will run on the parallella.
The Java seems to be faster than the C TBH but that is probably rendering to X verses the framebuffer which is very slow. gcc isn't having the best time of the critical inner loop either. Currently i'm not running any fragment shaders and I have half an idea to just try creating a small soft-3d engine all in java since the jvm can handle some of that. Maybe not.
I thought i'd look at GLES2+ to see how it handles certain things, ... and decided to base some of the API on that because it dictates to a good degree the backend implementation and is based on 20+ years of industry experience. Apart from the shader compilers (which i'm going to side-step entirely) the core components are quite simple. The biggest one from my perspective is the one i've been focusing on so far - the rasteriser and varying interpolator.
I hadn't really thought about how many varyings there need to be, and 8x4 is a good amount. I hadn't got to thinking about uniforms yet either.
I played a bit with code to implement glDrawArrays() which is mostly just data conversion and flattening. My first obvious thought was to select elements from the arrays and turn them into rows (i.e. array of structures) and then batch-process them using the vertex shader. Locality of reference and all that. But after thinking about the inner loop of the rasteriser it will be more efficient to use a structure of arrays approach. It also makes it easier to SIMDise anything that needs to run on the ARM - quite likely the vertex shaders and primitive setup. It makes reading the vertex array data itself much more efficient anyway since each array type is an outer-loop decision rather than an inner-loop one although could have some poor cache behaviour if that isn't taken into consideration.
The potential size of the various data-structures has made me rethink the approach I was going to take. I was going to load as many triangles into the rasteriser as would fit in LDS and process them all at once. But that just wont be enough to be any use so it will have to cycle through them multiple times for different rendering bands. If I drop it down to just a pair of buffers it simplifies the i/o stuff and doesn't make any real difference to the number of times things are read from the external memory.
Due to memory constraints i'm going to have to split the rasteriser+zbuffer test to one or more cores and the fragment rendering to other cores. Each varying interpolator requires 3 floats per element, or 12 floats per 4-element vector. A simple gourad-shaded polygon will require at least 128 bytes to store everything needed (+some control stuff). I was going to pass the uniforms around with the triangle but they are too big so instead I will pass incremental updates to uniform elements in a processing stream, and the rasteriser will make sure the fragment shaders have the updates when necessary as well.
The queueing will be a bit of a pain to get right, but i'm ignoring it for now.
Rasteriser inner loop
Because of the number of varying elements I had to change the way I was thinking of writing the inner loop. I can't keep everything in registers and will need to load the interpolation addends as I go - this is why the data has to be stored as a structure of arrays because it always getting element 0 of a 3-element vector and that's more efficient to load using dword loads.
Also, since fadd is just as costly as fmadd I can remove the incremental update of the coefficients from always having to be executed - i.e. when a z-buffer test fails. It would also allow me to split the work into a couple of passes - one that generates live pixels, and another which turns them into interpolated fragments which could run branchless. I'm not sure if that is worth it yet though since it doesn't remove the branch.
So a single horizontal scan will be something like the following. This is the biggest case.
(v0,v1,v2) = edge equation results for start location
(zw, 1/w) = interpolants for z/w, 1/w
(p0-p31) = interpolants for varying values
(e0,e1,e2) = update values for edges
(ez, ew) = update values for z/w, 1/w
x = start;
lastx = start
start:
in = v0.sign | v1.sign | v2.sign;
if in
zt = load zw-buffer[x]
if (zw > zt) // i think some of my maths is flipped
store zw-buffer[x] = zw
// use delta of X so that 3-instruction fmadd can be used!
xdiff = x - lastx;
lastx = x;
; imagine this is all magically scheduled properly ...
1/w += xdiff * ew
dload ep0-ep1
p0 += xdiff * ep0
p1 += xdiff * ep1
dload ep2-ep3
p2 += xdiff * ep2
p3 += xdiff * ep3
.. etc
write target fragment record
write 1/w
write z/w
// (i don't think i need v0-v3)
write p0-p31
fi
fi
v0 += e0;
v1 += e1;
v2 += e2;
zw += ez;
while !done
I'm still experimenting with ways to work out how 'start' and '!done' are implemented. I've got a bunch of different algorithms although I need to get it on-hardware to get more accurate timing information. The stuff in ATTILA uses a sort of flood-fill algorithm but for various reasons I don't want to use that. I have a pretty reliable way to get both the start and end point of a line using a binary search, ... but its costly if run every line (it's still not perfect either but I think that's down to float being a shit :-/).
My current winner uses a 8x8 search every 8 lines and then uses that as the bounds. And that's even with a broken test which often over-runs (i've subsequently found the maths that work but haven't included it yet).
For small triangles just using the bounding box is pretty much as good as it gets, so may suffice.
Removing the loop branches
Actually it might be possible to have 2 branchless loops ...
(v0,v1,v2) = edge equation results for start location
(zw) = interpolant for z/w,
tmp = room for hit locations
loop1 (over bounds):
in = v0.sign | v1.sign | v2.sign;
zt = read zwbuffer[x]
in &= (zt - zw).sign
zt = cmove(in, zw)
write zwbuffer[x] = zt
tmp[0] = x
tmp = cmove(in, tmp+1)
All branch-free. At the end, tmp points to the end of an array which includes the X values of all visible pixels.
The second loop just interpolates everything for the x locations stored in the tmp array.
lastx = 0
loop2 (over tmp-tmp.start):
load x
increment everything by (x-lastx)
output
lastx = x
As with a previous post about getting good fmadd performance, it should be just about possible to dual-issue every fmadd and remove all stalls. All writes are written directly to the fragment shader core for that row?
Requires working memory for the X coordinates though; but that should be doable since this is all the core will be running.
However, having said all that; the fragment output from a single row can more than exceed the fragment processor memory so they need to be throttled. Back to loops and branches I guess but it was an interesting puzzle.
As one might tell i'm not really that concerned with getting a working solution, more in investigating the ways to fit the peculiarities of the hardware. There's just a lot to write even if i've got a fairly good idea of a workable solution and had all the components necessary :-/
Or maybe ...
Just do everything in a single-loop on the same core?
Yes maybe, hmm, dunno now. Really depends on if there's enough memory for it to fit and whether loading the triangle Nx times vs 1x times is slower than all the comms overheads. Unless the mesh is saturated; I would say no chance.
It's much easier and probably the first step to performance analysis anyway.
I guess I was more lost in dots than I realised when I made the subject (it was for the pic).
better edges
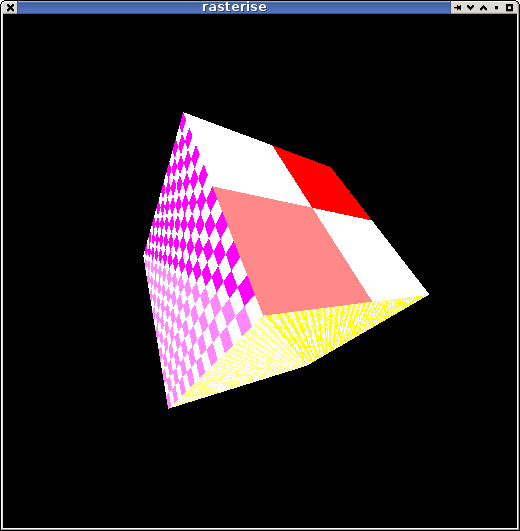
Been poking more at the renderer. I have a fairly clean set of routines now that can be used to implement most of what I need: generating fragments, interpolating arbitrary parameters, handling a depth test.
And well, just running it and looking at the pretty pictures ...
The Z/W buffer stretched to 8-bit:
Add a few more, use a different 'fragment shader', ... polygonal shade-bobs.
I'm still just running stuff in Java on my workstation but i've been doing a lot of experimenting with micro-optimisations an trying to work out how i'm going to split the work up.
My current idea is to process the scene by complete scan-lines rather than tiles. This greatly simplifies the looping and address arithmetic but would not be very efficient for texture lookups. I'm basing the following on a loose understanding of a gpu pipeline but erring on the side of epu-efficiency.
- The first pass would basically just find out which triangles are live on the current line and determine the triangle leading edge. Walking the triangle edges is surprisingly involved.
- The second pass converts this span into fragments, interpolating z/w, 1/w ,and the triangle parameters/w and performing z-buffer tests. The result of this pass will be sent to an epu for processing. Each parameter requires a single addition per pixel. The data sent to the epu will be the pixel location, each interpolated parameter, and the interpolated 1/w.
- The fragment processor will perform the reciprocal calculation (1/1/w) and convert the parameter/w values to parameter values and invoke the fragment shader. The reciprocal calculation is relatively expensive but by batching up several the cost can be reduced significantly - I have some C code that takes about 12 cycles/reciprocal if 6 care calculated concurrently. Because the fragment processor doesn't have to perform a per-pixel to test so see if the pixel is live it can more efficiently batch this calculation up compared to performing it in the second pass.
- Each fragment processor will process a whole line or some significant portion thereof depending on memory requirements. I'm hoping to use a floating point format which will make blending and a lot of operations essentially time-free but at a cost of 4x the memory. A 1024 element RGBA buffer will require 16K for a forward renderer although i'm going to look into deferred rendering too. It might be possible to defer the texture lookups for example.
I'm not sure where the first and second passes will reside, and for small triangles they will possibly run in the same loop. It may make sense to place some of the decision work on the arm so as to reduce the need for multiple passes over the triangles for each 'run'. In any event several rows will be processed at once since there will be several epus dedicated as fragment/row processors.
It's interesting that due to the FPU and branch latency you're forced to consider SIMD style algorithms for efficiency in a lot of cases. i.e. unrolling loops, branchless logic, re-arranging processing so decisions are taken elsewhere. I'm still juggling the code around to find out what works best on-paper although I should start poking on-board soon.
That better edge test
I'm also surprised at just how little code is required for the inner loop. Only 3 flops and 4 ialu ops (+branch) are required to implement a length-bounded 'inside triangle run' test.
This is an example of scanning right looking for the first set pixel in the triangle.
; v0, v1, v2 = edge equation value (already calculated)
; e0, e1, e1 = edge equation x coefficient
; i = length left
1: and code,v0,v1 ; negative test for v0 & v1
fadd v0,v0,e0
and code,code,v2 ; negative test for v0 & v1 & v2
fadd v1,v1,e1
sub i,i,#1
fadd v2,v2,e2
orr code,code,i ; negative test for i
bgte 1b
5 cycles + branch = 8. Can be unrolled.
This is the equivalent of:
do {
code = (v0 < 0 && v1 < 0 && v2 < 0) || (i < 0));
v0 += e0;
v1 += e1;
v2 += e2;
i -= 1;
} while (code == 0);
Rather than move the negative bit somewhere else as in the previous post I found just leaving them in-place reduces the instruction count. This also lets me combine float and integer comparisons in the same way.
A similar calculation can be used as the exit condition for the fragment generating loop. As each parameter is interpolated using a single addition within the loop it makes for a very simple loop. The only "problem" is that the calculations are so simple that branches become more expensive.
edges
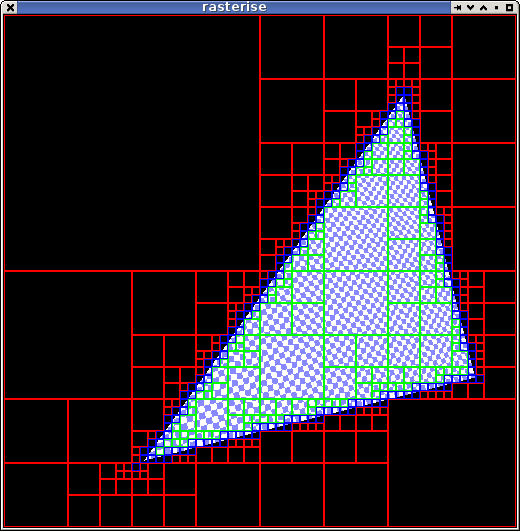
Just been playing with edge equations this morning.
Here it's recursively determining the fill area of the triangle, red is no content, green is all fill, blue is partial fill. Dunno how useful it is in this form but it looks nifty.
If the 3 edge equation results for each corner of a tile are turned into bits then the equations for each case are simple bit logic.
int ec0 = edgeCode(e, x0, y0);
int ec1 = edgeCode(e, x0 + tsize, y0);
int ec2 = edgeCode(e, x0, y0 + tsize);
int ec3 = edgeCode(e, x0 + tsize, y0 + tsize);
int and = ec0 & ec1 & ec2 & ec3;
int orr = ec0 | ec1 | ec2 | ec3;
all_filled = and == 7;
all_empty = orr != 7;
Rather than rely on floating point compare (aka subtract) which adds further latency to the calculation and thus cannot be directly pipelined, I form form the edgeCode directly using integer arithmetic.
public static int edgeCode(float[] e, float x, float y) {
float v0 = x * e[0] + y * e[1] + e[2];
float v1 = x * e[3] + y * e[4] + e[5];
float v2 = x * e[6] + y * e[7] + e[8];
int c0 = Float.floatToRawIntBits(v0);
int c1 = Float.floatToRawIntBits(v1);
int c2 = Float.floatToRawIntBits(v2);
return (c0 >>> 31) | ((c1 >>> 31) << 1) | ((c2 >>> 31) << 2);
}
(>>> is a LSR op in Java).
Since epiphany (and most decent ISAs) share float and int registers the above is going to translate directly into clean machine code. This stuff might need to live on the ARM too and is SIMDable.
Actually there's a bunch of optimisations possible that reduce that instruction count and if using power-of two tile sizes and fixed-point arithmetic everything can be reduced to simple integer addition; but I haven't explored that yet.
Obviously this is working toward toward one important requirement: the renderer will have to tile to take advantage of the LDS, and it also needs pipelineable/simdable algorithms. But that's enough for this weekend, things to do ...
rasterise
After thinking about the old C64 and Amiga games I thought i'd look into something I used to play with back then but haven't really touched properly in a long time: 'vector gfx'.
Since the parallella doesn't have a gpu it leaves it to software.
I looked into how hardware does it presently and it seems to be down to the technique described in Triangle Scan Conversion using 2D Homogeneous Coordinates so that's what I looked at. I got a basic 2d half-space triangle rasteriser going quickly but wanted a quicker solution for something more capable (and I couldn't find some of the references on the net) so did a hunt and came across the ATTILA project which has all the bits needed. I've only done a cursory scan for what i was interested in right now but I expect i'll becoming quite acquainted with it should i continue working on this for any time.
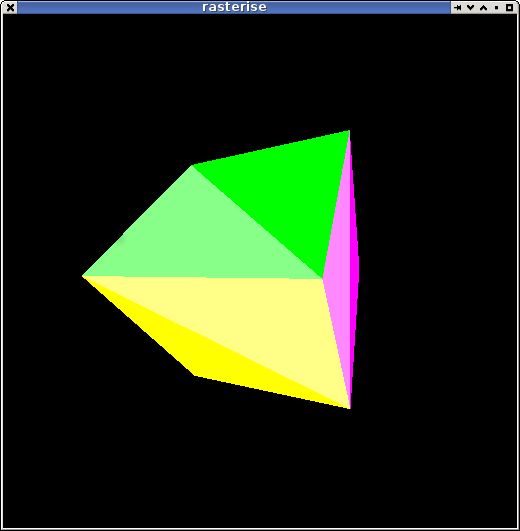
I extracted some of the low-level bits from it, set up some vertex handling and matrix code and ended up with a very basic solid-colour rasteriser for a 'hello cube' demo:
Definitely not going to break any speed records but it does run at full-frame rate on this pc even if it's only flat shaded. (it's java+javafx on a kaveri pc).
Getting this stuff working on the epiphany will be ... well interesting I guess.
Ahah, I just sussed out the parameter interpolation, an important bit I needed before looking at epiphany code.
Destiny is no Mercenary.
'cause i had a spare arvo and not much to do I downloaded the "Destiny" beta since it was 'opened' for the weekend. Its probably not a game I was going to get anyway but I thought i'd have a look. I find the way they've implemented the multiplayer interesting; even if it isn't something I want to do myself.
While it was downloading I got my other parallella working - which took a good chunk of the afternoon because it took me a while to discover that the sd-card wasn't actually in a ready-state. I didn't check it to start with because the only machine i have with a sdhc card slot has a dying fan so i've put it away. So i had to dig it out, download the images, copy them across, write them a few times because they weren't working, ... whilst trying to stop the laptop overheating (although the fan righted itself enough in the end). Well it booted and a usb keyboard worked but I didn't want to get out a hub so I logged on via ssh, fixed the shell (tcsh, tcsh, no no!) and shut it down to await another day.
Back to Destiny. As one would expect from a game with so much money spent on it, it's pretty polished in the game part - apart from the super-chunky shadow maps on the PS3 and the lack of the ability to properly invert the controls (who the fuck would want to only invert y and not x too??). Well the game bits are polished, the story seems a bit corny and just just badly acted - but it is just the beta so one shouldn't expect much. The hub seems too much like a "mall" in Playstation Home though; they just need some chess tables and a bowling alley.
I didn't get far before basically not being able to progress due to being shit at the game (with no help from the fucking camera controls) and so kinda gave up. Actually i'd been doing ok by being cautious and methodical but was overwhelmed by a specific situation which seems designed to force you to team up with other players. But i'm just not in a sociable mood so I just went back outside and wandered around jumping off cliffs to misadventurous[sic] deaths and taking pot shots of baddies and drones until other players started showing up in number. Since I didn't really want to socialise I quit back to tv.
Actually apart from the camera controls the most annoying thing was the menu's - they're all operated with a joystick-driven mouse pointer 'big dot', which sucks as much as it sounds. Just use the bloody direction buttons, it's a lot easier/faster. The music did nothing for me either; a bit too nicey softly-epic. Too Spielberg.
Playing it got me thinking about Mercenary: Escape from Targ. Or at least, wishing there was a game more like that instead.
Crash land on a planet, half way between two separate races/groups who are at war, you play them off each other and earn enough money to buy a ship to leave (or trade your way to find one, iirc there were multiple ways to escape). I think there was one gun, a few ground-cars, a couple of planes (which you could crash and destroy; basically ending the game unless you wanted to walk for hours) and a couple of space-capable ships. Teleports, lifts, an underground multi-room complex or two, and i think a space station (this is really stretching my memory so i could be out). One item which most ties in with Destiny specifically is the "9th generation (pocket?) pc" you have which constantly talks you through the game; acting as a guide, translator, atm, companion.
All whilst walking (and/or flying) around in 1st person perspective "3d".
Released in 1985. You know, back when 1st person 3d games just didn't exist.
Obviously graphically crude by today's standards and probably not something I would have the patience to play in its original form of 160x200-odd pixel playfield in 4-colours-at-once glory at 3-4 frames per second (if that), and even then the 'objects' were so far apart you could only see one at a time (one building, or a couple of trees). But I finished it at least once (maybe twice) and the story made a hell of a lot more sense than some of the stuff coming out these days even if i didn't realise it even had one at the time.
The story in Titanfall for example: completely barmey, you have giant space-based factories generating 'super-robots' with papier-mâché-like fragility which are delivered from space to a tiny battle arena so that drugged-up flying super-soldiers can shoot them to bits with pop guns. Why not just blow up the space-factory? Why not just drop big fucking bombs instead? The whole economics of the story as a war doesn't make any sense whatsoever. (I haven't played it, not likely to ever). As a multiplayer game at least, it just seems to be Brockian Ultra Cricket with mechs, but with a nonsense backstory that makes even less sense than if that's what it was really called.
Destiny at least has some basic coherence to the story on the surface (and sci-fi enough to be given some lee-way). But what the fuck are all the people in that giant city doing? Playing houses and looking at the sunset whilst these alien invaders come to wipe them out from existence? Cities are literally giant factories for making shit: they'd be pumping out war machines for their defense, not relying on a rag-tag group of ?resurrected? Boba Fett's roaming the wild-lands and salvaging incrementally-better shit from a planet full of wasted junk.
I guess the problem is these types of games are designed to never end so they need some artificial hook to keep people coming back. And the story has to be bent to breaking point around these mechanics. Traditional RPGs get away with it because you are meant to be a neophyte random traveller wandering around killing shit and learning your trade, not one of 'many'
man's 'only' hope against utter annihilation
.
Maybe No Man's Sky will capture the essence of games like Mercenary. It certainly sounds like it might so far although some of the details are a bit thin on the ground. Actually i'm sure nothing probably ever will be because nothing will ever be the same as when I played it; mostly me.
I didn't really know much about it until watching that excellent video and endearing presentation on Sony's stage at E3. I think Gamespot did a series of very good background stories on it as well. I've dabbled in some extremely simple procedural world ideas but never got anywhere - the thought you could create a whole galaxy of realistic if 30s sci-fi inspired solar systems and planets complete with atmospheres, fauna and flora, and motion thereof - all from a deterministic seeded algorithm, ... and in real-time. Mind-blowing.
The scale is really what is amazing here. As the good books says, space is big, really big ... there would be no way to create a game of this size and detail any other way; it would never fit on a disk and couldn't be downloaded. It could only ever be created dynamically/procedurally, and it could never be done in such fidelity without the memory and processing power of modern computers. The easiest way I can think of visualising how they've done it is by looking at the set of julia sets: very simple rules create it, a given location always looks the same, but there is also infinite detail and an infinite number of sets. A similar multi-dimensional number surface must be driving the physical rules which are then used to create the worlds. It's not random - otherwise you'd end up with blended pea soup colour palettes and flying ratchet screwdrivers. In fact nothing can be random otherwise it couldn't possibly work. Bummer about the ratchet screwdrivers ... although there's always the possibility of easter eggs.
I really hope they can pull it off; even if i don't get into it as a game or the rest of the game doesn't reach the same bar; the technology shown so far is phenomenal and has incredible possibilities for the future. I guess I might have to get PS4 for it if driveclub hasn't done that already by then - that looks an absolute corker and I loved their WRC games (motorstorms were good too but the WRC games had a certain feel that was missing).
Actually this also reminds me of another C64 game. The Sentinel. It had 10 000 levels in a single tape load. And must have been procedurally generated, in '86. There's another game ripe for a remake. I never played it much or got very far when I did but when that scanner went static it was scary as hell - it took so long to rotate you didn't have room for mistakes.
ext4 ... data loss, what? why?
Somehow this passed me by over the years because I never liked ext3 either and avoided it but boy is ext4 shit. Apparently it wont flush anything to disk unless f(data)sync() is called which means on a system that I crash as much as the parallella i'm often left with empty files all over the place - from a compile i ran 20 minutes ago. Fortunately emacs must be calling fsync and so i haven't lost any "real work". Running "sync" often takes ages too since it's decided to leave all the writes since boot-up lying around in ram.
Despite any arguments to the contrary it's pretty obvious why ext4 was broken in this way: blah blah ... benchmarks look better ... blah blah.
I just can't believe the distro "community" or any sysadmin actually puts up with this sort of nonsense given there are so many other (excellent, stable) filesystems to choose from. For a so-called meritorious-based "community" this reeks of the same type of following the "industry default" that lead to the disastrous wintel-fucked-over lost-decade of the 90s.
Come on, it's just shit, use something else. There's no excuse. And rather than focusing on benchmarks, isn't it about time the filesystem writers focussed on robustness? I mean come on, why the fuck do I still have to unmount a removable disk before taking it out? That's some other fucked-up-shit that was introduced in the 90s.
I got sick of it so a few weeks ago I changed to developing on the parallella via a nfs disk. Since the TOD clock on my rev0 board is out of whack since changing to the rev1 distro (drifts about 1s per minute) i'm usually editing and compiling on my workstation as well; which makes everything quicker and easier as a bonus. I have a rev1.1 board but haven't tried it yet because the rev0 is working well enough for what i'm doing and my desk is a bit cramped (hmm, but should do a burn-in test soon).
I was looking into a NAS box to just centralise all the "bulk" filesystems of all my computers but couldn't decide on one to buy and then thought that since they were probably running gnu/linux anyway I could at least see if it would be workable (it is). I probably don't even need that magnitude of space anyway: I had another workstation just running to record tv using mythtv for the last few years - but I stopped watching any of it months ago and last time the power went out during a storm I just left it turned off (mysql is another piece of shit so it usually requires some massaging to work after a reboot too, so i saved myself some hassles). It wasn't the original goal/use of the machine it's just that it's in a poor location and then I got other computers.
I did get a usb drive instead, which was probably a bit pointless in hindsight and it's just sitting on the other one I barely use, collecting copious amounts of dust infront of the telly. It seemed like a good idea at the time; I guess i'll get a nas box one day although not for archiving movies or tv series i'm just not going to end up watching.
Commercial TV here is almost unwatchable now with a recording and even with a recording it's a hassle skipping through the ads - there is almost more ads than tv and it's often the same annoying ones over and over again. I'm barely watching the footy this year either - which is normally something to have in the background at least during a wintry weekend: when channel 7's "a-team" are commentating it's just too hard to watch with the sound on at all - fuck fuck bruce macevaney[sic] and all his fucking inane and repetitive one-liners - and i've had more than enough of bunnings "team members" telling me about their shitty cheap imported junk every time a goal gets kicked. And since channel 7 bought the SANFL rights they barely show any games - ABC at least had one match of the week every week, with no fucking ads (actually 7 are showing less national games too, pushing people to their paytv stuff). Most of the rest of the "content" is pretty crap anyway (dumbed down way too much, and/or based on idiotic premises), or repeated to overload. Lately the thing on commercial tv seems to be to show a series as fast as possible by showing 2 or 3 (or more) back to back, once a week until they're all shown. Must be some marketing junk about 'captive' audience but I can't see that working for long if they then repeat the same short series every 6 months and when tv's come with video recorders built in.
I guess on the plus side ... it means i've been doing a lot more hacking.
It's my weekly RDO today, not sure what to do. Should get a quote for solar hot-water or new stove-top or a good number of other things to do around the house but, well, I just don't want to deal with it. Too cold to do much outside - i think the storms have cleared up but a full day of still grey overcast sucks the heat out of the world. Should at least run the vacuum around a bit and load the dishwasher. After that I might do some hacking if i can think of anything interesting to hack on although my brain is still a bit fried from ezetime and work. I've been cranky as hell this week from work and interrupted sleep so maybe I should just do a bit of fuck all.
how ffast can a fmadd fm & add?
Someone asked on the parallella forums how to get that 1-cycle-per fused multiply-add thing to work. I'm pretty sure it's impossible to get it out of the compiler as it stands right now so I didn't even try but I had a look at doing it in assembly language. I was going to post this there but i remembered it doesn't use pre-formatting for code blocks, and it's kind of interesting anyway.
The basic technique is straightforward: double-word loads must be used to load every floating point value otherwise there are too may ialu ops, and once that is established one just needs enough of a calculation to fit in a loop to remove all dependency stalls by unrolling it some number of times.
The details are important though, my first cut didn't delay the fmadd's enough - but ezetime showed this very obviously so it was easy enough to fix.
Actually it's not that straightforward: the inner loop itself also needs to be pipelined - so not only is it unrolled 8 times the 8 steps have been split into two stages temporally separated by half a loop each so it's "effectively" been unrolled 16x. Infact it's a bit better than that because no amount of loop unrolling could hide the data loads completely if each loop were independent. In this case it just needs to perform 0.75 loops incoming (all the loads and half the flops) and 0.25 loops outgoing (the remaining half the flops) outside of the loop to prepare/complete the calculation so the loop count is set to one less than required.
So here's a dump from running ezetime over the assembled code. Of interest is the inner loop where every instruction pair dual-issues and a new fmadd is issued every cycle.
0123456789012345678901234567890123456789012345678901234567890123
_fmadd:
00000000: movts.l special.0.5,r2 | ---1 |3
00000004: mov.l r2,#0x0000 | ---1 |3
00000008: movts.s special.0.6,r2 | ---1 |3
0000000a: mov.l r2,#0x0000 | ---1 |3
0000000e: movts.s special.0.7,r2 | ---1 |3
00000010: mov.l r16,#0x0000 | ---1 |3
00000014: mov.l r17,#0x0000 | 1 |
00000018: mov.l r18,#0x0000 | 1 |
0000001c: mov.l r19,#0x0000 | 1 |
00000020: mov.l r20,#0x0000 | 1 |
00000024: mov.l r21,#0x0000 | 1 |
00000028: mov.l r22,#0x0000 | 1 |
0000002c: mov.l r23,#0x0000 | 1 |
00000030: ldrd.l r48,[r0],#+1 | 12 |
00000034: ldrd.l r56,[r1],#+1 | 12 |
00000038: ldrd.l r50,[r0],#+1 | 12 |
0000003c: ldrd.l r58,[r1],#+1 | 12 |
00000040: ldrd.l r52,[r0],#+1 /| 12 |
00000044: fmadd.l r16,r48,r56 \| 1234 |
00000048: ldrd.l r60,[r1],#+1 /| 12 |
0000004c: fmadd.l r17,r49,r57 \| 1234 |
00000050: ldrd.l r54,[r0],#+1 /| 12 |
00000054: fmadd.l r18,r50,r58 \| 1234 |
00000058: ldrd.l r62,[r1],#+1 /| 12 |
0000005c: fmadd.l r19,r51,r59 \| 1234 |
hw_loop_s:
00000060: ldrd.l r48,[r0],#+1 /| 12 |
00000064: fmadd.l r20,r52,r60 \| 1234 |
00000068: ldrd.l r56,[r1],#+1 /| 12 |
0000006c: fmadd.l r21,r53,r61 \| 1234 |
00000070: ldrd.l r50,[r0],#+1 /| 12 |
00000074: fmadd.l r22,r54,r62 \| 1234 |
00000078: ldrd.l r58,[r1],#+1 /| 12 |
0000007c: fmadd.l r23,r55,r63 \| 1234 |
00000080: ldrd.l r52,[r0],#+1 /| 12 |
00000084: fmadd.l r16,r48,r56 \| 1234 |
00000088: ldrd.l r60,[r1],#+1 /| 12 |
0000008c: fmadd.l r17,r49,r57 \| 1234 |
00000090: ldrd.l r54,[r0],#+1 /| 12 |
00000094: fmadd.l r18,r50,r58 \| 1234 |
00000098: ldrd.l r62,[r1],#+1 /| 12 |
0000009c: fmadd.l r19,r51,r59 \| 1234 |
hw_loop_e:
000000a0: fmadd.l r20,r52,r60 | 1234 |
000000a4: fmadd.l r21,r53,r61 | 1234 |
000000a8: fmadd.l r22,r54,r62 | 1234 |
000000ac: fmadd.l r23,r55,r63 | 1234 |
000000b0: fadd.l r16,r16,r17 | 1234 |
000000b4: fadd.l r18,r18,r19 | 1234 |
000000b8: fadd.l r20,r20,r21 | 1234 |
000000bc: fadd.l r22,r22,r23 | -1234 |1
000000c0: fadd.l r16,r16,r18 | -1234 |1
000000c4: fadd.l r20,r20,r22 | --1234 |2
000000c8: fadd.l r0,r16,r20 | ----1234 |4
000000cc: jr.l r14 | 1 |
Over 2048 data elements it executes in 2089 cycles plus a couple dozen for the function invocation and hardware timer setup overheads. I used 2x8k buffers one in bank 1 and the other in bank 2.
Once it finishes the inner loop it completes the calculations for the data pre-loaded during the final iteration and then sums across the 8 partial sums in 3 parallel steps.
A compatible/equivalent C function taking the same args would be:
// len8s1 == element count / 8 - 1
float fmadd(const float *a, const float *b, int len8s1) {
int count = (len8s1+1)*8; // 'unroll' the count
float c = 0;
for (int i=0; i < count; i++)
c += a[i] + b[i]; (oops)
c += a[i] * b[i];
return c;
}
I haven't validated that it produces the correct calculation but apart from a typo or something it should be correct.
The movts instructions near the start of the listing above are lc, ls, and le respectively (loop count, loop start, loop count) for the hardware loop feature; ezetime doesn't output the register aliases. This is also for an unlinked object so the addresses are all zero - but it sets ls to (hw_loop_e-4) for those who might understand what that means, i just put the label where it is to make the loop more readable. I fiddled with the size of the movts instructions till i got the alignment right so it doesn't need any nops for that alignment. Also, the movts instruction cycle timing isn't meant to be correct.
PS Another 8 cycles could be knocked off if the first loop just used fmul since the 8xloads of 0.0 could be removed; but then it would need 1.75 loops before starting the inner loop
JavaFX Task interface
I've been doing a bit of work on a JavaFX application turning it from a very rough prototype to a very rough product (i mean, what can one really accomplish in two weeks?). I already had a bunch of background tasks running using threads but because the original was thrown together in a rush for a small side-project I just hand-rolled everything using familiar techniques (combination of threads and ExecutorService).
I'd seen JavaFX's Task and wasn't really sure what the point was - sure it simplified a couple of things but Platform.runLater() is easy enough to use and so on.
But I found things got messy pretty fast and behaviour started leaking between abstraction layers.
So as part of this re-work I decided to "use it in anger" and see how it turned out. Quite well, if you're prepared to let JavaFX control the middle-tier of the application by using Task everywhere (and for a JavaFX application, there's no reason not to). Encapsulating the work in a Task object allows the decisions about what to do with the user interface to be decided wherever it is used; e.g. does it bother to start a spinny thing or just run silently and so on. And it handles some of the fiddly stuff so that you don't end up with a busy spinner that never runs out.
Having tasks as immutable single-use objects is how I usually write multi-thread code anyway so it wasn't much of a change (IMHO it's the only way which works). Basically all transient state needs to be captured in the job object so it can be worked on independently of the rest of the application, and all outputs are collected in a result object (memory permitting, and the size of modern memory systems makes them very permissive). If incremental updates are desirable then they can be communicated via some other mechanism although it is perhaps surprising how often incremental update just doesn't work very well for a user.
There are still some small gotchas. Say for example that you're firing off a calculation based on interaction with a slider. Ideally you want the result to update as fast as the slider does but this is often not possible. You can't just let every job run to completion because otherwise it will quickly start to lag and just feel wrong. You can't cancel every job if a new one arrives because you may never have one complete leaving the user staring at stale results. One hack is to just update the result when the user releases the slider knob but that removes most of the interactivity from the GUI and defeats the purpose.
Previously i've solved it by implementing a greedy consumer. Jobs are indivisible units which always run to completion (and to the user interface) but whenever the worker thread polls for incoming jobs it throws away all but the last one if more are queued. ExecutorService doesn't directly allow this granularity of job control but it can be emulated easily enough by something like the following.
ExecutorService queue;
Task task;
void dowork() {
if (task != null && !task.isDone() && !task.isRunning()) {
task.cancel();
}
task = new WorkTask( ... );
task.setOnSucceeded( ... );
queue.submit(task);
}
(is there another way? I don't know, this is what I found ...).
This isn't used for tasks which might take a very long time to complete but for ones which are already interactive speed or close to it (roughly, under 0.5s). It lets any already running jobs finish but cancels any waiting in the queue.
This makes the application "feel" much lighter and more responsive even if it does slightly more calculation than necessary. Unless the work is very trivial almost all such work needs to be thrown into a thread otherwise sliders start to feel unresponsive. This is pretty much the same for any toolkit (or os).
Copyright (C) 2019 Michael Zucchi, All Rights Reserved.
Powered by gcc & me!